Embodied Intelligence VLA Struggles in the "Data Quagmire": Can Human Activity Video Data Provide a Breakthrough?
 08/04 2025
08/04 2025
 590
590
Preface
Despite significant advancements, current Vision-Language-Action (VLA) models exhibit substantial performance degradation in new scenarios and interactions with complex objects, trailing behind large multimodal models (LMMs) like LLaVA in following instructions.
This limitation arises from the reliance of existing VLA models on synthetic data with an inherent sim-to-real gap or limited-scale laboratory teleoperation data lacking diversity, making them unsuitable for high-dexterity tasks and limiting their generalization to new scenarios.
1) Synthetic Data: Researchers have attempted to obtain low-cost synthetic data using simulators, but the limited diversity and unresolved sim-to-real discrepancies hinder the practical deployment of dexterous hands.
2) Teleoperation Data: The scale of this data lags far behind the training data of internet-scale LMMs, trapping embodied intelligence in a persistent "data quagmire." For dexterous hands, this data scarcity is particularly acute due to operational complexity and hardware costs, limiting most VLA models to simple grippers. However, these end-effectors have limited degrees of freedom, failing to achieve the precise finger control required for complex interactions or nuanced force adjustments.
How can the data challenges faced by embodied intelligence be overcome? The paper "Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos," jointly published by Peking University, Renmin University of China, and Beijing BeingByond Technology Co., Ltd., presents an intriguing approach.
The paper suggests that to break the data bottleneck, human activity videos offer a new avenue for VLA training – abundant real-world data with minimal real-world discrepancies. While implicit learning methods (e.g., contrastive learning, masked autoencoders, latent action modeling) have been employed to enhance robotic skills, their learning mechanisms and transfer effects remain unclear.
Notably, these methods fail to replicate the performance leap seen in the LLM/LMM domain, such as the breakthrough effect of visual instruction tuning in LLM/LMMs. This gap may stem from fundamental differences in data structure – in large language models and LMMs, pre-training and downstream training data are isomorphic, enabling seamless adaptation of text reasoning and language tasks, with visual-text understanding naturally transferring to multimodal tasks.
In contrast, VLA exhibits heterogeneity – a significant gap exists between text/2D visual inputs and 3D action spaces with embodied perception demands.
Therefore, researchers analyzed the success factors of visual instruction tuning and proposed a new paradigm, physical instruction tuning, to train the dexterous Vision-Language-Action model – Being-H0.
This model establishes the human hand as a universal benchmark for downstream manipulation (i.e., the human hand as the "base manipulator"), enabling robots to learn diverse skills from online videos. It is the first time an extensible, strongly generalized VLA model has been pre-trained through explicit action modeling of large-scale human videos.
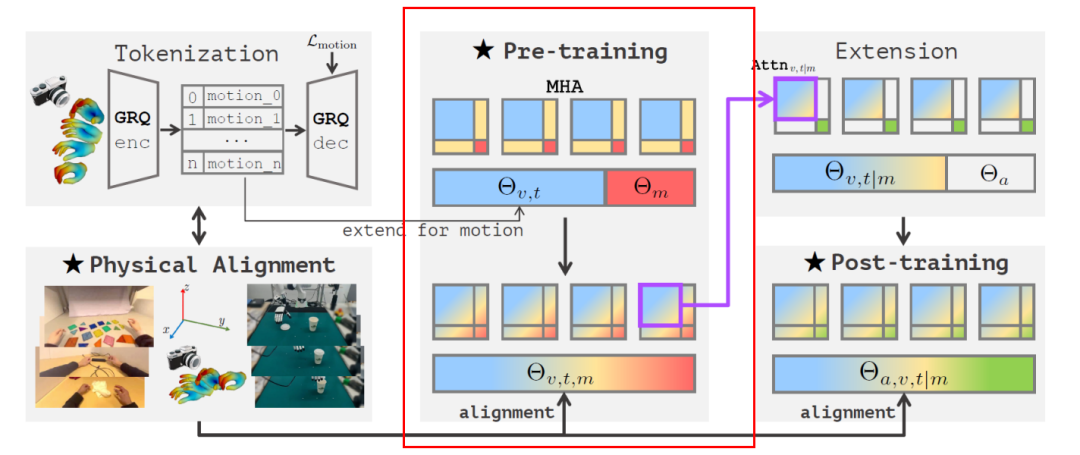
As shown in the figure below, the physical instruction tuning paradigm comprises three key components: human video-driven VLA pre-training, physical space alignment for 3D reasoning, and post-training adaptation for robotic tasks.
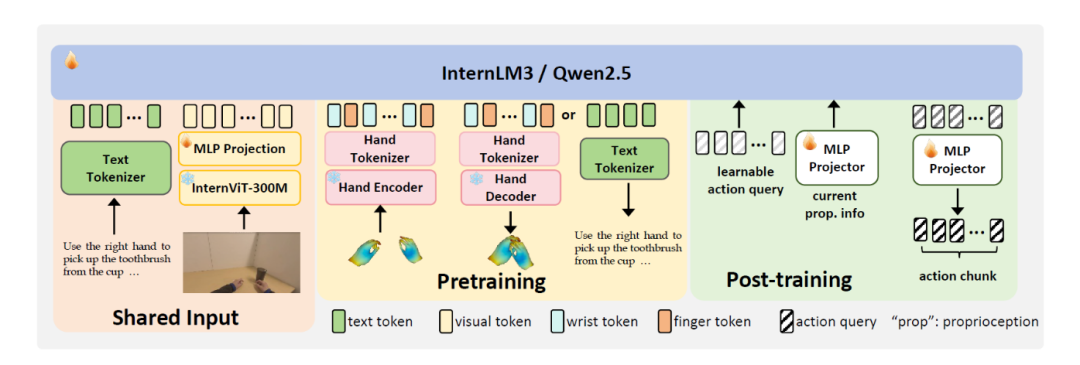
Three Key Components of Being-H0 Model's Physical Instruction Tuning
Note: The text tokenizer and visual encoder are shared during pre-training and post-training. For pre-training and hand motion/translation tasks, Being-H0 generates outputs autoregressively. For post-training and downstream manipulation tasks, Being-H0 introduces a set of learnable query vectors as action blocks for prediction.
Additionally, the paper proposes a part-level action tokenization technique to model precise hand trajectories with millimeter-level reconstruction accuracy. To support this framework, researchers constructed a unified data preparation pipeline integrating motion capture data, VR interaction records, and pure RGB videos, forming a large-scale dataset containing millions of action-driven instruction instances – UniHand.
I. Three Key Components of Physical Instruction Tuning
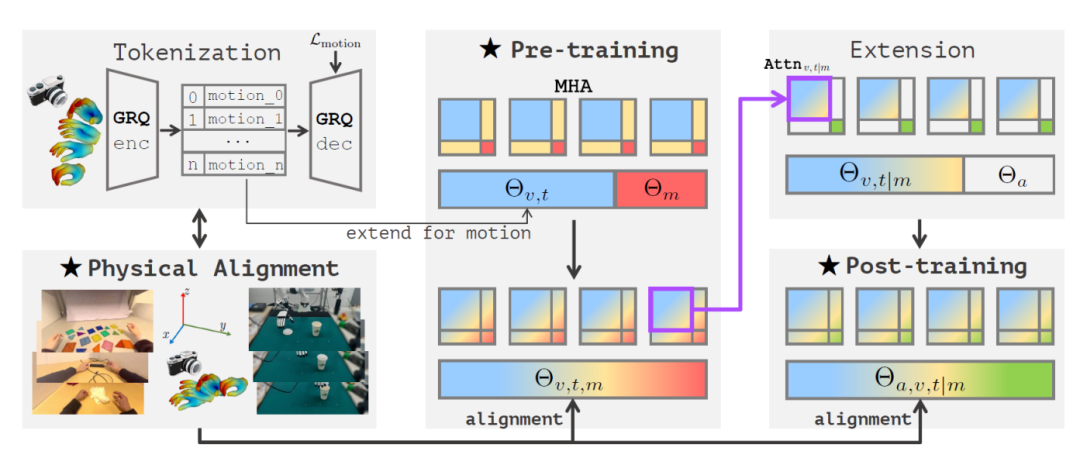
Being-H0 Model's Physical Instruction Tuning Process
Through unified physical instruction tuning, a bridge is built between human video datasets and robotic manipulation.
1) Left of the figure: Part-level motion tokenization – converting continuous hand motion into discrete tokens. Physical space alignment unifies heterogeneous data sources – from human hand demonstrations in videos (datasets) to real robot data – through coordinate system alignment and MANO parameterization, creating consistent representations for pre-training and post-training supervision.
2) Middle of the figure: During pre-training, the visual-text parameters Θv,t are extended to incorporate motion parameters Θm, enabling multi-head attention interactions among visual, text, and motion tokens within a unified sequence. Visual and text attention is represented in blue, motion attention in red, and cross-modal attention in yellow.
3) Right of the figure: The expansion stage demonstrates how the attention mechanism adapts pre-trained cross-modal dependencies (Attv,t|m), followed by the post-training stage, which incorporates action parameters Θa to generate the final VLA model with parameters Θa,v,t|m for downstream robotic tasks. Action attention is represented in green.
1. Pre-training
Existing LMMs excel in multimodal reasoning but underperform when adapted as VLAs for manipulation tasks. This is due to a fundamental mismatch between pre-training and downstream task data.
To bridge this gap, researchers leveraged the structural similarity between human and robotic manipulators, introducing hand motion generation pre-training. This pre-training method treats the human hand as an ideal manipulator, with robotic manipulators viewed as simplified versions.
Pre-training uses a multimodal dataset: D = {(v, t, m)} to train the base VLA to predict hand motion based on visual input and language instructions.
Here, v represents visual input, t represents language instructions, and m = {θ, rrot, τ, β} represents motion data parameterized based on the MANO model (including joint angles θ, wrist rotation rrot, translation τ, and hand shape β). Each sample is considered an instruction-execution pair {XQ, XA} and trained through the following optimization objective:
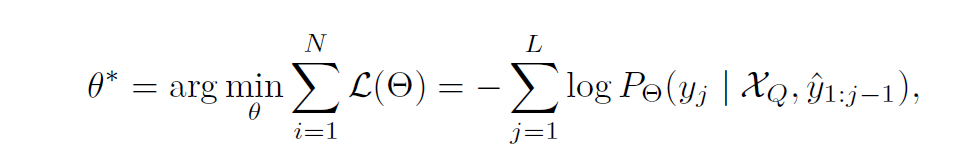
Where Θ represents the base model, and XA = {y} contains target tokens from text and motion modalities. This unified framework supports flexible task definitions, including visual-to-motion generation, motion description generation, and multimodal conditional generation for diverse hand-object interaction scenarios.
1) Model Architecture
Being-H0 is built upon pre-trained LMMs, adopting the InternVL3 architecture. The backbone network comprises two main parts: a pre-trained InternViT-300M as the visual encoder and a 2-layer MLP as the projector. At each time step, the model processes image-text pair inputs to predict hand motion sequences.
A dynamic high-resolution strategy is employed, dividing input images into multiple patches while maintaining the aspect ratio to minimize distortion, thereby preserving fine visual details.
