Can Text-to-Image Models Also Suffer from a Form of 'Cognitive Dissonance'? Peking University and ByteDance Unveil the Mystery: The More They 'Think', the More They Err! A Parallel Framework Puts an E
 11/17 2025
11/17 2025
 529
529
Interpretation: The Future of AI-Generated Content

Key Highlights
In-Depth Benchmarking and Analysis: ParaBench, a newly designed benchmark, systematically evaluates 'thinking-aware' image generation and editing tasks. It goes beyond merely assessing the quality of the final generated images and texts; more importantly, it gauges the degree of alignment between them.
Parallel Multimodal Diffusion Framework: A purely discrete diffusion-based parallel framework is introduced for 'thinking-aware' image editing and generation. This framework enables bidirectional attention interaction between text and image modalities at every denoising step, effectively mitigating the error accumulation that is inherent in autoregressive (AR) sequential generation processes.
Parallel Reinforcement Learning (ParaRL): A novel parallel reinforcement learning strategy, ParaRL, is presented. This method distributes semantic rewards along the entire denoising trajectory, rather than just rewarding the final outcome. As a result, it further enhances the consistency and overall performance among output modalities.
Comprehensive Evaluation and State-of-the-Art Alignment: Through extensive experiments, this paper validates the effectiveness of the framework. On the ParaBench benchmark, compared to the existing state-of-the-art (SOTA) model Bagel, this work achieves a significant 6.9% improvement in the 'output alignment' metric while maintaining comparable performance on unimodal metrics. This establishes a more robust paradigm for 'thinking-aware' image synthesis.
Problems Addressed
In 'thinking-aware' generation tasks, the model first generates a reasoning step (i.e., the 'thinking process') and then generates or edits an image based on this reasoning. While this approach often enhances performance, this paper identifies a critical failure mode: in certain complex tasks, pre-generated reasoning can actually lead to a decline in the semantic fidelity of the final image.
This issue arises because most existing methods adopt a sequential, autoregressive generation process. In such processes, any ambiguity, inaccuracy, or error in the reasoning text is propagated and amplified to the subsequent image generation stage. This causes the final generated image to deviate from the user's core instructions. Existing evaluation benchmarks focus solely on the final image, neglecting the quality of intermediate reasoning steps and their alignment with the final image. As a result, they fail to locate and resolve this issue.
Proposed Solution
To address the aforementioned problems, a parallel multimodal diffusion framework, MMaDA-Parallel, is proposed, supplemented by a novel training strategy, ParaRL.
MMaDA-Parallel Framework:
Parallel Generation: Unlike the sequential mode of generating text first and then images, this framework enables the simultaneous and parallel generation of reasoning text and target images within a unified diffusion process.
Bidirectional Interaction: At each denoising step, bidirectional attention interactions can occur between the tokens of text and images. This means that text generation can refer to the emerging image features at any time, and vice versa. This continuous cross-modal 'negotiation' mechanism avoids one-way error propagation.
Parallel Reinforcement Learning (ParaRL):
Trajectory-Level Optimization: Traditional reinforcement learning computes rewards only at the final step (i.e., the final output) of the generation process. The innovation of ParaRL lies in computing reward signals at multiple intermediate steps of the denoising process.
Semantic Alignment Rewards: The reward signals are directly derived from the degree of semantic alignment between the text and images generated in intermediate steps (e.g., measured by CLIP scores). By continuously reinforcing this alignment throughout the entire generation trajectory, the model learns to generate more internally consistent multimodal content.
Technologies Applied
Discrete Diffusion Models (DDMs): These form the foundation of the framework. Both text (via LLaDA tokenizer) and images (via MAGVIT-v2 quantizer) are uniformly represented as discrete token sequences. This enables a single diffusion model to handle both modalities simultaneously.
Interleaved Sequence & Bidirectional Attention: The input and output text and image tokens are arranged in a single sequence, separated by special markers (sentinels). This allows the model to perform comprehensive bidirectional cross-modal attention calculations within a unified context.
Parallel Denoising & Dual Schedulers: During decoding (sampling), the model performs parallel denoising on a shared timeline. However, different masking schedulers are employed for text and image modalities—linear revelation scheduling for text and cosine revelation scheduling for images—to accommodate their respective generation characteristics.
