Jensen Huang's 'AI Factory' Struggles to Ease Investors' Growth Concerns
 03/27 2025
03/27 2025
 659
659
Author|Xuushan
Editor|Yifan
Tickets were scarce on-site, and the stock price tumbled online.
'The more you buy, the more you save, the more you earn.'
At the NVIDIA GTC Conference, Jensen Huang unveiled this year's potent AI industry slogan.
Dressed in his signature leather jacket, Huang swiftly ascended the stage at the SAP Center in San Jose, California. He declared that this year's GTC Conference was the Super Bowl of AI—AI is solving a myriad of problems for numerous industries and companies. As a tech industry bellwether, the conference featured 1,000 sessions, 2,000 speakers, and nearly 400 exhibitors, attracting over 25,000 attendees. Tickets sold out rapidly, with some reselling for as much as RMB 10,000 prior to the event.

This GTC Conference was a pivotal battle for NVIDIA.
The outside world wonders if the AI boom has peaked and if AI chip sales are slowing down. With DeepSeek demonstrating a more cost-effective computing path, can NVIDIA, which still insists on high computing power, maintain its position as the king of AI infrastructure?
Investors' pre-conference doubts gradually waned after Huang's 120-minute keynote speech for GTC. NVIDIA not only unveiled the four-year roadmap for three generations of GPU architectures, showcasing chips like Blackwell Ultra, Rubin, Rubin Ultra, and Feynman, but also mentioned numerous advancements in AI, data centers, robotics, and the CUDA ecosystem.
However, investors responded lukewarmly. After the keynote, NVIDIA's stock price fluctuated slightly, dropping by 3.5%. Concept stocks within the NVIDIA ecosystem, such as TSMC, CEC Port, Shenghong Technology, and Hongbo Technology, also saw minor declines. Among them, Shenghong Technology, NVIDIA's top domestic supplier of computing boards, saw its stock price fall by 5.75%.
Industry insiders indicate that the stock price decline was mainly due to Huang's speech largely aligning with Wall Street's expectations. Many of the new technological advancements had already been discussed at this year's CES. Additionally, the parts of Huang's speech related to quantum computing and embodied intelligence are unlikely to see substantial growth in the short term.
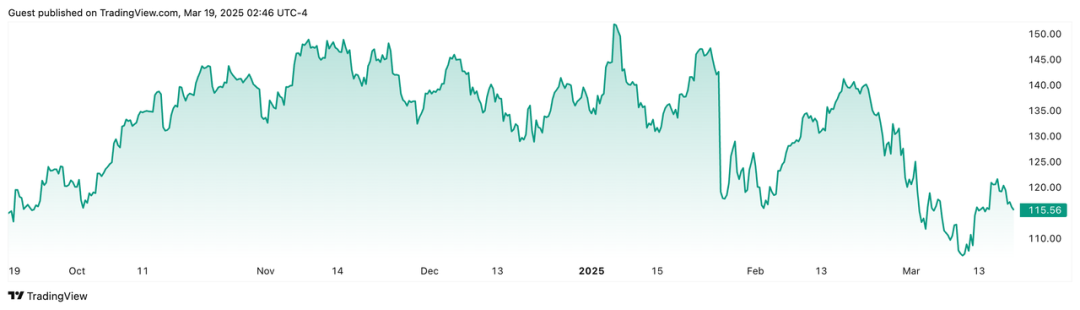
NVIDIA's stock price trend over the past six months Source: TradingView
Here are the key takeaways from today's GTC Conference keynote speech:
1. Comprehensive Upgrade of the Chip Suite: Blackwell chip sales are accelerating and expected to be three times that of Hopper; Blackwell Ultra will be the first GPU with 288GB HBM3e, paired with GB300 NVL72 racks and HGX B300 NVL16 rack systems, making it the flagship product for the second half of this year;
First announcement of the technical blueprint for the next three years: Introducing the Rubin architecture in 2026 (FP4 computing power reaching 100P Flops), Rubin Ultra supporting 576 GPU clusters in 2027, with Rubin's AI factory performance potentially reaching 900 times that of Hopper; Feynman architecture to be released in 2028;
NVIDIA is also jointly packaging optical network chips with TSMC and will introduce a new version of Ethernet chips in the second half of this year;
2. Building a Supercomputing Center Factory: For developers and corporate R&D scenarios, NVIDIA introduced the world's smallest AI supercomputer, DGX Spark, and the AI supercomputer, DGX Station; Launched DGX SuperPOD equipped with Blackwell Ultra GPUs, providing AI factory supercomputing, and simultaneously introduced the DGX GB300 and DGX B300 systems to provide out-of-the-box DGX SuperPOD AI supercomputers; Launched NVIDIA Instant AI Factory to realize AI hosting services, etc.;
3. Launching the AI Inference Model Series: Introducing AI inference service software Dynamo, aiming to maximize token revenue for AI factories deploying inference AI models, increasing the number of tokens generated by the DeepSeek-R1 model by over 30 times, processing over 30,000 tokens per second; Launching the new Llama Nemotron inference model to help enterprises build enterprise-level AI data platforms;
4. Open-Source Robot Model: Interactive robots created in collaboration with Google DeepMind and Disney; Unveiling NVIDIA Isaac GR00T N1, the world's first open-source and fully customizable foundational model, enabling general-purpose humanoid robots to perform reasoning and various skills;
5. Strengthening the CUDA Ecosystem: Introducing the CUDA-X library equipped with the GH200 superchip, enabling CUDA-X to work in coordination with the latest superchip architecture, increasing the speed of computing engineering tools by 11 times and expanding computing capacity by five times; Establishing the first Quantum Computing Day and upgrading the cuQuantum library to drive quantum computing research.
At the conference, NVIDIA repeatedly mentioned China's AI large model DeepSeek, stating that DeepSeek is generally beneficial to NVIDIA in accelerating the promotion of its ecosystem and will not have a negative impact on NVIDIA. Huang addressed the previous sharp drop in stock prices. In fact, by iterating on the architecture once a year, NVIDIA has gradually shortened the cycle for improving AI computing power density.
In the third year of generative AI, NVIDIA officially announced its ambition to build a full-stack AI infrastructure ecosystem at the GTC 2025 Conference. From hardware generational differences, ecological monopoly, and industry standard-setting power, NVIDIA's moat around the 'technology-business' double closed loop is gradually improving. In the short term, NVIDIA has almost no competitors in the AI infrastructure field.

Four-Year, Three-Architecture Technical Roadmap Revealed! Jensen Huang: Tokens Are the Foundation of Everything
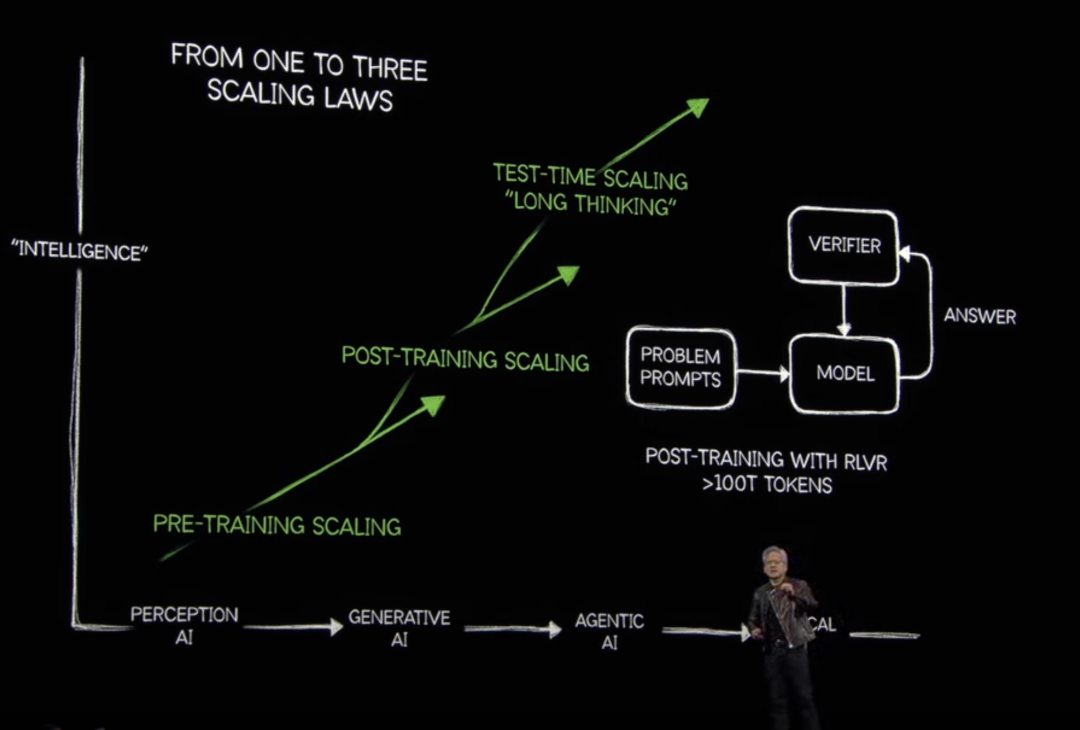
'Everything last year was wrong. The Scaling Law is far from over.' Huang bluntly stated that the Scaling Law is developing faster than expected. As AI shifts from relying on experience and pre-trained data for learning and reasoning to adopting a chain-of-thought approach to generate complete reasoning steps, the demand for computing power increases exponentially.
