Not Just E2E: AI Large Models Are Ushering in the Era of 'Embodied Intelligence' for Autonomous Driving
 07/24 2025
07/24 2025
 817
817
In today's rapidly evolving landscape of autonomous driving technology, we find ourselves at a pivotal juncture. From the initial modular 'perception-localization-planning-control' system to Tesla's groundbreaking end-to-end (E2E) learning, and now to the burgeoning trend of embodied intelligence integrating vision, language, and action (VLA), each shift marks a significant leap forward in autonomous driving capabilities. 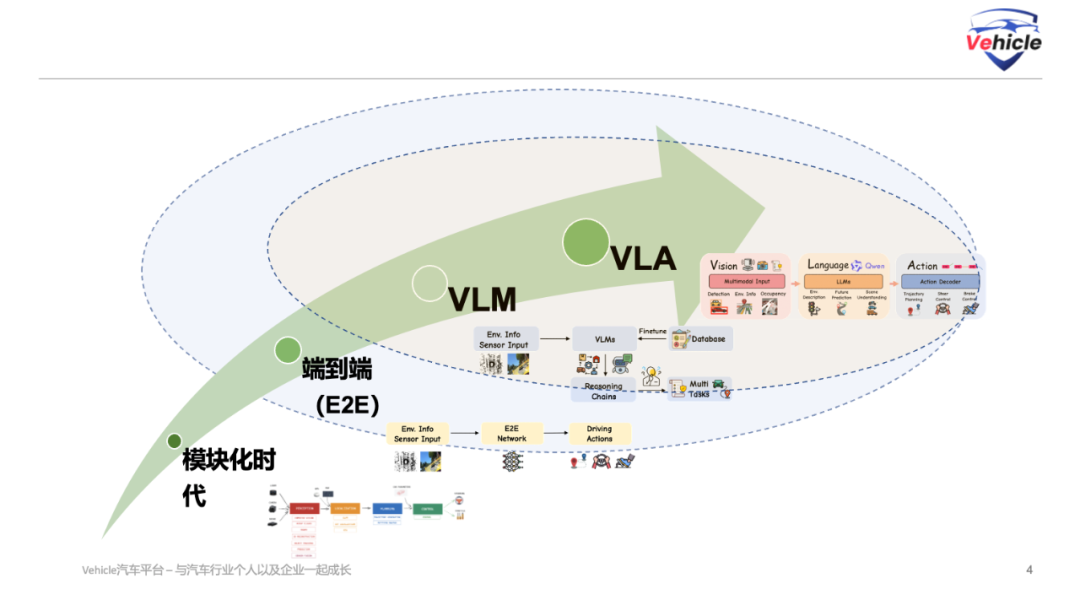
This article delves into these evolutionary paths, analyzes their respective merits and challenges, and anticipates how VLA models will pave the way for a safer, more versatile, and more human-centric future in intelligent driving.
1. The Modular Era: From Rules to the Initial Exploration of Intelligent Driving
Autonomous driving systems initially emerged as modular designs, comprising four primary components: perception, localization, planning, and control. This approach, akin to building with LEGO blocks, assigned specific tasks to each module, aiming to make autonomous driving feasible, marking the dawn of rule-based systems. Each entity crafted rules, validated modules, and maintained a well-organized structure. 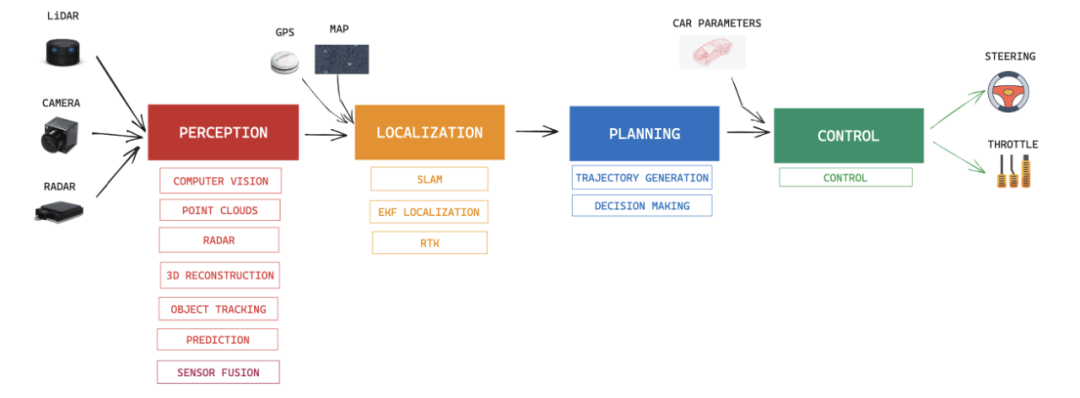
However, challenges arose: there was a tendency for error accumulation and information loss between perception, prediction, and planning modules.
