Domestic AI Challenges Silicon Valley, with Altman Tweeting: "What Are All These o1-Like Models Competing For?"
 01/23 2025
01/23 2025
 763
763

The unveiling of two domestic reasoning models has ushered in an early festive atmosphere within the global AI community.
Just days ago, Dark Side of the Moon introduced the Kimi k1.5 multimodal thinking model, and DeepSeek released the DeepSeek-R1 text reasoning model. Both are benchmarked against OpenAI's official o1 in terms of reasoning capabilities.
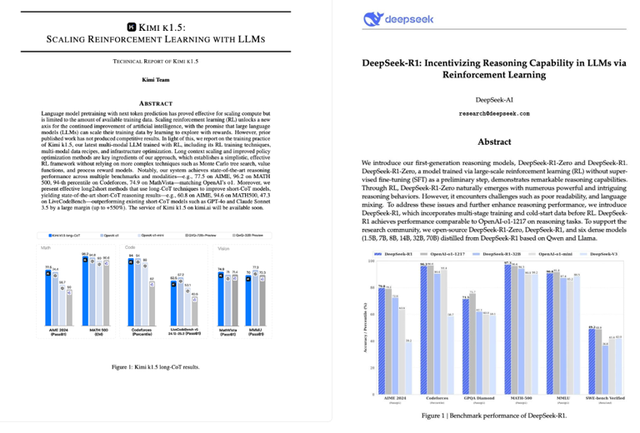
In less than two months, domestic reasoning models have achieved parity with OpenAI's fully-featured o1 (launched in December 2024). Unlike OpenAI, which keeps its technical secrets hidden, both Chinese companies have openly shared their unique technological insights: DeepSeek R1's exceptional cost-effectiveness and Kimi k1.5's original technology of long2short efficient chain of thought + native multimodal capabilities.
Consequently, Kimi and DeepSeek, the "binary stars," have overtaken Silicon Valley overnight. Upon the release of their technical reports, they garnered significant attention and interpretation from peers both domestically and internationally, skyrocketing in popularity on GitHub.
Currently, the feedback from overseas peers has been overwhelmingly positive. For instance, Paul Couvert, the founder of Answera, exclaimed that with the simultaneous release of two Chinese o1 models, the pace of Chinese AI's advancement is accelerating rapidly!
Of course, there have also been some skeptics.
OpenAI CEO Sam Altman tweeted, "Twitter hype is out of control." He believes that outside speculation about AI soon replacing most middle-tier jobs (primarily relying on reasoning models) is greatly exaggerated. He urged everyone to calm down and cut their expectations by 100 times.
Perhaps some may wonder, have domestic reasoning models truly risen? How has large model technology evolved from "scaling expansion" to "reasoning expansion"? Regarding the path of reasoning models, should we remain excited or take a step back and be calm? This article will provide detailed insights.

The new models from these two Chinese AI companies have garnered significant attention from peers both domestically and internationally. The reason is simple: reasoning models are extremely popular.
In the fourth quarter of 2024, a new form of reasoning model, LLM, emerged, employing a chain of thought for "slow thinking" and investing more computation in the reasoning stage (reasoning expansion approach). This innovation endows large models with advanced reasoning abilities, reducing hallucinations, enhancing reliability, and handling more complex tasks, achieving intelligence at the level of human experts/graduate students. It is considered the most promising new technology after the Scaling Law hit a wall.
Following the o1 series, leading model factories have begun to invest in the "slow thinking" reasoning model technology path, including major players like Google, Baidu, Alibaba, iFLYTEK, Quark, as well as AI startups such as Zhipu, DeepSeek, and Jieyue Xingchen. They have previously launched quasi-o1 reasoning models but have not fully benchmarked against the official o1 domestic reasoning model until now.
To prove the rise of domestic reasoning models, two prerequisites must be met: first, they must withstand scrutiny from global peers; second, they must possess original capabilities rather than simply following others, achieving full benchmarking rather than partial compliance.
Currently, Kimi k1.5 and DeepSeek R1 meet these conditions.