Additionally, hand motion is treated as a "foreign language" to facilitate seamless integration with LMMs. During pre-training, the hand motion token generator quantizes continuous motion features into discrete embeddings. To integrate motion tokens into the LMM backbone, the model's vocabulary is extended with K discrete codes from a motion codebook. Furthermore, two special tokens [MOT_START] and [MOT_END] are introduced to mark the boundaries of motion blocks.
2) Hand Motion Tokenization
The motion tokenizer aims to encode hand features M = {m1, m2, ..., mT} containing T frames in the original motion sequence into ⌈T/α⌉ token embeddings of dimension d, where α represents the temporal downsampling rate.
a. Motion Features
The 3D MANO model is used to represent hand poses, parameterized as m = {θ, rrot, τ, β}. Five alternative representations are explored in this paper:
MANO-D51: Each frame of hand motion is encoded as m∈R¹⁵⁹, including θ∈R¹⁵׳, rrot∈R³, and τ∈R³, where θ and rrot are represented in axis-angle form.
MANO-D99: Each frame of hand motion is encoded as m∈R²¹³. Unlike MANO-D51, this representation uses 6D rotations (θ∈R¹⁵×⁶ and rrot∈R⁶) instead of axis-angle form.
MANO-D109: Extends MANO-D99 by incorporating shape parameters β∈R¹⁰.
MANO-D114: Extends MANO-D51 by adding joint positions j∈R²¹×³. Note that joint positions are only used as auxiliary features during reconstruction training, with only the 51-dimensional parameters used during evaluation and inference.
MANO-D162: Similar to MANO-D114, extends MANO-D99 by adding joint positions j∈R²¹×³.
The paper mentions that 6D rotation features perform better in reconstructing finger joint rotations, while axis-angle features excel in wrist pose reconstruction. Researchers attribute this to the structural characteristics of different hand parts – the wrist typically exhibits larger but simpler rotations, where the simplicity and computational efficiency of axis-angle representation are advantageous. In contrast, finger rotations involve finer details better captured by the continuity and numerical stability of 6D rotation representation.
Although the overall reconstruction error is lower when using axis-angle features due to the dominant influence of wrist pose errors, researchers ultimately selected 6D rotation features for the hand motion token generator due to its superior performance in Being-H0 training.
A possible explanation is that LMMs relatively easily learn wrist pose patterns but face greater challenges in modeling fine finger motions. Therefore, in this study, MANO-D162 is selected as the feature for hand motion.
Additionally, researchers plan to explore combinations of axis-angle features for the wrist and 6D rotation features for the fingers in future work.
b. Grouped Residual Quantization
The precision of the motion token generator critically impacts the quality of the generated hand motion and the transferability of learned motion priors to downstream manipulation tasks. To ensure optimal performance, researchers meticulously designed a token generator specifically for hand motion, based on the Grouped Residual Quantizer Variational Autoencoder (GRQ-VAE), as shown in the figure below.
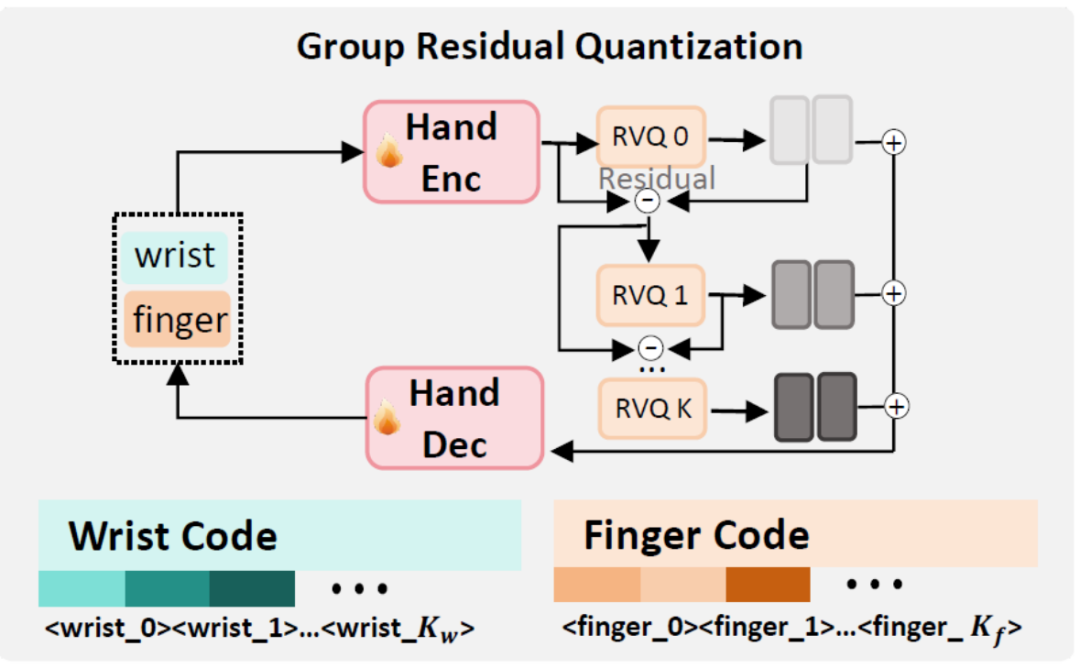
GRQ-Based Part-Level Hand Motion Tokenization
c. Part-Level Motion Token Generator
Given the higher complexity of wrist parameter reconstruction compared to finger motion, researchers designed separate token generators for wrist and finger parameters, enabling each to better model part-level features.
Specifically, hand motion features m = {θ, rrot, τ, β} are decomposed into wrist motion {rrot, τ} for global pose and precise localization, and finger motion {θ, β} for fine manipulation.
