Post-DeepSeek V3.1 Launch: Investors Must Ponder These Four Questions Shaping the Future
 08/21 2025
08/21 2025
 578
578
Last night, the AI community was rocked by yet another unexpected late-night announcement.
DeepSeek, sans a press conference, quietly unveiled its new V3.1 version. 
Despite its low-key launch, the disclosed performance and parameters were nothing short of "groundbreaking," quickly igniting heated debates in both technology and investment circles. Public information and community tests reveal that the highlights of this update are exceptionally prominent:
Programming prowess surpasses Claude 4 Opus: In the authoritative Aider programming benchmark test, V3.1 scored 71.6%, outperforming the previously renowned programming powerhouse Claude Opus 4, topping the open-source model rankings. 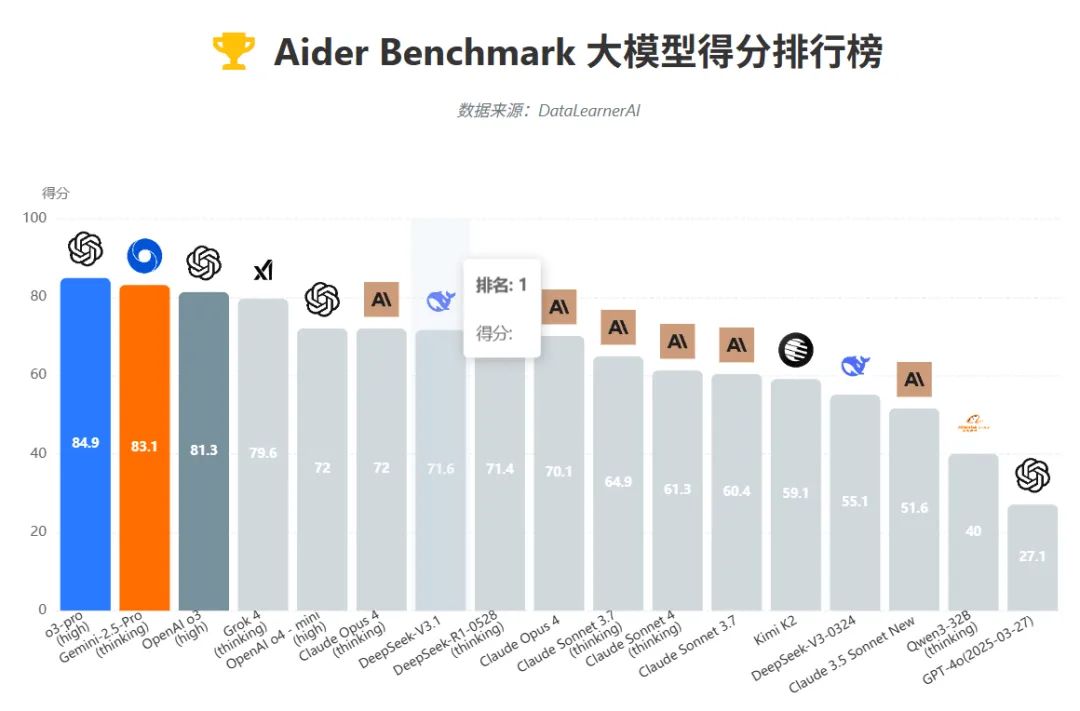
Extreme cost advantage: The cost of completing a full programming task is merely $1.01, 68 times cheaper than the slightly less capable Claude Opus 4!
Signs of architectural innovation: The online model silently removed the "R1" (representing deep thinking) label and added special tokens such as search and think, sparking widespread speculation in the industry about DeepSeek's potential adoption of a "hybrid architecture" in the future. 
While public evaluation data represents the "past," investment decisions are always geared towards the "future." As the community and media celebrate the performance benchmarks of V3.1, astute capital has already begun stress-testing the underlying logic and future landscape of the AI sector.
The following four questions may influence the flow of funds in the AI sector more significantly than mere benchmark data in the coming quarters. These are areas where we believe you most need to obtain firsthand insights.

Four "non-consensus" questions investors must consider:
1. The ultimate showdown between open-source and closed-source: Is the balance shifting, or are we entering a "hybrid state"?
The emergence of DeepSeek V3.1 solidifies the narrative of "open-source catching up with closed-source." However, the simple phrase "catching up" overshadows a more intricate industrial evolution. What professional investors need to delve into is:
The dissolution and reconstruction of moats: Historically, the market believed that closed-source giants' (OpenAI, Anthropic) moats resided in the "data flywheel + top talent + extreme model scale." Now, with Llama, Mistral, and DeepSeek surpassing them in specific capabilities (like programming, mathematics),
We must reassess the true breadth of this moat. Has the core advantage of closed-source shifted from "absolute leadership in general intelligence" to a "time window" advantage in cutting-edge functions like multimodality and ultra-long context? How long will this time window last? How much long-term suppression will this exert on closed-source models' valuation logic and API pricing power?
