China's AI Twins Shake Up Silicon Valley by Teaching OpenAI a Lesson
 01/23 2025
01/23 2025
 732
732
Written by | Hao Xin, Wu Xianzhi
Edited by | Wang Pan
The domestic large model community is currently witnessing a fierce competition. Did OpenAI wake up to find a world transformed?
On January 20th, DeepSeek unveiled the DeepSeek-R1 model without any prior warning. Within two hours, the new Kimi k1.5 model followed suit. Both models came with detailed technical training reports.
These two reasoning models, which comprehensively benchmark OpenAI o1, have achieved results that are on par with or exceed o1 in multiple benchmark tests. The DeepSeek-R1 text reasoning model is open-source and commercially available right out of the box. Kimi k1.5 supports both text and visual reasoning, excelling in all indicators and becoming the first multimodal model to reach the full version level of o1.
China's 'twin stars' in the large model community have suddenly made waves overseas, causing quite a stir in Silicon Valley. Many industry and academic leaders on social platform X have reposted and liked posts about DeepSeek-R1 and Kimi k1.5.
Jim Fan, an AI scientist at NVIDIA, posted a real-time summary of their similarities and differences, evaluating the published papers as "heavyweight" level.
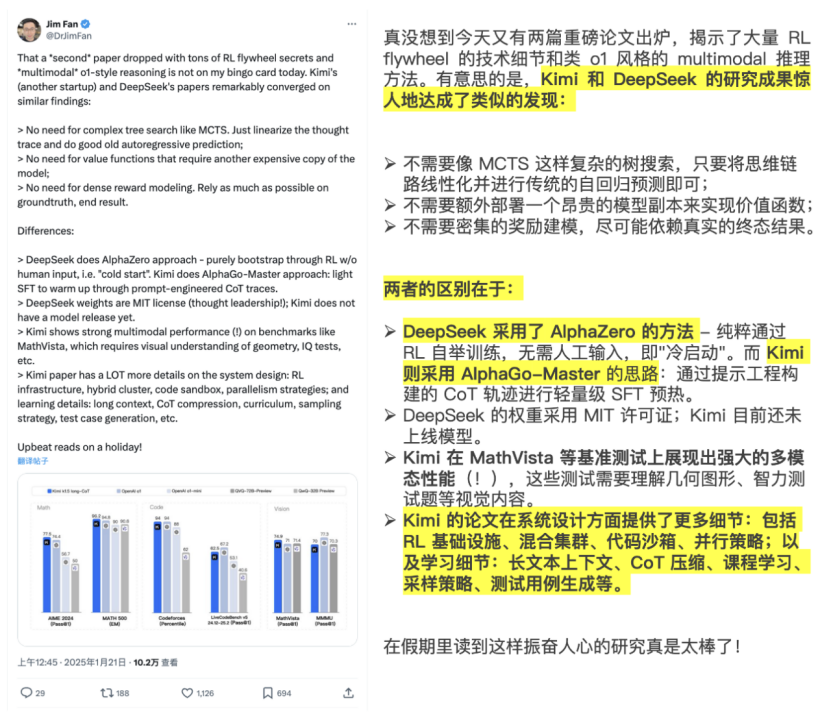
(Source: X)
(Source: X)
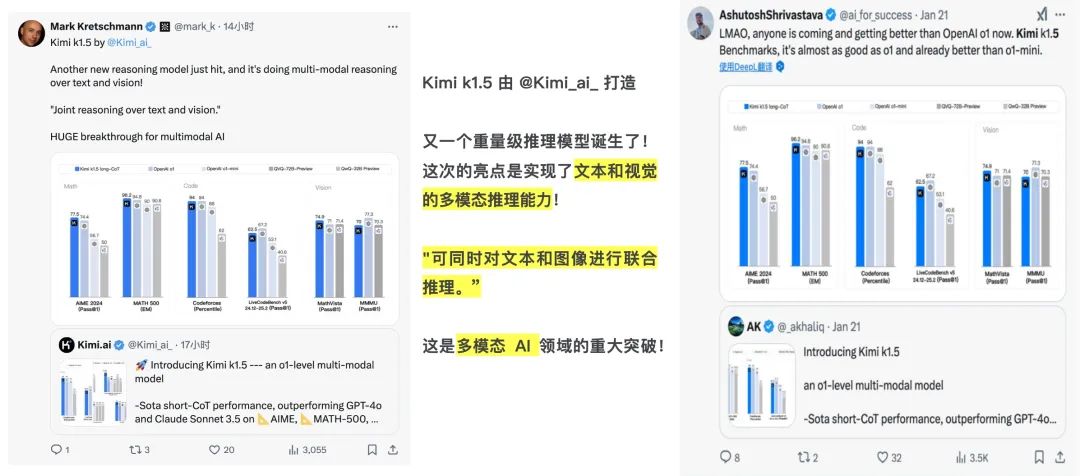
Multiple AI technology influencers have given affirmation to Kimi k1.5. Some have commented that "another heavyweight model has been born, with the highlight being its multimodal reasoning ability for text and vision, which is a significant breakthrough in the field of multimodal AI." Others have compared it to OpenAI o1, lamenting whether OpenAI has been dethroned, asking "Are more and more models defeating OpenAI o1?"
(Source: X)
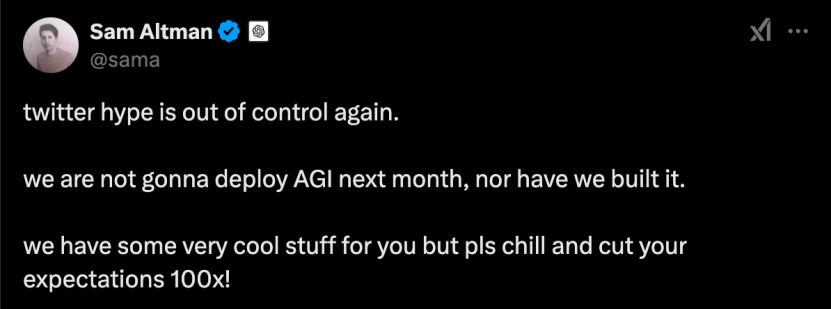
Faced with challengers from China, OpenAI CEO Sam Altman, who has been releasing futures in a slow and steady manner, posted on his personal account complaining about media hype around AGI, urging netizens to lower their expectations, saying "AGI will not be deployed next month, nor will it be built." Unexpectedly, this only angered netizens, who sarcastically accused him of "crying wolf".
Changes are indeed happening in the AI world. DeepSeek-R1 and Kimi k1.5 have validated the feasibility of the reinforcement learning (RL) approach and begun to challenge OpenAI's absolute leading position.
At the same time, Chinese local models are challenging the impossible and achieving overtaking by changing lanes, which is also a morale boost for the domestic large model industry. In the future, Chinese AI enterprises still have the opportunity to break Silicon Valley's technological monopoly and forge an independent technological path for China.
The True Full-Fledged o1 Has Arrived
Following the release of the k0-math mathematical model in November last year and the k1 visual thinking model in December, Kimi brought the K series reinforcement learning model Kimi k1.5 in the third consecutive month of upgrades.

According to the Kimi k-series thinking model roadmap, the evolution from k0 to kn is a comprehensive expansion of modalities and domains. k0 belongs to the textual state, focusing on the field of mathematics; k1 adds a visual state, becoming the first multimodal version of o1 outside of OpenAI, with its domain expanded to physics and chemistry; the upgraded k1.5 remains multimodal, which is also one of the prominent features of the Kimi model, and its domain has been upgraded from mathematics, physics, and chemistry to more commonly used and broader fields such as code and general-purpose applications.
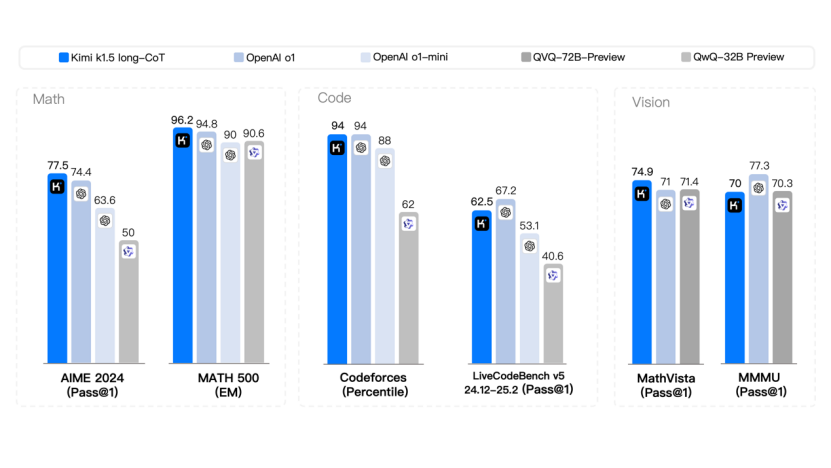
From the benchmark test results, the k1.5 multimodal thinking model achieves SOTA (state-of-the-art) level multimodal reasoning and general reasoning capabilities.
Many models claiming to reach the o1 level have been promoted domestically and internationally, but from the data, only the models released by Kimi and DeepSeek are truly full-fledged versions of o1. Other models released by various companies are still at the o1-Preview level, with a gap of 30%-40%.