This part-level tokenization not only improves feature modeling but also provides clear token semantics, enabling the LMM backbone to better capture structured hand dynamics. When using the part-level token generator, the wrist loss Lwrist is omitted.
3) Multimodal Integration
Similar to traditional LLMs, output is generated using next token prediction. Being-H0 processes the three modalities – RGB vision, text, and hand motion – by unifying their tokenization (conversion to discrete tokens).
Text processing follows conventional LLM practices, while the processing of the other two modalities (vision and hand motion) is elaborated below.
a. Visual Tokens
Visual input requires special processing to address challenges of variable resolution images and dynamic content complexity. Given an input image, a dynamic patching strategy is first employed to generate N image patches based on image content complexity.
Following the design of InternVL, this patching strategy includes thumbnail generation to preserve global context: a downsampled version Ithumb (with a pixel shuffling ratio of 0.5) is always retained and processed in parallel with detail patches.
Visual processing: First, the visual encoder extracts features from these patches, which are then projected into a unified embedding space through an MLP layer.
Visual tokens are wrapped in sequence using boundary tokens [VIS_START] and [VIS_END], with [VIS_PLACEHOLDER] acting as a dynamic placeholder token replaced in real-time by actual visual embeddings during processing.
b. Motion Token
Before being integrated into the token stream, motion data undergoes quantization. For a motion feature sequence represented as M, the motion tokenizer quantizes it into a discrete token sequence {mi}.
The motion sequence forms motion blocks of 128 tokens per second through boundary marking and structural construction. This structural representation ensures clear boundaries for motion information within the token stream while maintaining compatibility with the Transformer architecture.
Multimodal Fusion: The model processes all modalities through a unified token space, employing shared embedding layers and attention mechanisms. During fusion, visual tokens replace placeholders, while motion tokens are inserted as structured blocks into the text sequence.
This generates a combined token sequence S = {si}, where each element si may represent text, visual, or motion content. The attention mechanism operates synchronously across modalities: for the concatenated multimodal hidden state Hv,t,m = [Hv; Ht; Hm] (representing visual, text, and motion embeddings, respectively), the query (Q), key (K), and value (V) are computed through shared projection weight matrices:
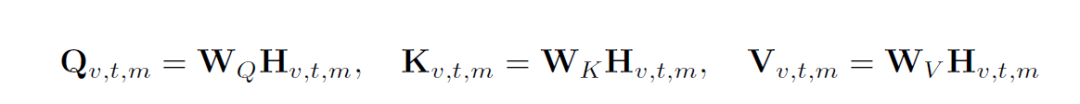
Where W{Q,K,V} represents the weight matrices. This architecture facilitates direct cross-modal attention, enabling the model to capture deep dependencies between modalities, such as associating visual observations with specific hand motions or linking language instructions to motion sequences.
During pre-training, motion parameters Θm are incorporated alongside the original visual-text parameters Θv,t, achieving unified processing of the three modalities through shared attention mechanisms. The model learns to generate coherent motion sequences by predicting discrete motion tokens within the broader context of visual observations and language instructions.
Physical Instruction Tuning Process
2. Physical Space Alignment
The aforementioned pre-training approach aims to bridge the gap between vision and action, establishing a foundational Visual-Language-Action (VLA) model. However, it faces unique alignment challenges beyond standard visual instruction tuning.
The primary difficulties arise from three aspects:
(1) Visual inputs from various sources exhibit differences in camera intrinsics and are captured in a dynamic world coordinate system.
(2) The model's backbone network is initialized with 2D visual-text pre-training, lacking crucial 3D spatial priors.
(3) Video data lacks fundamental physical attributes such as force and friction, which humans intuitively understand.
Unlike biological vision systems that naturally develop 3D perception through embodied experience, this paper explicitly calibrates these diverse data sources through physical space alignment, unifying observations into a consistent coordinate system and gradually instilling 3D reasoning and physical understanding abilities.
To construct a sufficiently large-scale dataset of dexterous human hand motion videos, samples must be collected from various datasets and public sources. However, this approach leads to differences in camera systems, posing challenges for effective pre-training. Additionally, existing Language-Multimodal Models (LMMs) have limited 3D perception capabilities.
To address this issue, the paper introduces physical space alignment techniques—a unified toolkit that maps videos from different cameras into a consistent physical space, integrating 3D spatial reasoning and physical attributes (if available) to enhance geometric and perceptual consistency across datasets.
Next, we introduce two physical space alignment strategies mentioned in the paper: weak perspective projection alignment and viewpoint-invariant action distribution balancing.
1) Weak Perspective Projection Alignment
Inherent differences in camera systems across data sources lead to inconsistent projections in 3D space. While humans can intuitively perceive depth and estimate grasping distances between hands and objects, models trained on such multi-source datasets often struggle to accurately map image projections to real 3D scenes, resulting in errors in 3D spatial reasoning.
To alleviate this, researchers establish a unified weak perspective camera space, ensuring consistent alignment from 2D visual content to a shared 3D reference frame. This approach maintains a uniform pixel scale for objects at similar depths, mitigating inconsistencies due to differences in camera intrinsics.
2) Viewpoint-Invariant Action Distribution Balancing
Cultivating robust instruction-following abilities in models requires meticulous preprocessing of instruction-tuning data to ensure balanced data distributions, especially for physical instruction tuning.
If a particular camera configuration dominates the dataset, it may bias the 3D perception system, ultimately limiting the model's generalization ability to unseen camera settings.
To mitigate this, researchers propose a novel distribution balancing strategy that augments video-action pairs from small-scale data sources to prevent them from being overshadowed by samples from large-scale sources. During balancing, hand pose distributions are adjusted without altering camera viewpoints and positions. Importantly, this method preserves the weak perspective consistency between actions from different data sources, ensuring coherent 3D understanding.
