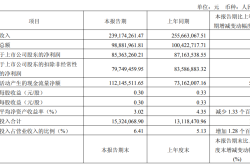
Reversing the Heavenly Steeds! Stanford AI Team Plagiarizes Chinese Large Model
 06/05 2024
06/05 2024
 822
822
Editor: Meimei
How can it not be considered a form of international recognition when a Chinese large model is plagiarized?
On May 29, an AI research team from Stanford University released a model called "Llama3V," claiming that it could train a SOTA multimodal model for only $500, rivaling the effects of GPT-4V, Gemini Ultra, and Claude Opus.
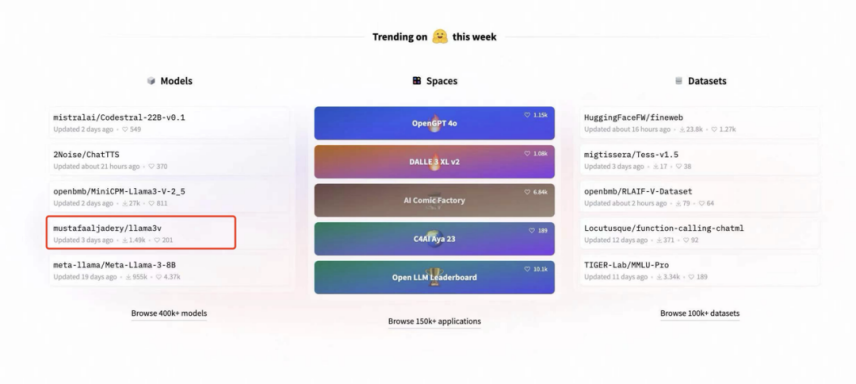
The paper has three authors: Mustafa Aljaddery, Aksh Garg, and Siddharth Sharma, two of whom come from Stanford and have backgrounds from various institutions such as Tesla, SpaceX, Amazon, and the University of Oxford. To outsiders, they are typical industry leaders. Therefore, the tweet announcing the release of this model quickly exceeded 300,000 views, and the project also reached the front page of Hugging Face. People who tried it out found that the effects were genuinely good.
But why did this large model recently "delete its database and run away"? What happened?
Could it be that a prestigious American university plagiarized a Chinese large model?
Not long after the release of Llama3V, some suspicious voices emerged on platform X and Hugging Face. Some believe that Llama3V is actually a "shell" of the 8B multimodal small model MiniCPM-Llama3-V 2.5 released by Mianbi Zhineng in mid-May but did not express any tribute or thanks to MiniCPM-Llama3-V 2.5 in their work on Llama3V.
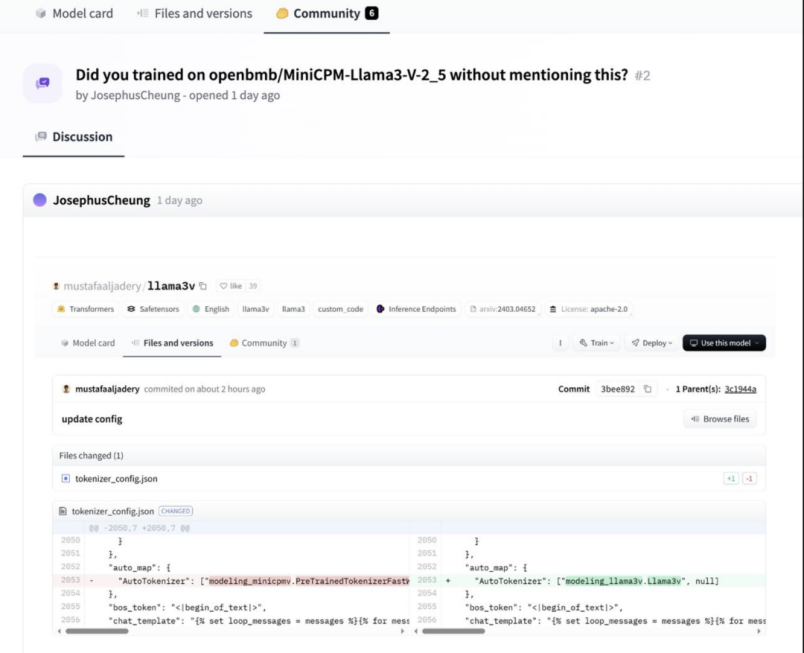
Mianbi Zhineng is a Chinese AI large model company whose core team members include members from the Natural Language Processing and Social Humanities Computing Laboratory (THUNLP) at Tsinghua University, such as CEO Li Dahai and co-founder Liu Zhiyuan.
