DeepSeek R1's Steady Progress Ushers in a Moment of Glory for Chinese AI
 05/30 2025
05/30 2025
 858
858
A seemingly minor version update has propelled domestic large models to the global forefront in programming and design, underscoring the strategy of incremental improvements in reshaping the AI competitive landscape.
In January 2025, the introduction of DeepSeek R1 sparked a significant shift in the global AI scene. Developed by a Chinese team at a mere $6 million training cost, this model achieved performance on par with OpenAI's $500 million o1 model.
Surprisingly, in the subsequent months, DeepSeek opted for a series of minor version updates rather than launching a revolutionary R2 version as anticipated.
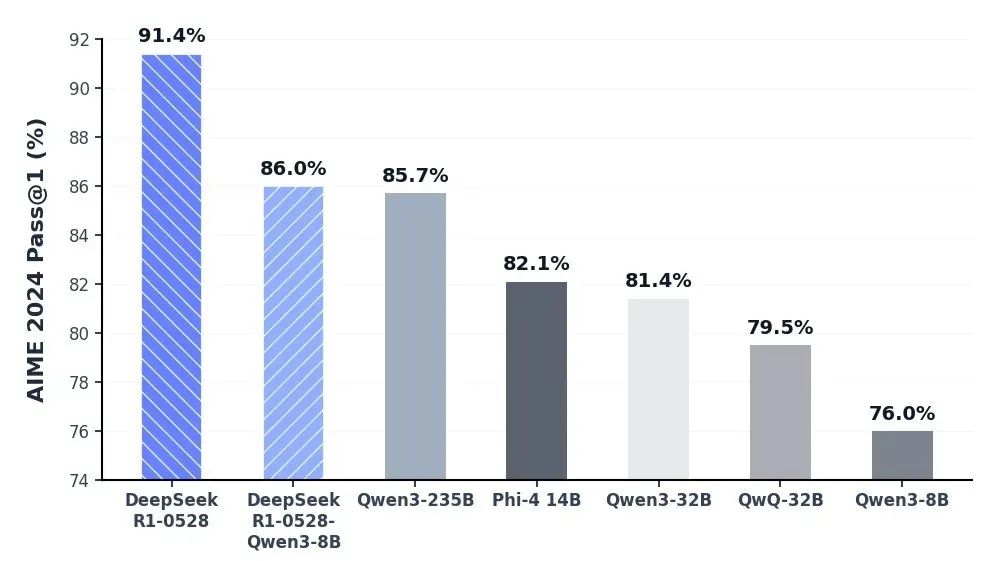
The R1-0528 version, released on May 28th of this year, once again stirred the tech community with its "minor upgrade." This new iteration achieved a breakthrough in programming, capable of generating 728 lines of code simultaneously to build a 3D animation application with particle effects, matching the performance of Anthropic's Claude 4.