Group Relative Policy Optimization (GRPO)-Based Reinforcement Learning: The implementation of ParaRL is based on the GRPO objective function, which has been adapted to suit the non-autoregressive nature of diffusion models and the setting of trajectory-level rewards. The reward function is based on normalized CLIP scores to ensure training stability.
Achieved Results
Significantly Enhanced Cross-Modal Alignment: On the ParaBench benchmark, MMaDA-Parallel (combined with ParaRL) achieved the highest 'Output Alignment' score (59.8%) among all open-source models. This represents a 6.9% improvement over the previous SOTA model Bagel (52.9%).
Maintained High-Quality Unimodal Outputs: While improving alignment, the model performed comparably to Bagel on unimodal metrics such as text quality and image quality, despite Bagel being trained on a much larger dataset.
Validated the Superiority of Parallel Framework and Trajectory Optimization:
Ablation experiments demonstrate:
Compared to sequential generation baselines, parallel decoding significantly improves output alignment.
Compared to traditional reinforcement learning that applies rewards only at the final output, the proposed trajectory-level optimization (ParaRL) brings more stable and significant performance gains.  Figure 2: MMaDA-Parallel supports parallel, thinking-aware image editing and generation. Compared to Bagel, MMaDA-Parallel exhibits higher reasoning quality and stronger consistency between generated text and image outputs. MMaDA-Parallel
Figure 2: MMaDA-Parallel supports parallel, thinking-aware image editing and generation. Compared to Bagel, MMaDA-Parallel exhibits higher reasoning quality and stronger consistency between generated text and image outputs. MMaDA-Parallel
Discoveries and Benchmarking for 'Thinking-Aware' Synthesis
To investigate whether pre-generated reasoning truly enhances performance, this paper conducted a controlled study on image editing tasks. These tasks provide clearer instruction-based evaluation compared to pure image synthesis. Inputs were sampled from existing benchmarks, and paired outputs were generated using Bagel—an advanced open-source unified model supporting 'thinking-aware' generation—in both 'thinking' enabled and disabled modes. The average editing evaluation metrics on Kris-Bench are reported in Figure 1(c) and Table 1.
 Figure 1: Sequential vs. Parallel Thinking-Aware Image Synthesis. (a) Sequential generation (Bagel, GPT4o) may suffer from ambiguous or erroneous reasoning. (b) Parallel generation can adjust text and images at each denoising step, reducing hallucinations and errors. (c) Quantitative comparisons show that reasoning degrades performance in certain categories. (d) Poorer categories also exhibit weaker reasoning-image alignment, highlighting the necessity of enhancing cross-modal alignment.
Figure 1: Sequential vs. Parallel Thinking-Aware Image Synthesis. (a) Sequential generation (Bagel, GPT4o) may suffer from ambiguous or erroneous reasoning. (b) Parallel generation can adjust text and images at each denoising step, reducing hallucinations and errors. (c) Quantitative comparisons show that reasoning degrades performance in certain categories. (d) Poorer categories also exhibit weaker reasoning-image alignment, highlighting the necessity of enhancing cross-modal alignment. 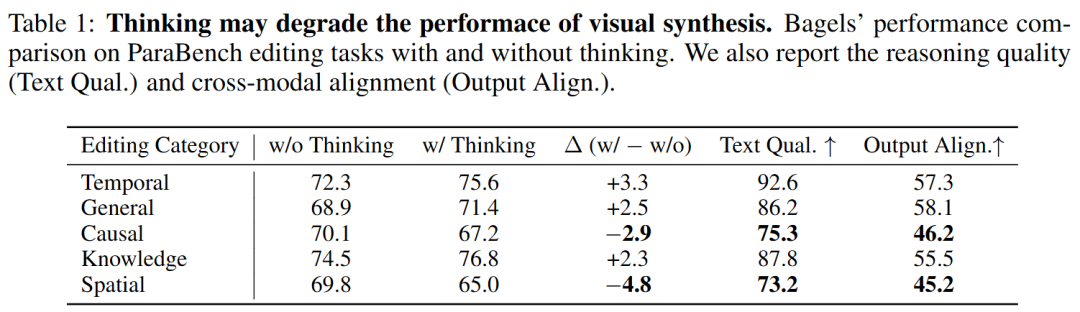
Discoveries: While the reasoning step improved performance on most tasks, a significant anomalous trend emerged: in a substantial portion (approximately 23%) of cases, performance actually declined, particularly in complex compositional editing tasks. Deeper analysis revealed that these failures typically stemmed from low-quality or ambiguous reasoning texts that misguided the image generation process. This exposed a critical flaw in existing evaluation protocols: they assess only the final image while neglecting the quality of intermediate reasoning as another generated modality.
