UALink Specification Release: Challenging NVIDIA's AI Dominance
 04/14 2025
04/14 2025
 566
566
Produced by Zhineng Zhixin
The Ultra Accelerator Link (UALink) 1.0 specification has been officially unveiled, heralding a fresh wave of competition in Artificial Intelligence (AI) and High-Performance Computing (HPC).
UALink, spearheaded by industry titans such as AMD, Broadcom, Google, and Intel, aims to establish an open, high-speed, low-latency interconnect standard that directly confronts NVIDIA's dominance in NVLink technology. With a bandwidth of 200 GT/s per channel, support for up to 1024 accelerators, and features including low cost, scalability, and high security, UALink 1.0 injects new competitive vigor into the AI accelerator ecosystem.
We delve into the significance of UALink from the perspectives of technological innovation and market competition, exploring its potential impact on the AI industry landscape.
Part 1
UALink's Technological Innovations and Advantages
UALink's inception is a collective response from companies like AMD, Broadcom, and Intel to NVIDIA's proprietary NVLink technology.
NVIDIA has crafted an efficient GPU interconnect ecosystem through NVLink and NVSwitch, demonstrating robust performance in rack-level solutions like the Blackwell NVL72. However, the closed nature of NVLink restricts the participation of other vendors and escalates system integration costs.
UALink dismantles these barriers with open standards, enabling accelerators from diverse vendors (like AMD Instinct GPUs and Intel Gaudi) to collaborate seamlessly, thereby reducing the complexity and cost of data center deployments.
This open ecosystem not only grants flexibility to system integrators and data center operators but also opens avenues for small and medium-sized AI hardware vendors to compete.
UALink Specification Release: The Dawn of NVIDIA's AI Dominance Challenge
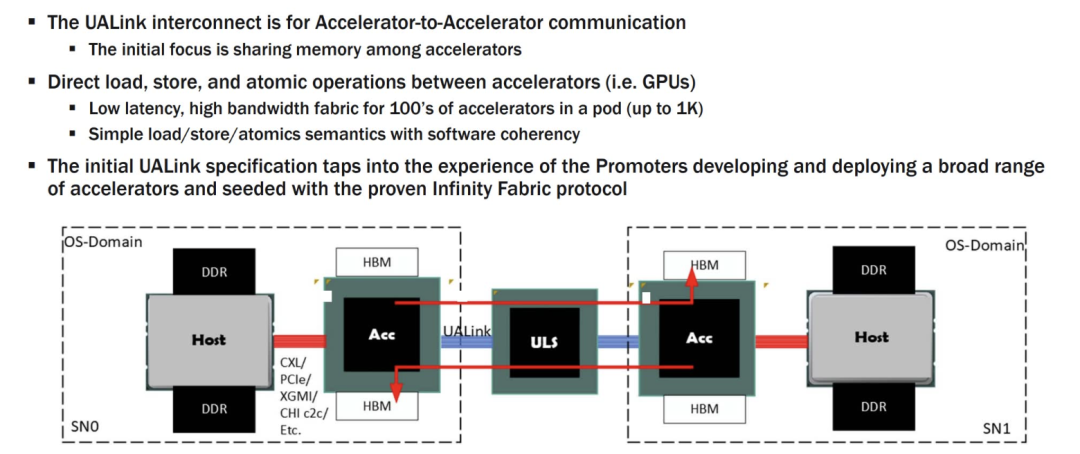
● The UALink 1.0 protocol stack comprises physical, data link, transaction, and protocol layers, deeply optimized for AI and HPC workloads.
◎ Physical Layer: Built on standard Ethernet components (e.g., 200GBASE-KR1/CR1), it significantly minimizes latency by enhancing forward error correction (FEC) and codeword interleaving while maintaining compatibility with the existing Ethernet ecosystem.
◎ Data Link Layer: Employs a 64-byte to 640-byte flit packetization mechanism, coupled with cyclic redundancy check (CRC) and optional retry logic, ensuring reliable and efficient data transmission.
◎ Transaction Layer: Achieves up to 95% protocol efficiency through compressed addressing and direct memory operations (read, write, atomic transactions), optimizing memory access across accelerators, particularly suited for the stringent low-latency requirements in AI training and inference.
◎ Protocol Layer: Supports UALinkSec hardware-level encryption and trusted execution environments (such as AMD SEV, Intel TDX), offering secure isolation and confidential computing capabilities for multi-tenant data centers.
