AI Search War: New Bing Reigns Supreme, Nano AI Emerges as a Formidable Challenger
 05/30 2025
05/30 2025
 906
906
 AI search is making a generational leap, transitioning from merely understanding search needs to delivering precise, reliable results.
AI search is making a generational leap, transitioning from merely understanding search needs to delivering precise, reliable results.
Author|Jeff Editor|Yang Zhou
Search remains the most ubiquitous entry point for AI. Within this powerful channel, three major players have undergone self-revolution and secured their positions at the table.
01 Google Raises the Red Flag
In 2022, The New York Times reported that shortly after ChatGPT's release, users hailed it as a potential replacement for Google Search, exclaiming, "ChatGPT is so powerful, it can replace Google Search." At the time, Google executives dismissed these claims, viewing them as well within their "expectations."
However, this optimism was short-lived. Google swiftly pivoted, with Pichai personally sounding a rare red alarm – a signal within Google indicating an immediate, critical, and direct crisis. This alarm was akin to a search or Gmail outage, requiring immediate attention regardless of sleep deprivation.
Pichai's alarm conveyed a clear message: "You must treat the threat posed by ChatGPT to Google with the same gravity as a Google Search downtime incident."
The initial lack of concern stemmed from Google's prior work on LaMDA (Language Model for Dialog Applications), an AI chatbot trained on a vast dataset of 1.56 trillion words comprising documents, conversations, and other data. After LaMDA was reported by The Washington Post, it generated significant buzz, with Google engineers discovering that it not only demonstrated deep thinking capabilities but also consistently claimed to possess consciousness and emotions during chats. Essentially, LaMDA already possessed similar capabilities to ChatGPT.

Google had its own product, even predating ChatGPT. However, from the 2021 I/O conference to the end of 2022, LaMDA remained unreleased on a large scale, unlike ChatGPT. What truly shocked Google was that ChatGPT-3.5 became the first AI product to break into the mainstream, a feat Google had not anticipated. Despite LaMDA's earlier release, it lagged behind ChatGPT, a significant oversight that necessitated urgent attention akin to a production environment accident.
02 The Growth Legend of Perplexity
Currently, the AI search market primarily comprises three types of products: dedicated AI search engines, traditional search engines with AI capabilities, and search-enabled products from large model vendors.
The first category includes Perplexity, Nano AI Search, and Quark AI Search; the second category comprises New Bing and Google AI Overview; and the third category features Kimi, Doubao, and Tencent Yuanbao. Notably, Perplexity, the current darling of native AI search, has inspired numerous "imitations" from competitors.
Perplexity is a revolutionary company that replaces the traditional "search engine" with an "answer engine." The rationale behind this is that search is fundamentally about obtaining answers, making the answer engine a first principle.
In 2023, Perplexity faced a Google ban, resulting in a complete cutoff of traffic and daily struggles on the brink of closure.
However, in 2024, investors worldwide rushed to invest, with the world's top 10 companies offering high-priced acquisition deals that were ultimately rejected.
Founded by former OpenAI research scientist Aravind Srinivas and his partners, Perplexity surpassed 10 million MAU (Monthly Active Users) with no initial user base, achieving this milestone in just under two years.
This rapid growth underscores the transformative potential of AI search – often, it is not another search engine that disrupts the market but cross-border innovation and entirely new species.
Perplexity's first product was a natural language to SQL conversion tool aimed at enterprise customers. During market research, the founding team identified several issues with traditional search engines:
• Traditional search engine results are often cluttered with advertisements, providing a poor user experience.
• Information overload makes it difficult for users to quickly find accurate answers.
Realizing that AI could fundamentally revolutionize the search experience, Perplexity pivoted and developed an AI-driven conversational search engine, introducing two key innovations:
• Replacing traditional search's web page ranking with AI Overview-generated answers.
• Annotating answers with references and attaching reliable source links for traceability.
In essence, Perplexity understands questions better than Google and possesses greater real-world data perception than ChatGPT.
Traditional search engines require users to sift through information and read links, which is inefficient. While generative AI like DeepSeek is convenient, it occasionally suffers from "hallucinations." When searching for academic materials or conducting investment research, it is challenging to find authoritative and accurate results.
Compared to traditional search engines, Perplexity directly provides summarized answers, enhancing efficiency and accuracy. Unlike the conversational content output by chatbots like DeepSeek and ChatGPT, users don't need to worry about hallucination issues, which is Perplexity's unique value proposition.