Mixed-Modality Benchmarking: This analysis revealed a fundamental limitation of current evaluation paradigms: existing benchmarks assess only images, neglecting the quality of reasoning itself and its alignment with the image. To address this gap, this paper introduces ParaBench, a new benchmark specifically designed for comprehensive evaluation of 'thinking-aware' image synthesis. ParaBench contains 300 challenging prompts, including 200 for editing and 100 for generation. The editing prompts are carefully curated to test a wide range of capabilities, covering not only conventional operations (e.g., adding, removing, replacing) but also complex tasks requiring reasoning. The 100 generation prompts focus on open-ended creative synthesis of complex scenes. This paper uses GPT-4.1 to evaluate model performance on ParaBench across six fine-grained dimensions: for text outputs, text quality and text alignment are assessed; for visual outputs, image quality, image alignment, and image consistency are evaluated; finally, overall output alignment between the two is assessed.
To demonstrate ParaBench's diagnostic capability, it was applied to a representative baseline model, Bagel. While complete quantitative results are presented in Appendix A, Table 1 highlights a key finding by focusing on two critical metrics—text quality and output alignment. The results show a clear correlation between the quality of reasoning steps and final performance. Notably, categories that exhibited performance declines also suffered significant drops in reasoning quality and reasoning-image synergy. This pattern strongly suggests that poor reasoning not only fails to provide beneficial guidance but actively misleads the generation process, thereby validating the necessity of explicitly enhancing text-image generation synergy.
Motivation for Parallel Multimodal Diffusion: The benchmarking results in this paper reveal a critical limitation of current 'thinking-aware' generation: the sequential generation paradigm (i.e., reasoning precedes image synthesis) creates a rigid dependency that can propagate errors and limit cross-modal synergy. When reasoning quality declines, it directly impairs subsequent image generation, as evidenced by the correlated performance drops observed in spatial and temporal editing tasks. To address this fundamental issue, this paper proposes a parallel unified multimodal diffusion framework capable of simultaneously generating reasoning text and images, thereby facilitating true multimodal collaboration and eliminating the error propagation inherent in sequential approaches.
Basic Algorithms and Architecture
Discrete diffusion models have demonstrated strong performance in image and text generation tasks. Based on a unified discrete diffusion perspective, MMaDA demonstrated that a single diffusion framework can jointly model multiple modalities; however, its decoding process remained sequential across modalities. To overcome this limitation, this paper proposes a parallel multimodal diffusion framework that: (i) represents all modalities as discrete tokens, (ii) arranges them in an interleaved sequence with bidirectional attention, and (iii) employs a cross-modal shared single masking predictor to enable synchronous denoising of text and images. An overview of the framework is shown in Figure 3.
 Figure 3: Parallel Generation Architecture: (a) During training, image and text responses are masked and predicted in parallel using a unified masking predictor, optimized with a masked token likelihood objective. (b) During sampling, the model performs parallel decoding, jointly generating image and text responses to enable efficient multimodal response generation.
Figure 3: Parallel Generation Architecture: (a) During training, image and text responses are masked and predicted in parallel using a unified masking predictor, optimized with a masked token likelihood objective. (b) During sampling, the model performs parallel decoding, jointly generating image and text responses to enable efficient multimodal response generation.
Interleaved Discrete Sequence Layout: Following the MMaDA framework, this paper processes text and images within a unified discrete token space. Specifically, text is tokenized using the LLaDA tokenizer, and images are encoded into discrete visual token grids using a pre-trained MAGVIT-v2 quantizer. These tokenized modalities are then serialized into a single interleaved sequence, using explicit separators (sentinels) and task labels to enable full bidirectional cross-modal attention:

During training, this paper concatenates input and output templates into a single sequence, allowing the model to attend from outputs to inputs within a unified context. The task token <|task|> is instantiated differently according to various scenarios, with <|thinkgen|> used for 'thinking-aware' generation and <|thinkedit|> for 'thinking-aware' editing. This single-sequence design eliminates the sequential asymmetry and exposure bias introduced by autoregressive cross-modal flows.
Training objective. Let 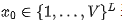 denote the concatenated training sequence (input part followed by output part), where
denote the concatenated training sequence (input part followed by output part), where  is the total number of tokens in the sequence. This paper keeps the input part unchanged and only applies noise to the output part. At a sampled time step
is the total number of tokens in the sequence. This paper keeps the input part unchanged and only applies noise to the output part. At a sampled time step 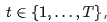 , for each token in the output part, this paper replaces it with [MASK] with probability
, for each token in the output part, this paper replaces it with [MASK] with probability 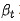 and keeps it unchanged with probability ; tokens in the input part remain unchanged:
and keeps it unchanged with probability ; tokens in the input part remain unchanged:

Equivalently, when considering a specific position in the output, the marginal distribution of the absorbing state after t steps is represented as 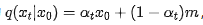 , where
, where 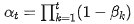 denotes the one-hot distribution corresponding to [MASK].
denotes the one-hot distribution corresponding to [MASK].
The parallel diffusion model 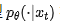 is designed as a unified mask-token predictor that operates over the combined vocabulary of text and image tokens. Let
is designed as a unified mask-token predictor that operates over the combined vocabulary of text and image tokens. Let  represent the token positions within the concatenated input-output sequence. Given that only the output portion is subjected to noise during the diffusion process, the model's task is to predict the true token at the currently masked position. To achieve a more balanced training dynamic across different modalities, this paper introduces modality-specific time step-dependent loss weights. Specifically, tokens within the output image section and output text section are assigned independent weights
represent the token positions within the concatenated input-output sequence. Given that only the output portion is subjected to noise during the diffusion process, the model's task is to predict the true token at the currently masked position. To achieve a more balanced training dynamic across different modalities, this paper introduces modality-specific time step-dependent loss weights. Specifically, tokens within the output image section and output text section are assigned independent weights  , respectively. For simplicity, this paper employs a unified, token-aware weight function
, respectively. For simplicity, this paper employs a unified, token-aware weight function  to encapsulate the objective function. The paper optimizes a time step-reweighted cross-entropy loss, which is expressed as:
to encapsulate the objective function. The paper optimizes a time step-reweighted cross-entropy loss, which is expressed as:

Here, 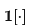 functions as an indicator function, and
functions as an indicator function, and
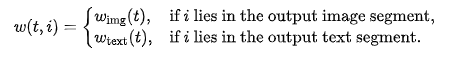
Empirical evidence presented in this paper indicates that applying a time step-varying weight 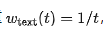 to text tokens and a constant weight
to text tokens and a constant weight 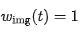 to image tokens significantly enhances the stability of the training process, particularly in terms of image quality and output alignment. This process is illustrated in Fig. 3(a), with detailed preliminaries and ablation studies provided in Appendix D.
to image tokens significantly enhances the stability of the training process, particularly in terms of image quality and output alignment. This process is illustrated in Fig. 3(a), with detailed preliminaries and ablation studies provided in Appendix D.
Parallel denoising with dual schedulers. The decoding process unfolds along a shared diffusion timeline  , as depicted in Fig. 3(b). This paper introduces two modality-specific schedulers,
, as depicted in Fig. 3(b). This paper introduces two modality-specific schedulers, 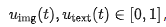 , which delineate the target proportion of unmasked tokens at each step t. During each reverse step, the model (i) jointly predicts the distribution for all currently masked positions; (ii) for each modality, samples a portion of tokens (e.g., through confidence-based sampling), while the remaining positions retain the [MASK] token. Given that attention operates bidirectionally across the entire sequence, text and image can mutually inform each other at every decoding step. In our experiments, the text scheduler is implemented as a fully linear revelation scheduler combined with semi-autoregressive confidence-based decoding, whereas the image scheduler adheres to a cosine revelation scheduler with global confidence-based decoding.
, which delineate the target proportion of unmasked tokens at each step t. During each reverse step, the model (i) jointly predicts the distribution for all currently masked positions; (ii) for each modality, samples a portion of tokens (e.g., through confidence-based sampling), while the remaining positions retain the [MASK] token. Given that attention operates bidirectionally across the entire sequence, text and image can mutually inform each other at every decoding step. In our experiments, the text scheduler is implemented as a fully linear revelation scheduler combined with semi-autoregressive confidence-based decoding, whereas the image scheduler adheres to a cosine revelation scheduler with global confidence-based decoding.
