NUS and Others Release WEAVE: The First Complete Solution for Context-Interleaved Cross-Modal Understanding and Generation
 11/18 2025
11/18 2025
 690
690
Interpretation: The Future of AI Generation
Key Highlights
Dataset Innovation: WEAVE-100k—the first large-scale dataset for multi-turn context-aware image understanding and generation. It includes 100,000 samples, 370,000 dialogue turns, and 500,000 images, comprehensively covering image understanding, editing, and generation tasks.
Evaluation Framework Construction: WEAVEBench is the first human-annotated evaluation benchmark for interleaved multimodal understanding and generation tasks. The benchmark contains 100 carefully designed test cases and innovatively adopts a hybrid VLM evaluation framework to systematically assess multi-turn generation, visual memory, and world knowledge reasoning capabilities.
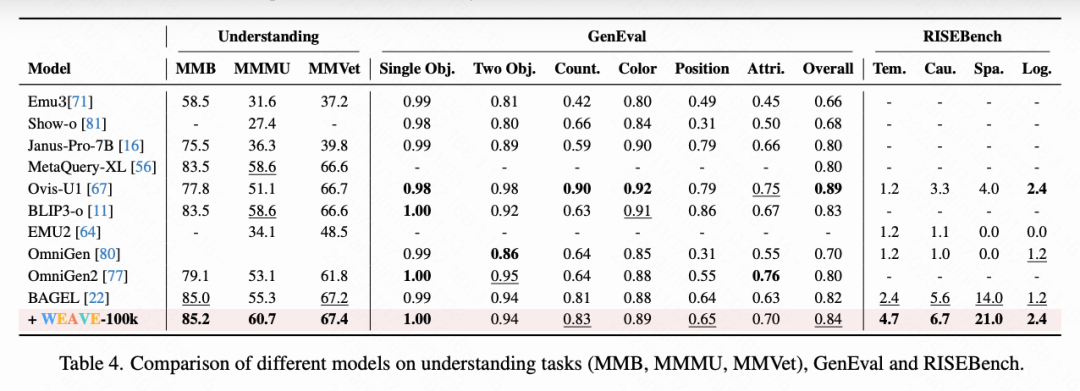
Empirical Research Breakthrough: Verified that training based on WEAVE-100k significantly enhances model performance on traditional benchmarks and effectively elicits the emergence of visual memory capabilities. WEAVEBench evaluation results reveal persistent technical limitations in existing models regarding multi-turn context-aware generation.
Summary Overview
Problems Addressed
Core Limitation: Existing unified multimodal model datasets and benchmarks primarily target single-turn interactions, failing to support research and evaluation of real-world image creation and editing processes involving multi-turn and contextually related interactions.
Proposed Solution
Core Solution: Introduced a complete solution named WEAVE, the first research framework for context-interleaved cross-modal understanding and generation.
Components:
WEAVE-100k: A large-scale dataset containing 100,000 samples, 370,000 dialogue turns, and 500,000 images, covering understanding, editing, and generation tasks requiring historical context reasoning.
WEAVEBench: A human-annotated benchmark testing platform with 100 tasks (based on 480 images) for systematically evaluating model capabilities.
Applied Technologies
Hybrid VLM Evaluation Framework: In WEAVEBench, innovatively combines reference images and the "original image + editing instructions" approach for comprehensive evaluation.
Multi-Task Dataset Construction: In the WEAVE-100k dataset, integrates three task dimensions—understanding, editing, and generation—while requiring models to perform historical context reasoning.
Achieved Effects
Capability Enhancement: Training based on WEAVE-100k effectively improves models' visual understanding, image editing, and understanding-generation synergy capabilities while promoting the emergence of visual memory as a new capability.
Evaluation and Findings: WEAVEBench evaluations reveal persistent technical limitations in current advanced models regarding multi-turn context-aware image generation and editing.
Community Contribution: Provides a new perspective and critical foundational support for multimodal community research on context-interleaved understanding and generation.
WEAVE
To evaluate context-interleaved understanding and generation capabilities, this paper first introduces the data collection processes for WEAVE-100k and WEAVEBench, followed by detailed descriptions of evaluation settings and metrics, and presents core statistical data for WEAVE.
Data Collection
To generate diverse data with visual memory capabilities, this paper constructs a data pipeline as shown in Figure 3. The pipeline includes four independent generation paths and undergoes multiple filtering and optimization stages to ensure data accuracy and quality. To generate multi-turn editing data with visual memory capabilities, this paper implements four methodological paths: (i) Multi-image fusion: Achieves historical iterative referencing by fusing edited or directly generated images; (ii) Removal and restoration: Uses techniques of first removing/replacing objects and then re-adding them to enable the system to recall previously deleted visual elements; (iii) Derivative imagination and comparison: Introduces derivative methods of deducing alternatives or generating new images before fusion; (iv) Sequential workflow: Implements serialized editing according to narrative progression or structured editing operations.
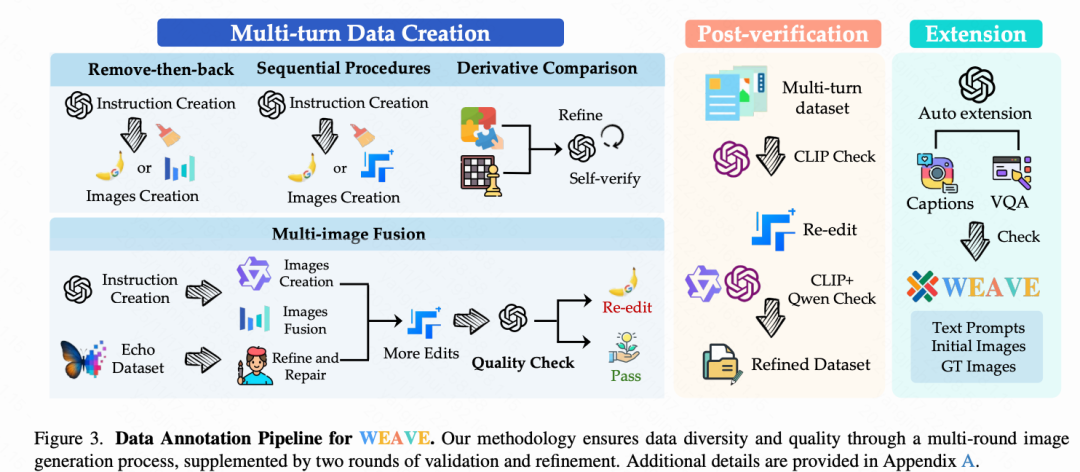
WEAVEBench is annotated by personnel with STEM graduate degrees. The benchmark contains 100 test items across 16 task categories, covering both multi-turn editing tasks requiring visual memory and challenging tasks requiring world knowledge (cultural backgrounds, physical phenomena, and chemical processes). As shown in Figure 2, tasks include generating instances involving the Tokyo Tower and demonstrating understanding of traffic signal responses. The images used include network-sourced content as well as synthetic images generated by three models: Seedream 4.0, Nano Banana, and SeedEdit 3.0.

Evaluation Settings and Metrics
This paper adopts the VLM-as-judge automatic evaluation framework. To achieve focused evaluation, this paper employs a keypoint-based structured scoring method: guiding VLMs to evaluate simultaneously based on reference images and the "original image + editing instructions" combination through a hybrid strategy. As shown in Figure 5, the evaluator calls different images as references and scores based on preset keypoints.
This paper's evaluation includes four metrics (the first three apply to editing tasks, and the last applies to understanding tasks):
Keypoint Correctness (KP): Measures whether the edited image meets specified editing requirements.