General Motors' Super Cruise exemplifies a classic modular system. It utilizes CNN vision algorithms to identify lane lines and objects, combines this with high-definition maps and RTK localization, and integrates these for path planning and control, realizing intelligent driving.
Chinese newcomers like NIO's NIO Pilot and XPeng's XPilot in 2019 belong to this category. To date, most highway navigation assistance systems still adhere to this approach, recognized for its maturity and cost-effectiveness.
During this period, small chips with computing power ranging from a few to 30 TOPS, such as Mobileye and NVIDIA Xavier, supported a substantial portion of the intelligent driving industry.
2. End-to-End (E2E): A New Era Pioneered by Tesla
Tesla's end-to-end (E2E) driving strategy revolutionized the industry. It directly maps raw sensor data to control commands, bypassing manually written rule codes and modular processes. 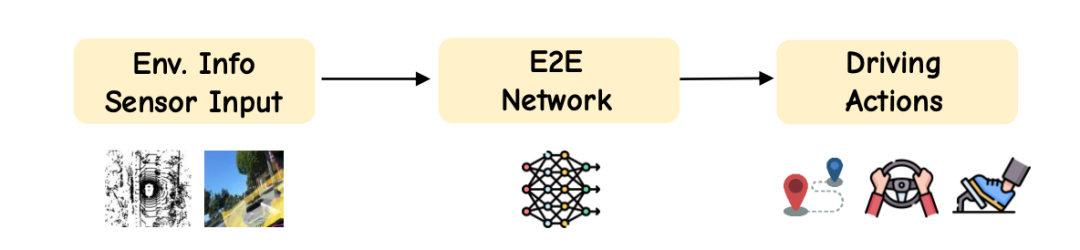
Essentially, E2E is a vision-to-action (VA) system. Visual input can stem from cameras or LiDAR, with action output typically being future trajectories or control signals. Tesla's FSD (Full Self-Driving) is a quintessential E2E representative. Through technologies like BEV (Bird's Eye View) and Occ (Occupancy Network), it integrates a spatio-temporal end-to-end large model, creating a data loop from vision to execution. Shadow data combined with the General World Model generates data, enabling closed-loop training and algorithm iteration for the E2E large model. 
Since 2023, however, Tesla has ceased publicly disclosing the algorithmic structure of FSD, leaving us to speculate or rely on insiders for insights. As intelligent driving began to 'enter cities' in 2024, China faced an onslaught of complex scenarios that overwhelmed rule-based designs. NVIDIA's 256 TOPS Orin X high-performance chip arrived as a timely savior, and the industry shifted towards Tesla's more integrated end-to-end solution. Integrating perception, prediction, and planning modules into a unified framework facilitates cross-module feature-level information flow and ensures efficient data loops. However, academia has found that traditional E2E algorithms experience diminishing returns after a certain threshold of training data, with performance varying greatly across different scenario types.
These findings suggest that sole reliance on data accumulation is insufficient for achieving autonomous driving capabilities beyond L4. In summary, end-to-end learning significantly shortened the distance from raw sensor input to control decisions, but it still grapples with two persistent challenges: Semantic fragility in rare or rapidly changing scenarios, particularly with language and symbolic information (e.g., road signs, sirens), and opaque reasoning due to poor interpretability, making safety audits and verifications difficult. After model upgrades, only repeated model flashing and test drives can ascertain any regression or effectiveness.