Post-training with parallel reinforcement learning
Supervised fine-tuning for parallel synthesis. A pivotal challenge in our approach lies in the absence of inference trajectories required by the parallel synthesis framework within existing generation and editing datasets. To overcome this, we initially construct a suitable training dataset by aggregating samples from diverse sources. For each sample, which includes an input image (for editing tasks), an instruction, and a final output image, we utilize a multimodal large language model (Qwen-2.5-VL in our implementation) to generate the corresponding inference trajectory. Further details on the dataset construction process, including sources and categories, are provided in Appendix F. Subsequently, we employ this dataset for the supervised fine-tuning of MMaDA, transforming it into a parallel variant capable of "think-aware" synthesis, where reasoning and generation occur concurrently.
Synergistic effects on denoising trajectories. Upon analyzing the generation results of the fine-tuned model, we observe the synchronous emergence of certain semantic concepts in both text and image during intermediate denoising steps. As illustrated in Fig. 5, when the task involves transforming a shirt into "vivid rainbow colors," specific color terms and their corresponding visual features manifest simultaneously at the same time step. This observation leads to a crucial insight: cross-modal alignment is not a phenomenon confined to the endpoint but is gradually established throughout the generation trajectory. Consequently, applying supervision to these intermediate steps, rather than solely to the final output, can further enhance such alignment.
 Fig. 5: Demonstration of the sampled synergistic effect. Specific color decoding in both text and image occurs simultaneously at the same step for the prompt "Replace the blue shirt with vivid rainbow colors"
Fig. 5: Demonstration of the sampled synergistic effect. Specific color decoding in both text and image occurs simultaneously at the same step for the prompt "Replace the blue shirt with vivid rainbow colors"
Parallel reinforcement learning with trajectory optimization. Building upon this insight, we introduce Parallel Reinforcement Learning (ParaRL), a novel training paradigm that directly leverages the cross-modal synergistic effect at intermediate steps. ParaRL rewards not only the final output but also utilizes the degree of alignment between text and image tokens at each denoising step as a dense reward signal.
Specifically, for a given query, the generated response constitutes a complete trajectory, where represents the total number of denoising steps, and denotes the set of tokens decoded at step . Although this form facilitates step-level rewards for each intermediate response, optimizing the entire dense trajectory is computationally infeasible. To render training feasible, we adopt a sparse optimization strategy. During each online rollout, we pre-select a sampling step count and fix a subset of step indices , computing rewards and their corresponding normalized advantages solely at these time steps. We employ a diffusion GRPO objective function that adapts to token-level likelihood ratios and computes advantage values over these sampled steps:
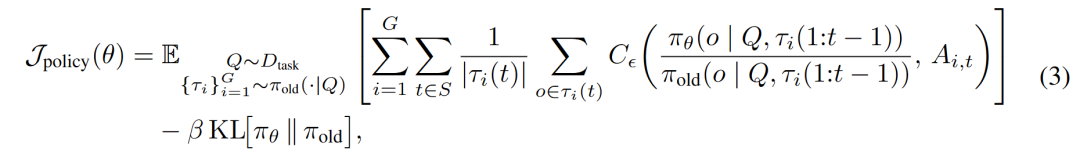
where . In this objective, the summation is conducted over the sparsely sampled steps . The term iterates over all tokens in the state at the sampled step, while represents the complete history of all tokens generated before step . Finally, denotes the behavior policy utilized to generate deployment samples, and controls the strength of the KL penalty.
Trajectory reward design. In conventional trajectory-level optimization frameworks, a well-trained process reward model (PRM) or value function is typically required, as intermediate partial outputs often lack sufficient semantic information for reliable evaluation. Surprisingly, in our parallel text-image generation setting, we discover that intermediate fragments already possess semantic meaning. For instance, even partially decoded text tokens frequently suffice to reveal semantic cues, enabling the calculation of alignment with simultaneously generated image content, as shown in Fig. 4. This observation allows us to circumvent the need for a dedicated PRM by directly utilizing semantic alignment between text and image as the reward signal.
 Fig. 4: Overview of our proposed Parallel Reinforcement Learning (ParaRL). Rather than focusing solely on the final denoising output, ParaRL introduces reward signals throughout the entire denoising trajectory, continuously reinforcing semantic consistency during the generation process.
Fig. 4: Overview of our proposed Parallel Reinforcement Learning (ParaRL). Rather than focusing solely on the final denoising output, ParaRL introduces reward signals throughout the entire denoising trajectory, continuously reinforcing semantic consistency during the generation process.
