Alibaba, the Global No. 1!!!
 06/28 2024
06/28 2024
 765
765
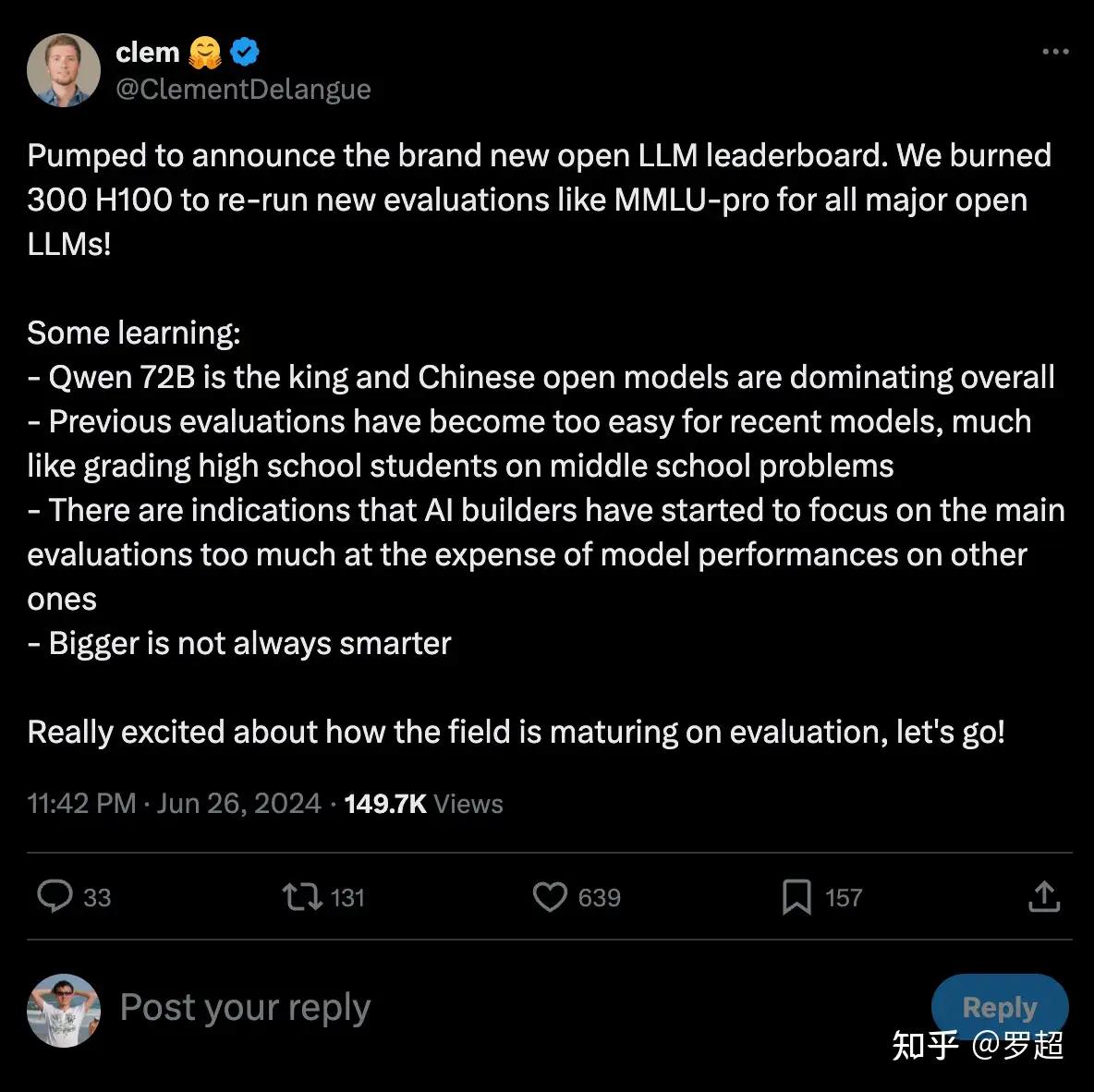
Recently, Clem, the co-founder and CEO of the globally renowned open-source platform HuggingFace (smiley face), announced on a social media platform that Alibaba's newly open-sourced Qwen2-72B instruction-tuned version has retained its championship position, continuing to rank first on the global open-source model rankings.
At a time when OpenAI has rejected Chinese developers, this "first place" came at a very opportune moment.
First, Chinese developers have collectively "returned home" from OpenAI, and domestic large model providers have rolled out migration solutions to welcome them. As discussed in the article "OpenAI Rejects Chinese Developers, 'Hundred Model War' Fully Enters the Second Half" by Leitech, over 10 large model providers have launched various services to "snatch customers".
However, in many people's inherent impression, Chinese large model providers are merely "substitute versions" that are barely usable when there's no other choice. Some even say that GPT is like a high-speed train, while domestic large models are tractors; while both can run, they are actually different.
In fact, this is a bias. In many fields, domestic large models have already achieved world-class competitiveness, especially open-source large models.
What is a large model with world-class competitiveness? There are two types:
One is the player who claims to comprehensively surpass GPT4 at every press conference, never losing in terms of parameters but never winning in evaluations. This is self-promotion and boasting.