3. VLM: When Large Language Models Meet Autonomous Driving
At the end of 2022, OpenAI's GPT era showcased the formidable power of large language models (LLMs), once as elusive as nuclear weapons. By 2024 and 2025, numerous open-source multimodal LLMs emerged, such as Meta's LLaMA, Deepseek's Deepseek, and Alibaba's Qwen, sparking interest in integrating them into the intelligent driving industry. By unifying perception and natural language reasoning within a shared embedding space, LLMs and VLMs (Vision-Language Models) offer a promising solution. 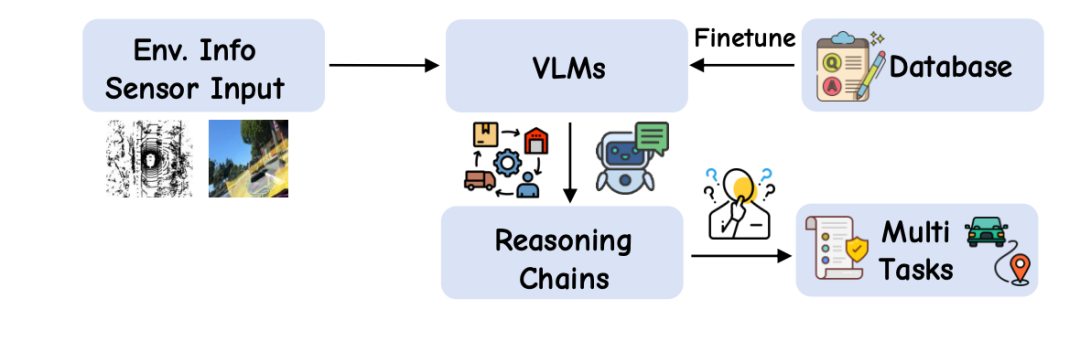
Combining language models with driving tasks enhances the perception and reasoning capabilities, interpretability, and generalization abilities of autonomous driving systems. At its core lies large-scale multimodal pre-training, enabling the model to acquire common-sense associations (e.g., seeing a text sign/intersection means slowing down; hearing a siren means yielding; recognizing when to enter or not enter a tidal lane/bus lane). While large foundational models excel in common-sense reasoning and understanding extreme situations, integrating them into driving systems also presents drawbacks: poor spatial perception, fuzzy numerical outputs, and increased planning latency. Academia has extensively studied the use of VLMs to enhance E2E intelligent driving, but currently, only Li Auto has conducted exploratory implementations in the industry. Li Auto employs a dual-system architecture, using an offline VLM after knowledge distillation as a 'slow system' to provide feedback or auxiliary signals to the 'fast system' end-to-end system. 
Running such large language models on Orin X chips, with a combined computing power of only 504 TOPS, remains challenging even after distillation and reduction.
4. VLA: A New Driving Paradigm Enabled by Embodied Intelligence
With the advancement of artificial intelligence, embodied intelligent robot products, though less safety-sensitive than automobiles, have leveraged various experimental opportunities to drive the booming development of the robotics industry. Unifying vision, language, and action within a single framework has become a trend in embodied intelligent robots. Similarly, as AI infiltrates the human physical world, the automotive industry has been inspired by the latest progress in embodied intelligence, adopting VLA (Vision-Language-Action). 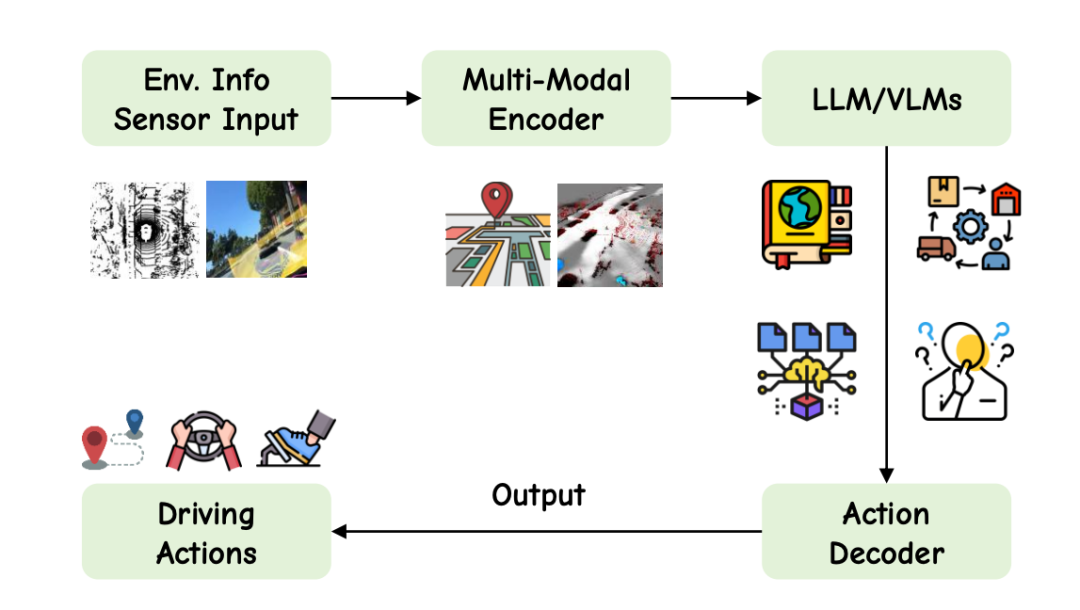
Leveraging foundational models pre-trained on internet-scale visual and language data, VLA demonstrates robust generalization across various domains and benchmarks. Moreover, VLA jointly reasons about vision, language, and action, integrating text and trajectory outputs, long-horizon memory, symbolic safety checks, and multimodal diffusion planning, initiating a new paradigm. Crucially, VLA supports language (instruction/question-answering) interaction, positioning it as a potential personal 'driver master' for autonomous driving: Direct navigation commands like 'Turn left at the next intersection' or 'Stop behind the red vehicle' can be understood. As the system matures, users or agents can ask questions like 'Is it safe to change lanes now?' or 'What is the speed limit here?' enabling interactive situation awareness and environmental queries. Further progress introduces task-level language specifications, such as explaining traffic rules, parsing high-level goals, or understanding map constraints in natural language. It can even transition to multi-turn dialogues and reasoning chains (e.g., chain-of-thought prompts). Tool-enhanced language interfaces can support richer forms of reasoning, aligning with human decision-making processes. Currently, these VLA language interactions are primarily successful laboratory projects, with mass production yet to materialize.