Taking OpenAI o1 as the benchmark, it scores 74.4 points in mathematics and 67.2 points in programming, and supports multimodality. Reviewing the domestic reasoning models released based on this standard, Alibaba's QVQ, WISDOM's GML, iFLYTEK's Spark, and the Step series models are still at a certain distance from the actual o1 level. The DeepSeek and Kimi models both exceed OpenAI in mathematics and are close to o1 in programming. However, compared to DeepSeek, Kimi supports multimodal visual reasoning, while DeepSeek can only recognize text and does not support image recognition.
Specifically, in the short-CoT (short chain of thought) mode, Kimi k1.5 surpasses all other models. Its mathematics, code, visual multimodal, and general capabilities significantly surpass the global short-CoT SOTA models GPT-4o and Claude 3.5 Sonnet, leading by up to 550%.
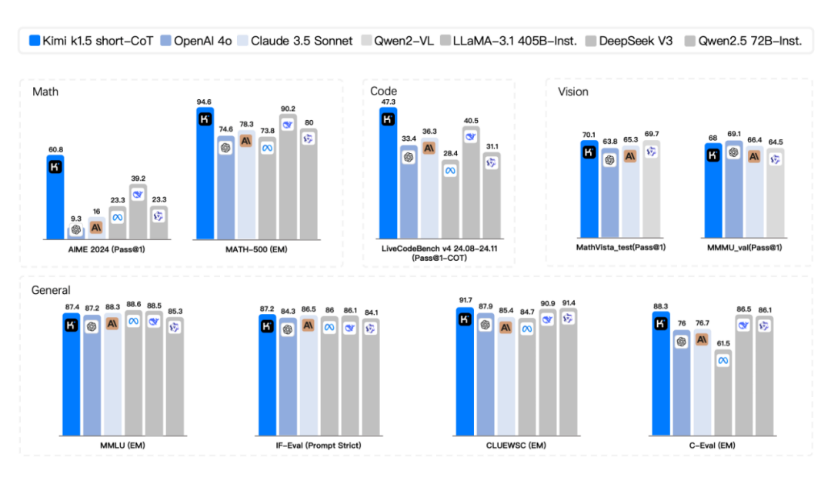
In the long-CoT (long chain of thought) mode, Kimi k1.5's mathematics, code, and multimodal reasoning capabilities also reach the level of the long-CoT SOTA model OpenAI o1 official version. It defeats o1 in two mathematics level tests (AIME 2024 and MATH-500) and ties with o1 in the programming level test (Codeforces). This should be the first time a company outside of OpenAI has achieved o1 official version multimodal reasoning performance globally.
The Secret to Kimi k1.5's Success
With support from both domestic and international communities and strength that withstands testing, how did Kimi hone its "super brain"?
After reviewing the informative technical report, it can be summarized as one training approach, one training scheme, and one training framework. Among them, efficient reasoning and optimization ideas run through it all.
Restricted by the limitation of data volume, the pre-training approach of "brute force" often encounters obstacles in real-world training. Since OpenAI o1, the industry has begun to shift training paradigms and invest more energy into reinforcement learning.
The previous approach can be understood as "direct feeding," where humans actively "feed" data to large models, supervise their work, and intervene in the "training" process of large models. However, the core idea of reinforcement learning is to allow large models to self-learn and evolve without excessive human intervention.
This time, Kimi's new model update adopts the reinforcement learning path. The training process proves that good model performance can be achieved without relying on Monte Carlo tree search, value functions, or process reward models.
The reinforcement learning approach is concisely embodied in the "Long2Short" training scheme, which is also the highlight of Kimi's technical report. According to its official introduction, the specific approach is to first utilize a larger context window to allow the model to learn long-chain thinking, then transfer the reasoning experience of the "long model" to the "short model," merge the two, and finally fine-tune the "short model" through reinforcement learning.
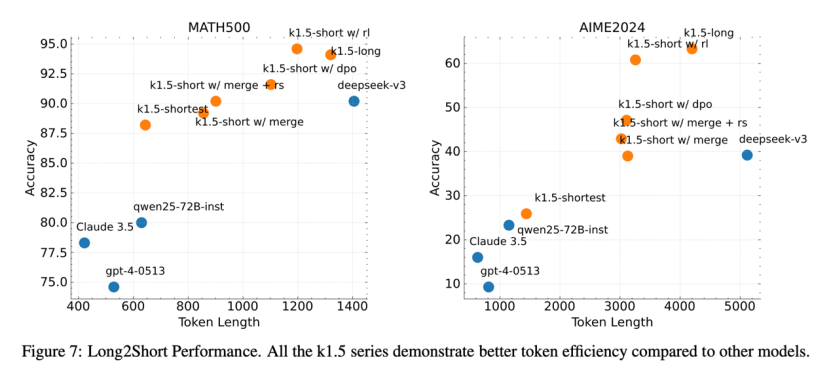
Caption: The closer to the top left, the better.