The other type is the one that has achieved a ranking on authoritative lists. HuggingFace is the world's most authoritative open-source model list, and it has given "official recognition" to Alibaba Cloud's Qwen2, or provided "authoritative certification".
Second, why can HuggingFace be the world's most authoritative open-source model list?
This definition is not given randomly but is related to the background of the platform. HuggingFace is not a large model provider but the world's most popular open-source community for large models and datasets. Developers can obtain open-source code for large models and datasets for training here. It can be said that HuggingFace is basically unavoidable for AI development, and it is also known as GitHub for large models/machine learning.
In other words, HuggingFace is more like an application, distribution, and publication platform for large models. Large models from giants like Microsoft, Facebook, Tesla, etc., are all published on HuggingFace. For example, at Microsoft's Build conference recently, Nadella announced that Microsoft released the Phi-3-medium, Phi-3-small, and Phi-3-vision series models on Huggingface. Among them, Phi-3-medium-128k-instruct is currently the best model available on consumer-grade hardware.
With a vast amount of open-source large models and datasets, as well as a large number of AI developers and usage data, HuggingFace can create the industry's most authoritative open-source model list. This is fundamentally different from lists created by media or specialized third-party evaluation agencies. Many evaluation lists originate from such "third parties," and aside from authority, objectivity, and neutrality, their professionalism may also be greatly discounted.
Now that we have clarified the authority of the HuggingFace list, let's take a look at how powerful Alibaba Cloud's Qwen2 is.
Third, why did HuggingFace release two lists in June? What is the significance of List V2?
In fact, on June 7th this year, HuggingFace also released a list, with Qwen2 ranking first at the time. Why was the list updated to V2? HuggingFace said that "the test sets within the list are harder, better, faster, and stronger." Therefore, the evaluation of the models is also more convincing.
In fact, the process of evaluating large models based on test datasets can be figuratively described as "taking a test." It's similar to our exams. However, the problem is that the test questions are open. Therefore, a situation arises: many large models will "practice test questions" by training the model several times to obtain good evaluation scores. Some companies will employ human "data annotators" to do the questions and provide the answers to the large models, while other companies will let GPT-4 answer the questions and then use the answers to train their own large models, allowing the large models to achieve "full marks." Many large models can achieve full marks and "rank first" to surpass GPT-4 right after their launch, and the mystery lies here.
In other words, open-source evaluation datasets are equivalent to "open-book exams" in college entrance examinations. Unless it's a particularly open-ended question (such as a job interview), test takers can targetedly practice test questions and memorize answers in advance, and the final scores naturally cannot reflect their true level.
HuggingFace also pointed out in a technical blog post, "Over the past year, the benchmark indicators of the Open LLM Leaderboard have been overused, resulting in several issues: the questions have become too simple for the models; some newly emerging models show signs of data pollution; and some evaluation benchmarks contain errors. Therefore, the platform has proposed a more challenging V2 list based on new benchmarks using uncontaminated, high-quality datasets and reliable metrics."
Now that the test datasets (questions) have undergone significant updates, with the latest test papers and exams, Alibaba Cloud's Qwen2 remains in first place. It is precisely because of this that Huggingface's co-founder and CEO, Clem, publicly stated that "Qwen2-72B is the king, and China is in a leadership position in the global open-source large model field." Without rigorous and sufficient testing, he would not have publicly given such a "thumbs up".
We look forward to HuggingFace's list being updated faster in the future, with faster updates to the test datasets, so that Alibaba Cloud's Qwen2 and domestic large models can continue to achieve better rankings.
With OpenAI not supporting Chinese developers, open-source large model vendors must quickly improve and bravely fill the gap. Now is an excellent opportunity for domestic large models and the domestic open-source large model ecosystem to be forced to accelerate progress and prove themselves.
-
![]()
From Huawei’s 49 Yuan Offering to Kimi’s 199 Yuan Plan: What’s a Fair Price for an “AI Agent” Subscription?
-
![]()
Liang Zhu's Copyright Moat is Being Overcome by Jiao Yubo Using AI
-
![]()
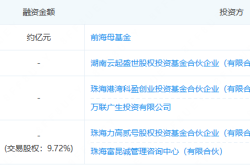
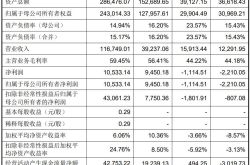
Match Rate Exceeds 99.7%! This Optical Enterprise Secures Nearly 100 Million Yuan in Exclusive Investment
-
![]()
Unitree Robotics IPO: A 'Pioneering' Leader?
-
![]()
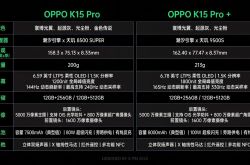
OPPO K15 Pro+ Review Unveiled: Gaming Vibes Abound, But Battery Life Steals the Show
-
![]()
The First IPO Among Hangzhou's Six Little Dragons: Three Silicon Valley Scholars' 14-Year Journey in Spatial Intelligence
-
![]()
I did cross-border business overseas alone with AI
-
![]()
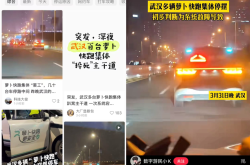
Hundreds of Luobo Kuaipao Robotaxis in Wuhan Come to a Halt! Does the Demise of Robotaxi's 'Safety Myth' Raise Alarms for Humanity?