Visual Consistency (VC): Ensures non-target elements remain unchanged, maintaining consistency with the original image (complete preservation of unedited regions in scene retention; stylistic coordination in edited regions during scene modification), and evaluates identity preservation of edited objects.
Image Quality (IQ): Assesses the overall quality of generated images.
Accuracy (Acc): Measures the correctness of reasoning results.
Data Statistics
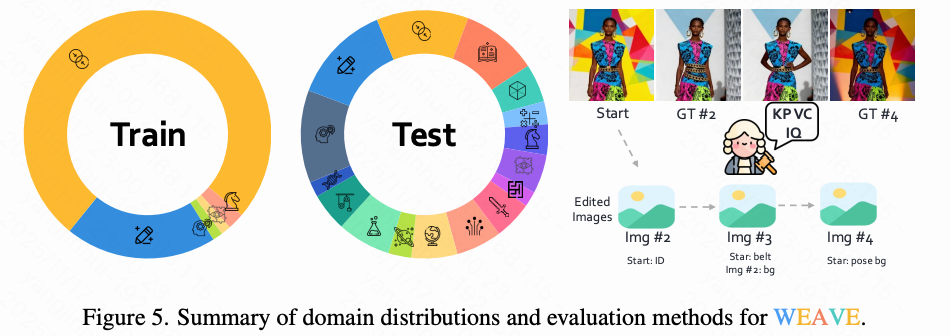
For each instance in WEAVE, this paper provides textual prompts, one or more initial images, and real examples. The test set also includes key information that correct output images must satisfy.
Appendix D provides representative dataset examples. Table 4 below shows key statistics for the training set. Most instances contain more than five images, with an average of 3.8 dialogue turns per instance. Figure 5 above displays the category distribution for the training and test sets, showing a relatively balanced distribution across data types.
Experiments
First evaluated the performance of 22 models on WEAVEBench, finding that current models struggle with context-interleaved generation and experience performance degradation as content length increases. Subsequently, this paper verified the high-quality characteristics of WEAVE-100k through fine-tuning Bagel. Finally, a quality analysis was conducted, and the effectiveness of the evaluators was assessed.
WEAVEBench
Settings. As shown in Table 2 below, this paper evaluated 4 LLMs, 7 editing models, and 11 UMMs on WEAVEBench. Evaluations were conducted under three different context conditions: (1) No context (single-turn generation without contextual information), (2) Partial context (using only self-generated images and explicitly mentioned visual contexts, excluding other historical interactions), (3) Full context (all prior interactions visible). For image placement, this paper adopted two configurations: "first mention" (images appear at the first mention location) and "front-loaded" (all images integrated at the input beginning), with Table 2 reporting results for the latter. For models unable to process sequential format inputs, this paper implemented a concatenation scheme following previous work [19,89].