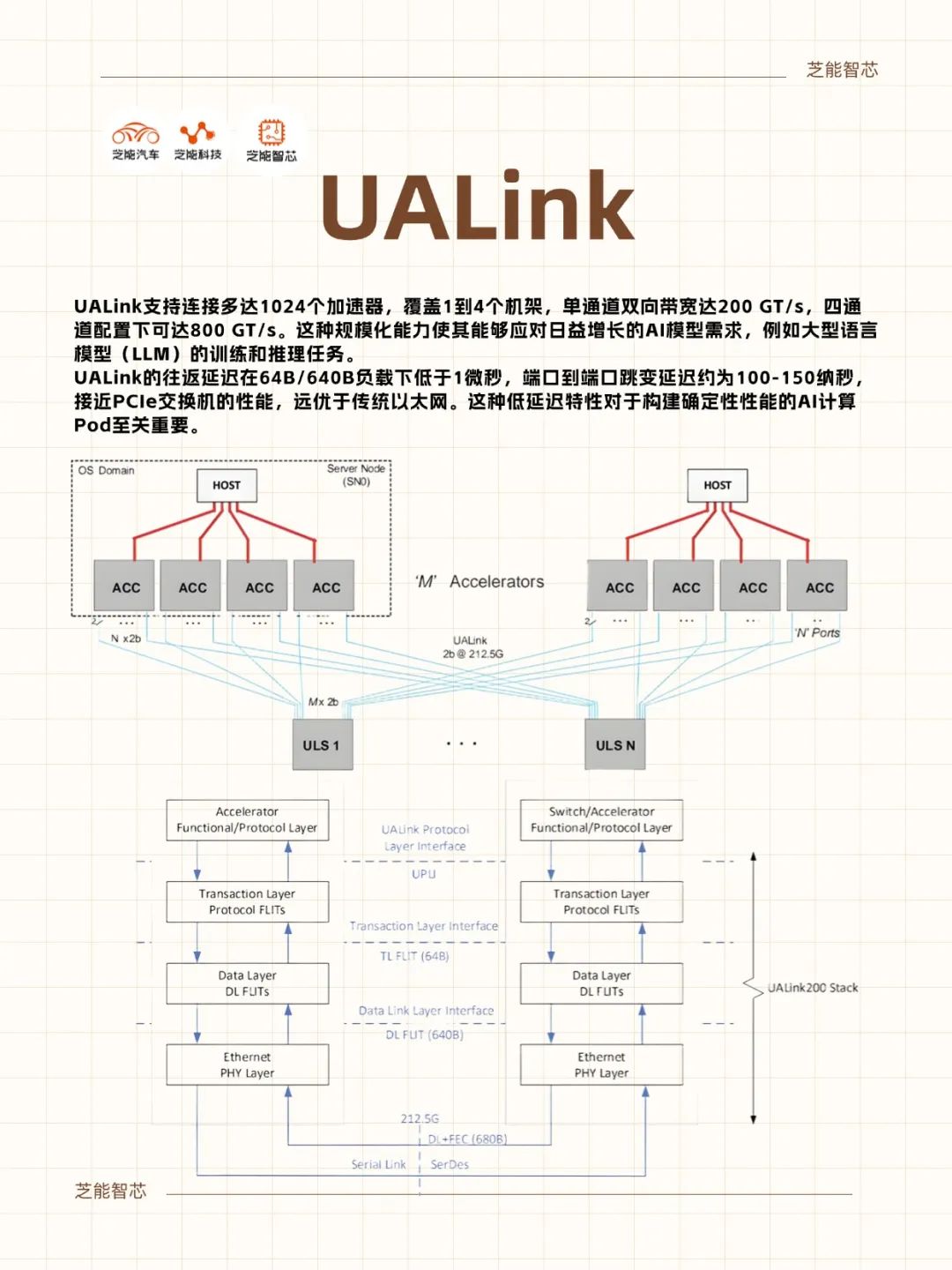
This layered design simplifies protocol complexity while maintaining high performance. Compared to PCI-Express (PCIe) or CXL, UALink offers superior bandwidth and latency, ideal for large-scale AI computing clusters.
UALink supports the connection of up to 1024 accelerators, spanning 1 to 4 racks, with a single-channel bidirectional bandwidth of 200 GT/s, scaling to 800 GT/s in a four-channel configuration.
This scalability empowers it to handle the escalating demands of AI models, such as the training and inference tasks of large language models (LLMs).
Furthermore, UALink's round-trip latency is below 1 microsecond under 64B/640B loads, with port-to-port hop latency around 100-150 nanoseconds, approaching the performance of PCIe switches and surpassing traditional Ethernet. This low-latency attribute is crucial for constructing AI computing pods with deterministic performance.
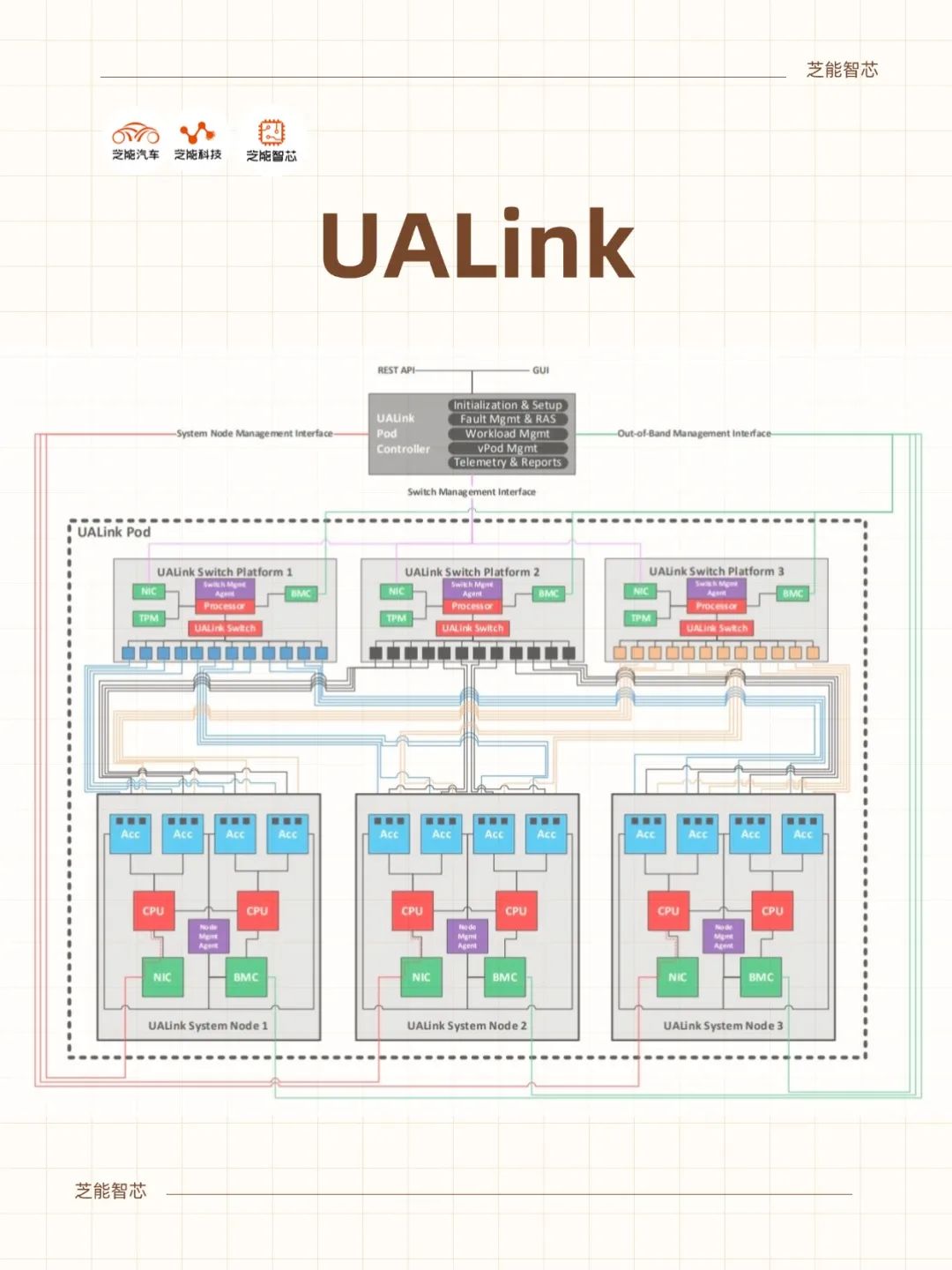
UALink's design underscores energy efficiency, with its switches consuming only 1/3 to 1/2 the power of equivalent Ethernet ASICs, saving 150-200 watts per accelerator. Smaller chip areas and reduced power consumption not only cut hardware costs but also decrease data center power and cooling expenses, thereby optimizing the total cost of ownership (TCO).
This is particularly vital for hyperscale cloud service providers (like Google and Microsoft), who need to balance performance with operational costs.
Part 2
UALink Challenges NVIDIA's Ecological Barriers
NVIDIA's dominant position in the AI accelerator market stems not just from its powerful GPU hardware but also from the synergy of NVLink, NVSwitch, and the CUDA software ecosystem.
For instance, the Blackwell NVL72 rack connects 72 GPUs through NVLink, supporting 576 GPUs with Pod-level expansion, while the upcoming Vera Rubin platform will further elevate the number of GPUs per rack to 144.
In contrast, UALink 1.0 theoretically supports Pod scales of up to 1024 accelerators, showcasing greater scalability potential.
However, NVIDIA's ecological barriers are not solely reliant on hardware interconnectivity; the widespread adoption of CUDA and its optimized toolchains has deeply entrenched it within the developer community.
The UALink alliance must compete not only at the hardware level but also nurture software ecosystems (like ROCm and oneAPI) to entice developers to migrate from NVIDIA platforms.
The UALink alliance comprises members from various fields, including chip design (AMD, Intel, Broadcom), cloud services (Google, Microsoft, Meta), network equipment (Cisco), and system integration (HPE).
This broad industry support provides a foundation for the rapid deployment of UALink. For example, Synopsys has launched UALink IP controllers and verification IPs, and Astera Labs and Broadcom also plan to produce UALink switches.
However, coordinating the interests within the alliance may prove challenging. For instance, Google and Meta focus on custom accelerators (like TPUs), while AMD and Intel aim to promote general-purpose GPUs. These differing priorities among members may complicate the evolution of standards.
Moreover, NVIDIA's absence makes it difficult for UALink to shake its market dominance in the short term, especially in the high-end AI training market.
The release of the UALink 1.0 specification marks a significant leap in technological development, but it typically takes 12-18 months from specification to commercial products. The alliance anticipates the first UALink devices to hit the market in 2026, while NVIDIA's NVLink 6.0 and Rubin Ultra platform may further elevate performance in 2027.
This means UALink must demonstrate its performance and cost advantages within a limited time frame to capture market share.
Market acceptance will hinge on performance in actual deployments, such as seamless integration with existing data center infrastructure and the ability to substantially reduce the overall cost of AI training and inference.
Furthermore, small and medium-sized enterprises may be more receptive to open standards than large customers reliant on the NVIDIA ecosystem, presenting UALink with opportunities to penetrate the market.
UALink's collaboration with the Ultra Ethernet Consortium (UEC) is a crucial aspect of its strategy.
UEC is dedicated to optimizing Ethernet to meet the scaling needs of AI and HPC, while UALink focuses on high-speed interconnectivity for accelerators within Pods. The union of these two is expected to form a holistic solution for "within-scale + beyond-scale." For instance, UALink can be utilized to connect Pods of 8-128 servers, while Ultra Ethernet facilitates expansion across Pods.
This synergistic effect enhances UALink's ecological competitiveness but also increases the complexity of technology integration, necessitating efficient collaboration among the alliance in standard setting and product development.
Conclusion
The release of the UALink 1.0 specification signifies the evolution of the AI industry's competitive landscape. As an open standard, UALink provides a crucial tool for companies like AMD, Intel, and Google to challenge NVIDIA's AI dominance through high-speed, low-latency, and low-cost interconnect technology.
The optimized design, scalability, and security of the protocol stack lay the groundwork for constructing the next generation of AI computing Pods, while the synergy potential with Ultra Ethernet further augments its market prospects. The alliance must continue its efforts in software ecosystems, product deployments, and market promotion, particularly proving its value within the critical time window of 2026.
More broadly, the emergence of UALink reflects the AI industry's yearning for openness and diversity. With the relentless growth of AI training and inference demands, the competition between UALink and NVLink is poised to commence forthwith.
-
![]()
A Humanoid Robot Becomes an Office Intern: The 'Reinforcement Learning' Journey of a Former NVIDIA Engineer
-
![]()
Meta Plans to Launch Cloud Infrastructure Business: Is Computing Power Really in Excess?
-
![]()
Giants Enter the Arena One After Another: The Embodied AI Battle Commences
-
![]()
Is It More Profitable to Build 'Hands' for Robots Than 'Humans'?
-
![]()
Yunling Optoelectronics Accelerates Its Listing on the Beijing Stock Exchange: Secures 989 Million Yuan to Bolster Production of Computing Optoelectronic Chips
-
![]()
From Drill Bits to Optical Coatings: A 200-Billion-Yuan Behemoth Quietly Unveils a New Business Front!
-
![]()
New Energy Vehicle Growth Slows: Are 370 Million Existing Cars the Next Lucrative Market?
-
![]()
Is Baidu Now Fostering Its Own 'Yao Shunyu'?