Reflections from a Former OpenAI Engineer: The Secrets Behind Their Continuous Innovation
 07/18 2025
07/18 2025
 684
684

Editor: Key Points Guy
From ChatGPT, igniting a technological revolution, to DALL·E, Whisper, Sora, and Codex, many ponder the enigma of OpenAI's relentless output of groundbreaking products that reshape the world.
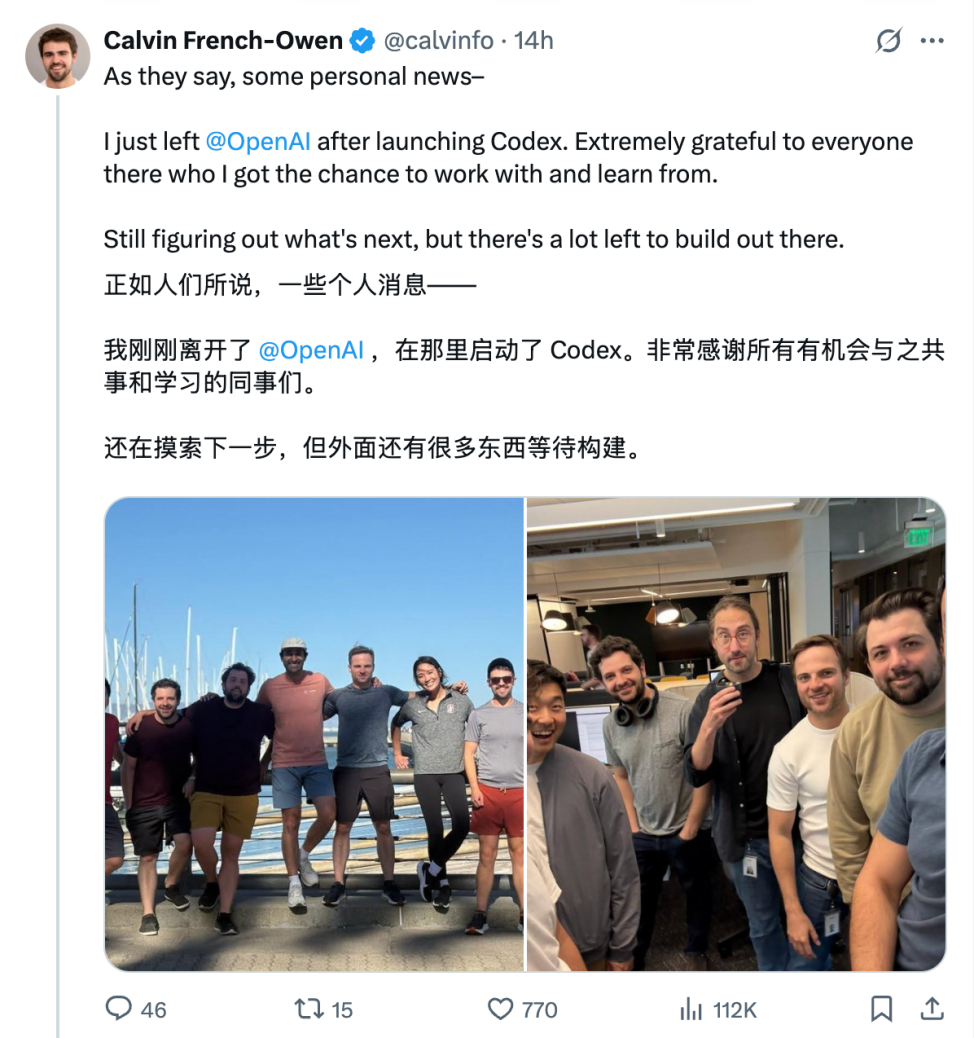
Three weeks ago, Calvin French-Owen, a senior engineer and core member of the Codex project at OpenAI, announced his departure. Codex, OpenAI's programming assistant, stands in competition with Cursor and Anthropic's Claude Code.
Upon leaving, Calvin penned a detailed internal reflection, offering a frontline engineer's perspective on the inner workings of OpenAI to the curious. To him, OpenAI is a complex entity—part research laboratory, part perpetual product machine.
One Year at OpenAI: A Surge from 1,000 to 3,000 Employees
When Calvin joined OpenAI, he was the 1,000th employee. A year later, the company had tripled in size. In his blog, he detailed the typical "growing pains" of such rapid expansion: chaotic organizational communication, disparate team rhythms, and Slack messages overwhelming everything.
Email is virtually unused internally at OpenAI; all communication is conducted on Slack. The emphasis is on keeping pace, regardless of how you use it.
He described the transition from being the founder of a small team at Segment to becoming a cog in a 3,000-person organization. This disparity momentarily questioned his decision. However, during this period, he also witnessed the operation of a "giant research and product factory."
Bottom-Up Approach: Ideas Spring from Prototypes
Calvin repeatedly emphasized the word "bottom-up." At OpenAI, good ideas often emerge not from processes but from someone secretly crafting a prototype.
At one point, there were 3-4 versions of the Codex prototype circulating internally, all assembled by small groups. Once results were promising, they could recruit people, form teams, and initiate projects.
Management differs from traditional giants: those who can conceive and execute good ideas gain more influence in the team. The company values "whether you can deliver the product" more than speeches and political maneuvering.
He even stated that the best researchers are like "mini CEOs," with complete autonomy over their research. What matters is the outcome, not the process.
Rapid Action: Codex Launched in Just Seven Weeks
The most vivid part of Calvin's memo stems from the seven-week sprint on Codex.
He ended his paternity leave early and returned to the office, working tirelessly with a dozen people to refine the product, test features, and modify code. He wrote, "These were the most exhausting seven weeks of my decade. I'd go home at 11 or 12 p.m. every night, be woken up by my kids at 5:30 a.m., and sit back in the office at 7 a.m., working through weekends as well."
From the first line of code to launch, Codex took just seven weeks. Behind this was a core team of fewer than 20 people, supplemented by ChatGPT engineers, designers, product managers, and marketers as needed. There was no unnecessary bickering, no quarterly OKRs; whoever could step up did so.
He said he'd never seen a company turn an idea into a product in such a short time and make it freely available to everyone—this is the true work rhythm of OpenAI.
Magnified Attention and Invisible Pressure
OpenAI's ambitions extend far beyond ChatGPT. Calvin revealed that the company is simultaneously betting on over a dozen directions: APIs, image generation, coding assistants, hardware, and even unannounced projects.
He also saw the inevitable high pressure behind this.
Almost all teams pursue the same goal: creating Artificial General Intelligence (AGI). Every Slack message they send could become global news. Internal product and revenue data are tightly guarded, with varying levels of access within the team.
Regarding external security concerns, Calvin also had his observations. He said that most teams worry less about "when will AI take over the world" and more about hate speech, political manipulation, prompt injection, or users using it to write biological weapon recipes. These real, inconspicuous risks are far more challenging than philosophical questions.
What Makes OpenAI Unique?
To outsiders, this company is "the closest to human ultimate intelligence." To those who have left, what's cool is precisely that it hasn't turned into a sluggish giant.
The Codex project was launched in seven weeks, and teams could quickly reallocate people across projects. "If it's useful, don't wait for the next quarter's plan." Leadership is constantly present on Slack, not just for show but to genuinely participate in specific discussions and decisions.
Another point that impressed him was that OpenAI made its most powerful models freely available through APIs, not just to large enterprises but also to ordinary people, without annual agreements or expensive licensing fees. They truly practice what they preach.
His reason for leaving was less dramatic. The outside world loves to amplify departures into conspiracies. But Calvin said that 70% of his reason for leaving OpenAI was simply because he wanted to start something new on his own.
In his eyes, OpenAI has transformed from a group of mad scientists in a lab to a hybrid: half research and half a consumer-grade product machine, with different teams having different goals and rhythms. And he needed new explorations.
This final letter serves as a reminder from an observer's perspective: OpenAI is not a cold AGI factory but a group of people using an almost extreme speed to turn ideas into products used worldwide.
He wrote, "Even just being a small screw in this giant machine is enough to make one sober and excited."
This sentence might resonate with everyone who has left, stayed, or is simply curious about OpenAI.
Original link: https://calv.info/openai-reflections
Below is Calvin's original reflection (translated by GPT):
Reflections on OpenAI
July 15, 2025
I left OpenAI three weeks ago. I joined the company in May 2024.
I want to share some of my thoughts because there's a lot of noise around what OpenAI does, but few firsthand descriptions of the actual cultural experience of working there.
Nabeel Qureshi wrote a great article, "Reflections on Palantir," where he delves into what makes Palantir unique. I want to do the same for OpenAI while my memories are still fresh. There's no business secret here, more some reflections on the current state of one of the most fascinating organizations in history during an extremely interesting period.
First, a disclaimer: There's no personal animosity in my decision to leave—in fact, I feel quite ambivalent about it. The transition from running my own project to being a part of an organization with 3,000 employees was difficult. Now I crave a fresh start.
It's entirely possible that the quality of work will draw me back. It's hard to imagine creating something as far-reaching as AGI, and LLMs are undoubtedly the technological innovation of this decade. I'm lucky to have witnessed some of these developments and been involved in the launch of Codex.
Obviously, these are not the company's views—as observations, they are my personal perspectives. OpenAI is a big platform, and this is just a small window into it for me.
Culture
The first thing to understand about OpenAI is its rapid growth. When I joined, the company had just over 1,000 employees. A year later, it surpassed 3,000, and I was in the top 30% in terms of tenure. Almost all leadership members work on content vastly different from 2-3 years ago.
Of course, rapid expansion brings various issues: how to communicate as a company, reporting structures, product release processes, people management and organization, hiring processes, and more. Cultural differences among teams are significant: some teams are always sprinting, some are overseeing large projects, and others maintain a more stable rhythm. There's no single OpenAI experience, and the timing of research, applications, and marketing departments varies greatly.
A special aspect of OpenAI is that everything—I mean everything—relies on Slack. No emails. During my entire tenure, I received only about 10 emails. If you're not good at organization, this can be extremely distracting. But if you can manage channels and notifications reasonably, it's quite feasible to use.
OpenAI places particular emphasis on a bottom-up approach in research. When I first joined, I started asking about the next quarter's roadmap. The response was, "It doesn't exist" (though it does now). Good ideas can come from anywhere, and it's often hard to predict in advance which ones will be the most fruitful. Rather than having a grand "master plan," progress is iterative, emerging gradually as new research findings come out.
Precisely because of this bottom-up culture, OpenAI also values competence and contribution highly. Leaders in the company have traditionally been promoted based on their ability to come up with good ideas and implement them. Many highly capable leaders are not adept at speeches or political maneuvering in all-hands meetings. These aspects are far less important at OpenAI than in other companies. The best ideas tend to prevail.
There's a strong bias towards action (you can just go and do things). Similar teams, though unrelated, often converge on various ideas. I initially worked on a parallel (but internal) project similar to the ChatGPT connector. There were probably about 3-4 different Codex prototypes circulating before we decided to push for a release. This work was often carried out by a small group of people without permission. As projects showed potential, teams would quickly form around them.
Andrey (head of Codex) once told me that you should view researchers as their own "mini CEOs." There's a strong tendency to focus on one's own thing and see how it turns out. Here's a corollary—most research is done by "geek-inducing" researchers to focus on a specific problem. If a problem is deemed boring or "solved," it likely won't be pursued further.
Excellent research managers are influential but also quite limited. The best managers can connect many different research efforts into larger model training. The same applies to excellent product managers (hats off to ae).
The ChatGPT product managers I worked with (Akshay, Rizzo, Sulman) are some of the coolest clients I've ever met. They seem to have seen it all. Most of them are relatively hands-off but hire great talent and strive to ensure their success.
OpenAI can quickly pivot directions. This is something we valued highly at Segment—doing the right thing as new information comes in is far better than sticking to the original path just because there's a plan. It's surprising that a company as large as OpenAI still maintains this spirit—Google, obviously, does not. The company makes decisions quickly and goes all in once it decides to pursue a direction.
The company faces a lot of scrutiny. As someone from a B2B business background, this shocked me a bit. I often saw news outlets breaking stories that hadn't been announced internally yet. When I told people I worked at OpenAI, I often encountered predetermined perceptions of the company. Some Twitter users run automated bots to check for upcoming feature releases.
Therefore, OpenAI is a very secretive place. I can't disclose details of my work to anyone. There are several Slack workspaces with different levels of access. Revenue and funding consumption data are even more tightly guarded.
OpenAI is also a more serious place than you might think, partly because the sense of risk is very high. On the one hand, the goal is to build Artificial General Intelligence (AGI)—which means many things must be done right. On the other hand, you're building a product that hundreds of millions of users rely on for everything from medical advice to psychotherapy. On another hand, the company is participating in the world's largest competitive arena. We closely monitor Meta, Google, and Anthropic—I'm sure they're doing the same to us. All major governments are closely watching this space.
Despite OpenAI often being vilified in the media, everyone I met was actually trying to do the right thing. Given its consumer-facing positioning, it's the most visible among large labs and thus bears a lot of slander.