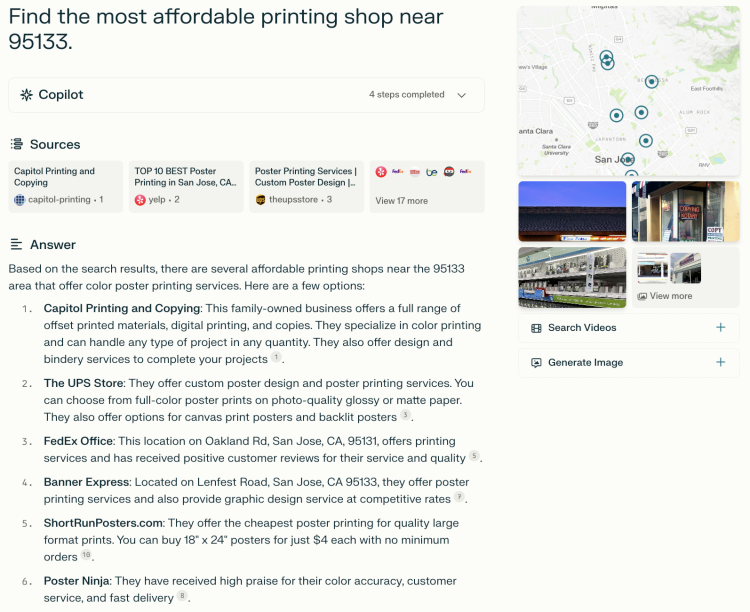
Perplexity's high-quality answers are also reflected in academic-level accuracy. For users seeking papers and academic materials, Perplexity significantly reduces the error rate by 70%. NVIDIA founder Jensen Huang reportedly uses Perplexity "almost every day," citing an example of using it to search for information on computer-aided drug discovery.
Perplexity also supports continuous questioning, akin to an "AI Q&A community." The founding team includes members from Quora, the American version of Zhihu. When using Perplexity, users can ask multiple questions, and it will "remember previous questions," gradually delving deeper within the context. Unlike traditional search, which is "one question, one search," users must integrate answers themselves.
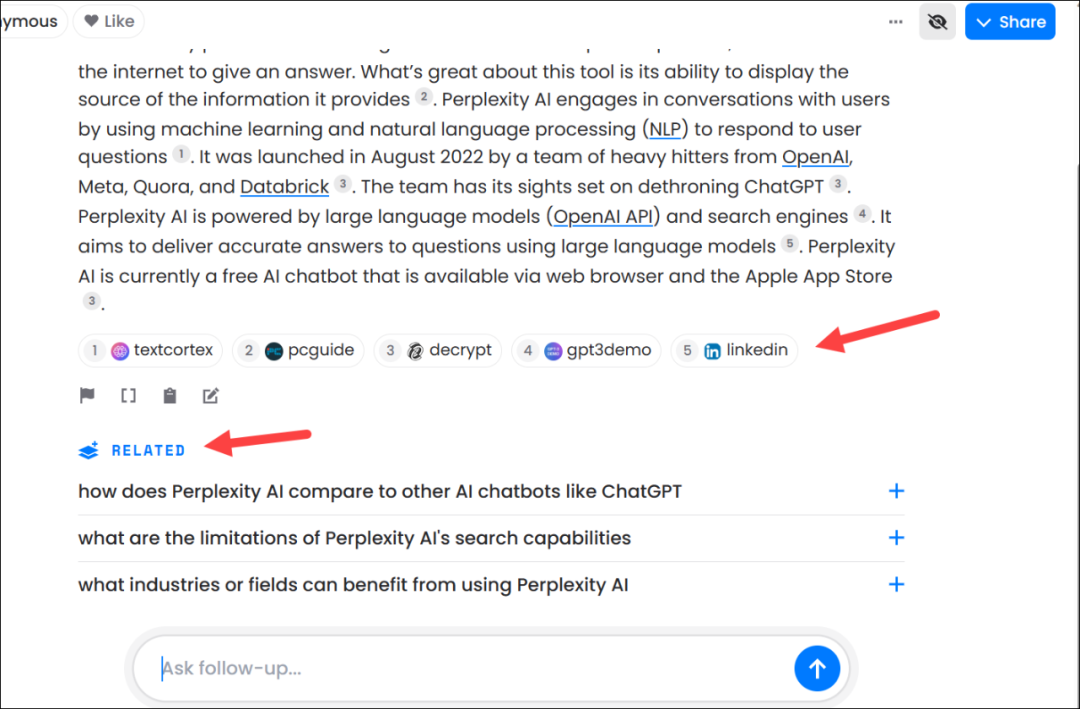
Perplexity's success extends beyond reading web pages and combining user questions with AI Overview to provide annotated answers. These features have become standard in AI search. Deeply processing user questions at the source and digging into the questions themselves are also crucial. According to interviews, Perplexity founder Aravind Srinivas believes in the notion that "users don't make mistakes":
"While everyone has a strong curiosity, few can turn it into precise questions." Therefore, Perplexity spends considerable time processing, analyzing, and reorganizing user queries. When users ask vague questions, Perplexity first refines them into a more logical format, optimizes the prompt, and then presents the question to the model for an answer.
