Revised DeepSeek Disrupts Huawei's Mindset
 07/07 2025
07/07 2025
 627
627
Source: SourceByte
The industry was thrown into chaos when the correlation of technical parameters soared to an astonishing 0.927.
Recently, a research team publicly compared data on GitHub, highlighting that the parameter structure of Huawei's Pangu ProMoE and Alibaba's Qwen-2.5 14B is remarkably similar, reaching 0.927—well above the industry's typical range (below 0.7). Huawei's Pangu team swiftly responded, emphasizing that their model is optimized for Ascend hardware, representing a "different path leading to the same goal." Alibaba, usually vocal in public discourse, surprisingly remained silent.

Screenshot from Noah's Ark Lab's official account
Similarly, last month, Kimi-Dev-72B from the Dark Side of the Moon amazed everyone with a test score of 60.4%, but later faced controversy when labeled as a "shell" due to the notation "Basemodel: Qwen2.5-72B." As developers debated endlessly, it was discovered that Alibaba was once again at the center of controversy, leading to questions such as: Is this a triumph of fine-tuning technology, or a fig leaf for a lack of originality?
DeepSeek R2, once highly anticipated, remains unreleased. Expected to continue pressuring the world's top large models, it has long been "delayed," contributing to a "loss of focus" in the technical standards of domestic large models.
Amidst repeated cries of "the wolf is coming" regarding R2, the market seems to be gradually losing patience, shifting the competition among domestic large models from a technological battle to internal resource consumption.
01 The Technical Maze Behind the Parameter Debate
The "0.927 similarity" between Huawei's Pangu ProMoE and Alibaba's Qwen-2.5 14B directly exposes the black box of large model research and development.
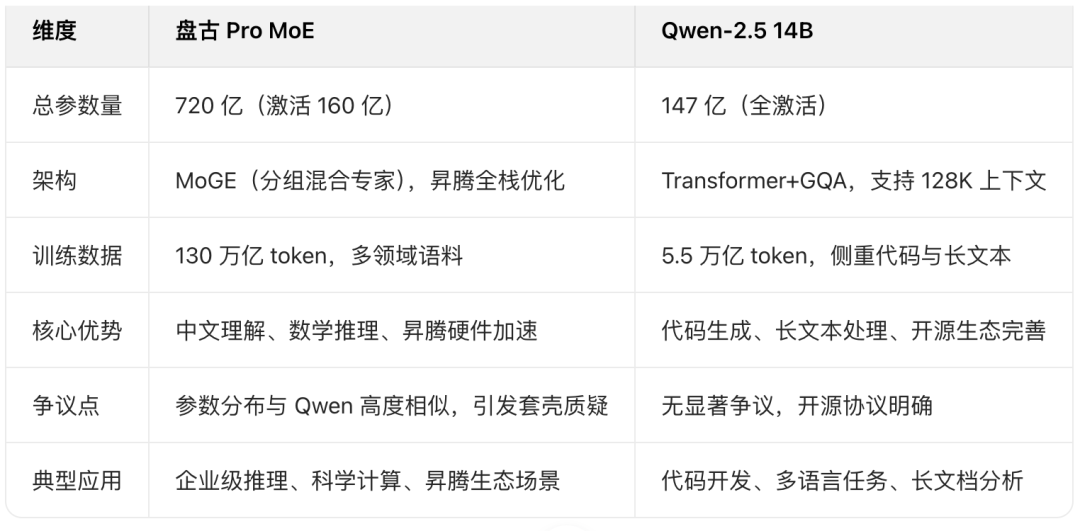
The research team found that the structural similarity between the two models far exceeds the industry norm by comparing the distribution of attention parameters. Huawei insists that its model is optimized for Ascend hardware, representing a "convergence of different paths leading to the same goal" within a heterogeneous architecture. Alibaba remains silent, but the open-source community has raised questions about the compliance of code reuse.
However, the controversy over technical details quickly descended into the quagmire of commercial competition.