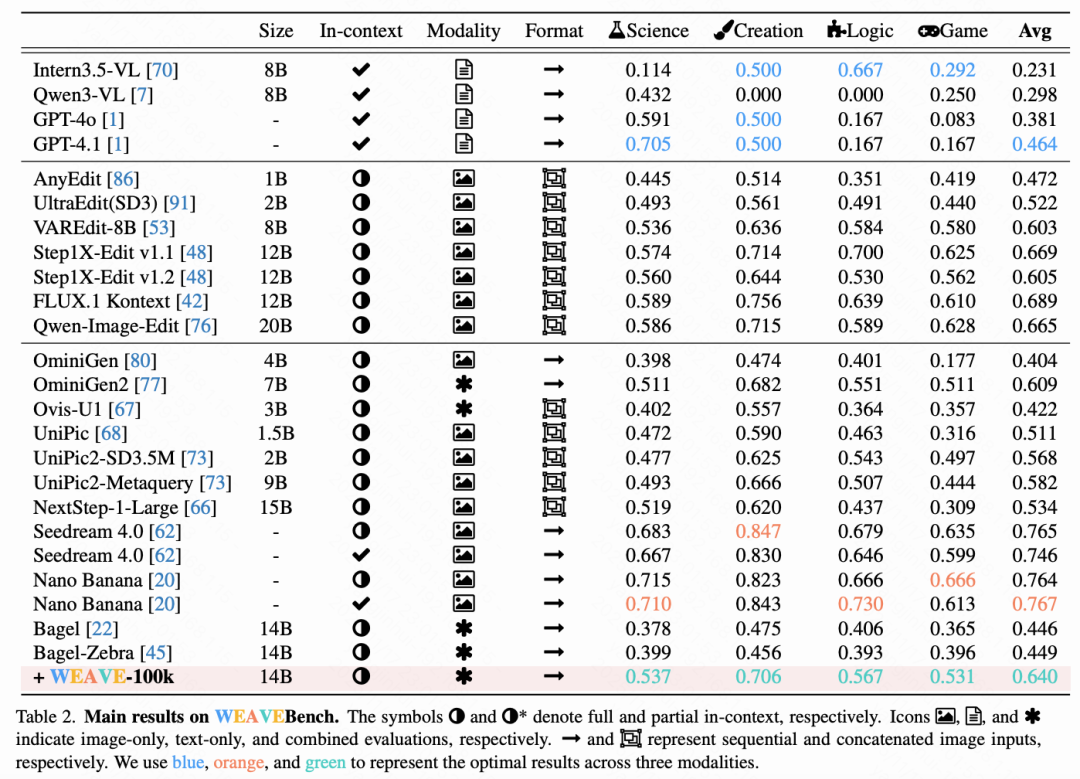
Based on the table results, this paper draws the following conclusions: Contextual image generation remains challenging. Among tested models, the best-performing editing model and UMM method achieved maximum scores of only 0.68 and 0.767, respectively. Additionally, significant domain bias was observed, with creative image domains consistently outperforming scientific and logical domains. This indicates substantial room for improvement in generating capabilities for effectively integrating world knowledge.
Context utilization is critical (a) For understanding tasks, using contextual information brings significant performance improvements compared to baseline conditions without historical context. As shown in Figure 6(a), QwenVL demonstrates a notable 163% improvement, indicating WEAVEBench's success in incorporating historical information into model evaluation. (b) For generation tasks, increasing contextual content produces differentiated effects across model types. Open-source models exhibit gradual performance declines as historical context increases—Qwen-Edit shows performance decreases of 5.3% and 8.6%, respectively. This suggests that open-source models, limited by single-turn editing capabilities, experience reduced positioning accuracy when processing extended contextual information and thus cannot effectively utilize contextual data. Conversely, closed-source models like Nano demonstrate progressive improvements, indicating successful utilization of contextual information. (c) WEAVEBench exhibits excellent image quality. As shown in Figure 6(b), using WEAVEBench real images as contextual examples enhances performance for all models. Notably, Qwen-Image-Edit shows a significant 7.1% improvement, possibly due to its inherently weaker generation capabilities compared to nano-banana [21].
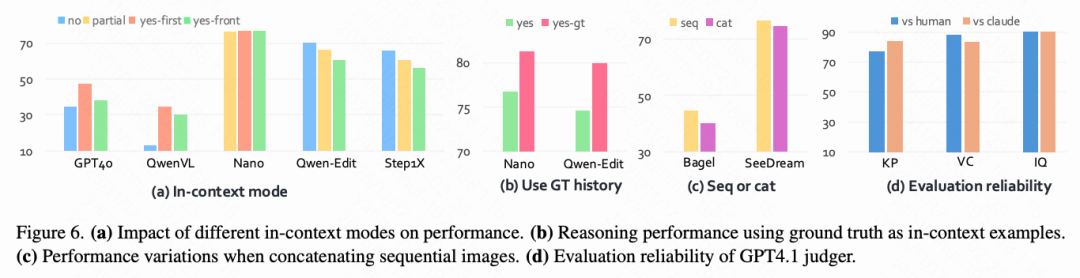
Advantages of sequential input. As shown in Figure 6(c), sequential image input demonstrates significant performance advantages over concatenated input. This effect is particularly pronounced in the Bagel model, where concatenated input leads to a 10.3% performance decline. These findings highlight the potential of UMM as effective editing models, especially considering traditional editing models cannot directly process multiple images and historical information as inputs.