The design of features like "related questions" and "discover" on Zhihu follows the same logic. Aravind Srinivas personally participates in selecting content for the "discover" tab to ensure the product remains "simple enough for even ordinary new users to understand." Data from Perplexity's Chief Business Officer Dmitry Shevelenko shows that "related questions" generate 40% of Perplexity's total queries.
By continuously improving the product, enhancing AI answer quality, and maintaining user-friendliness, Perplexity not only thrived amidst competition from giants but also witnessed a soaring valuation:
• Early 2024: Approximately $500 million
• June 2024: $3 billion
• December 2024: $9 billion
• May 2025: $14 billion
Perplexity's latest valuation stands at $14 billion, with an ARR of $120 million in 2024. According to the 23rd AI Product Ranking jointly released by domestic AI Product Ranking, 36kr, and Silicon Star | Woyin AI, Perplexity's monthly web visits reached 117 million in April.
03 Nano AI Search "Emerges as a Formidable Challenger"
Perplexity calls itself an "answer engine" because, as a product that directly "wraps" everything from search APIs to underlying large models, it doesn't provide direct search capabilities. Instead, it accesses content retrieved by search engines through APIs, summarizes answers using large models like GPT-4 and Claude, and presents them to users in a fixed format.
In other words, Perplexity's $14 billion valuation is built on its innovative product design.
Perplexity demonstrates that AI search is not just about search but high-quality AI overview. Its product methods can be summarized as "correcting, locating, and continuing" user input questions, reducing hallucinations, and increasing professionalism in AI output answers.
The true competition among AI search products lies not in underlying technological capabilities but in providing more accurate and reliable answers, faster response speeds, and more intelligent user experiences. Among these, "accuracy and reliability" are crucial for outpacing competitors, which is precisely where Perplexity excels.
For AI Overview to deliver high-quality answers, the quality and quantity of underlying data are paramount. Only when the database is large, information-rich, and updated timely can the large model "have a basis" for acquiring content, thereby summarizing and outputting more accurate and timely information. This explains why Google has maintained a market share of over 90% in the search engine field for years – they've been building indexes since 1998, possessing the world's largest and most comprehensive index database, capable of providing the most accurate and timely search results.
Therefore, building an in-house index database is vital for improving search result accuracy.
Currently, most AI search products access traditional search engine APIs without rebuilding an underlying search system. Only a few, like MITA AI Search (for podcasts and document libraries), Nano AI Search, and some vertical AI search engines, have built index databases. This is because accessing traditional search engine APIs can solve 95% of problems, while building an in-house index database is extremely costly, requiring significant manpower, financial resources, and time. Thus, if the in-house index database doesn't offer better content than Google and Bing APIs, there's no need to build one.
How costly is building an in-house index database? Liang Zhihui, vice president of 360, once mentioned in a podcast that crawling 50 million web pages costs approximately 1-2 million yuan. However, 50 million web pages are a minuscule number for search engines. Essentially, to create a search engine, at least 100 billion web pages need to be crawled; indexing global web pages requires 3,000-10,000 servers for support.
In other words, even the simplest search engine requires a budget of at least 2-4 billion yuan, excluding server costs for PageRank, protection fees for terminal manufacturers, and personnel costs. This is a hurdle difficult for small or medium-sized startups to overcome.
This is why only major players like Google, Microsoft, Baidu, and 360 are involved in search engines – the cost of building one is prohibitive, and only large companies have sufficient funds and talent.
Besides the high cost, search technology and algorithms are also highly challenging. Google's ranking algorithm, for instance, considers hundreds of factors, including content quality, user experience, mobile friendliness, page loading speed, security, etc. It's not only complex but also updates in real-time based on external conditions. Google reportedly releases an average of 6 algorithm updates daily, amounting to 2,000 updates annually. Moreover, the algorithm is highly confidential, with few within Google fully understanding its search ranking algorithm.
Given these enormous costs and extremely high technical barriers, it's no less difficult for small and medium-sized search engine/AI search companies to build an index database for the entire web than for Yu Gong to move mountains.
Shell-based products accessing traditional search engine APIs risk being "controlled" or "discriminated against" by third-party search engines. Building an in-house index database, which provides more accurate and reliable information sources, is a formidable task.
This is also the true weakness of native AI search engines like Perplexity. Without its own search capability, the quality and quantity of retrieved content, crucial for AI Overview, cannot be guaranteed. Relying solely on product design, Perplexity cannot rest easy in the long run, as it would be relatively easy for large companies with search capabilities to replicate its approach.
-
![]()
Market Share Dilemma: DJI vs. Insta360—Is It '40-40' or '60-30'?
-
![]()
Market Share Dilemma: DJI vs. Insta360 – A '40-40 Split' or '60-30 Split'?
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust