AI Learning Notes|Why Do Large Language Models Lie?
 08/21 2025
08/21 2025
 789
789
The lying issue with large language models is more complex than mere inaccuracies typical of traditional analytical AI. These models fabricate content on a serious scale.
When using a large language model to generate long text, you'll often find that the cases and data it introduces seem plausible and rigorous, yet they often do not exist in reality; they are purely fabrications of the model.
This week, my colleague confirmed my observations in our conversation.
According to her, many people now rely on AI to write commercial articles to save time. These articles are seamless and deceptive, making it challenging for ordinary readers to spot errors. Often, it's the senior insiders of the companies involved (typically the responsible parties) who raise questions: "How come I don't know about this?" An AI-generated article directly implicates the responsible person, media, and author.
This is quite awkward.
My colleague refers to this phenomenon as "AI hallucinations." Typical manifestations include: 1. Data hallucinations, where data is fabricated based on logic; 2. Fabrication of key information; 3. Creation of corporate development stories; 4. Overuse of clichés and templates in language.
Therefore, her requirements for receiving articles strictly prohibit AI creation, a point she has repeatedly emphasized.
In the end, she echoed my sentiment from the first episode of "AI Chronicles": "Resolutely advocate for human creation; commercial writing should have a human touch." – This conclusion is the most uplifting sentence I've heard this week.
But the question remains: why do large language models lie?
01 Unfathomable Emergent Abilities
In 1950, Alan Turing, the father of computer science, stated in his paper "Computing Machinery and Intelligence": "An important feature of learning machines is that their teachers are often ignorant of the internal workings of the machine."
This sentence succinctly summarizes the terrifying "emergent abilities" demonstrated by large language models today.
People cannot comprehend why the training data (pre-trained language models) and architecture (transformer architecture) are controllable, yet the results and abilities presented after data processing through the architecture become completely uncontrollable.
Typical "emergent abilities" of large language models include:
- Contextual Learning: Introduced by GPT-3, large language models can perform tasks through contextual understanding of natural language instructions without additional training or parameter updates.
- Instruction Following: After fine-tuning on task A, a large model can perform a completely different, unseen task B by following the pattern of task A.
- Step-by-Step Reasoning: Large models adopting the "chain of thought" reasoning strategy can gradually solve complex problems compared to smaller language models.
These abilities are not solely derived from data feeding or provided by the sequence-to-sequence transformer architecture. How large language models achieve these things remains a mystery. Currently, we can only describe the observed peculiar phenomena but cannot fully understand their origins.
Questions such as at what parameter scale emergence occurs, which adjustments affect ability emergence, what ability directions will emerge, and whether we can control it, remain unanswered.
Because we do not understand the underlying mechanisms, we refer to the operating mode of large language models under the transformer architecture as the "black box model."
Even excellent large language models can demonstrate impressive multimodal abilities. For example, when shown a photo of a world map made of chicken pieces, GPT-4 not only accurately understood the image but also grasped the humor behind it.