That said, you probably shouldn't view OpenAI as a monolithic entity. I think OpenAI started out like Los Alamos Laboratory, a group of scientists and tech enthusiasts exploring the scientific frontier. This group accidentally spawned the most virally contagious consumer application in history. Subsequently, its development goals expanded to selling to governments and enterprises. People with different seniority and in different departments within the organization then had vastly different goals and perspectives. The longer you're there, the more likely you are to see things through the lens of a "research lab" or a "non-profit serving the public interest".
One thing I admire most about this company is that it "walks the talk" when it comes to distributing the benefits of AI. The most advanced models are not limited to the enterprise level requiring annual agreements. Anyone in the world can directly use ChatGPT to get answers, even without logging in. You can sign up and use the API—most models (even the most advanced or proprietary ones) usually enter the API soon for startups to use. You can imagine a mode of operation vastly different from the system we're in today. OpenAI deserves a lot of credit for this, which remains a core part of the company's DNA.
Security holds a paramount importance that might often be underestimated from reading materials by Zvi or Lesswrong. A vast array of individuals is dedicated to developing secure systems. Given OpenAI's nature, I observe a greater emphasis on practical risks (such as hate speech, abuse, manipulation of political biases, creation of bioweapons, self-harm, and prompt injection) than on theoretical risks (like intelligence explosion and power seeking). This is not to say that theoretical risks are ignored; there are certainly individuals focused on them. However, from my perspective, they are not the primary focus. Much of this work remains unpublished, and OpenAI should strive to release more of it.
Unlike other companies that casually distribute promotional items at every recruitment event, OpenAI rarely hands out swag, even to new hires. Instead, there are "drops" where you can order items that are in stock. The first drop generated such high demand that it crashed the Shopify store. There was even an internal post detailing how to properly POST JSON packets to bypass the limits.
GPU costs dwarf almost all other expenses. For instance, a niche feature developed as part of the Codex product had GPU costs comparable to our entire Segment infrastructure (while not on the scale of ChatGPT, it still managed a significant portion of internet traffic).
OpenAI is arguably the most ambitious organization I've ever encountered. One might think that having one of the top global consumer-grade applications would be sufficient, but they aspire to compete in numerous areas: API products, deep research, hardware, coding agents, image generation, and some yet-to-be-announced fields. It's a fertile ground for nurturing and advancing ideas.
The company pays close attention to Twitter. If you tweet something related to OpenAI that goes viral, chances are someone will see it and take it into account. A friend of mine joked that "this company runs on Twitter vibes." As a consumer-facing company, that's probably not entirely inaccurate. While they extensively analyze usage, user growth, and retention, the vibes also matter.
The team at OpenAI is more adaptable than elsewhere. When launching Codex, we needed help from a few experienced ChatGPT engineers to meet the release date. We met with some of the ChatGPT engineering managers to make the request. The next day, two exceptionally capable individuals were ready to lend a hand. There was no "waiting for the quarterly plan" or "realigning headcount" rigmarole; it moved swiftly.
Leadership is highly visible and deeply engaged. Perhaps obvious in a company like OpenAI, but every executive seems incredibly invested. You'll regularly see gdb, sama, kw, mark, dane, etc., actively participating on Slack. There are no absent leaders.
Code
OpenAI utilizes a massive single codebase primarily in Python (though there is an increasing number of Rust services and a smattering of Golang services for web proxies, etc.). This leads to significant variability in code style since there are many ways to write Python. You'll encounter everything from scalable libraries designed by ten-year Google veterans to ad-hoc Jupyter notebooks written by freshly minted PhDs. Almost everything revolves around creating APIs with FastAPI and validating with Pydantic, but there's no enforced code style guide overall.
All OpenAI services run on Azure. Interestingly, I'd say there are only three reliable services: Azure Kubernetes Service, CosmosDB (Azure's document store), and BlobStore. There's no real equivalent to Dynamo, Spanner, Bigtable, BigQuery, Kinesis, or Aurora. The mindset of auto-scaling units is also less prevalent. IAM implementations are generally less polished than AWS, and there's a strong bias towards in-house development.
In terms of personnel (at least in engineering), there has been a notable flow of talent from Meta to OpenAI. In many ways, OpenAI feels like early Meta: a blockbuster consumer application, nascent infrastructure, and a desire to grow rapidly. I've observed that most of the infrastructure talent who have moved over from Meta and Instagram are incredibly strong.