The "hybrid model" adopted by enterprises becomes mainstream:
More enterprises are embracing a pragmatic "hybrid model": for end-user and privatized deployments, they prioritize fine-tuned, more controllable open-source models to handle sensitive data and high-frequency tasks; whereas on the public cloud, they invoke the most powerful closed-source models to manage the most complex, non-core data tasks.
How will this "hybrid state" reshape the AI service landscape of cloud vendors? Is this a positive or negative development for companies like Snowflake and Databricks, which are striving to build integrated "data + model" platforms? How should investors reassess the value distribution of the entire AI PaaS layer under this trend? 
2. Speculation on "hybrid architecture": Is it the next-generation technological moat or an advanced "cost game"?
DeepSeek's removal of the "R1" label and addition of special tokens are widely interpreted in the industry as potentially exploring a "hybrid reasoning" or "model routing" architecture. This isn't a simple technological iteration but has profound business implications behind it.
"Dimensionality reduction strike" on reasoning costs: The core idea of "hybrid architecture" is to utilize a lightweight "scheduling model" to gauge the complexity of user requests and then distribute them to the most suitable "expert model" (large, medium, or small) for processing, avoiding "using a sledgehammer to crack a nut."
Can this architecture elevate the unit economics of large model reasoning by an order of magnitude? If so, this will directly impact companies whose primary business model is providing general large model APIs. More importantly, what does this signify for the cost structure of downstream AI applications?
Structural impact on hardware demand: The current "bigger is better" model paradigm directly drives massive demand for top-tier GPUs like NVIDIA's H100/B200. But if "hybrid architecture" becomes mainstream, does it imply that future data centers will require a more diversified computing power mix, such as a plethora of low-cost inference chips for "scheduling models" and "small models"? Will this open new market windows for chip vendors other than NVIDIA (like AMD, Intel) and companies specializing in inference optimization (like Groq)? Should this new variable be considered when evaluating NVIDIA's long-term investment logic?
3. Ultimate cost-effectiveness: When will the "Cambrian explosion" of the AI application layer arrive?
As model capabilities approach SOTA and reasoning costs plummet by 60-70 times, the most direct impact will be felt at the AI application layer. This isn't just a quantitative change but may trigger a qualitative transformation.
Fundamental shift in business models: Previously, the high cost of API calls was a core shackle preventing many AI-native applications (especially agent-type applications) from large-scale commercialization. Now, the steep drop in costs may mean that the business model of AI applications can shift from "pay-per-use" or "pay-per-token" to the more enterprise-acceptable "monthly subscription (SaaS)" model. This will significantly enhance the revenue stability and market ceiling of AI applications.
Which listed companies in which sectors should investors keep an eye on, as they are most likely to benefit from this "cost revolution," thereby achieving a "Davis double play" in earnings forecasts?
Profit redistribution in the value chain: If foundational models (IaaS/PaaS layer) gradually become "commoditized" due to open-source competition, will the profit center in the value chain accelerate its shift towards the upstream "application layer" and "solution layer"? The real moat is no longer which model one possesses but who has "high-quality private data," "a deep understanding of specific industry workflows," and "strong enterprise sales channels."
Under this logic, how should we reassess the competitive landscape between traditional software giants (like Microsoft, Adobe, Salesforce) with vast user and data holdings and emerging AI-native application startups?
4. Beyond performance: Where is the next core battleground that will decide victory or defeat?
As models increasingly compete for rankings on various benchmark lists, pure performance scores are no longer the sole determinant of a model or company's commercial success or failure. Competition in the next phase will unfold in more hidden dimensions more relevant to actual enterprise deployment.
"Enterprise readiness": This is a comprehensive concept encompassing a model's stability, predictability, security, and compliance (like data privacy, GDPR). A model highly praised in the open-source community may not pass the compliance review of large financial or medical institutions. In the future, whoever can take the lead in providing a complete "enterprise suite" including models, toolchains, and compliance solutions may hold the key to unlocking the trillion-dollar enterprise market.
Deep optimization and ecosystem construction in "vertical domains": General large models (GWM) cannot solve all problems perfectly. The real commercial value explosion often stems from "vertical large models" (Vertical LLM) deeply integrated with specific industries (like law, finance, biopharmaceuticals).
For instance, BloombergGPT trained by Bloomberg. The focus of competition will shift from "whose model is bigger" to "whose model better understands the 'jargon' and complex logic of specific industries." Simultaneously, the ecosystem around these vertical models - including developer tools, API interfaces, community support - will become crucial for locking in customers and building long-term barriers. 

The release of DeepSeek V3.1 is akin to a stone tossed into a lake; its true significance lies not in the stone itself but in the ripples of industrial diffusion it generates, spreading outwards in circles. 
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?