These advancements represent a decisive shift from perception-centric VLM processes towards multimodal agent VLA, integrating action perception, interpretability, and instruction compliance, paving the way for safer, more versatile, and more humanized autonomous driving. In 2025, after several delays, NVIDIA's next-generation edge computing chip, Thor, is expected to launch the 720 TOPS Thor U, capable of running VLA. This instantly ignited competition for the implementation of VLA in Chinese automobiles in 2025. While Li Auto, XPeng, Yuanrong, and others have expressed intentions to mass-produce VLA systems, they are all in nascent stages. The technical details of VLA primarily comprise three core modules: Visual Encoder, using self-supervised models like DINOv2, CLIP, combined with BEV projection and LiDAR fusion technology; Language Processor, utilizing large language models (e.g., LLaMA, Qwen, Vicuna, GPT), often optimized through lightweight techniques like LoRA; and Action Decoder, encompassing autoregressive tokens, diffusion planners, and hierarchical controllers (high-level strategy → PID/MPC control). 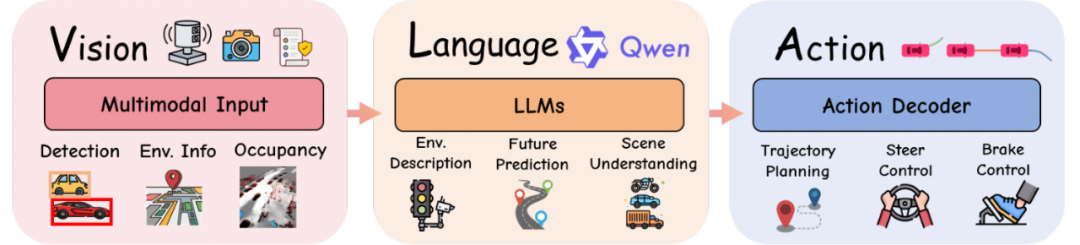
VLA is still in its infancy in intelligent driving applications. Academia has summarized the development of VLA models in intelligent driving into four main stages: Pre-VLA, where language serves as an interpreter; Modular VLA, transitioning the language model from a passive scene describer to an active planning component; Unified End-to-End VLA (e.g., EMMA), mapping multimodal inputs directly to control or trajectory outputs; and Reasoning-Enhanced VLA, where the language model is at the core of the control loop, supporting long-term memory and chain reasoning.
Currently, XPeng has mentioned VLA-like capabilities, but according to released information, these should be considered future, laboratory, or advertising claims, unlikely to be implemented in vehicles before early next year. After all, VLA with long reasoning and memory faces two major issues: high on-board computing power demands and reasoning latency from CoT (Chain of Thought).
5. Epilogue: Foundational Models and World Models
Those following the development of intelligent driving algorithm software may have encountered two buzzwords: 'Foundational Models (FM)' and 'World Models (WM)'. A foundational model can be seen as the 'parent model' for multimodal perception and reasoning modules in VLA models. Originally trained in the cloud, mostly by technology giants, automotive industry applications involve fine-tuning and specialized training of these models. For instance, Xiaopeng and Li Auto primarily use Alibaba's Tongyi Qianwen as their base models.

For a deeper understanding, refer to this article: "Understanding Autonomous Driving Foundation Models with Three Diagrams".
In this context, Tesla and NIO's NWM (Neural World Model) represent two primary roles of the World Model: constructing a physical virtual world for simulation and serving as a foundation model for intelligent driving algorithms.