On-site, he demonstrated this using the Llama 3.3 70B and DeepSeek R1 models by posing them the same seating arrangement problem. The traditional Llama model only used 439 tokens for training and ultimately gave a wrong answer, while the reasoning model DeepSeek R1 used 8,559 tokens for repeated thinking, 20 times that of Llama, with 150 times the computing resources called upon, ultimately providing a correct answer.

Huang believes that data remains the core of everything. Even R1 consumed 608 billion pieces of training data, and the next generation of model improvements may require trillions of data points. The idea of high computing power led by the Scaling Law still holds in NVIDIA's narrative. Furthermore, at this conference, NVIDIA proposed three stages of the Scaling Law: Pre-Training Scaling, Post-Training Scaling, and Test-Time Scaling, the 'Long Thinking' stage. The entire industry will gradually shift from Agentic AI to Physical AI (referring to autonomous systems such as robots, self-driving cars, and smart spaces that can perceive, understand, and execute complex actions in the real world. Often called 'generative physical AI' due to its ability to generate insights and actions).
'I hope everyone is moving in the right direction,' Huang responded, perhaps also a positive response to previous claims that the AI singularity has arrived and that data is no longer the key to improving AI models. This year, NVIDIA's stock price has fallen by over 13%, and its market capitalization has evaporated by nearly $820 billion compared to the historical high hit on January 7, 2025. In this battle to defend its stock price, Huang chose to face head-on the market's doubts about NVIDIA's stock price and growth potential.
After stating that data and computing power are still the two most critical directions in the AI era, Huang began to showcase NVIDIA's treasure trove. From 2025, NVIDIA will launch the Blackwell, Rubin, and Feynman three-architecture series of chips within four years.
Blackwell Ultra will serve as the flagship product for the second half of this year, including the GB300 NVL72 rack-level solution and the NVIDIA HGX B300 NVL16 system. The GB300 NVL72 rack will connect 72 Blackwell Ultra GPUs with 36 Arm Neoverse-based Grace CPUs. Blackwell Ultra is expected to provide 1.5 times the FP4 inference capability of its predecessor (H100), significantly accelerating AI inference capabilities.

It can be seen that while Blackwell Ultra has some improvements over the previous generation, the overall performance enhancement is not very surprising and can be considered a minor version upgrade.
The 'major upgrade' in chip performance may come next year with the introduction of the Rubin series in 2026. Previously, Huang claimed that its computing power would achieve a 'huge leap.' Rubin is named after Vera Rubin, the astronomer who discovered dark matter.
Today, NVIDIA further revealed the latest information about the Rubin series. Next year, Rubin will be released simultaneously with Vera as the flagship CPU chip, alongside the GPU flagship chip.
Perhaps a metaphor can illustrate NVIDIA's ambition in the AI era—NVIDIA is building a vast AI empire that spans from downtown areas, highways, to suburbs.
The CPU is the downtown area, and the GPU is the developing high-tech zone. These two areas are connected through a channel called PCIE, with data volume representing traffic flow. If the data volume is large, roads need to be expanded or additional lanes added. Only the CPU can determine this allocation. The CPU ecosystem has long been monopolized by Arm and Intel's X86. Now, NVIDIA is challenging them.
Vera Rubin is a crucial piece in NVIDIA's CPU+GPU strategy and will be released in the second half of 2026, equipped with a custom Nvidia-designed CPU named Vera. Nvidia claims that Vera Rubin offers significantly improved performance compared to its predecessor, Grace Blackwell, especially in AI inference and training tasks.

Vera has 88 custom ARM-based cores and 176 threads. Simultaneously, Vera will have a 1.8TB/s NVLink core interface for connection with the Rubin GPU. Compared to traditional interconnect technologies, NVIDIA's interconnect technology is faster and can accommodate more 'vehicles.' Vera will replace the existing Grace CPU. According to NVIDIA, Vera's new architecture design will be twice as fast as the Grace CPU. At the GTC Conference in 2021, NVIDIA introduced its first CPU, Grace, with an Arm architecture at its core.
Looking back at the Rubin series, Rubin retains a tiled design, meaning it is essentially two GPUs spliced together on a circuit board to form a new GPU. In terms of performance, compared to B300, Rubin offers 3.3 times the computing power, providing 1.2 ExaFLOPS FP8 training.
Vera Rubin provides 50 petaflops of FP4 inference performance, 3.3 times that of Blackwell Ultra in a similar rack configuration.
In 2027, Rubin Ultra will contain four GPUs, supporting 576 GPU clusters. At the rack level, it will be approximately four times more powerful than the Rubin NVL144 configuration. Additionally, NVIDIA plans to use Vera CPUs in Feynman as well.
From the latest technical roadmap, it can be seen that NVIDIA's GPU updates are currently progressing steadily, with a major version upgrade every two years and a minor iteration every year. The pace of new CPU products is slightly slower, with a major version upgrade expected every three years or so.
But in any case, NVIDIA's self-developed GPU+CPU ecosystem has gradually improved. According to Morgan Stanley statistics, NVIDIA accounts for nearly 77% of the global market share of AI-specific chips. At the same time, NVIDIA has always been a VVVIP customer of TSMC, securing nearly half of TSMC's production capacity and enjoying a strong supply chain advantage. NVIDIA's Rubin adopts TSMC's 3nm process and CoWoS (Chip on Wafer Substrate) packaging technology. The most advanced manufacturing and packaging processes mean that the performance of this chip will be significantly enhanced, and NVIDIA will accumulate rich advanced process IPs through its cooperation with TSMC. A chip industry insider told Silicon Rabbit that advanced process capacity is generally limited, and major customers can obtain priority for beta testing and orders.
Moreover, NVIDIA has been cooperating with leading companies in various industries to understand the most advanced technologies, innovation trends, and industry know-how within the industry. It can be said that on the AI training side, NVIDIA's combination of chips is almost unstoppable. This is also the core key to NVIDIA's unhindered ascent to the throne of AI infrastructure, and data centers also contribute the majority of NVIDIA's revenue.
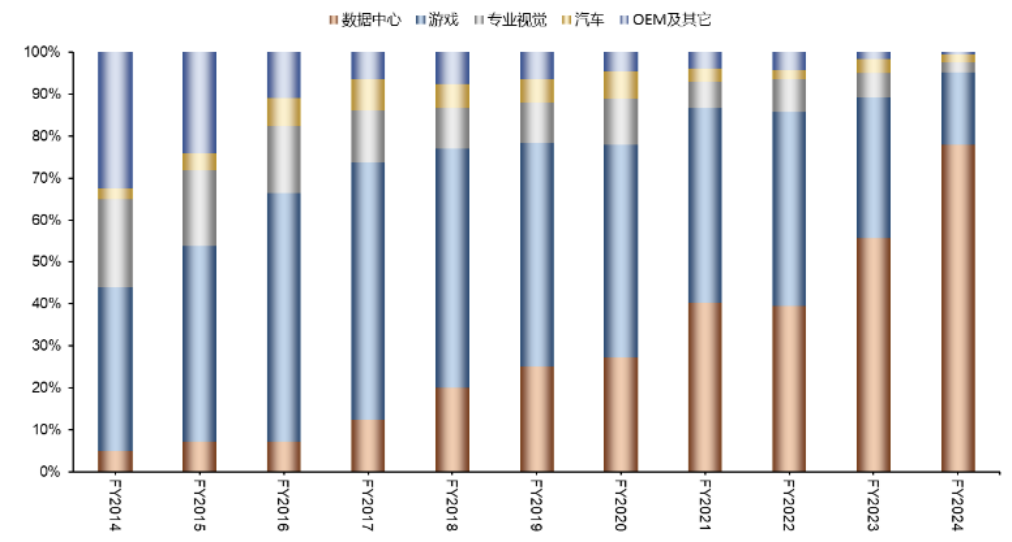
NVIDIA's revenue share changes of main businesses from 2014 to 2024
Source: Wind, WISCO Securities Research Institute
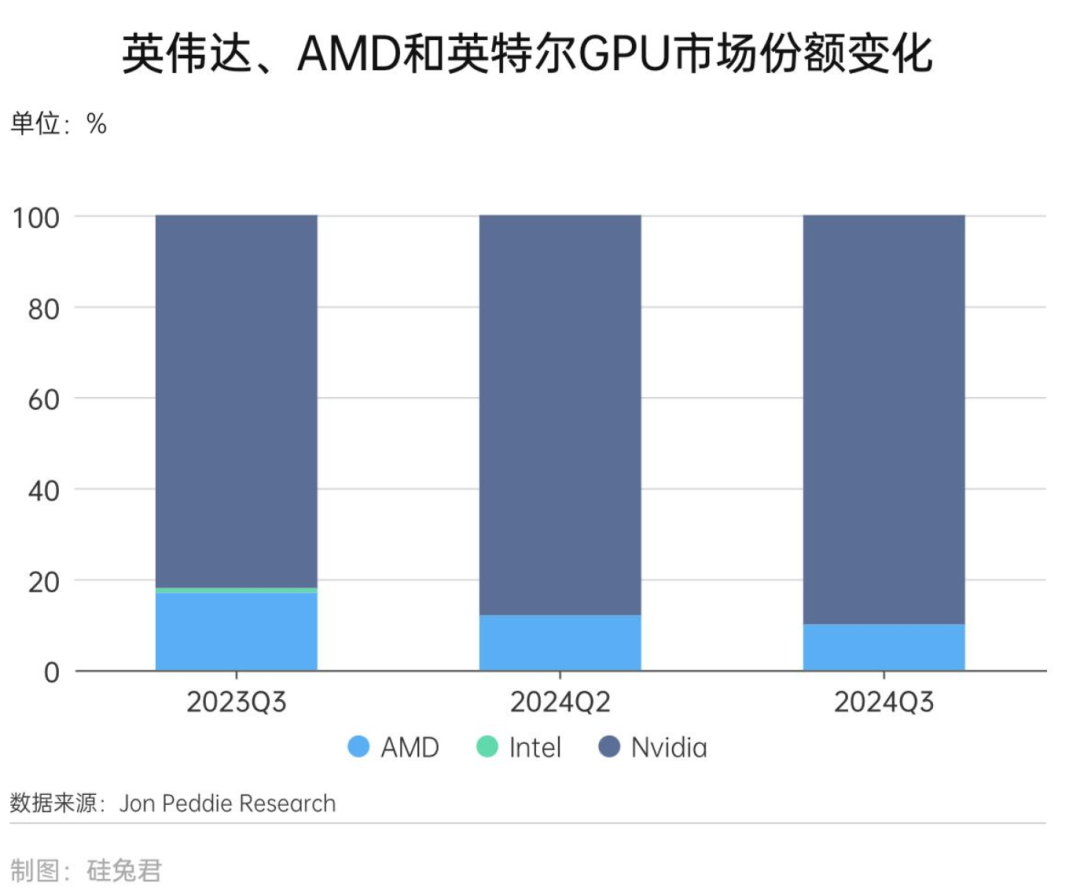
Furthermore, NVIDIA has collaborated with leading firms across various industries to gain insights into the most advanced technologies, innovation trends, and industry know-how. On the AI training front, NVIDIA's chip combination is virtually unstoppable, serving as the cornerstone of its unimpeded ascent to the throne of AI infrastructure. Notably, data centers contribute significantly to NVIDIA's revenue. Huang