In response, the Stanford AI team claimed that they "only used the tokenizer of MiniCPM-Llama3-V 2.5" and "started this work before the release of MiniCPM-Llama3-V 2.5." However, as diligent netizens dug deeper, they found that the model structures, code, and configuration files of these two models were identical, with only the variable names changed.

However, after netizens presented evidence to question the Llama3V team, the team's approach was to delete comments and the database. Many web pages related to this project, whether on GitHub or Hugging Face, all became 404 errors. Ignoring the evidence, netizens found the other party involved in the incident, namely Mianbi Zhineng, and presented a series of evidence.
Upon seeing this, Mianbi Zhineng had the two models tested and found that they "not only have identical correct places but also identical errors." If this were a coincidence, it would be hard to justify. Subsequently, they found a crucial piece of evidence, which is the recognition of Qinghua Bamboo Slips. This is actually one of the unique functions of MiniCPM-Llama3-V 2.5.
Qinghua Bamboo Slips are very rare ancient Chinese characters written on bamboo during the Warring States period. When they were trained, the images used were scanned from recently unearthed cultural relics, and Mianbi Zhineng annotated them. Therefore, it can be said that other large models, apart from Mianbi Zhineng, basically do not have this function. Moreover, Llama3V was developed by a US team, which theoretically should not have specifically developed this function. However, in reality, the recognition of Llama3V and MiniCPM-Llama3-V 2.5 is extremely similar, which is basically conclusive evidence.

In the face of evidence, the attitude of admitting guilt is confusing
In the face of various evidence, this Stanford team still did not admit to plagiarism but instead removed almost all projects related to Llama3V, making the following statement:
We are very grateful to those who pointed out similarities to previous research in the comments.
We realize that our architecture is very similar to OpenBMB's "MiniCPM-Llama3-V 2.5," and they were ahead of us in implementation.
We have removed the original model about the authors.
However, they quickly backtracked, with two of the authors, Siddharth Sharma and Aksh Garg, and another author, Mustafa Aljadery from the University of Southern California, cutting ties, accusing the latter of writing code for the project without informing them about Mianbi Zhineng. They claim that they were more involved in promoting the model.
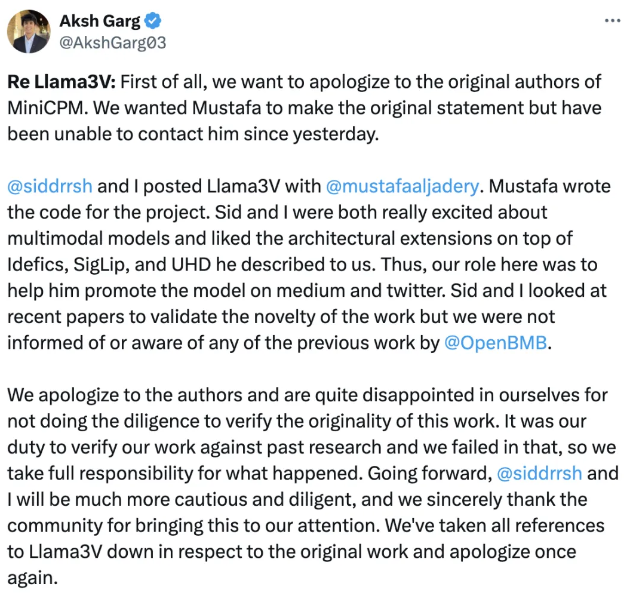
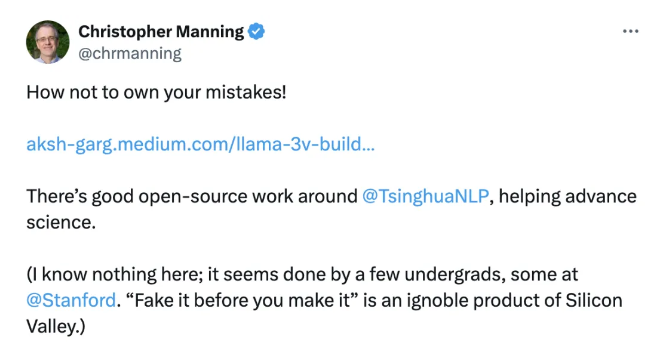
This led many netizens to mock that simply promoting the model through tweets could make one a co-author of the project, a title that came too easily. Therefore, Christopher Manning, the director of Stanford Artificial Intelligence Laboratory, criticized this as "a typical case of not admitting one's mistakes!"