WEAVE-100k Training
To verify data effectiveness, this paper conducted experiments on Bagel. Performance improvements were achieved across four task categories: (i) Visual understanding. This paper's data effectively enhances understanding task performance, particularly achieving a 9.8% improvement on MMMU. (ii) Image editing. As shown in Table 3 below, fine-tuned Bagel achieves a 4.8% overall score improvement on GEditBench. The model surpasses the baseline version in most tasks, with particularly notable improvements in material change (13.4%) and style change (15.6%) categories. (iii) Understanding-generation synergy. Table 4 above shows that fine-tuned Bagel achieves significant improvements in RISE cognitive tasks. Both spatial reasoning and logical reasoning tasks demonstrate 100% performance growth, indicating that the fine-tuned model more effectively utilizes understanding capabilities and world knowledge to enhance the generation process. These findings confirm the high-quality characteristics of the WEAVE-100k approach. (iv) Interleaved cross-modal understanding and generation. As shown in Table 2, this paper's fine-tuned model achieves a 42.5% improvement over Bagel on WEAVEBench. Performance on more challenging scientific questions improves by 34.6%, indicating that training with this dataset significantly enhances models' interleaved cross-modal understanding and generation capabilities.

Quality Analysis
As shown in Figure 7 below, through quality result analysis, this paper draws the following conclusions: (i) Instruction-following capabilities still require improvement. For example, in the left case of the figure, OmniGen and Ovis fail to correctly execute generation; in the right case's third column, Qwen-Image-Edit only generates the tower without including any human figures. (ii) Fine-tuning based on the WEAVE dataset elicits visual memory capabilities. The fine-tuned model correctly distinguishes between protagonists wearing pink and yellow clothes in the left case and demonstrates the ability to first remove human figures and then reintegrate them in the right case.

Reliability of Evaluator Usage
To assess the reliability of VLM-as-a-judge scoring, an expert evaluation study was conducted, inviting three human experts to perform cross-evaluations on Nano-banana, Qwen-Image-Edit, and SeeDream models, analyzing 100 instances per model. By calculating the Pearson correlation coefficient between GPT-4.1 scores and expert scores and comparing with Claude Opus 4.1 evaluation results (Figure 6 above), the findings show: GPT-4.1 maintains consistent correlation with human scores exceeding 0.8, while Claude evaluations demonstrate strong cross-VLM consistency, indicating that the specific choice of VLM evaluator has minimal impact on evaluation results.
Conclusion
WEAVE—the first comprehensive suite for in-context interleaved cross-modal understanding and generation. It introduces a large-scale dataset, WEAVE-100k, comprising 100,000 samples, 370,000 dialogue turns, and 500,000 images, along with a manually annotated benchmark WEAVEBench consisting of 100 tasks (including 480 images) and equipped with a hybrid VLM judge evaluation framework. Experiments demonstrate that training based on WEAVE-100k achieves significant improvements on multiple authoritative benchmarks: a 9.8% increase on MMMU and a 4.8% increase on GEditBench, while also fostering the emergence of visual memory capabilities in UMM. Meanwhile, extensive evaluations on WEAVEBench reveal that current models still struggle with multi-turn context-aware generation, particularly as content length increases. Additionally, this challenging task has proven to be beyond the capabilities of traditional editing models. WEAVE lays the foundation for research on in-context interleaved multimodal understanding and generation and underscores the urgent necessity for development in this field.
References
[1] WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






