AI data explosion triggers an "oil crisis," content companies can now make money easily
 07/23 2024
07/23 2024
 410
410

“
If we compare AI large models to cars, raw data is the crude oil.
”
Author | Jiang Jiang Editor | Manman Zhou The emergence of ChatGPT and the explosive adoption of Midjourney have enabled the first large-scale application of AI, namely the popularization of large models.
Large models refer to machine learning models with a large number of parameters and complex structures, capable of processing massive amounts of data and completing various complex tasks.
01
AI Data Copyright Disputes
If we compare current AI large models to cars, raw data is the crude oil. Regardless, AI models first need sufficient "crude oil."
The main sources of "crude oil" for AI companies include:
● Publicly available free data sources online, such as Wikipedia, blogs, forums, news, etc.;
● Established news media and publishers;
● Research institutions like universities;
● C-end users who utilize the models.
In the real world, the ownership of oil is governed by mature legal norms, but in the chaotic realm of AI, the mining rights of "crude oil" are still unclear, leading to numerous disputes.
Recently, several major music labels have sued AI music production companies Suno and Udio, accusing them of copyright infringement. This lawsuit is similar to The New York Times' lawsuit against OpenAI in December last year.

Image Source: Billboard
In July 2023, some writers filed a lawsuit against the company, alleging that ChatGPT generated summaries of their copyrighted works.
In December of the same year, The New York Times also filed a similar copyright infringement lawsuit against Microsoft and OpenAI, accusing the two companies of using the newspaper's content to train AI chatbots.
Additionally, a class-action lawsuit was filed in California, accusing OpenAI of accessing users' private information from the internet without their consent to train ChatGPT.
OpenAI ultimately did not pay for these allegations, stating that they do not agree with The New York Times' claims and cannot reproduce the issues mentioned. More importantly, the data source provided by The New York Times is not significant to OpenAI.

Source: https://openai.com/index/openai-and-journalism/
For OpenAI, the biggest lesson from this incident may be to properly handle relationships with data providers and clarify rights and responsibilities. Consequently, we have seen OpenAI form partnerships with numerous data providers over the past year, including but not limited to The Atlantic, Vox Media, News Corp, Reddit, Financial Times, Le Monde, Prisa Media, Axel Springer, American Journalism Project, and more.
In the future, OpenAI will legitimately use data from these media outlets, and these media outlets will integrate OpenAI's technology into their products.
02
AI Driving Content Platform Monetization
However, the fundamental reason for OpenAI's partnerships with data providers is not fear of being sued but the impending data depletion faced by machine learning. Researchers from MIT and others have estimated that machine learning datasets may exhaust all "high-quality language data" by 2026.
"High-quality data" has thus become a coveted asset for model manufacturers like OpenAI and Google. Content companies and AI model manufacturers have repeatedly formed partnerships, enabling a hands-off earning model.
Traditional media platform Shutterstock has successively partnered with AI companies such as Meta, Alphabet, Amazon, Apple, OpenAI, and Reka, increasing its annual revenue to $104 million in 2023 through content licensing to AI models, with projected revenue of $250 million by 2027. Reddit's content licensing revenue from Google reaches $60 million annually, while Apple is seeking partnerships with mainstream news media, offering copyright fees of at least $50 million per year. The copyright fees received by content companies from AI companies are soaring at an annual growth rate of 450%.

Image Source: CX Scoop
Over the past few years, monetizing content beyond streaming has been a significant pain point for the content industry. Compared to the internet startup era, AI's emergence has brought greater imagination and stronger revenue expectations to the content industry.
03
High-Quality Data Remains Scarce
Of course, not all content meets AI's requirements.
Another notable aspect of the OpenAI and The New York Times dispute mentioned earlier is data quality. Extracting oil from crude oil requires both good oil quality and excellent purification technology.
OpenAI specifically emphasized that The New York Times' content did not significantly contribute to OpenAI's model training. Compared to Shutterstock, which spends tens of millions of dollars annually on OpenAI, text-based media like The New York Times, which rely on timeliness, are not the darlings of the AI era. AI requires profound and unique data.
Given the scarcity of high-quality data, AI companies are focusing on "purification technology" and "one-stop applications."
On June 25, OpenAI acquired real-time analytics database company Rockset, which provides real-time data indexing and query capabilities. OpenAI will integrate Rockset's technology into its products, enhancing the real-time value of data.