The advantage of this approach lies in its ability to improve token utilization and training efficiency, finding the optimal solution between model performance and efficiency.
From an industry perspective, Kimi's "Long2Short" training scheme is also a manifestation of "model distillation." Here, the "long model" is the teacher, and the "short model" is the student. The teacher imparts knowledge to the student, utilizing the large model to enhance the performance of the small model. Of course, Kimi also adopts some methods to improve efficiency, such as using multiple samples generated by the "long model," selecting the shortest correct solution as the positive sample, and the longer generation time as the negative sample, to form a control group training dataset.
To adapt to reinforcement learning training, Kimi k1.5 has specifically designed a special reinforcement learning framework to support the entire training system.
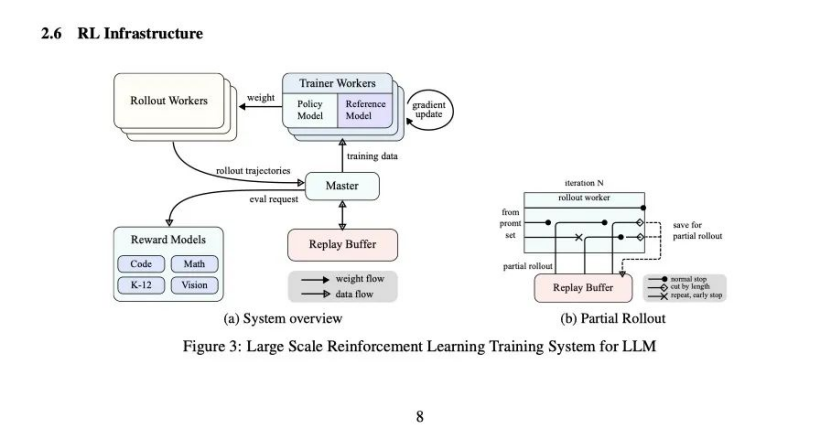
The k1.5 model supports a maximum context length of 128k. If the model has to complete a complete chain of thought generation and reasoning process each time, it will impact computational resources, memory storage, and training stability. Therefore, Kimi introduces "Partial Rollouts" technology, dividing the generated chain into multiple steps rather than completing it in one go.
The underlying AI infrastructure construction approach reflects DarkSideOfMoon's accumulation in long texts. How to maximize and efficiently utilize resources has always been a key issue it focuses on solving, and now this approach will be extended to chain of thought generation and reasoning.
Will China's 'Twin Stars' End the OpenAI Myth?
From Kimi and DeepSeek, we may be able to see several trends in future model training: increased investment and resource allocation towards reinforcement learning training; OpenAI o1 becoming the new threshold for large models entering the next stage, with those unable to keep up in technology and resources falling behind; long context technology being particularly important, serving as the basis for generating and reasoning long chains of thought; and the Scaling law not yet completely invalidated, with potential still existing in some areas, such as long contexts.
China's 'twin stars' have opened up OpenAI's black box. Previously, OpenAI defined four stages of large model training: pre-training, supervised fine-tuning, reward modeling, and reinforcement learning. Now, this paradigm has been broken. Both Kimi and DeepSeek have proven that certain steps can be skipped and simplified to improve model training efficiency and performance.
The impact of Kimi and DeepSeek is twofold. Going abroad, they prove to the overseas AI community, especially Silicon Valley, that continuous focus and dedication can yield miracles, and that China still has the ability to compete in the first tier of technology.
OpenAI should reflect on why, with such resources and a high concentration of talent, it has been surpassed by Chinese enterprises in many aspects. This may bring subtle changes to the world's competitive landscape. One can't help but ask, how long will OpenAI's first-mover advantage last? Not only does it have a rival in the same country, Anthropic, which has taken away its To B orders, but now it also needs to be vigilant against AI enterprises from China.
Domestically, a new landscape seems to be in the making. DeepSeek has received unprecedented attention with its open-source model that surpasses OpenAI in performance, and some have even begun to include it in the ranks of the "AI Six Little Tigers."
Compared to before, Kimi at this stage has a clearer technical roadmap from k0 to kn. Although it states that it will "focus on the Kimi product," what Kimi carries has far exceeded that of an ordinary AI application.
Kimi k1.5 has earned DarkSideOfMoon the ticket to the next stage, giving it more initiative in future competition. After maintaining a certain lead, the new goal for 2025 is to thrive even better.
A new round of reshuffling has quietly begun. Who will fall behind first, and who will be able to stand out?
WeChat ID | TMTweb
Official Account | Photon Planet
Don't forget to scan the QR code and follow us!
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