Kimi k1.5 and DeepSeek R1 have truly benchmarked the official o1 for the first time, achieving state-of-the-art (SOTA) results. Among them, k1.5 is also the first multimodal o1 in China, supporting both text and image reasoning. These are impressive achievements in the global reasoning model field.
Moreover, unlike OpenAI's secretive style with o1, Kimi and DeepSeek have released detailed technical reports sharing their exploration experiences in model training techniques, immediately sparking a wave of paper interpretation in the overseas AI community.
For example, research scientists at NVIDIA quickly analyzed the reports and concluded that the research by Kimi and DeepSeek is "exciting."
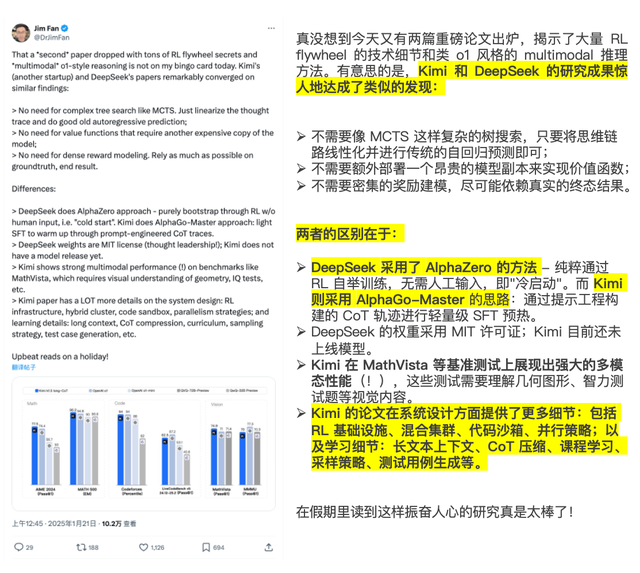
As the current mainstream narrative and technological high ground in the AI field, any movement in reasoning models attracts the attention of global practitioners. With two heavyweight papers in the reasoning model race, Chinese companies have presented models with high gold content that have undergone focused and rigorous scrutiny, including many original technologies.
It can be said that starting with the "binary stars" of Kimi k1.5 and DeepSeek R1, domestic reasoning models have truly risen.

How have domestic AI companies caught up in the realm of reasoning models? We, along with the overseas AI community, have stayed up late reading the Kimi and DeepSeek papers with bleary eyes and can briefly summarize as follows:
In general, both k1.5 and R1 utilize reinforcement learning (RL) technology to enhance the model's reasoning abilities. However, in terms of technical details, Kimi and DeepSeek have introduced entirely new concepts.
DeepSeek did not adopt the commonly used supervised fine-tuning (SFT) as a cold start solution but proposed a multi-stage cyclic training approach. Using a small amount of cold start data, the model is fine-tuned as the starting point for reinforcement learning and then self-evolves through reward signals in the RL environment, achieving excellent reasoning results.
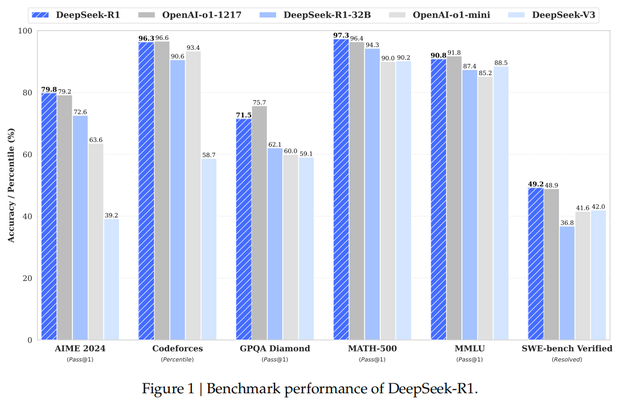
Kimi k1.5 pioneered the long2short chain of thought, allowing LLM to conduct exploratory learning through a reward mechanism, autonomously expanding training data to extend context length, thereby optimizing RL training performance and achieving SOTA results in short chain-of-thought reasoning.