3) Other Considerations
In addition to the above strategies, the paper also suggests that integrating richer physical cues can further enhance the model's understanding of spatial and physical environments. For example, incorporating visual depth information, tactile feedback, or other multi-sensory signals can provide more grounded and realistic representations of human activities. These modalities complement information about physical interactions and 3D structures from different perspectives, which are often ambiguous or under-represented by 2D visual input alone.
This multi-sensory integration addresses fundamental limitations inherent in purely visual approaches. For instance, depth information from RGB-D sensors eliminates spatial ambiguity arising from weak perspective projections; tactile feedback captures critical contact dynamics, grip force, and material properties that are invisible in visual observations but crucial for successfully completing manipulations; and audio signals generated by object interactions can further distinguish between visually similar but physically distinct manipulation strategies, such as differentiating between gentle placement and forceful pressing actions.
These enhanced alignment strategies build more robust representations that more accurately capture the rich physical understanding naturally possessed by humans in manipulation tasks.
For larger and more diverse datasets, integrating such multimodal physical cues becomes increasingly important to bridge the gap between human demonstration data and reliable deployment of robots in various real-world scenarios.
3. Post-Training
After pre-training and physical space alignment, the foundational VLA model possesses comprehensive visual-language-action understanding abilities but needs to adapt to specific robotic manipulation tasks.
The post-training stage extends the model parameters from Θv,t,m to Θa,v,t|m, incorporating action parameters Θa to enable direct robot control while leveraging the rich multimodal representations learned during pre-training.
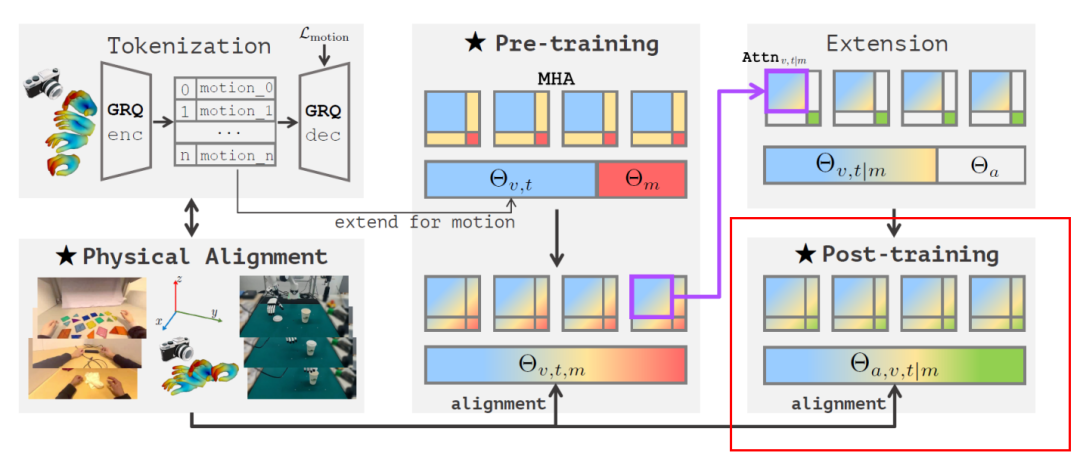
Physical Instruction Tuning Process
The kinematic differences between human hands and robotic dexterous hands/grippers prevent direct transfer of the foundational VLA model and its motion tokens. Researchers adopt a non-autoregressive MLP-based projection method to bridge this gap.
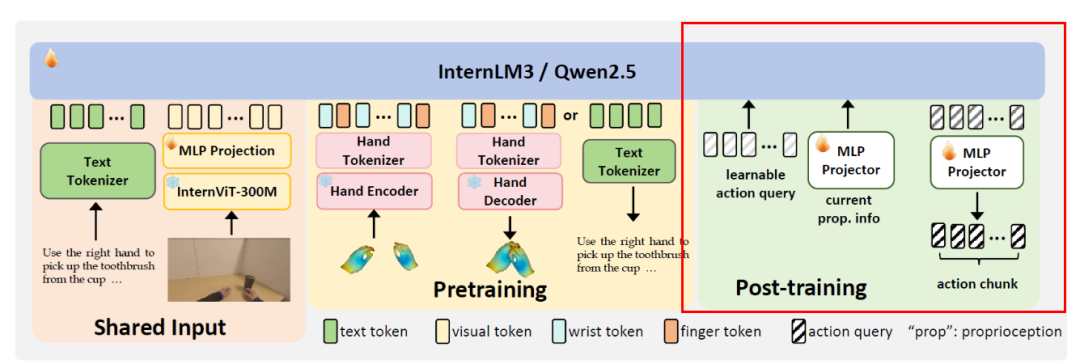
Three Key Components of Being-H0 Model Physical Instruction Tuning
The VLA backbone network serves as a pre-trained encoder, projecting the proprioceptive state of the dexterous hand into its embedding space through a lightweight MLP projection head (fp). This proprioceptive embedding is combined with visual-text tokens to form a unified context (ctx), enabling collaborative reasoning over sensory inputs, language instructions, and the current physical configuration.
For action generation, a set of learnable query tokens {q1, ..., qNa} is used, which attend to the aforementioned context within the pre-trained encoder. Simultaneously, a regression policy head MLP (fr) converts the output of the pre-trained encoder into executable dexterous poses.
The post-training phase aims to reproduce expert demonstrations through imitation learning. This approach effectively upgrades the pre-trained foundational VLA model to one that can generate robot-executable control instructions, while retaining cross-modal reasoning abilities and supporting multiple tasks, such as generating actions from visual-text inputs, describing observed actions based on text, and adapting robot control through domain-specific fine-tuning.