Unlike tasks with binary rewards (e.g., mathematical reasoning), our cross-modal alignment objective provides a continuous reward signal. However, the raw CLIP scores that serve as the reward source may exhibit high variance and arbitrary scales, rendering them unstable for direct use in reinforcement learning. To ensure training stability, we adopt a normalization scheme inspired by previous work in continuous reward RL. We initially estimate the mean and standard deviation of CLIP scores on the training distribution, computed over a random 1% data subset. Let denote the raw CLIP score for content generated at step . We standardize this score using . Subsequently, we clip this standardized score to the range and linearly scale it to obtain the final reward , which is bounded within the range:

The corresponding advantage utilized in Equation 3 is then derived through standardization over deployment samples: 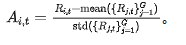 .
.
Experiments
Our main evaluations were conducted on the self-built ParaBench benchmark, with GPT-4.1 serving as the "judge" to assess six fine-grained metrics. MMaDA-Parallel was compared against multiple state-of-the-art models, including Bagel, GPT-4o, Gemini-2.5, among others.


Main results: As depicted in Table 2, MMaDA-Parallel achieves the highest output alignment score among all open-source models, validating the effectiveness of its parallel decoding and trajectory-level optimization. Despite having a significantly smaller training dataset than Bagel, MMaDA-Parallel matches it in terms of general text and image quality. Compared to top proprietary models (e.g., GPT-4o), our work substantially narrows the gap in alignment metrics, demonstrating superior data efficiency. Additionally, the ParaRL phase consistently enhances text-image consistency in outputs, indicating that trajectory-level optimization effectively strengthens cross-modal grounding throughout the generation process.

Key Contribution Analysis: This paper addresses two core research questions through ablation experiments:
Is parallel decoding superior to sequential decoding? The experiment (Table 3) demonstrates that our parallel framework significantly outperforms the sequential generation baseline on key alignment metrics, validating that parallel, interactive decoding is crucial for reducing error propagation and producing coherent multimodal outputs. Is trajectory-level fine-tuning superior to output-level fine-tuning? The experiment (Table 4) reveals that, compared to traditional RL that computes rewards solely at the final output, our proposed ParaRL (trajectory-level optimization) yields more substantial gains in text-image consistency and output alignment, with more stable training dynamics. Further analysis (Table 5) indicates that sampling 3 steps () in the trajectory for reward computation represents the optimal balance between performance and efficiency.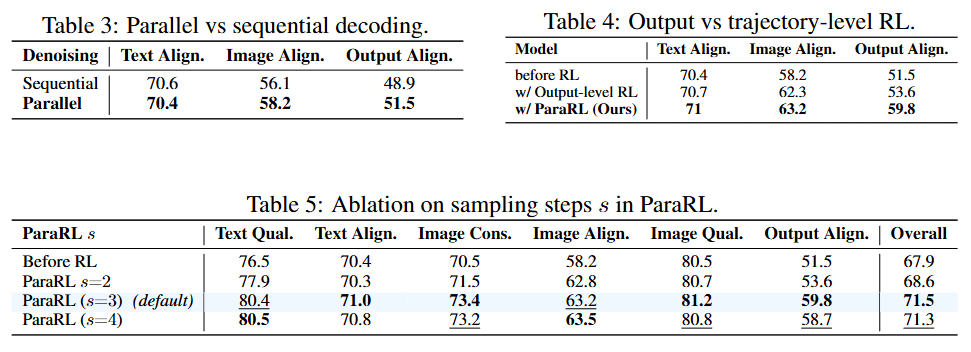
Summary
This work investigates a critical phenomenon where sequential 'thinking-aware' models may exhibit anomalous performance degradation when tackling complex tasks. We conducted an in-depth analysis using our self-proposed ParaBench benchmark, which uniquely evaluates two output modalities, and uncovered a strong correlation between performance degradation and poor alignment between generated modalities. To address this issue, we propose a parallel multimodal diffusion framework trained via supervised fine-tuning and further optimized using Parallel Reinforcement Learning (ParaRL)—a novel approach that applies rewards along the entire denoising trajectory. Experiments confirm that our method significantly enhances cross-modal alignment and semantic consistency, establishing a more robust paradigm for 'thinking-aware' image synthesis.
References
[1] MMADA-PARALLEL: MULTIMODAL LARGE DIFFUSION LANGUAGE MODELS FOR THINKING-AWARE EDITING AND GENERATION
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






