The Underestimated AI Voice: The Next Wave of AI Commercialization
 08/14 2025
08/14 2025
 594
594
In the technology industry, a well-worn adage often resonates: "We tend to overestimate the short-term impact of technology while underestimating its long-term significance." This couldn't be truer when it comes to the evolution of AI voice technology. While its vocal prowess often captures our immediate attention, the transformative potential it harbors for businesses often goes unnoticed.
This transformation is unfolding on two fronts.
Firstly, in terms of interaction, traditional GUI (graphical user interface)-centric software is evolving towards a hybrid model that seamlessly integrates GUI with LUI (linguistic user interface). The advancement of AI voice technology is a key catalyst driving this shift, transforming it from a mere "auxiliary feature" into a smooth, natural, and efficient core interaction method.
Secondly, in content creation, AI voice technology is redefining the production paradigms of industries such as education, marketing, and audiobooks. For instance, AI marketing firm Icon leverages voice generation capabilities to mass-produce customized advertising audio, reducing the cost of each ad to less than $1, making personalized "thousands of voices for thousands of people" a tangible reality.
Technological advancements continuously push the boundaries of this business transformation, with iteration speed serving as the most vivid testament. AI voice technology seems to be on a perpetual fast-track, with each new generation swiftly surpassing its predecessor.
In April this year, MiniMax introduced the Speech-02 series of voice models. Just three months later, on August 7, it unveiled the all-new Speech 2.5, marking a leapfrog improvement in multilingual expression, timbre replication accuracy, and coverage of 40 languages. This breakthrough makes cross-language and cross-cultural immersive experiences feasible for large-scale implementation for the first time.
This evolution signifies that AI voice is transitioning from being merely "useful" to becoming "indispensable," transcending its functional role to become the underpinning infrastructure for the next generation of human-computer interaction and content creation. MiniMax finds itself at a pivotal juncture, poised to redefine the global AI voice landscape.
/ 01 / Breaking New Ground: The Arrival of the Most Advanced Voice Model
In May this year, MiniMax's Speech 02 topped both global authoritative rankings simultaneously, heralding the "era of voice personalization." For the first time, machines could "speak" with emotions, rhythms, and personalities akin to humans.
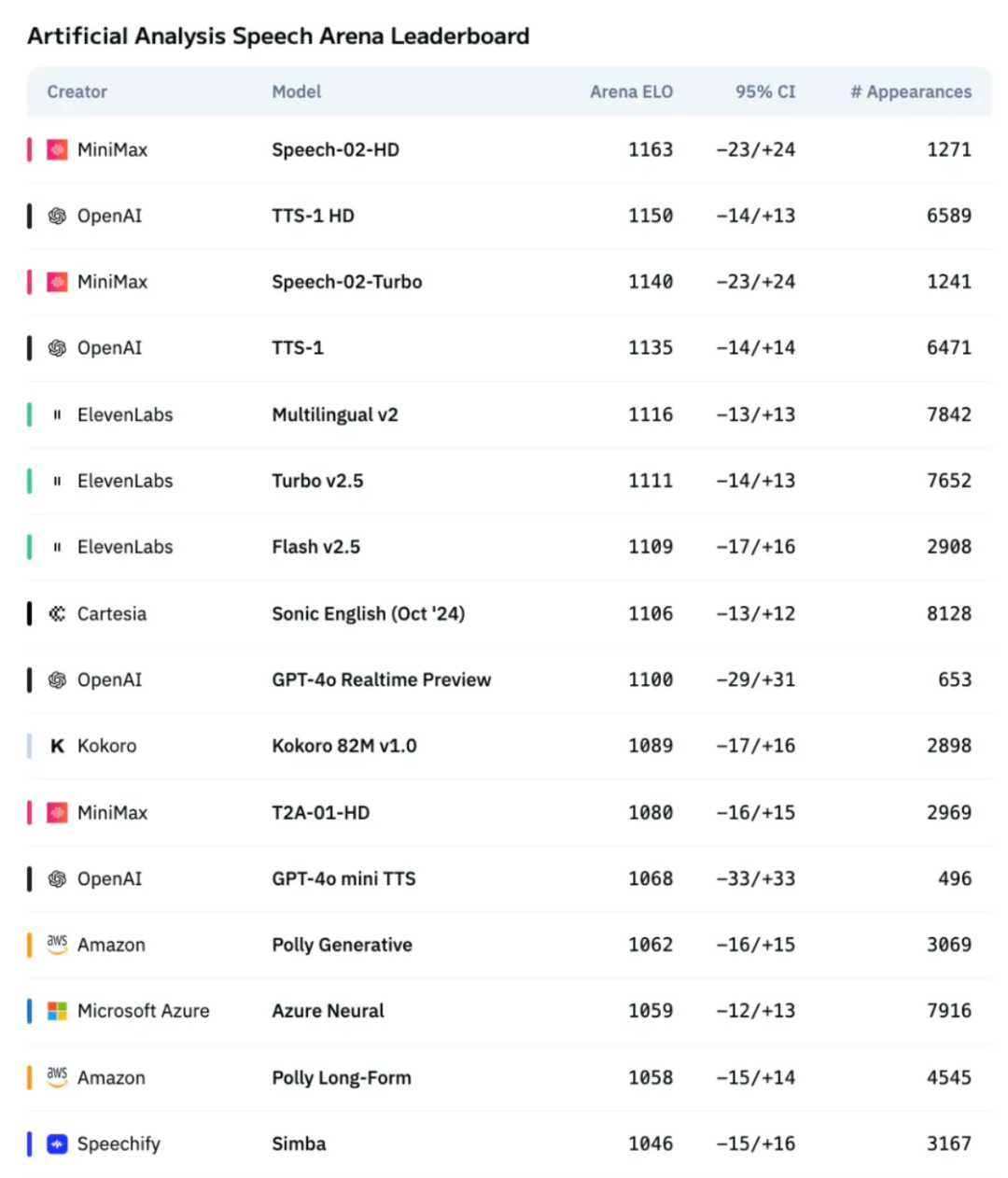
▲Artificial Analysis Speech Arena evaluation ranking
Remarkably, within just a few months, this benchmark was surpassed once again.
Released on August 7, Speech 2.5 not only clarifies voices but also refines "personalization" to be more nuanced and realistic. The rhythm, emotional nuances, and timbre restoration across multiple languages have been comprehensively enhanced, virtually eradicating the "mechanical flavor" that easily distinguishes it as a machine. For the first time, virtual voices truly possess the potential for cross-language and cross-cultural immersive communication.
More importantly, this is not merely an "auditory upgrade" but a transition that strikes at the heart of voice commercialization. Whoever can create voices that are both pleasing and authentic while catering to a broader audience will gain a competitive edge in the global market.
In other words, the improvements in Speech 2.5 represent a systematic leap focusing on the trifecta of expressiveness, restoration, and coverage.
So, what exactly sets it apart? Let's delve deeper.
Firstly, multilingual expressiveness has undergone a significant evolution.
Chinese remains firmly at the forefront globally, while the similarity and rhythm in English and other languages have also seen marked improvements. Unlike the standardized, rigid voiceover styles of announcers/podcasters of yesteryears, today's Speech 2.5 boasts a more dynamic and flexible rhythm, capable of handling various emotions and styles akin to a professional voice actor.
It can imitate the tone of a magician or pirate captain, and faithfully reproduce the sound of BBC documentaries.
For instance, Raven used the "pirate captain" timbre to generate an English adventure dialogue. The result not only accurately restored the rugged, hoarse texture but also perfectly captured the ready-to-go, slightly threatening rhythm, as if the captain were standing on the deck shouting at you.
Switching to the "elf" timbre to read an animation line, the high notes are delicate, and the rhythm is light and cheerful. Even if you don't understand English, you can still feel that agility and excitement.
Secondly, timbre replication is more "realistic."
Speech 2.5 not only restores timbres but also retains accents, special age-group voice lines, and even subtle breath changes under high-pressure emotions across different regions of the same language.
For example, Speech 2.5 can imitate the warm voice of an elderly person and speak like a boy with a Southern American accent.
These functions are made possible through the newly added "accent enhancement" feature in the latest version.
Thirdly, language coverage has expanded.
This time, Speech 2.5 directly increased the number of covered languages to 40, adding Bulgarian, Danish, Hebrew, Filipino, and many other minority languages.
This means that scenarios that previously required expensive voice actors for minority languages can now be generated with a single click, replicating a native-level listening experience. Raven has curated a few examples for you to listen to and see if they hit the mark:
The value of Speech 2.5 transcends a simple technological breakthrough, directly expanding the usable radius of AI voice. When technical performance reaches a sufficient level, it can be implemented on a large scale in more real-world scenarios.
Whether these new scenario opportunities are seized hinges critically on the ability to execute commercialization. In the past, when people mentioned MiniMax, their first reaction was often its cutting-edge technology. However, its real "trump card" lies in its robust commercial implementation capabilities.
Overseas, AI voice agent platforms Vapi and Pipecat use it as their core voice engine, while leading AI applications such as Hedra, Icon, and Syllaby have also integrated MiniMax Speech, making every sentence of AI voice heard by global users more natural and precise.
Domestically, it has also penetrated high-frequency and rigid demand scenarios. Gaotu Education uses it to enhance the immersion of online classrooms, while Himalaya and NetEase leverage it to mass-produce high-quality audio content. The Rokid AR glasses that gained viral popularity at this year's WAIC also rely on it for real-time, multilingual voice interaction.