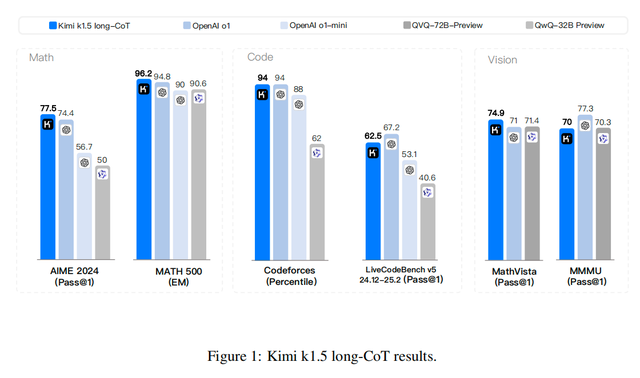
The most powerful long-CoT version of Kimi k1.5 can match the mathematical, coding, and multimodal reasoning capabilities of OpenAI's official o1, a long-thinking SOTA model. The simplified short-CoT version, based on the long-CoT version, still boasts impressive performance but is more efficient in reasoning, surpassing the global short-thinking SOTA models GPT-4o and Claude 3.5 Sonnet by a whopping 550%.
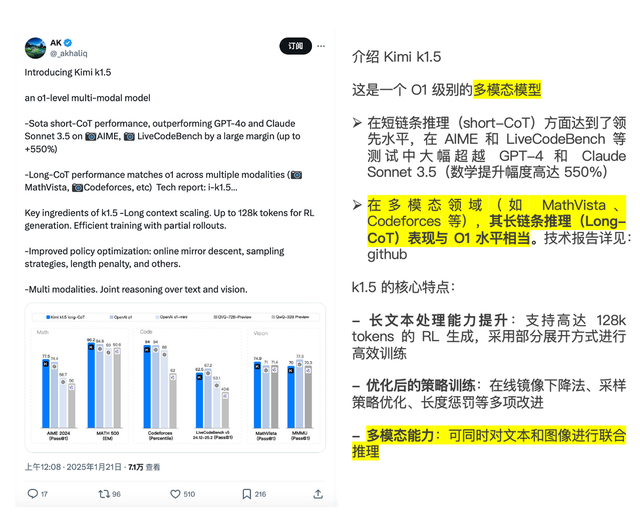
In addition, the two domestic reasoning models each have their unique selling points.
DeepSeek-R1 continues the excellent tradition of being the "Pinduoduo of AI," with an API pricing of 16 yuan per million output tokens, far surpassing the cost-effectiveness of o1, which charges 60 USD per million output tokens.
Kimi k1.5 is the first model outside of OpenAI to achieve o1's multimodal reasoning performance. k1.5 supports multimodal input that overlaps text and images, enabling joint reasoning, filling the gap in domestic multimodal thinking models.
Among human senses, visual information accounts for over 70%. With multimodal capabilities, understanding one's own Benchmark charts becomes a piece of cake.
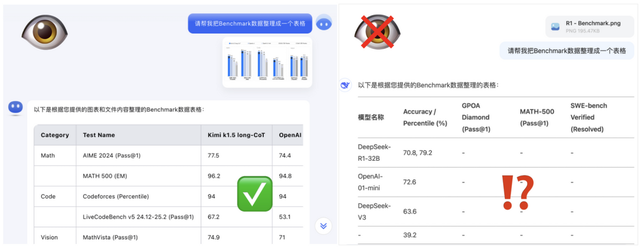
As everyone knows, o1 is either expensive to use (with a monthly subscription fee of 200 USD) or simply unavailable (as OpenAI does not provide services to China). Therefore, the aforementioned highlights of domestic reasoning models offer tremendous value to AI developers both domestically and internationally, exciting many developers.
One developer lamented on a forum that these two Chinese labs "do more with fewer resources. Their immense focus on model efficiency and refinement benefits us all."

Amarok developer Mark Kretschmann also praised k1.5 on social media, calling it a "major breakthrough in the field of multimodal AI."