Renxun revealed that in 2025, the four major cloud service providers—Microsoft, Google, Amazon, and Meta—have procured 3.6 million Blackwell chips. It is anticipated that data center capital expenditures will surpass $1 trillion by 2028, driving chip sales for NVIDIA amidst the tech giants' enthusiasm for data center construction. In the third quarter of 2024, NVIDIA's GPU market share reached an impressive 90%.
The saga of the "shovel seller" continues to enrich its wealth legend. The financial report indicates that the company's sales for the fiscal year ending in January 2025 more than doubled to $124.62 billion. Investment analyst Vellante commented, "We believe GTC 2025 will mark another milestone, signifying a future where extreme parallel computing transcends the realm of large corporations and becomes a daily routine for all enterprises." However, recent financial reports suggest a slight decline in the gross margin of Blackwell chips, raising questions about whether the next-generation GPU can successfully transition into production and maintain its status as NVIDIA's cash cow, requiring further market validation.

Agentic AI + Physical AI: NVIDIA's Next Growth Catalyst
"AI is reaching an inflection point, becoming smarter and more utilitarian." Huang Renxun reminisced about ChatGPT's nascent struggles two years ago, often faltering in answering even simple queries. Despite extensive training and information absorption, it approached each question anew, akin to a human blurting out an answer. Today, however, AI possesses reasoning capabilities, enabling it to deliberate repeatedly, with the chain-of-thought technology continually advancing.
Huang Renxun envisions a future where every company will operate two factories: one built by humans and another, an AI factory, dedicated to scientific research or training. At the commencement of his keynote, he highlighted Agentic AI and Physical AI as the central themes of this year's discussion.
If AI is destined to permeate every industry's fabric, NVIDIA is constructing an expansive and robust CUDA ecosystem. This ecosystem will serve as the fertile soil for various AI-related industries, thriving on increased adoption and fostering superior hardware-software compatibility.
To date, NVIDIA has developed over 900 domain-specific CUDA-X libraries and AI models, lowering the barriers to entry for accelerated computing. In 2025, CUDA-X will venture into advanced engineering disciplines such as astronomy, particle physics, quantum physics, automotive engineering, aerospace, and semiconductor design.

"If the entire conference were to present a single PPT, it would be this one," said Huang Renxun, emphasizing the indispensability of CUDA and NVIDIA's infrastructure for developers to leverage these cutting-edge libraries. He provided detailed updates on MONAI (focused on healthcare), Earth-2 (focused on weather), and cuQuantum (focused on quantum computing). These libraries constitute NVIDIA's latest vertical AI field achievements, attracting a plethora of developers to the CUDA ecosystem centered around vertical domain data information. Additionally, NVIDIA launched Dynamo, an AI inference service software, designed to maximize token revenue for AI factories deploying inference AI models. According to NVIDIA, Dynamo can enhance the number of tokens generated by the DeepSeek-R1 model by over 30 times, processing over 30,000 tokens per second. Dynamo comprises four core components: GPU Planner, Smart Router, Low-Latency Communication Library, and Memory Manager. It also supports separation services, allocating different GPUs to distinct computational stages of LLMs.
Currently, several AI startups have expressed their intent to collaborate with NVIDIA. AI provider Cohere plans to utilize Dynamo to support agentic AI features in its Command series models. Together AI aims to dynamically resolve traffic bottlenecks at various stages of the model pipeline through Dynamo. Furthermore, NVIDIA released the open-source Llama Nemotron model series with inference capabilities, aimed at providing developers and enterprises with ready-to-use foundations to construct advanced AI agents capable of independent or collaborative task completion. In conjunction with Dynamo, NVIDIA's new Llama Nemotron inference model leverages advanced techniques to enhance contextual understanding and response generation, enabling separate fine-tuning and resource allocation for each stage through separation services, thereby increasing throughput and response speed.
The Llama Nemotron model series includes three scales: Nano, Super, and Ultra. The Nano model offers peak accuracy on PCs and edge devices; the Super model provides optimal accuracy and highest throughput on a single GPU; and the Ultra model achieves the highest agent accuracy on multi-GPU servers.

NVIDIA asserts that compared to base models, the Llama Nemotron inference model offers enhancements in multi-step mathematical operations, coding, reasoning, and complex decision-making capabilities. These improvements result in up to a 20% increase in model accuracy and a five-fold speed enhancement in inference compared to other leading open-source models. Beyond Agentic AI, Physical AI was seamlessly integrated into the GTC conference. Upon entering the exhibition center, attendees encounter an AI sculpting robot designed using brainwave measurements by AI artist Emanuel Gollob and choreographed by AI. Nearby, a humanoid robot serves as an exhibition consultant, capable of answering inquiries about events, forum timings, locations, etc. This robot was developed by startup IntBot. During the keynote's conclusion, Huang Renxun interacted with Blue, a robot co-created by Google DeepMind and Disney. According to Huang, Blue, equipped with two personal supercomputers, exhibits remarkable intelligence, understanding and promptly responding to his instructions. Despite its bipedal design, Blue resembles a robot dog, primarily offering emotional value.

Robots were ubiquitous at the conference. Huang Renxun mentioned that embodied intelligence faces three major challenges: data handling, model architecture selection, and determining the Scaling Law for the robotics industry. While Huang did not provide specific answers, he outlined NVIDIA's approach through its product layout. NVIDIA has enhanced and upgraded the world foundation model Cosmos, introducing an open and fully customizable physical AI development inference model, empowering developers with better control over world generation. Cosmos Transfer simplifies perceptual AI training by converting 3D simulations or ground truths created in Omniverse into realistic videos for large-scale, controllable synthetic data generation. Cosmos Transfer WFM can assimilate structured video inputs such as segmentation maps, depth maps, LiDAR scans, pose estimation maps, and trajectory maps to produce controllable and realistic video outputs. Cosmos Reason is an open and fully customizable WFM with spatio-temporal perception capabilities, utilizing chains of thought reasoning to comprehend video data and predict interaction outcomes, such as a person walking onto a sidewalk or a box falling from a shelf. 1X, Agility Robotics, Figure AI, Foretellix, Skild AI, and Uber are the first enterprises to adopt Cosmos, enabling faster and larger-scale generation of richer training data for physical AI.

Declining Expectations
NVIDIA encounters challenges in its self-developed chips. Judging from GTC 2025, Huang Renxun appeared less confident and spirited compared to his 2023 demeanor. His speech was punctuated by stutters, and he seemed slightly nervous when addressing key questions and mentioning pivotal products. Since the beginning of 2025, NVIDIA's market value has fluctuated and declined, influenced by the broader US stock market environment and the impact of DeepSeek. More crucially, investors' expectations for NVIDIA have gradually waned, leading them to view its growth trajectory more rationally. Following the sentiment downturn, NVIDIA's market value has stabilized. However, this does not signify a slowdown in its AI promotion efforts. On the contrary, in 2024, NVIDIA paid closer attention to the progress of cutting-edge AI projects.