II. UniHand: Hand Action Instruction Dataset
1. Dataset Sources
1) The dataset sources primarily come from three channels:
Motion Capture Datasets: These contain high-precision 3D annotations from multi-view motion capture systems in controlled environments (e.g., studios, labs) but often have limited diversity. For example, OAKINK2 provides multi-view, object-centric recordings of real-world bimanual manipulations.
VR Recording Datasets: These utilize VR devices (e.g., Apple Vision Pro) to capture natural hand-object interactions in less constrained environments through calibrated cameras and SLAM-based tracking, while maintaining reliable 3D ground truth. An example is EgoDex, which includes up to 194 household manipulation tasks such as tying shoelaces and folding clothes.
Pseudo-Annotated Datasets: These generate pseudo-3D labels from real-world videos using off-the-shelf hand motion predictors. Although noisy, they excel in scalability and diversity. For instance, Taste-Rob contains about 100,000 first-person videos recorded from a fixed perspective, paired with aligned language instructions.
The UniHand dataset integrates information from 11 sources, including detailed hand motion annotations and corresponding RGB observations. It is massive, encompassing over 440,000 task trajectories, more than 130 million frames, and over 1,100 hours of video content.
Due to computational constraints, researchers extracted 2.5 million instruction data points from UniHand for pre-training. This subset, termed UniHand-2.5M, was selected based on a balanced sampling strategy to ensure diversity in task types and data sources, reportedly making it the largest first-person hand action dataset to date.
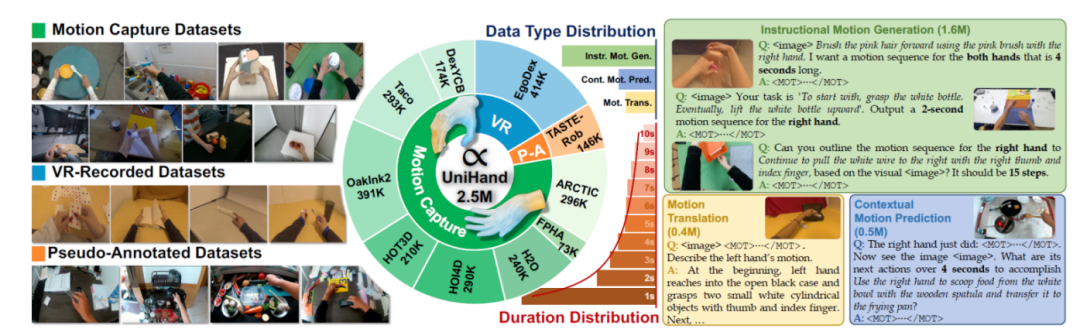
UniHand-2.5M Dataset
Note: The left side shows scenes and tasks from different data source types; the middle shows the distribution of different data sources, data types, and durations; the right side shows samples of different data types.
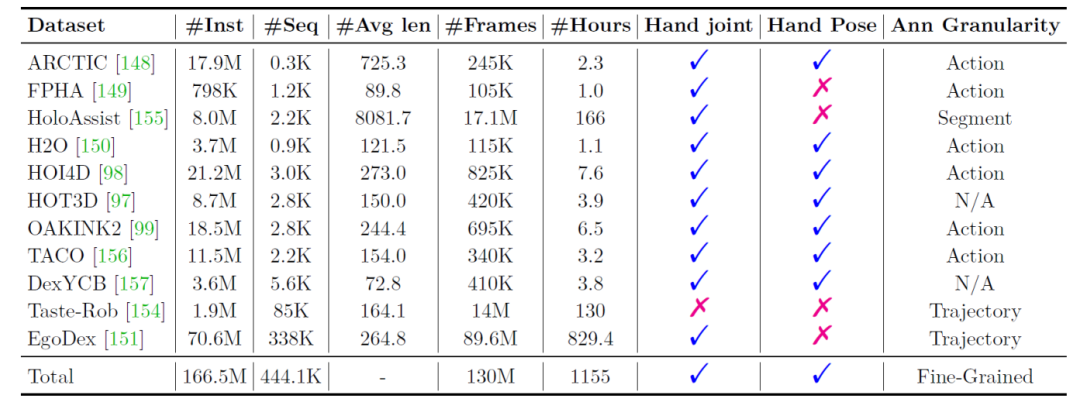
UniHand Dataset Information Statistics
Note: #Inst refers to the number of instruction samples generated for this study.
2. Data Preparation Process
1) Hand Pose Standardization
The model treats hand motions as 3D signals, learning an explicit mapping from 2D visual observations to 3D spatial coordinates to ensure geometric accuracy and visual-semantic consistency. To address the heterogeneity of motion labels across different datasets, hand pose standardization is required to integrate diverse data sources.
For datasets containing motion capture or SLAM tracking labels, annotations in MANO parameter form are directly extracted. When only 3D hand joint positions are available, corresponding MANO parameters are derived through a gradient-based optimization approach. If a dataset completely lacks 3D hand poses or joint annotations, HaMer is used for frame-by-frame pose estimation to maintain consistent motion semantics.
To enhance the reliability of HaMer outputs, left-right hand matching errors are detected and corrected by identifying pose discontinuities, followed by time interpolation to fill minor gaps. Additionally, joint angle constraints and temporal smoothing regularization are incorporated into the fitting process to ensure physically plausible and coherent hand motions.
2) Task Description Labels
To establish robust semantic associations between vision, language, and action, a structured hierarchical annotation framework is introduced, enriching action semantics and overcoming the sparsity or imprecision of text labels in existing datasets. This framework provides detailed and consistent text descriptions, enabling the VLA model to effectively align visual inputs, natural language instructions, and quantized hand motion representations.