In response, the CEO of Mianbi Zhineng said yesterday that "it is also a way of being recognized by international teams," and the chief scientist Liu Zhiyuan also stated, "Two of the three members of the team are just undergraduate students from Stanford University and have a long way to go in the future. If they can recognize and correct their mistakes, it would be great."
Chinese large models lack recognition from international teams
Although this incident is highly dramatic, the reason it attracted attention is mainly because Llama3V not only has the endorsement of prestigious universities and companies but also possesses genuine strength. However, this has also led to reflections.
Lucas Beyer, a researcher from Google DeepMind and the author of ViT, mentioned that Llama3-V is plagiarized, but there is indeed a model that costs less than $500 and rivals the open-source models of Gemini and GPT-4, which is Mianbi Zhineng's MiniCPM-Llama3-V 2.5. However, compared to Llama3V, MiniCPM has received much less attention. The main reason seems to be that this model comes from a Chinese laboratory rather than an Ivy League university.

Omar Sanseviero, the head of Hugging Face, also stated that the community has been overlooking the work of the Chinese machine learning ecosystem. They are doing amazing things with interesting large language models, visual large models, audio, and diffusion models.
Including Qwen, Yi, DeepSeek, Yuan, WizardLM, ChatGLM, CogVLM, Baichuan, InternLM, OpenBMB, Skywork, ChatTTS, Ernie, HunyunDiT, and many others.

Indeed, from the perspective of the large model arena, Chinese large models actually perform quite well. For example, Yi-VL-Plus from Zero One Everything ranks fifth in the one-on-one visual large model arena, surpassing Google's Gemini Pro Vision. CogVLM, a collaboration between Zhipu AI and Tsinghua University, also ranks among the top ten. Chinese large models often make the list in other project competitions.
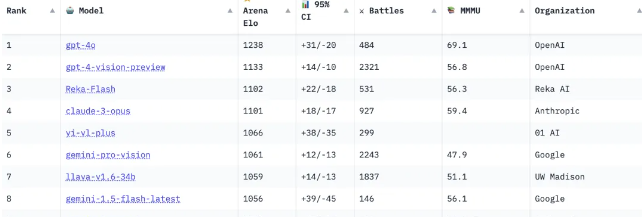
Even with such strength, domestic large models are not only unwelcome internationally but also often trapped in public opinion mud domestically, labeled as "we are independent when others open source" and "shells." This incident can well illustrate that, in fact, some Chinese large models are outstanding. Although there is still a significant gap compared to internationally leading models, Chinese large models have grown from being nobody to one of the key drivers in AI, and some prejudices about Chinese large models need to be broken.
-
![]()
Is Tencent AI Heading in the Right Direction?
-
Latest Update! Jinding Optics’ GEM IPO Review Now “Under Inquiry”
-
![]()
VOYAH’s CBO Sets Ambitious Target: Secure Top 3 Spot in Luxury BEV Market Within Two Years, Launch 4 New Models to Cover All BEV Segments
-
![]()
Sehwa Technology Invests 740 Million Yuan, Eyeing the Lucrative Optical Film Market!
-
![]()
150 Million Users, $40 Million ARR: AIShige Technology Enters the Final Round of AI Video Competition
-
![]()
StepOn Star Forays into Smartphone Manufacturing: A Rationally Sound Yet High-Risk Endeavor
-
![]()
TCL Zhonghuan: Embracing a New Story Despite Anticipated Losses
-
![]()
Forty Years On: From Volkswagen’s State-Backed Entry into China to BYD’s Hiring of a Former European Foreign Minister