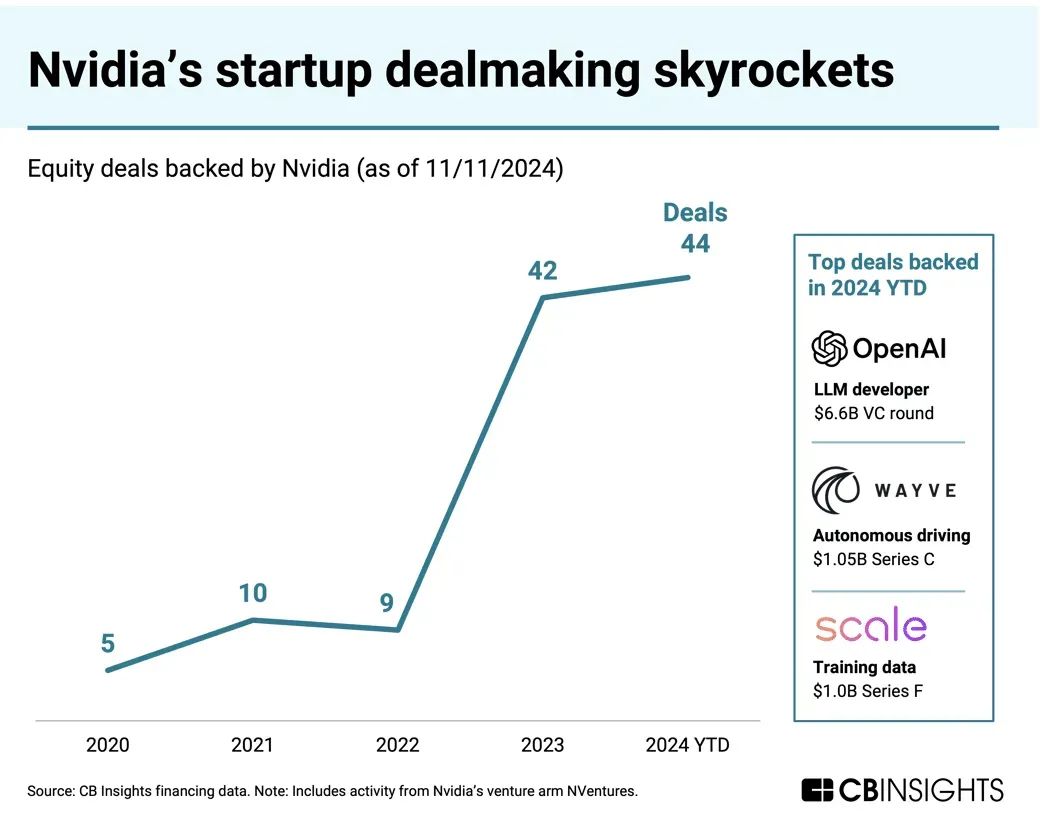
PitchBook data reveals that in 2024, NVIDIA intensified its venture capital investment efforts, participating in 44 funding rounds for AI companies, a notable increase from 34 rounds in 2023. NVIDIA's corporate venture capital fund, NVentures, also engaged in 24 investment deals in 2024.