Image Source: DePIN Scan
By acquiring Rockset, OpenAI plans to improve AI's utilization and access to real-time data. This will enable OpenAI's products to support more complex applications such as real-time recommendation systems, dynamic data-driven chatbots, real-time monitoring, and alarm systems.
Rocket serves as OpenAI's built-in "petrochemical department," converting ordinary data directly into high-quality data required for applications.
04
Is Creator Data Confirmation a Pipe Dream?
Data from internet media platforms (Facebook, Reddit, etc.) largely originates from UGC, i.e., user-generated content. While many platforms charge AI companies substantial data fees, they also quietly include a clause in their user agreements stating that the platform has the right to use user data to train AI models.
Although user agreements specify the right to train AI models, many creators are unaware of which models are using their content, whether it is being used for payment, or how to obtain their rightful benefits.
During Meta's quarterly earnings call in February this year, Zuckerberg explicitly stated that he would use images from Facebook and Instagram to train his AI generation tools.
It is reported that Tumblr has also secretly reached content licensing agreements with OpenAI and Midjourney, but the specific contents of these agreements have not been disclosed.
Creators on the stock photo platform EyeEm recently received a notification informing them that their published photos would be used to train AI models. The notification mentioned that users could choose not to use the product but did not mention any compensation policy. EyeEm's parent company Freepik revealed to Reuters that it had signed agreements with two major tech companies to license most of its 200 million images at a price of around 3 cents per image. CEO Joaquin Cuenca Abela stated that five similar deals were in progress but declined to disclose the buyers' identities.
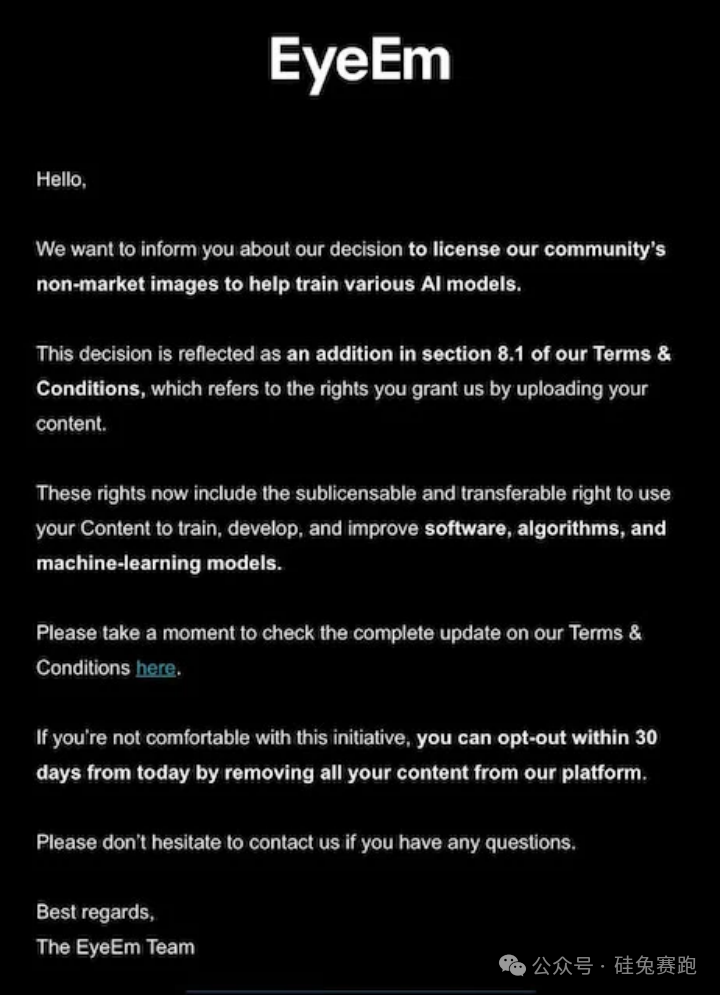
UGC-driven content platforms such as Getty Images, Adobe, Photobucket, Flickr, and Reddit face similar issues. Tempted by the lucrative data monetization opportunities, these platforms choose to ignore users' content ownership rights and sell data en masse to AI model companies.
The entire process takes place in the shadows, leaving creators with no chance to resist. Many creators may only suspect that their works have been sold to AI companies for model training when similar content emerges from a model in the future.
To address the challenges of confirming creators' data rights and protecting their earnings, Web3 may be a viable solution. As AI companies reach new heights on U.S. stock markets, Web3 AI concept coins are also soaring. Blockchain, with its decentralized and tamper-proof nature, has inherent advantages in protecting creators' rights.
Media content such as images and videos has already undergone large-scale adoption on the blockchain during the 2021 bull market, and UGC content from social platforms is also quietly being uploaded. Meanwhile, many Web3 AI model platforms are incentivizing ordinary users who contribute to model training, whether as data owners or trainers.
The exponential growth of AI models has created a greater demand for data confirmation. Creators should consider: Why are my works being sold to AI model companies for 5 cents each without my consent? Why am I uninformed throughout the process and unable to receive any earnings?
Media platforms' exploitation of data sources cannot alleviate AI model companies' data anxiety. Achieving high-quality data output requires data confirmation and a reasonable distribution of benefits among creators, platforms, and AI model companies.
-
![]()
"The Ascent and Decline of the 'Cold King' Are Inconsequential; What Truly Counts Is the Shifting Expectations for China's Chip Sector"
-
Domestic AI Leaps Past 'Computing Power Anxiety' Era
-
![]()
Smart Glasses Take Center Stage at IFA: AR Interaction Emerges as a Norm, Product “Simplification” Sparks a Phase of Quality Leap
-
![]()
Real-Life Images of the Xiaomi 16 Surface, Genuinely Honoring the Classics!
-
![]()
Exclusive | MiniMax Rolls Out Multi-Million-Dollar Stock Option Plan, Escalating Talent Battle in Large-Scale AI Sector
-
![]()
Cook in a Quandary: Will Apple's iPhone 17 Air Be Delayed in China?
-
![]()
Valued at $14 Billion! Endorsed by the President, Europe's Leading AI Firm Takes on OpenAI
-
![]()
LongCat Large Model Unveiled - Alibaba Springs a Surprise, Leaving Meituan Scrambling for a Response