In R1-0528, the DeepSeek team focused on optimizing the model's core challenge—hallucination issues. By enhancing the self-verification mechanism, the model's accuracy in mathematical reasoning and factual answers significantly improved.
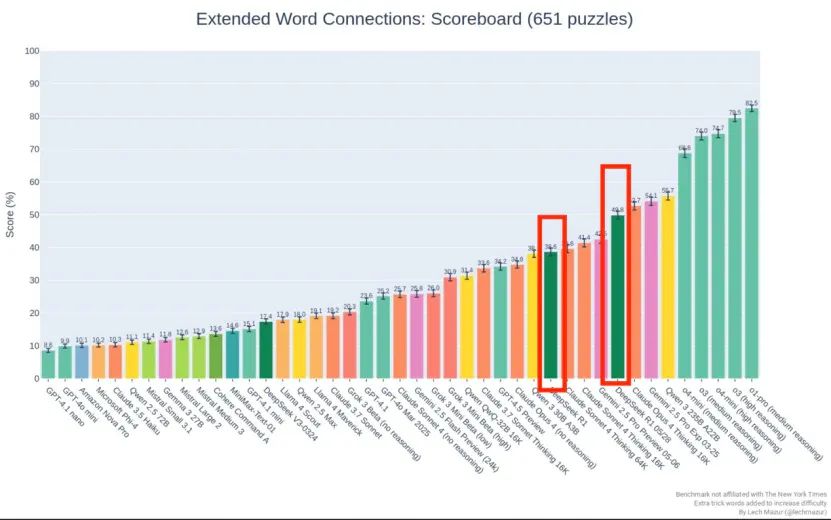
Comparative tests revealed that in the Extended NYT Connections benchmark, the new version's score jumped from 38.6 of the original R1 to 49.8, marking a nearly 30% increase.
This progress stems from DeepSeek's innovative GRPO algorithm (Group Relative Policy Optimization). Unlike traditional PPO algorithms, GRPO dynamically adjusts policies through intra-group sample comparison, eliminating the need for an independent value network, reducing memory usage by 40%, and improving training efficiency by 2.3 times.
Upon closer inspection, however, this upgrade did not introduce groundbreaking capabilities. The model's advancements in key areas like multilingual support and multimodal understanding remain limited. When users pose questions in German, the model still translates them into Chinese or English for processing, resulting in slower response times.
In complex function calls and role-playing scenarios, the performance still falls short of industry leaders. The anticipated true innovations—such as cross-modal understanding and complex tool usage—will have to await the arrival of R2.
The most significant change lies in the model's thinking approach. R1-0528 employs longer chains of thought, demonstrating human-like step-by-step reasoning abilities when tackling complex problems.
When tasked with "estimating π/7," the model took 148 seconds to provide an answer with numerous intermediate steps, meticulously considering methods like Taylor series expansion and numerical approximation, far exceeding what's required for simpler problems.
This deep thinking mode is a double-edged sword:
Advantage: In programming tasks, long chains of thought enable the model to self-correct errors. Tests show that when faced with Zig language development tasks, the model can swiftly adjust its approach after making a mistake.
Cost: Response time significantly increases. It has become commonplace for ordinary users to wait over ten seconds with a "thinking" prompt, providing a subpar experience in real-time interaction scenarios.
Tech enthusiasts appreciate this transparent reasoning process, believing it enhances result credibility. However, ordinary users prioritize efficiency—when Claude can deliver the correct answer within 3 seconds, the value of an excessively long chain of thought is debatable.
In content creation, R1-0528 demonstrates a qualitative leap. Compared to earlier versions, its medium to long output has evolved threefold:
● More rigorous structure: Answers follow a standard "problem analysis → step-by-step derivation → conclusion verification" process, significantly enhancing logical clarity.
● Richer information: In historical questions, the model supplements cultural backgrounds and controversial viewpoints, rather than limiting itself to simple facts.
● More standardized expression: Through the format reward mechanism in RL training, the model's mixed Chinese and English output issue has been largely resolved.

The most notable cost of performance improvement is response speed. Multiple real-world scenarios have exposed this bottleneck:
● Takes 83 seconds to solve the most difficult math problem on the college entrance exam.
● Takes 213 seconds to tackle real AIME competition questions.

● Processes few-shot prompts 7 times slower than non-reasoning models.
The speed bottleneck partly stems from engineering choices. To maintain a low-cost advantage, DeepSeek insists on using the MoE architecture (Mixture of Experts), activating only 37 billion parameters (out of a total of 671 billion) for each inference. This "power-saving mode" limits parallel computing efficiency.
In API service scenarios, the speed issue is mitigated by cost-effectiveness: the new version maintains pricing of $0.55 per million tokens for input and $2.19 per million tokens for output, which is only 3.7% of OpenAI's o1 pricing. However, when enterprises require real-time interaction, this shortcoming remains apparent.
DeepSeek's strategy this time signifies a shift in AI product development models. Unlike the "major version" mindset that pursues groundbreaking breakthroughs, the incremental improvement model demonstrates unique advantages:
● Risk controllability: Each iteration focuses on enhancing specific capabilities (like programming and design this time), avoiding the risks of comprehensive reconstruction.
● User-oriented: Quickly responds to community feedback, such as enhancing support for the three.js framework based on developer needs.
● Eco-friendly: The MIT open-source license allows enterprises to immediately integrate new versions, and the distilled model enables ordinary graphics cards to run 70B parameter models.
This model effectively addresses the "Jevons paradox": when technological progress reduces computing power costs, it instead stimulates greater demand. The surge in API calls following the launch of R1-0528, leading to a brief service interruption, vividly illustrates this phenomenon.
The cumulative effect of minor version iterations cannot be underestimated. After several updates, R1's programming ability has risen from Codeforces 1890 ELO at the beginning of the year to 2029, surpassing 96% of human players.
The quality of frontend design has reached a level where only professional designers can discern the differences.
The industry's attention has now turned to DeepSeek R2. As minor iterations have already brought it on par with Claude 4 in programming and design, the true next-generation architectural innovation may redefine the ceiling for domestic AI.
-
![]()
Market Share Dilemma: DJI vs. Insta360—Is It '40-40' or '60-30'?
-
![]()
Market Share Dilemma: DJI vs. Insta360 – A '40-40 Split' or '60-30 Split'?
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust