Kunlun Tech's UniPic 2.0 "Little Cannon" Model Creates a Stir: A Unified Solution for Understanding, Generation, and Editing
 08/14 2025
08/14 2025
 555
555

Large models have embarked on a new wave of iterative advancements.
Recently, from OpenAI unveiling GPT-5 to domestic players like Kunlun Tech, SenseTime, Baichuan Intelligence, and Wisdom Spectrum successively releasing their latest models. Among them, Kunlun Tech even hosted a technology week, launching a new model daily for five consecutive days. The third model introduced this week on August 13 is the multimodal unified model, UniPic 2.0.
UniPic 2.0 concentrates on seamlessly integrating the three core capabilities of image understanding, text-to-image generation, and image editing within a single model. This aligns precisely with the trending direction for multimodal technology this year—the convergence of understanding, generation, and editing.
Currently, most AI-generated images are challenging to modify post-creation, often leading to inadequate comprehension of secondary instructions, making each edit progressively more illogical.
However, when we tested UniPic 2.0's image editing capabilities, we were pleasantly surprised.
Recently, the popular meme "basic items shouldn't be paired with basic items, upper body basic, lower body not basic" emerged. We asked UniPic 2.0 to alter the lower body to a coordinating yet exaggerated outfit of the same color scheme, and it transformed the pants into a red poof skirt.

This model was already open-sourced on July 30, and the 2.0 version launched this time continues the strengths of the previous 1.0 version—"fast and good".
While other large models require tens of seconds to generate an image, UniPic 2.0 only takes a few seconds to render a complex "glass cat".
Unlike other open-source unified architecture multimodal models on the market, which often have extensive specifications with up to tens of billions of parameters, UniPic 2.0 boasts a parameter size of only 2B, making its response and generation speed an order of magnitude faster than its counterparts.

Despite its compact size, UniPic 2.0's expressive prowess in image generation, understanding, and editing remains formidable, even outperforming multiple open-source models with scales exceeding 10B in certain image editing-related metrics.
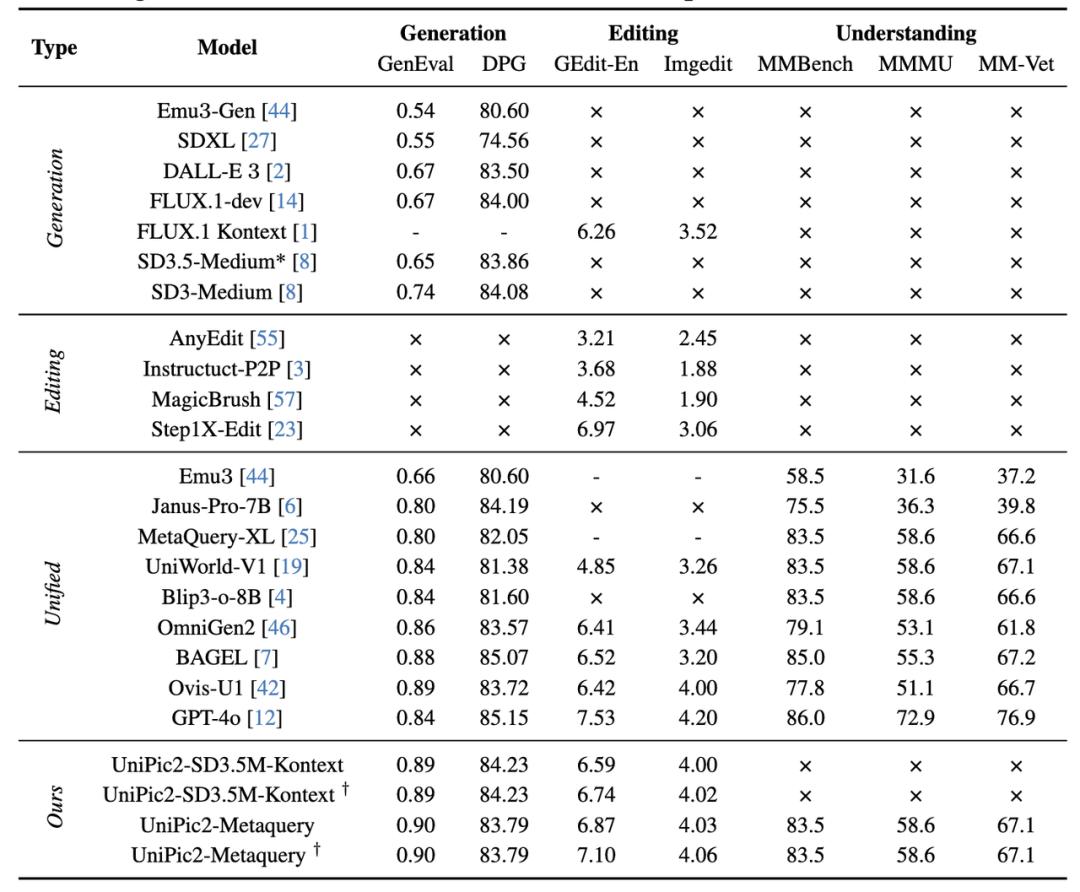
Starting with image generation, in terms of generation capabilities, UniPic 2.0's unified architecture version achieved a score of 0.90 on GenEval (testing the alignment between generated images and text), surpassing several open-source models and the closed-source GPT-4o (0.84). This demonstrates that UniPic 2.0 can maintain its high-performance edge despite its modest model size.
To test UniPic 2.0's text understanding and generation alignment, LightCone AI asked it and Bagel to each generate an image of a "Van Gogh-style tree". UniPic 2.0 provided a perfectly on-topic image, while Bagel's image even exhibited characteristics of a Christmas tree.

Image editing is where UniPic 2.0's performance truly shines. On the two key image editing task metrics of GEdit-EN and Imgedit, UniPic2 - SD3.5M - Kontext achieved scores of 6.59 and 4.00, respectively. The UniPic2-Metaquery series models performed even better, with the highest scores of 7.10 and 4.06, surpassing multiple open-source models including OmiGen2 and Bagel, essentially catching up to the closed-source GPT-4o.
For tasks such as image completion, erasure, subject consistency, and style transfer, LightCone AI provided multiple sets of prompts for evaluation.
We had already tested image modification earlier. We presented UniPic 2.0 with a landscape image and asked it to rotate the camera perspective 40 degrees to the right. The resulting image effect was quite stunning, even capturing the shadow cast by sunlight on the wall.

For more practical daily tasks like switching character backgrounds and erasing images, LightCone AI also arranged them for UniPic 2.0. This tests the effectiveness of large models in maintaining subject consistency.
We asked UniPic 2.0 to change the background of Ilya Sutskever, the former chief scientist of OpenAI, to a solid blue color. UniPic 2.0 swiftly "cut out" the character from the cluttered background and replaced it with a solid blue background resembling a one-inch photo in just 5 seconds.

We then asked the large model to add a beach coast background to the character with a solid color background. UniPic 2.0 seamlessly incorporated elements of the coast's sandy beach, sea, and coconut trees into the background.

Don't like a character blocking the view of a scenery? We gave UniPic 2.0 a photo dominated by a dog and asked it to erase the dog. The image generated by UniPic 2.0 was virtually identical to the original background, preserving the forest at the top and the dark area at the bottom right corner in the newly generated image.

In terms of style transfer, UniPic 2.0 can also handle various styles with ease. We first asked it to generate a cyberpunk-style image and then requested it to convert it to a Ghibli style. It adeptly transformed the cool robot into a protagonist from a Hayao Miyazaki film.