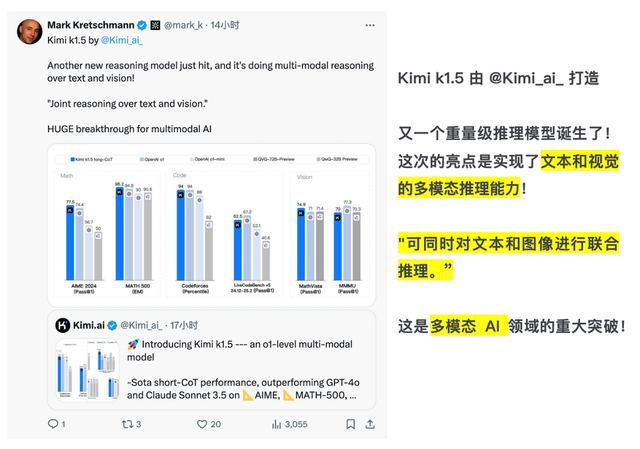
It is evident that in the face of the entirely new technological field of "reasoning expansion," China's AI "binary stars" have firmly secured their position with original hard power and forged a development and innovation path distinct from OpenAI's.

While OpenAI's Altman advises lowering expectations, what is the value and significance of Chinese AI companies' efforts in reasoning models?
For Chinese AI companies, illuminating the technological landscape of reasoning models has twofold significance:
First, by looking up at the stars, they can narrow the technological gap between Chinese and American AI. Leadership in large models does not come from nowhere but through persistent efforts. Keeping up with the latest technological trends allows the level of Chinese AI to rapidly improve. It took around six months to benchmark ChatGPT and less than three months to benchmark the official o1.
Take Kimi as an example. In November last year, it launched the k0-math mathematical model, followed by the k1 visual thinking model in December and the k1.5 multimodal thinking model in January this year, marking three iterations in just three months with extremely fast evolution. This demonstrates that keeping up with cutting-edge technology is the fastest and best training ground for Chinese AI.
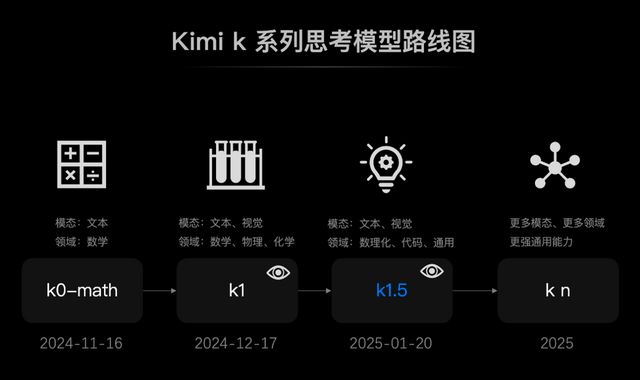
Second, by keeping their feet on the ground, China's fertile industry provides broader landing scenarios for domestic AI. The implementation of reasoning models will be better than that of o1. Overseas AI is mostly geared towards individual consumers, with o1's primary use cases being code assistants for programmers, data analysts, and individual developers, with a high threshold for ordinary users. In contrast, domestic large models are more oriented towards industry scenarios. AI-transformed business scenarios include a large number of serious production scenarios with low fault tolerance. Previous large language models struggled with complex tasks and desperately needed reasoning models with fewer hallucinations and higher reliability. Therefore, the implementation of domestic reasoning models may be faster and more extensive.
From these perspectives, introducing expert-level AI reasoning models into various industries to accelerate industry intelligence will likely be spearheaded by domestic AI. Domestic reasoning models such as k1.5 and R1 will contribute indispensable foundational value. Kimi officials also stated that in 2025, they will continue to follow the roadmap, accelerate the upgrade of the k-series reinforcement learning models, and bring more modalities, domain capabilities, and enhanced general capabilities.
So, if expectations are met, we will soon be able to utilize cost-effective and high-performing expert-level domestic AI.
The start of 2025 in large models, ignited by China's AI "binary stars," is exceptionally exciting. As the next watershed for model factories, whoever seizes the moment of the rise of domestic reasoning models will take the first step towards the future.

-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





