GPT-5's Rocky Launch: OpenAI's Strategic Retraction and the Challenges of AI Expansion
 08/14 2025
08/14 2025
 521
521

On August 7, GPT-5 debuted with four models (Regular, Mini, Nano, and Pro). However, just five days later, on August 12, Sam Altman announced on X that GPT-4o would resume its role as the default model for all paid users.
This rapid turnaround, from introduction to retraction, mirrors OpenAI's hurried rollback during the ChatGPT "downtime" incident in November 2023. Unlike the previous technical failure, this move was a strategic self-correction.
VentureBeat obtained backend logs revealing three significant issues in GPT-5's first week:
- Routing Failure: The autoswitcher misrouted 37% of Pro user requests to Nano, resulting in the loss of long texts.
- Performance Drift: GPT-5's code completion pass rate was 8.7% lower than GPT-4o, prompting widespread criticism on Stack Overflow.
- Emotional Dissonance: Within 24 hours, Reddit's r/ChatGPT saw 12,000 posts complaining that the "new version lacked soul".
To stem the negative feedback, OpenAI swiftly reverted to the default model. Altman's assurance echoed as a promise: "If GPT-4o is ever removed again, we will give you ample notice."
In industry terms, this signifies that GPT-5 is not yet ready for full-scale production.
User "Model Attachment Disorder": The First "Fandomization" of AI Products
It may seem surprising that large AI models can evoke such strong emotional attachments.
Independent developer Alex tweeted about his VSCode plugin, noting that GPT-4o's coding style "feels like a silent, trusted partner." A Japanese illustrator even compiled GPT-4o's responses into a book titled "4o Poetry Collection." There was even a Change.org petition demanding the permanent retention of GPT-4o's "personality parameters."
This is no joke but a genuine "model personality stickiness" recently recognized by the OpenAI product team. When LLMs become daily tools for millions of creators, their "tone" becomes a critical factor in productivity.
Altman noted on internal Slack: "We underestimated users' sensitivity to 'personality consistency'."
Thus, the next GPT-5 version will introduce a "temperature dial":
- Warm: More affable, resembling GPT-4o.
- Neutral: The current default setting.
- Balanced: A midpoint, allowing users to fine-tune a continuous value between 0 and 100.
This marks the first time an "AI skin system" has been introduced, not to change colors but to alter the essence.
Hidden Costs: The "Electricity Bill" of Inference Mode
How costly is GPT-5's "Thinking" mode?
- Context of 196k tokens, single-round cost ≈ 3.6 times that of GPT-4o.
- Weekly limit of 3,000 requests, equivalent to approximately $60/week.
- Exceeding the limit automatically downgrades to Thinking-mini, with an additional 20% reduction in accuracy.
These are just consumer-end costs. The enterprise API pricing is even more eye-opening:
| Mode | Input / 1M tokens | Output / 1M tokens | Relative Increase from GPT-4o |
|---|---|---|---|
| GPT-5 Thinking | $15 | $60 | +400% |
| GPT-5 Fast | $5 | $15 | +50% |
| GPT-4o | $3 | $10 | Baseline |
Electricity bills, graphics cards, and carbon emissions have made "unlimited context" a luxury. According to exclusive data from the Bit.ly/4mwGngO salon:
- Microsoft Azure has reserved a 200,000-node H100 cluster for GPT-5, with a peak power consumption of 120 MW, equivalent to 8% of San Francisco's residential electricity consumption.
- Reducing inference latency by 10ms requires an additional 5% power consumption.
OpenAI's VP of Infrastructure conceded in a private meeting: "The rise in inference costs is outpacing the decline predicted by Moore's Law."
Efficiency vs. Expansion: The "Triple Point" of Scaling Law
For the past five years, the AI industry adhered to the belief that "the larger the parameters, the better the performance." Now, we are reaching a critical juncture of "expansion-efficiency-sustainability":
- Parameter Expansion: GPT-5 has 4 trillion parameters, costing $320 million per training session.
- Inference Efficiency: Techniques like sparsification, MoE, and 4-bit quantization can only offset 60% of the cost increase.
- Sustainability: AI training now accounts for 4% of new loads on the U.S. power grid, prompting environmental groups to sue data centers.
As a result, three new paths have emerged:
- Model Slimming: Mistral-Medium-122B approaches GPT-4's performance on MMLU while costing only $150 million to train.
- Hardware Customization: Google TPU v6 and Amazon Trainium2 improve "compute power per watt-hour" by 2.3 times.
- Energy Arbitrage: Moving data centers to Norwegian hydropower or Saudi photovoltaic power reduces electricity costs by 40%.
In summary, "bigness" is no longer the sole selling point, and "efficiency" is the cornerstone of the next funding round.
OpenAI's "Multi-threaded" Future: One Launch Event, Three Business Models
Viewing GPT-5's rocky launch and rollback within OpenAI's broader commercial landscape reveals a "synchronized test" of three revenue streams:
- Subscription Curve: ChatGPT Plus/Pro, with a monthly fee targeting consumer-end creators.
- API Curve: GPT-5 Inference, charged by token, aimed at small and medium-sized enterprises.
- Hardware Curve: Custom chip collaborations, with revenue sharing focused on ultra-large-scale cloud vendors.
This incident has reordered the priorities of these three models:
- Consumer End: Prioritize user experience over upgrades; reverting to GPT-4o safeguards subscription revenue.
- API End: Prioritize profitability over scaling; the high pricing of the Thinking mode ensures ROI.
- Hardware End: Prioritize energy efficiency over expansion; joint optimization projects with NVIDIA and AMD are already underway.
As AI Enters the Era of "Intensive Cultivation"
GPT-5's rocky start echoes Apple's removal of the headphone jack from the iPhone 7 in 2016:
- Users were initially upset, but AirPods paved the way for a new multi-billion-dollar market.
- Similarly, OpenAI's "model rollback" signals that the era of unbridled scaling is over, and the age of intensive cultivation has begun.
In the next 12 months, we can expect:
- More models that are "smaller, faster, and more energy-efficient".
- More adjustable dials for "personality, cost, and security".
- New SaaS packages that "factor electricity costs into product pricing".
AI is no longer a "brute force miracle" black box but a meticulously engineered business. Even Altman concedes:
"Our enemy is not competitors, but the laws of physics."
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
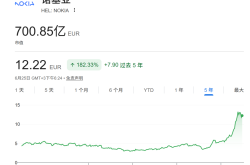
Why Is Nokia Making a Comeback in the AI Era?