To achieve structural coverage, each video is segmented into non-overlapping clips, each up to 10 seconds long, ensuring each clip captures a distinct stage of the task. Frames are then sampled at 2FPS, and annotations are generated at two temporal levels using Gemini-2.5-Flash-Lite: at the clip level, imperative instructions and concise summaries are generated, describing overall hand activities and object interactions;
At a finer, per-second level, each clip is further divided into overlapping 1-second windows, annotated with precise instructions and descriptions detailing contact states, object properties, hand parts, and motion trajectories relative to the camera perspective.
To ensure clarity and completeness, annotations are made separately for global bimanual actions and individual hand actions, capturing both bilateral and unilateral descriptions. This multi-scale annotation strategy ensures comprehensive and consistent coverage, bridging high-level task goals with fine-grained hand-object interactions within a unified framework.
3) Instruction Data Generation
Based on systematic annotation efforts, instruction-following training data is constructed, aiming to establish rich visual-language-action alignment relationships for the foundational VLA model. To this end, designed instruction tasks focus on multiple interrelated aspects of hand motion understanding, including spatio-temporal alignment of hand trajectories with visual contexts, precise object properties and contact states, clear action intentions, and consistency between high-level instructions and fine-grained action steps.
Following these principles, training data was developed for three complementary task types:
(1) Directive Action Generation: The model learns to generate step-by-step action sequences under the constraints of scene images and task instructions.
(2) Motion Translation: The model is required to translate motion sequences and visual cues into linguistic text describing hand-object interactions.
(3) Context-based Motion Prediction: The model predicts subsequent action sequences based on prior action history, current scene observations, and optional instructions or task goals.
During implementation, we crafted approximately 20 base templates tailored to each task type, leveraging the Gemini-2.5-Pro to generate a diverse array of instructional variants. Each template explicitly includes target duration specifications, empowering the model to handle varying temporal granularities and sequence lengths. Through rule-based instantiation, these templates are enriched with associated instructions, action tokens, and explicit length constraints.
To ensure a balanced distribution of visual perspectives in the training set, we employed a viewpoint-invariant action distribution balancing method to augment the data. Utilizing this balanced dataset, we generated over 165 million high-quality instruction pairs, encompassing multiple time scales, hand configurations, and manipulation scenarios. Systematic quality checks were conducted to ensure semantic coherence.
To further balance the distribution of data sources and task types in the training data, we extracted a subset of 2.5 million instances from the full dataset, providing more even coverage of task categories and data sources.
For the UniHand-2.5M dataset, the sample proportions generated from viewpoint-balanced data are illustrated below. This unified design provides robust supervision for the model, enabling it to learn consistent mappings between vision, language, and structured actions, inclusive of both two-handed and one-handed hand-object interactions.
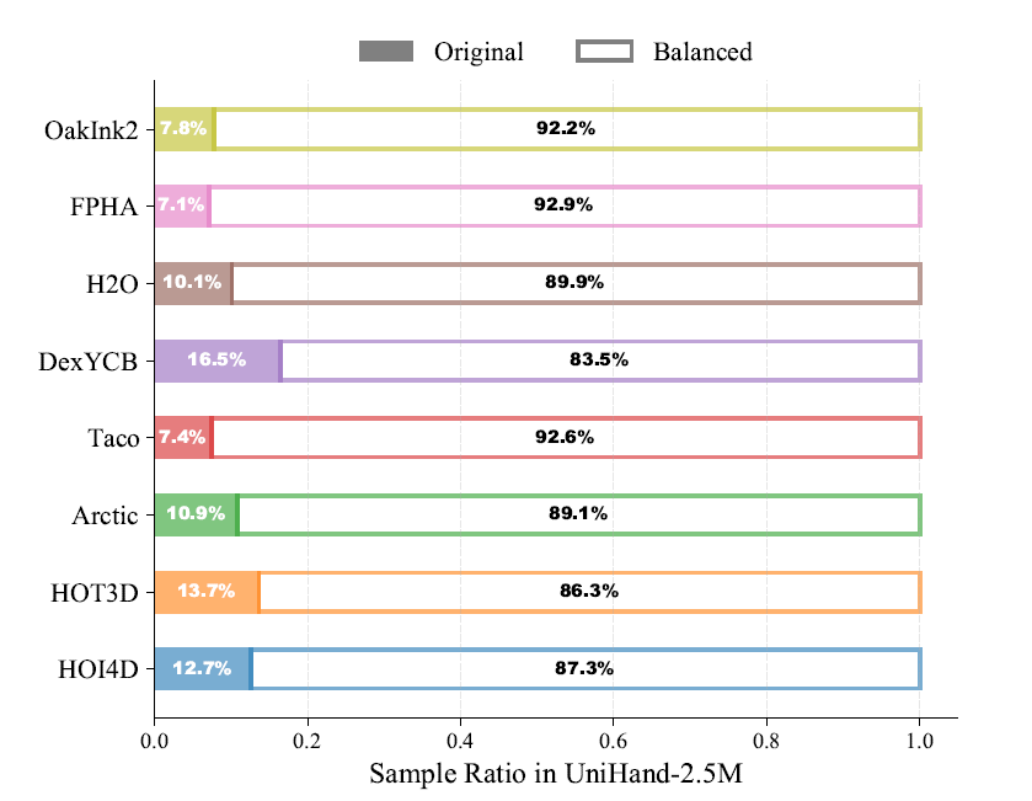
Sample Proportions in the UniHand-2.5M Dataset
In summary, this structured multi-scale annotation framework ensures comprehensive and consistent coverage of high-level task objectives and fine-grained hand-object interactions, providing rich action data for downstream modeling and analysis.