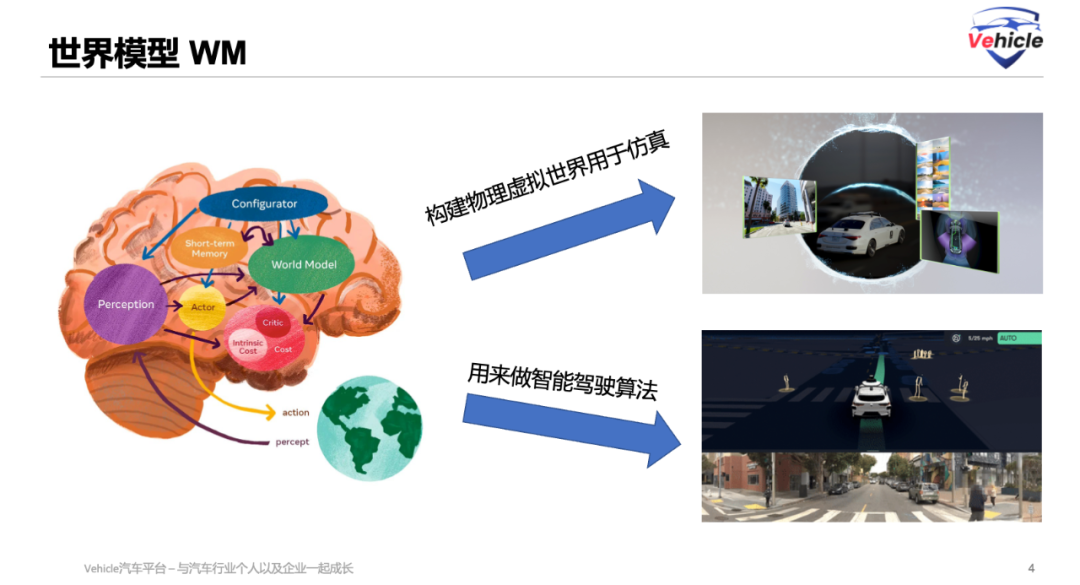
For further details, you can refer to the article titled "World Model 101."
In reality, these two terms are employed for promotional and educational ease. They share a commonality in being versatile large models that comprehend the human physical world and possess reasoning capabilities; the divergence lies solely in their applications and perspectives.
Observing the evolution of autonomous driving technology, we witness a clear shift from modularized engineering explorations to end-to-end (E2E) learning integration breakthroughs, and now to the novel paradigm of embodied intelligence epitomized by vision-language-action (VLA) models. Currently, we stand at the nascent stage of VLA technology's transition from the laboratory to mass production, where computational demands and inference latency pose practical challenges that necessitate urgent attention. Nonetheless, with chip manufacturers such as NVIDIA offering more robust edge computing capabilities, and companies like NIO, Li Auto, and XPeng actively engaged in research and development of high-performance chips, VLA, built upon large language models, is poised to become the linchpin driving force behind the next generation of intelligent driving, effectively transforming autonomous vehicles into our personal "AI drivers."
Reference articles and images:
Autonomous Driving Vision-Language-Action Model Overview - PPT and PDF versions - Jiang Sicong1 *, Huang Zilin4 *, Qian Kang'an2 *, Luo Ziang2, Zhu Tianze2, Zhong Yang3, Tang Yihong1, Kong Menglin1, Wang Yunlong2, Jiao Siwen3, Ye Hao3, Sheng Zihao4, Zhao Xin2, Topwin2, Zheng Fu2, Chen Sikai4, Kun Jiang2, 6, Diiange Yang2, 6, Seongjin Choi5, Lijun Sun1
1McGill University, Canada
2Tsinghua University, China
3Xiaomi Group
4University of Wisconsin-Madison, USA
5University of Minnesota Twin Cities, USA
6State Key Laboratory of Intelligent and Green Vehicles and Transportation, Tsinghua University
-
![]()
5G Standalone Private Network Policy Breaks the Ice, Creating an Exclusive 'Nervous System' for Physical AI in Industrial Scenarios
-
![]()
Two Investments Totaling 700 Million Yuan! Sunny Optical Sets Its Sights Beyond Lens Supply, Launching a Strategic Move in the XR Optics Arena
-
![]()
Xianyu Initiates Internal Testing of 'Yu Maimai' and 'Yu Maimai': Can AI Revolutionize Secondhand Transactions?
-
![]()
The Dullest 618 in History, with AI Being the Busiest
-
![]()
Shenzhen’s Most Mysterious Robot Startup Secures 1 Billion Yuan in Funding, Targeting a 150 Billion Yuan Market
-
![]()
Why Are Celebrities So Keen on Diving into the AI Realm?
-
Can WeChat AI Sidestep the Quandary Faced by Doubao Phone?
-
![]()
Luxury Lineup, Highly Anticipated! The Pioneer of Physical AI Gears Up for Hong Kong Stock Exchange Debut!