Taking everything into account, you'll find that many of the core infrastructure pieces evoke Meta. TAO has been internally reimplemented, efforts have been made to integrate authentication at the edge, and I'm sure there are many other projects I'm not privy to.
The notion of chat is deeply ingrained. Since ChatGPT's popularity, many codebases have been structured around the idea of chat messages and conversations. These fundamental elements are so embedded that ignoring them can be risky. We deviated slightly in Codex (drawing more from our experience with response APIs), but still leveraged a lot of existing artifacts.
Code wins. Rather than relying on a central architecture or planning committee, decisions are typically made by the teams planning to execute the work. The result is a very action-oriented culture where there are often multiple duplicated parts of the codebase. I've seen probably half a dozen libraries related to queue management or agent loops.
In several ways, the rapidly expanding engineering team and lack of tools created issues. sa-server (the backend monolith) became somewhat disorganized. Continuous integration (CI) failures on the main branch were much more frequent than expected. Even with test cases running in parallel and only considering partial dependencies, runs with GPUs could take around 30 minutes. These problems aren't insurmountable, but they serve as a reminder that these issues are common and can worsen during rapid expansion. To their credit, internal teams are taking this very seriously and working on improving the situation.
Other things I learned
This is what a large consumer brand looks like. I didn't fully realize it until we started developing Codex. All metrics are in units of "professional users." Even for a product like Codex, we primarily consider the onboarding experience for individual use, not team use. As someone primarily from a B2B/enterprise background, this was somewhat surprising for me. You flip a switch, and traffic floods in from day one.
Large model training (high-level overview). There's a spectrum from "experiment" to "engineering." Most ideas start as small-scale experiments. If the results look promising, they're incorporated into larger-scale training runs. Experiments involve not just tweaking core algorithms but also adjusting data mixes and scrutinizing results. At the large-scale training end, it almost resembles giant distributed systems engineering. You encounter all sorts of unusual edge cases and unexpected issues, and it's up to you to debug them.
How GPU computation works. As part of the Codex launch, we had to predict load capacity needs, and it was the first time I really spent time benchmarking GPUs. The key is to start with the required latency requirements (overall latency, number of tokens, first token time) rather than analyzing what performance the GPU can support from the bottom up. Every new model iteration can dramatically change load patterns.
How to work in a large Python codebase. Segment combined microservices, primarily using Golang and Typescript. We didn't have the scale of code that OpenAI does. I learned a lot about how to scale a codebase based on the number of developers. You have to put more safeguards in place for "works by default," "keeps the main branch clean," and "hard to misuse."
Launching Codex
A substantial portion of my last three months at OpenAI was spent on launching Codex. It was undoubtedly a major highlight of my career.
Background: As early as November 2024, OpenAI set a goal of launching a programming agent in 2025. By February 2025, we had some internal tools that were achieving notable results with the model. We felt pressure to launch a dedicated programming agent. Clearly, the model had evolved to the point where it was very useful for programming (evidenced by the proliferation of various programming assistant tools on the market).
I took my paternity leave early to come back and help with the Codex launch. A week later, we underwent a (somewhat chaotic) merger of two teams and then embarked on a frenetic sprint. From writing the first line of code to completion, the entire product took just 7 weeks.
The Codex sprint was probably the hardest I've worked in a decade. Most nights were until 11 PM or midnight. Woken up by a newborn at 5:30 AM every morning. Back in the office at 7 AM. Most weekends were also work. We were all-in as a team because every week mattered. It reminded me of my time at Y Combinator.
The speed was incredible. I've never seen an organization, large or small, go from an idea to a fully launched and freely available product in such a short time. The scope wasn't small either; we built a container runtime, optimized codebase downloads, fine-tuned a custom model to handle code editing, handled various git operations, introduced a brand new interface, enabled internet access, and ended up with a product that was a joy to use.
No matter what you say, OpenAI still embodies that pioneering spirit.
The good news is that the right people can work miracles. We were a crack team of about 8 engineers, 4 researchers, 2 designers, 2 marketing folks, and 1 product manager. Without this team, I think we would have failed. No one needed much direction, but there was definitely a fair amount of coordination required. If you have the opportunity to work with anyone from the Codex team, know that they are all incredibly talented.
The night before the launch, five of us stayed up until 4 AM trying to deploy the main monolith (a process that took hours). We then went back to the office to prepare for the 8 AM announcement and live stream. We flipped the feature switch and started seeing traffic flood in. I've never seen a product grow so quickly just by appearing in the left sidebar, but that's the power of ChatGPT.
In terms of product shape, we landed on a fully asynchronous form. Unlike tools like Cursor (which now supports a similar mode) or Claude Code at the time, our goal was to enable users to start tasks and have the agent run in its own environment. Our bet was that in the end, users should treat coding agents like colleagues: they send a message, the agent has time to work, and then comes back with a PR.
It's a bit of a gamble: we're in a somewhat awkward state where the models are good but not great. They can work continuously for minutes but not yet hours. There's a lot of variability in how much users trust the model's capabilities. And we don't even know yet how strong the models' true capabilities are.
In the long run, I do believe most programming will look more like Codex. In the meantime, it will be fascinating to see how all the products unfold.
Codex is (perhaps not surprisingly) very adept at working in large codebases and understanding how to navigate them. The biggest difference I've seen compared to other tools is its ability to start multiple tasks simultaneously and compare their outputs.
I recently saw public data comparing the number of PRs submitted by different LLM agents. Just from public data, Codex has generated 630,000 PRs. That's about 78,000 public PRs per engineer on average in the 53 days since launch (you can extrapolate the multiplier for private PRs yourself). I'm not sure I've ever worked on a project with such impact in my life.
Closing thoughts
Honestly, I was a bit hesitant about joining OpenAI initially. I wasn't sure what it would be like to give up freedom, have a boss, and be a tiny part of a massive machine. I kept my joining quiet in case it didn't work out.
I did want to get three things out of the experience:
1. Develop an intuitive understanding of how models are trained and where their capabilities are headed
2. Work with and learn from exceptional talent
3. Ship a great product
Looking back on the year, I think it was one of the smartest decisions I've made. It's hard to imagine learning more elsewhere.
If you're a founder and feel like your startup isn't really going anywhere, you should either 1) deeply reassess how to add more shots on goal or 2) go join a large lab. It's a fantastic time to start a company, but it's also an excellent time to gain insights into where the future is headed.
In my view, the path to AGI is currently a three-horse race: OpenAI, Anthropic, and Google. Each organization will take a different path based on their DNA (consumer-facing, enterprise-facing, strong infrastructure plus data). Working at any of them would be an eye-opening experience.
Thanks to Leah for being incredibly supportive and taking on most of the parenting duties during late nights. Thanks to PW, GDB, and Rizzo for giving me this opportunity. Thanks to the members of the SA team who taught me the ropes: Andrew, Anup, Bill, Kwaz, Ming, Simon, Tony, and Val. And thanks to the Codex core team for taking me on an unforgettable journey: Albin, AE, Andrey, Bryan, Channing, DavidK, Gabe, Gladstone, Hanson, Joey, Josh, Katy, KevinT, Max, Sabrina, SQ, Tibo, TZ, and Will. I'll never forget this sprint.
Whenever a leader leaves, it's easy to read into the drama, but I think about 70% of it is just that fact.
I do think we're at a slight inflection point. The company is hiring a lot of senior leadership from outside. I support this in general and think the company has benefited greatly from infusing new external DNA.
I get the sense that scaling the fastest-growing C-side product of all time tends to build up strong muscles.
Of course, we're also standing on the shoulders of giants. The CaaS team, the core reinforcement learning team, human data, and general application infrastructure made all of this possible.
We've also been persistent.
A few weeks ago, we saw some significant hires at Meta. xAI launched Grok 4, which performs well on benchmarks. Mira and Ilya are both incredibly talented. Maybe this will change the landscape (these folks are excellent). They still have some ground to catch up on.
-
![]()
Maxwell Technologies Gains Indirect Stake in Precision Optics via New Venture
-
![]()
Raising 1.8 Billion! This Domestic Optical Inspection 'Little Giant' is Going Public
-
China's AI 'Normandy Moment': The Explicit and Implicit Threads of BATL
-
![]()
Starting at 4999 Yuan! Nubia RedMagic Gaming Tablet 5 Pro Review: Impressive Performance, But Hefty Price Tag
-
![]()
ByteDance Initiates First Major Management Reform
-
![]()
AI is Quietly Destroying a Trillion-Dollar Industry
-
![]()
A Whopping 30 Billion Yuan Investment: Qingdao Kicks Off Another Major Central Enterprise Project
-
![]()
5G Standalone Private Network Policy Breaks the Ice, Creating an Exclusive 'Nervous System' for Physical AI in Industrial Scenarios