Most importantly, a model with a size of 2B can theoretically run on people's phones and computers, meaning that a usable, high-quality generative model is increasingly within reach of real-world deployment.
The core advantage of Kunlun Tech's Skywork UniPic 2.0 lies in compressing the model's generative architecture to 2B parameters, enabling the model to operate even with minimal computing power.
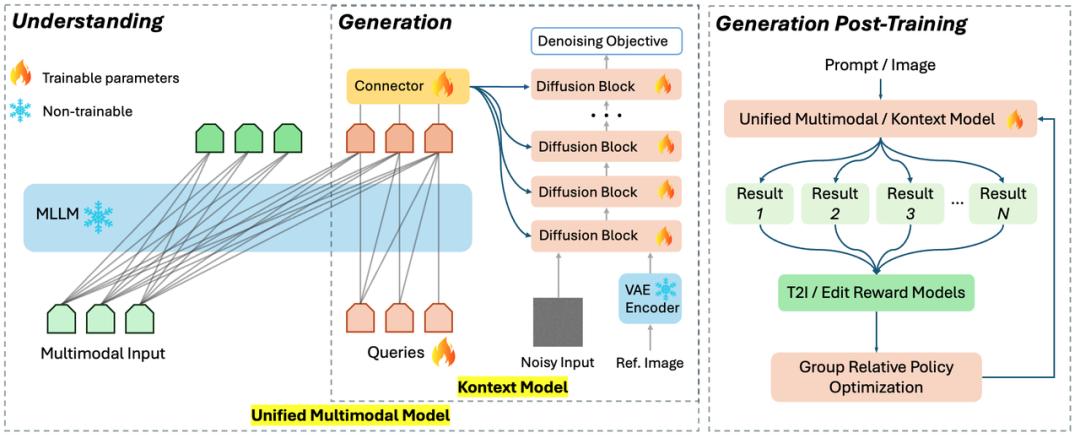
In terms of model architecture, Kunlun Tech opted for a unified architecture approach, accomplishing image editing, generation, and understanding within a single model.
For a long time, the AI field has adopted a "modular" strategy when tackling multimodal tasks: tasks like image understanding, text-to-image generation, and image editing are often handled by independent models or modules and then connected in series. This segmented architecture results in a lack of coordination between the various modules.
The consequence of "working in isolation" is that a model focused on image generation may not fully leverage image understanding information to optimize generation quality, and an image editing model may struggle to balance the semantics of text instructions during the editing process. This "isolated" model ultimately yields low test scores for various parameters, making it challenging to form a robust comprehensive ability.
In contrast, UniPic 2.0 employs a unified architecture that achieves a deep integration of the three major tasks of image understanding, generation, and editing. This integrated design allows the model to undergo collaborative training, fostering a more potent multimodal processing capability.
In fact, whether it's emphasizing native multimodality or integrating understanding and generation, these are cutting-edge directions being explored by the industry this year in the realm of multimodal large models. Although in the field of image generation, many companies still insist on a single architecture for commercialization reasons, the academic community and vendors dedicated to fundamental model research have actively explored technologies in understanding unified generation and native multimodality over the past year.
Models like Wisdom Source's OmniGen2, the multimodal reasoning model Step-3 released by StepStellar, and the BAGEL model open-sourced by ByteDance's Seed team all aim to enhance model generation capabilities through native multimodal frameworks or unified mechanisms for understanding and generation.
Additionally, in managing the performance advantages of multiple modules, Kunlun Tech has adopted an innovative multi-task reinforcement learning mode—"progressive dual-task reinforcement strategy" this time.
Traditional multi-task reinforcement learning often falls into the dilemma where optimizing one task impairs another. In response, Kunlun Tech first conducts specialized reinforcement for editing tasks and then, based on already aligned consistency editing, specializes in reinforcing the instruction compliance of text-to-image tasks. This mode ensures that the reinforcement learning processes of the two distinct tasks of text-to-image and image editing do not interfere with each other and can be improved simultaneously.
Ultimately, compared to models with a single architecture, the new unified architecture model significantly improves overall performance and generalization capabilities, allowing both generation quality and editing accuracy to be enhanced concurrently.
The generation module of the UniPic 2.0 model is trained based on the SD3.5-Medium architecture with 2B parameters. The 2B parameter size makes the UniPic 2.0 model very "lightweight" and holds the potential for deployment in various hardware environments, including personal computers, mobile phones, and other edge devices, thereby lowering the threshold for model application.
The 1.0 version of UniPic has already validated this possibility. Kunlun Tech stated that the model can run smoothly on RTX 4090 consumer-grade graphics cards.
A lightweight model translates to faster inference speed and lower computational resource consumption. It not only allows users to enjoy second-level response generation and editing experiences but also possesses the cost and environment for real-world deployment, becoming a truly "runnable" multimodal generative model.
In balancing AGI and pragmatic deployment, Kunlun Tech has consistently been a company with clear vision.