With independent learning and even the ability to understand human emotions, does this mean AI can have emotions? Does it possess self-awareness? Are we one step closer to AGI (Artificial General Intelligence)?
For some, this picture is enchanting. For others, it's far from appealing, especially considering the initial point about their tendency to lie.
And the reason why large language models lie precisely stems from this unexplainable emergent ability.
02 Why Do They Lie
Yann LeCun, the 2018 Turing Award winner and one of the pioneers in deep learning, briefly explained the underlying logic behind large language models' lying in a 2023 speech.
Essentially, the learning abilities of generative AI like large language models (LLMs) have a gap, not just a difference, from those of humans and animals.
As mentioned earlier, based on instruction tuning + transformer architecture, data feeding is the first step in AI training, followed by data conditioning. To efficiently and precisely process massive amounts of data, we have the transformer architecture, which captures dependencies in instructions.
However, when the required content cannot be captured, the transformer architecture uses "prediction" to fill in the gaps. Moreover, the system doesn't predict all missing words but only the last token. It continuously predicts the next token, moves it into the input, predicts the next token again, and repeats this process.
This prediction method is known as "probabilistic generation," or "token by token."
When reasoning and prediction are unnecessary, and every step has factual support, the conclusion will undoubtedly be accurate and natural. However, when there are missing parts and predictions are needed at every step, the final conclusion may continue to compound errors based on a wrong premise.
The result is that large language models seriously fabricate content, effectively lying.
According to Yann LeCun, "If you train these models on one trillion or two trillion tokens of data, their performance is astonishing. But ultimately, they will make very silly mistakes. They will make factual and logical errors, inconsistencies, and generate harmful content due to their limited reasoning abilities."
This error is not related to the productivity of large language models but is inherent in their operating logic. As long as they are running, there's a probability that they will lie. Since everything is based on autoregressive, self-supervised, and self-learning under the transformer architecture, you can't even pinpoint where the lies originate.
Lying is an inherent issue with the transformer architecture.
Therefore, while many consider the transformer architecture the path to AGI, a faction led by Yann LeCun holds a negative view.
I tend to agree with this assessment. We cannot entrust core issues and key areas to an AI that may deceive us with a certain probability, especially when we don't know exactly where the deception lies.
And if it cannot be relied upon for core issues, it cannot be considered AGI.
Thus, to achieve AGI, we may need to explore alternative routes.
Unless it stops lying.
03 Large Models That Don't Lie
Regarding the issue of large models lying under the transformer architecture, Yann LeCun and others propose a direct solution: change routes.
The proposed direction is to endow large models with human-like learning, reasoning, and planning abilities.
For example, in infancy, humans first grasp fundamental concepts of how the world operates, such as object permanence, the world being three-dimensional, the distinction between organic and inorganic, stable concepts, and the concept of gravity. Studies indicate that infants possess these abilities around 9 months old.
According to Yann LeCun's team, if you show a 5-month-old infant a scene where a small car is pushed off a platform, making it seem to float in the air, the infant won't be surprised. But a 10-month-old infant will be very surprised because at this stage, infants already understand that objects shouldn't stay in the air; they should fall under gravity.
Yann LeCun believes that "we should use machines to replicate this ability to learn how the world operates by observing or experiencing the world." Based on this, he proposed the concept of a "world model" in his 2022 paper "A Path Towards Autonomous Machine Intelligence."

Under the world model, large models can imagine a scenario and predict the outcome of actions based on this scenario's framing. This framing differs from current large model role-playing, which makes probabilistic predictions based on data. Instead, large models should understand fundamental concepts of the world's operation, like real space and physical laws.
Most crucially, their reasoning must be based on reality, not a black box; it must be visible and predictable, not unexplainable. From this perspective, the astonishing emergent abilities of large language models might actually be a misstep for LLMs?
It's worth noting that the world model sounds promising but is a highly ambitious and challenging task. If the leap from LLMs to world models is made, we might witness AGI in our lifetime.
Meanwhile, compared to the radical shift towards the world model, some are also attempting to address the issue by patching up LLMs and finding ways to make them stop lying.
For instance, Professor Zhao Hai's team from Shanghai Jiao Tong University in China recently released the first large language model, "BriLLM," which macroscopically simulates the global mechanisms of the human brain. It emphasizes being inspired by the brain's neurological system and uses brain-inspired dynamic signal propagation to replace the self-attention mechanism, aiming to overcome some limitations of the traditional transformer architecture.
"The human brain can process lifelong memories without expanding capacity. This is what AGI should aspire to!" said Professor Zhao Hai, the lead author of the paper. Currently, this project has been selected for funding as a key project in the 2025 annual plan of Shanghai Jiao Tong University's "SJTU 2030" initiative.
The similarity between the BriLLM model and the world model is that they both emphasize 100% interpretability of all nodes in the model.
Regardless of the outcome, whether it's "BriLLM" or "world models," their viewpoints suggest that for the problem of LLMs lying, cutting-edge solutions are eager to first shed their emergent abilities.
References
[1] Machine Heart Pro. Goodbye Transformer, Reshape Paradigms: The Birth of Shanghai Jiao Tong University's First "Human-Like Brain" Large Model. Toutiao. 2025
[2] Ling Zijun, Li Yuan. One of the Three Giants of Deep Learning, Yann LeCun: Large Language Models Cannot Bring AGI. Geek Park. 2023
[3] Shanhu. Today, with large language models being popular, why do we still need to embrace world models? Brain Extreme. 2025
[4] Large Language Models, Yann LeCun, etc. Baidu Encyclopedia. 2025

-Original creation is not easy. Welcome to share. Unauthorized reproduction is prohibited.
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
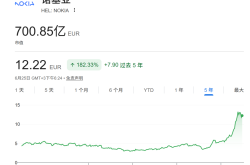
Why Is Nokia Making a Comeback in the AI Era?