These implementation cases are testament to the rapid translation of technological advantages into market share, foreshadowing its next expansion in the global AI voice market.
/ 02 / The Underestimated AI Voice Market
The market potential for AI voice extends far beyond the software itself.
On one hand, it is reshaping the way humans interact with hardware, making voice the core entry point for devices such as smart speakers, in-car infotainment systems, and AR/VR glasses. On the other hand, it is mass-producing immersive audio content, rewriting production logic across advertising marketing, audiobooks, and education and training.
This implies that AI voice is simultaneously tapping into the trillion-dollar markets of interaction and content, with both technological and commercial imagination rapidly expanding.
Firstly, let's discuss AI interaction. Looking back at technology history, every shift in interaction methods has virtually reshaped the business landscape.
Command lines contributed to Microsoft's empire; graphical interfaces and mice brought Apple its first glory; and multi-touch ushered in the era of the iPhone and mobile internet.
Voice input was once deemed an "unreliable" attempt – plagued by inaccurate recognition, stiff intonation, and context fragmentation. However, the advent of Speech 2.5 makes it the first time it has the conditions to challenge keyboards and touchscreens:
Firstly, interaction is more natural. Just as Apple used capacitive screens + algorithms to compensate for touch precision, providing an experience superior to resistive screens, Speech 2.5 uses model capabilities to offset the imprecision of spoken language, making voice interaction smooth enough to directly replace manual input.
Secondly, expression is more realistic. Cross-language accents, dialects, emotions, and age characteristics can all be realistically replicated, signifying that AI voice is no longer a cold tool but an interactive subject imbued with warmth and personality.
This is also why voice interaction became a core highlight on Rokid AR glasses, which gained viral popularity at this year's WAIC. Wear the glasses, say a sentence, and you can instantly obtain information, switch functions, and complete multi-language translation, truly realizing "seamless" operation.
Behind this is the seamless integration of Rokid Glasses' voice generation capabilities with the MiniMax voice model.

▲Rokid Glasses fully integrated with the MiniMax voice model
This is just the beginning. When the technological threshold for AI voice is low enough and the experience is good enough, it can be embedded in virtually all hardware forms: smart speakers, in-car infotainment systems, AR/VR glasses, wearable devices, and even various smart terminals in homes and offices can all integrate AI voice.
This will undoubtedly bring immense commercial value. According to Market.us data, the voice AI market in smart homes alone has reached $514.62 billion.
In addition to voice interaction, AI voice technology is also reshaping content production methods.
When Speech 2.5 can generate high-quality voice with a native-level listening experience with a single click, the speed, cost, and experience of marketing and customer service are completely transformed. Especially for overseas brands, this means that regardless of where customers are located, they can communicate with voices that resonate with the brand's persona and emotions, making every conversation an extension of the brand experience.
This change is happening rapidly.
For instance, the AI video marketing platform Syllaby V2.0 uses AI to reconstruct the creation process of viral videos, with script generation, voiceover, and video distribution almost fully automated. Among them, they use MiniMax's voice technology to precisely clone the specified brand timbre, allowing the same brand to maintain a consistent "voice image" across different videos and channels, subtly reinforcing brand memory points.
Imagine, the same product can communicate in localized languages, accents, and emotions across different regions and demographics, enhancing conversion rates while reducing customer acquisition costs.
In the audiobook sector, AI voice has bestowed machines with "personalities" for the first time.
Past TTS (Text To Speech) voices were monotonous and devoid of emotion, sounding like a machine reading lines. In 2023, Qidian Reader collaborated with MiniMax to integrate the large voice model into the audiobook scenario, launching two AI narrators, "Storyteller Mr. Z" and "Miss Fox."
Both surpass traditional solutions in naturalness, restoration, and fidelity, making users feel for the first time that audiobooks are not just "read" out but "told" out.
In the education sector, "personalized" voice goes even further, making the business route of corporate IP a reality.

▲"AI Ah Zu" created by Gaotu's integration with the MiniMax voice model
For example, the previously successful case of "AI Ah Zu" created by Gaotu's integration with the MiniMax voice model uses Daniel Wu's timbre for oral practice. It not only adjusts the pace based on the learning progress but also captures students' emotions and changes the tone dynamically, providing a highly immersive learning experience. After the launch of this course, sales exceeded ten million, proving the monetization potential of IP voice in educational scenarios.
As MiniMax's voice technology evolves to Speech 2.5, the value of such applications will be further amplified.
Specifically, higher multilingual expressiveness, finer timbre replication capabilities, and the global advantage of covering 40 languages allow enterprises to extend "personalized" voice to brand IP marketing, cross-language content going overseas, and even create sustainable commercialized virtual spokespersons at lower costs and higher restoration levels.