The Pangu team urgently released a technical white paper, emphasizing the patent layout of its MoE architecture. Alibaba, on the other hand, accelerated the iteration of Qwen-3.0, seemingly using version upgrades to hedge against public opinion risks. An anonymous chip engineer revealed, "The convergence of parameter structures is essentially a technical compromise under the arms race of computing power."
The developer community is skeptical. User @HonestAGI conducted a reverse verification using "LLM Fingerprint" technology, and the results were highly consistent with the original research. Does technological convergence equate to plagiarism? This question has sparked intense debates within the open-source community.
Voices supporting Huawei argue that technical overlap in the field of large models is inevitable, and the key lies in optimization and implementation. Supporters of the Ascend ecosystem specifically point out that Pangu's dynamic expert network design solves the problem of load balancing in distributed training, which is a tangible innovation.
However, opponents dug up anonymous revelations, claiming that some Pangu models involve "watermark washing" — that is, fine-tuning open-source models and repackaging them. Although the revelations did not provide specific evidence, Alibaba's Tongyi Qianwen open-source agreement clearly requires derived models to indicate their sources, a detail that adds to the confusion.
From a technical perspective, the similarity in parameter structures may stem from overlapping training data or converging optimization objectives. However, the core issue is whether this high degree of consistency violates the spirit of open-source agreements when both giants publicly emphasize "independent innovation."
In Huawei Pangu team's response, a detail is worth pondering: they mentioned "referencing industry open-source practices" but did not specify which practices. This vague statement makes it difficult for outsiders to judge the boundaries of their actions. Alibaba's silence, on the other hand, is interpreted as a tactical avoidance to prevent involvement in public debates.
An analyst who has been observing the AI industry for a long time said, "Behind the parameter debate lies the identity anxiety of domestic large models amidst rapid development — they must both catch up with international giants and stand out in local competition." This anxiety may be the true essence of the technical maze.
02 Fine-tuning Dividends and Innovation Dilemmas
The dispute between Huawei and Alibaba is not an isolated incident. Just last month, the Dark Side of the Moon and Alibaba were embroiled in a similar controversy.
Just as the outside world believed that the Dark Side of the Moon would fall behind in the internal competition among domestic large models, its Kimi-Dev-72B emerged as a clear winner in the SWE-bench test.
This model improved the accuracy of code tasks to 60.4% through the optimization of 150 billion specialized data points and millions of GitHub tickets. At that time, it set a new record for open-source models, leaving many competitors, including DeepSeek, behind.
However, the good times did not last long. Developers soon discovered that Kimi-Dev-72B clearly indicated its base model as Qwen/Qwen2.5-72B. Subsequently, disagreements spread rapidly within the developer community: some viewed it as a fine-tuning exemplar "standing on the shoulders of giants," while others questioned whether it was merely "technical assembly" cloaked in open-source clothing.
Fine-tuning is a common practice in the industry, but the transparency of labeling has failed to dispel doubts. The Dark Side of the Moon officially explained that they used Qwen 2.5-72B as a starting point and collected millions of GitHub issues and PR submissions as intermediate training datasets. Their core innovation lies in the adoption of large-scale reinforcement learning technology.
The core of the controversy is not the technology itself, but the boundaries of innovation. Kimi-Dev-72B's performance was indeed impressive, but does its success rely on the original capabilities of the base model? An anonymous developer sharply pointed out, "If fine-tuning can achieve top-level performance, where is the value of originality?"
The rules of the open-source ecosystem are being redefined. Alibaba attempts to maintain technological sovereignty through agreement updates, while the Dark Side of the Moon speaks with performance, attempting to prove that fine-tuning is not simply "shelling." Market reactions are polarized: some companies begin to emulate this rapid iteration model, while others call for a return to original research and development.
It is worth noting that Kimi-Dev-72B's optimization framework does have its uniqueness, combining the roles of BugFixer and TestWriter to precisely improve the efficiency of code repair and test writing through reinforcement learning.
However, whether such optimization is sufficient to define "innovation" remains an open question. It is evident that the industry's anxiety is intensifying. When fine-tuning becomes a shortcut, will the costs and risks of original research and development be marginalized? In this regard, a partner at a venture capital firm explained, "Capital prefers projects with quick results. The investment cycle for original large models is too long."
03 Disordered Competition
The glory of R1 is now a thing of the past, and the difficult birth of R2 has left the market anxious. DeepSeek, once renowned for its low cost and high performance compared to OpenAI, became a benchmark for global open-source inference models.

Screenshot from DeepSeek's official website
R2, rumored to be released in April this year, has yet to see the light of day, with only a revised version of R1 released at the end of May.
At least based on the two "shelling" incidents since June, the revised R1 model is unlikely to shoulder the responsibility of defining industry standards.
Media reports revealed that the delay was forced by the company's founder Liang Wenfeng's pursuit of ultimate performance and the shortage of H20 chips. According to leaked internal documents, its MoE design with 1.2 trillion parameters is benchmarked against GPT-4 Turbo, but training cost control has become a critical bottleneck.
Beyond technical bottlenecks, the industry is facing a more severe crisis of trust. R1 broke the technological paradigm with purely reinforcement learning training, but the absence of R2 has allowed Huawei and Alibaba to potentially seize ecological niches. A venture capital firm told SourceByte, "When everyone is busy 'gilding' models, true innovation becomes a luxury."
DeepSeek has now become synonymous with domestic large models, and its R1 model has the significance of defining industry standards. However, after more than half a year of technical absence and consecutive delays in R2, it is inevitable that some would want to replace it. "For leading internet companies, being able to define industry standards and lead the direction of industry progress is what they value most," the venture capital firm candidly admitted.
Simply put, the delay of DeepSeek R2 has indirectly caused the competition among domestic large models to lose focus.
Huawei and Alibaba have been active during the R2 vacuum period. While the controversy surrounding Huawei Pangu ProMoE has yet to subside, Alibaba has quietly advanced the iteration of Qwen-3.0. Although the technical paths of the two giants differ, their core logic remains the stacking of parameters and performance. It is no wonder that many anonymous developers are joking, "Everyone is playing 'who has the bigger number,' and no one cares whether the technology has truly progressed."
According to some developers who reported to SourceByte, some domestic AIs focus on "going overseas" rather than developing for the domestic market. Besides the fact that the domestic market has not yet formed a payment habit, a considerable part of the reason is that domestic large models only match or surpass overseas models in parameters, but there is still a certain gap in specific development details, directly leading to a surge in development costs.
Meanwhile, the chip shortage has exacerbated this chaos. The tight supply of NVIDIA's H20 has put enterprises reliant on high-end hardware in a passive position. The delay of DeepSeek may only be the beginning, as more small and medium-sized vendors may be forced to withdraw from competition due to insufficient resources.
Even so, the market's expectations for R2 have not diminished. Rumors suggest that its mixture-of-experts (MoE) architecture will significantly reduce costs, but its specific performance remains unknown. If R2 can break through as scheduled, it may reignite industry confidence; if delays continue, the competitive landscape of domestic large models may be rewritten.
Interestingly, this delay has inadvertently allowed the market to see the true state of the industry, where issues such as converging technical paths, lack of innovation, and resource monopolization have been magnified by the absence of R2. A practitioner helplessly stated, "What we need is not another parameter monster, but a tool that can truly solve problems."
Some images are sourced from the internet. Please inform us if there is any infringement for deletion.
-
![]()
Internet Valuation Logic Shifts: From Scale Narrative to Profit Accountability
-
VOYAH Struggles to Find Its Niche in the Competitive Auto Market
-
![]()
Maxwell Technologies Gains Indirect Stake in Precision Optics via New Venture
-
![]()
Raising 1.8 Billion! This Domestic Optical Inspection 'Little Giant' is Going Public
-
China's AI 'Normandy Moment': The Explicit and Implicit Threads of BATL
-
![]()
Starting at 4999 Yuan! Nubia RedMagic Gaming Tablet 5 Pro Review: Impressive Performance, But Hefty Price Tag
-
![]()
ByteDance Initiates First Major Management Reform
-
![]()
AI is Quietly Destroying a Trillion-Dollar Industry