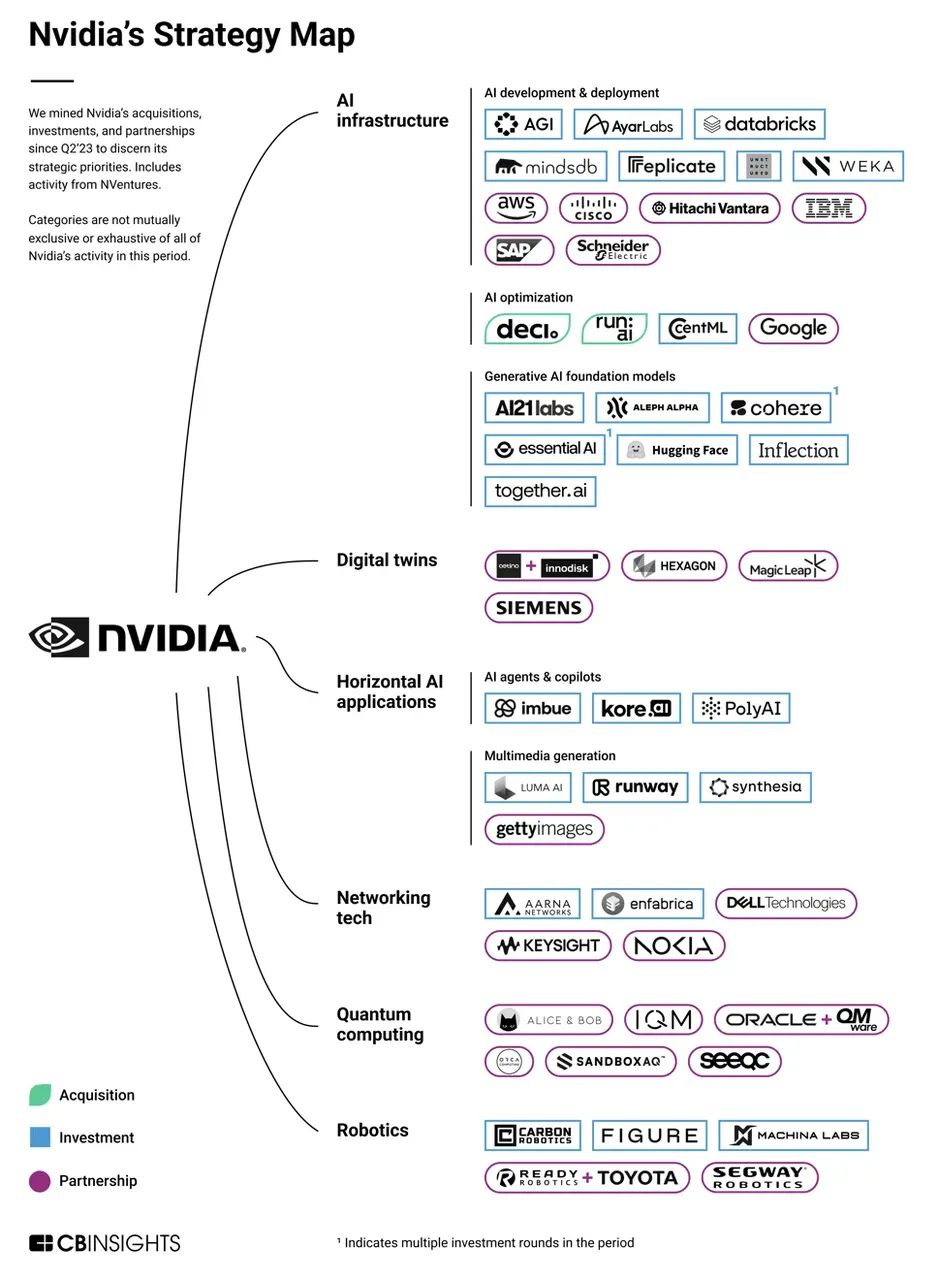
However, new challenges emerge. Recently, major companies like Google, Amazon, and Meta aim to develop their own chips (e.g., TPUs, Trainium) to reduce their dependency on NVIDIA GPUs. Amazon reportedly saves 10%-40% in computing costs through its Graviton chips. Nevertheless, these self-developed chips are primarily for internal use. For companies lacking robust software and hardware capabilities, NVIDIA remains their preferred choice. Additionally, due to US export controls, the performance of NVIDIA's China-specific chips has significantly diminished, prompting Chinese companies to gradually shift towards domestic substitutes or self-developed chips. In the GPU-centric data center business, NVIDIA's revenue from the Chinese market declined from 19% in fiscal year 2023 to approximately 5% in fiscal year 2024. Moreover, new chip architectures like quantum chips and photonic chips are accelerating their development and deployment, potentially bringing new disruptions to NVIDIA.
-
![]()
A Humanoid Robot Becomes an Office Intern: The 'Reinforcement Learning' Journey of a Former NVIDIA Engineer
-
![]()
Meta Plans to Launch Cloud Infrastructure Business: Is Computing Power Really in Excess?
-
![]()
Giants Enter the Arena One After Another: The Embodied AI Battle Commences
-
![]()
Is It More Profitable to Build 'Hands' for Robots Than 'Humans'?
-
![]()
Yunling Optoelectronics Accelerates Its Listing on the Beijing Stock Exchange: Secures 989 Million Yuan to Bolster Production of Computing Optoelectronic Chips
-
![]()
From Drill Bits to Optical Coatings: A 200-Billion-Yuan Behemoth Quietly Unveils a New Business Front!
-
![]()
New Energy Vehicle Growth Slows: Are 370 Million Existing Cars the Next Lucrative Market?
-
![]()
Is Baidu Now Fostering Its Own 'Yao Shunyu'?