III. Core Issues and Solutions
1. Two Core Issues
1) Can large-scale human activity videos support the pre-training of dexterous vision-language-action models, enabling them to explicitly understand and imitate human actions, akin to how GPT-3 learns language through large-scale pre-training?
2) Can such pre-trained models effectively transfer their capabilities to robotic manipulation tasks through post-training adaptation?
To address these issues, several key challenges must be overcome. Below, the paper delves into these difficulties and outlines corresponding solutions.
2. Solutions
1) Pre-training Data Preparation
In contrast to Natural Language Processing (NLP) and Computer Vision (CV) fields, current Vision-Language-Action (VLA) models face a significant data scarcity issue. Existing datasets like Open X-Embodiment and AgiBot are several orders of magnitude smaller than multimodal benchmark datasets and primarily focus on end-effector control, neglecting fine-grained finger coordination due to hardware constraints.
Human activity videos have the potential to mitigate this issue, but their potential remains largely untapped as most methods focus on implicit alignment (e.g., latent action optimization in GR00T N1.5), with limited substantiated benefits.
Recently, research has begun exploring text-to-motion generation based on precisely annotated laboratory datasets. However, these data are limited in scale, lacking diversity and generalization capabilities. Conversely, in-the-wild datasets (e.g., Ego4D) offer scale advantages but grapple with camera inconsistency and motion granularity issues.
In this paper, we systematically integrate these heterogeneous data sources through MANO parameter normalization and weak perspective alignment, constructing a unified dataset encompassing over 150 tasks spanning over 1000 hours.
2) Precise Hand Motion Quantization
This study treats hand motion as a 'foreign language,' posing a critical question: 'Can discrete action tokens maintain sufficient precision for motion prediction?' While prior research suggests quantization can disrupt pose continuity and precision, through meticulous design, our vector quantization (VQ)-based token generator achieves millimeter-level reconstruction accuracy.
Specifically, we utilize a one-dimensional convolutional encoder to discretize continuous MANO motion sequences M∈RT×D, generating feature maps z∈R⌈T/α⌉×d as follows:
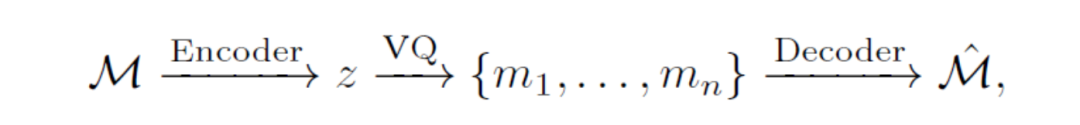
Where T represents the number of frames, and α is the temporal downsampling rate. Action tokens mi∈{, ..., } are separated by and , forming coherent action blocks to ensure seamless integration with text in the unified large multimodal model (LMM).
3) Unified Cross-modal Reasoning
To model the intricate relationships between visual observations, language instructions, and hand actions, we process all modal data into a unified token sequence S = {si}, where each token si can represent text, visual, or action information. Visual tokens replace the < IMG_CONTEXT > placeholder, while action tokens form coherent blocks within the sequence.
Cross-modal interactions are facilitated through a shared attention mechanism, where queries Qv,t,m, keys Kv,t,m, and values Vv,t,m are computed from the concatenated state Hv,t,m = [Hv; Ht; Hm]. This enables the model to learn rich multimodal dependencies, mapping visual scenes to manipulation strategies, associating language instructions with precise finger movements, and aligning temporal action patterns with task goals.
4) Adaptive Robot Control Transfer
Although the pre-trained Vision-Language-Action (VLA) model can generate continuous motions and maintain broad capabilities, directly transferring human hand actions to downstream manipulators presents challenges due to kinematic mismatches, degree-of-freedom differences, and physical constraints.
To validate the efficacy of learning from large-scale human videos, this paper adopts a simple projection method based on a Multi-Layer Perceptron (MLP), using a set of fixed learnable queries as action blocks for downstream manipulators.
Conclusion
Being-H0 is a dexterous vision-language-action (VLA) model trained on large-scale human videos, characterized by high scalability and sample efficiency. Its innovation lies in the adoption of a physical instruction fine-tuning paradigm, encompassing pre-training, physical space alignment, and post-training.
This study addresses four key challenges in learning dexterous manipulation from human demonstration videos:
Pre-training Data Preparation: Heterogeneous data sources are integrated through MANO parameter normalization and projection alignment techniques.
Hand Motion Quantization: The proposed grouped residual quantization scheme achieves millimeter-level reconstruction accuracy while seamlessly interfacing with language models, enabling isomorphic processing of actions and language.
Cross-modal Reasoning: Multimodal signals are unified into an autoregressive sequence, constructing complex cross-modal dependencies that connect visual scenes → manipulation strategies and language instructions → precise finger movements.
Robot Control Transfer: Through physical instruction fine-tuning, the kinematic differences between human hands and robotic manipulators are overcome, effectively transferring pre-trained multimodal representations.
Furthermore, this research lays the foundation for large-scale robot manipulation learning based on human videos and points to the following future research directions:
Deepening Physical Space Alignment: Enhancing transferability from human demonstrations to robot control by integrating depth perception information and tactile feedback, thereby improving the physical plausibility of manipulation skills.
Expanding to Complex Scenarios: Extending the Being-H0 model to tool use, multi-object interactions, and long-range reasoning scenarios, unlocking more challenging research frontiers.
Fusion of Simulation and Reinforcement Learning: Combining simulation environments with reinforcement learning frameworks to achieve more robust policy learning and safer real-world deployment.
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?