While the technical dividends of pursuing state-of-the-art (SOTA) are limited, in model competition, Kunlun Tech has carved out a unique comfort zone by focusing on cost-effectiveness and adhering to open source. This allows Kunlun Tech to maintain a technological edge while surpassing others in deployment, despite the competitive landscape of domestic giants.
Does it sound familiar? GPT-5 released by OpenAI a few days ago also employed a similar strategy, aiming to compete with the overseas top streamer Anthropic with a price that is 1/10 cheaper.
To achieve these goals, foremost, the technology must be robust. UniPic 2.0 has accomplished just that, with only 2B parameters but outperforming several models with the same architecture but larger parameters.
The benefit of this is that the computational resources required for UniPic 2.0 with 2B parameters during inference are greatly reduced, enabling the model to complete image generation and editing tasks at second-level speeds. For users, this speed is crucial—few are willing to wait for AI to run for tens of seconds or even minutes.
Smaller parameters also mean lower training and inference costs, which not only allows Kunlun Tech to spend less on the pursuit of SOTA but also reduces the cost for users each time they utilize it. For Kunlun Tech, which is currently focusing on overseas applications, UniPic 2.0 is undoubtedly a more cost-effective choice.
Simultaneously, an earlier decision—open source—has also supported Kunlun Tech in running faster in AI large model training.
The open-source storm sparked by DeepSeek has underscored the importance of open source for the evolution of model capabilities. As early as the end of 2022, Kunlun Tech was already aware of the significance of open source. From the earliest open-source algorithmic models for AI images, music, text, and programming, to the Skywork-13B series of large language models with tens of billions of parameters, to various multimodal large models, it can be said that Kunlun Tech has been a steadfast advocate of open source in the AI 2.0 era.
Open source not only fosters the gathering of more innovative ideas to feed back into model training but also allows Kunlun Tech to attract developers and users through its models, building brand influence.
From the results, Kunlun Tech's move was the right one.
In the July rankings of the internationally renowned open-source community HuggingFace, Kunlun Tech appeared among the Chinese companies listed alongside major players and the "Five Tigers". On this list, Kunlun Tech had two models ranked in the Top 100 of overseas model citations, one of which was the 1.0 version of UniPic.
By adhering to open source and pursuing SOTA in parallel, Kunlun Tech has avoided a direct clash with large players in terms of resources and instead found its own ecological niche through technological innovation and ecosystem construction.
After several years of racing to pursue AGI, Kunlun Tech has consistently been the keenest hunter. As the battle for large models intensifies, they are aiming for leadership in vertical categories by concentrating resources.
In the realm of models, Kunlun Tech has made its own choices—for instance, choosing to focus on deepening its expertise in the multimodal field.
The emergence of DeepSeek was one of the turning points for Kunlun Tech. In an interview, Fang Han, Chairman and General Manager of Kunlun Tech, mentioned that for general large models, they may choose to purchase externally. However, for some proprietary large models, they will train them in-house.
This time around, Kunlun Tech's five-day technology week serves as a showcase of their prowess in the multimodal domain, highlighting the accomplishments of their sustained deep exploration. From SkyReels-A3, an audio-driven portrait video generation model tailored for digital humans, to the highly anticipated embodied intelligent brain, the world model Matrix-3D, both embody the company's strategic vision: pushing boundaries while ensuring practical implementation.
Amidst the flurry of large model releases in August, Kunlun Tech managed to carve out a distinct niche for itself. In the current Chinese AI landscape, only a select few companies manage to sustainably capture the spotlight. This achievement underscores Kunlun Tech's ability to leverage strategic insights, maximizing outcomes despite limited resources.
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
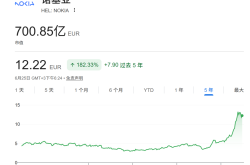
Why Is Nokia Making a Comeback in the AI Era?