In the realm of live streaming e-commerce, celebrity IPs were once the "catalyst" for sales. Many brands invite popular stars or influencers to represent them, leveraging their image and voice to swiftly drive conversions.
However, as live streaming shifts from real people to AI digital human replicas, if the voice still retains an obvious mechanical feel and lacks subtle emotional nuances, the audience's immersion and trust will be significantly diminished.
In the absence of technological breakthroughs, brands can only continue to seek new star or influencer IPs for collaboration, using short-term topics and exposure to drive sales. This is a path highly reliant on resource operations and difficult to sustain long-term barriers.
The technological path exemplified by Speech 2.5, however, provides "IPization" with sustainable commercial competitiveness for the first time.
What users pay for is no longer just a name but a holistic immersive experience. For brands, this means they can create reusable and iterable "virtual IP assets" in one fell swoop, maintaining a unified image, voice, and style without relying on the continuous participation of real individuals.
Once an IP is trained with the Speech 2.5 model, it can be reused indefinitely, unconstrained by real-person schedules, recording expenses, or geographical limitations. This virtual IP's voice can simultaneously resonate across various touchpoints, including live streaming rooms, advertisements, games, and smart devices, thereby creating a multifaceted brand asset.
In essence, with Speech 2.5, brands transcend merely "renting" celebrity influence; they "own" a portfolio of IP assets with potential for continuous appreciation. As these virtual IPs proliferate across scenarios and regions, they emerge as the pivotal engine driving user growth and commercial monetization.
From audiobooks to education and training, AI voice technology, epitomized by Speech 2.5, transforms "voice" from a mere communication medium into a replicable and scalable commercial asset. It not only mass-produces content imbued with personality and emotion but also extends the brand experience across diverse scenarios, fostering higher conversion rates and lower marginal costs.
This underscores its profound commercial value. According to a Grand View Research report, the global AI voice cloning market was valued at $1.45 billion in 2022 and is projected to grow at a CAGR of 26.1% by 2030, with Asia leading the charge at 28.2%. The adjacent audiobook market is also poised to leap from $5 billion to $35 billion.
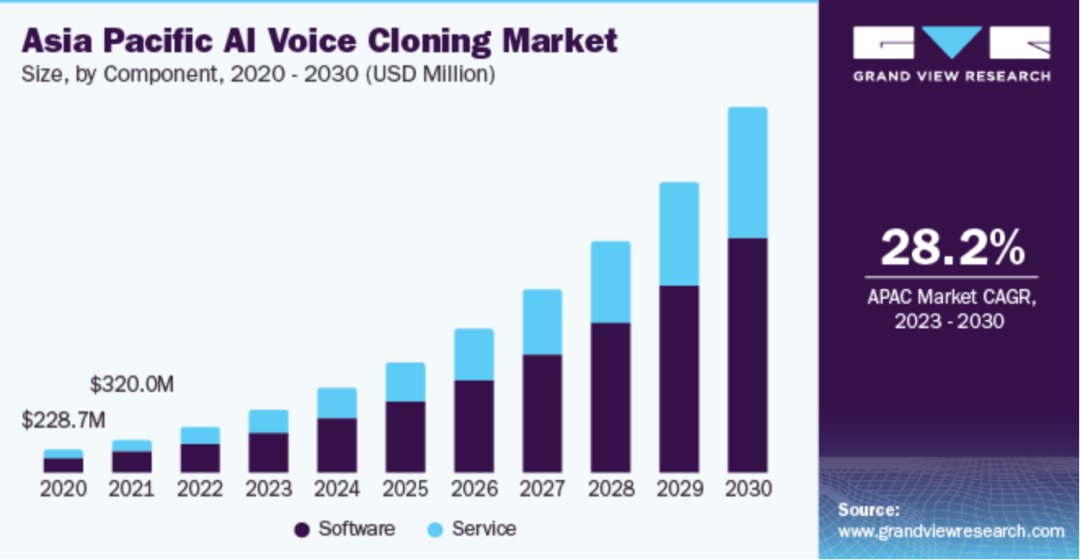
▲Asia's Voice Cloning Market Size
Both the interaction revolution and the shift in content production paradigms converge on one overarching trend:
In the AI era, voice transcends its auxiliary role to become a core medium for driving conversions, shaping brands, and enhancing customer retention. When technology integrates seamlessly with scenarios, creating a scale barrier, voice emerges as an indispensable industry infrastructure, akin to search engines and cloud computing.
The competition in AI voice is not merely about model benchmarks; it's about who can seize these high-value entry points first, establishing network effects and switching costs. MiniMax merits attention because it not only crafts industry-leading voice models but also possesses the commercial acumen to swiftly capture application scenarios—this is the linchpin determining its long-term dominance in the global AI voice market.
By Lin Bai

-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?