NPU's Path Obstructed: Is GPGPU the Solution?
 07/23 2025
07/23 2025
 830
830

The Neural Processing Unit (NPU) is a specialized chip designed for AI computing, with a core advantage in efficiently executing neural network-related operations (such as matrix multiplication, convolution, and activation function calculations). Compared to traditional CPUs and GPUs, NPU excels in energy efficiency and computational speed, making it ideal for mobile devices, edge computing, and embedded AI applications.
In recent years, NPU has been explored in training and inference for large AI models, with numerous market products adopting the NPU architecture to support AI network inference. Enterprises prefer NPU due to its controllability and reliable chip design. However, as AI technology evolves, NPU's limitations are becoming apparent, while General-Purpose Graphics Processing Unit (GPGPU) is seen as a more future-proof solution. Recently, reports emerged that a domestic manufacturer is transitioning its AI chip from NPU to GPGPU.
01
Differences between NPU and GPGPU
GPU was originally developed to accelerate graphics rendering, focusing on parallel tasks in computer graphics such as vertex transformation, lighting calculations, and texture mapping. As technology advanced, its parallel computing capabilities propelled it into general-purpose computing, forming GPGPU, widely used in scientific computing, deep learning training, video codecs, and other scenarios.
Conversely, NPU is a specialized chip tailored for AI and machine learning tasks, particularly focused on neural network inference and training in deep learning. Its architecture deeply optimizes matrix operations, convolution, and activation functions (like ReLU, Softmax, Pooling), executing these tasks efficiently through large-scale multiplier-accumulator (MAC) arrays. It also optimizes data flow transmission, reducing memory-to-compute data interaction overhead and significantly improving energy efficiency. However, NPU's instruction set and hardware design are highly specialized, only compatible with specific neural network models, limiting its support for other tasks. Its ecosystem is relatively new, relying on dedicated SDKs and toolchains from chip manufacturers (e.g., Huawei's Da Vinci architecture, Google's Edge TPU toolchain), requiring developers to optimize for specific architectures, offering lower flexibility but higher deployment efficiency.
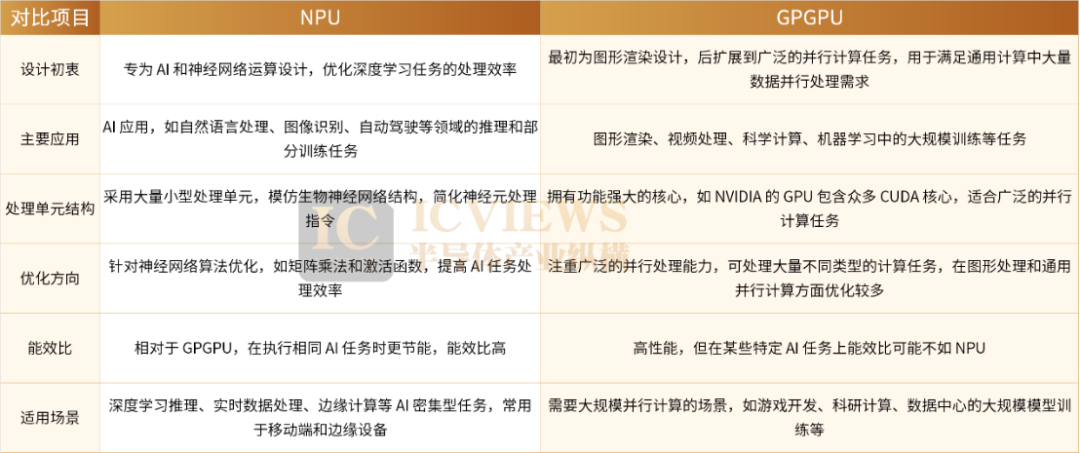
From an architectural perspective, GPGPU employs the Single Instruction Multiple Threads (SIMT) front-end (essentially SIMD encapsulated with a SIMT front-end), achieving high performance "out-of-the-box" through general scheduling mechanisms and friendly programming interfaces. NPU/TPU still uses the traditional Single Instruction Multiple Data (SIMD) architecture, requiring manual pipeline orchestration with less efficient latency hiding compared to SIMT, making it challenging to write high-performance kernels and leaving its ecosystem less developed than GPGPU. (SIMT is the core parallel computing model in GPU architectures, driving multithreaded parallel execution through a single instruction stream, with each thread processing an independent data set. Its core mechanism organizes threads into warps of 32 threads, handling branching logic through lockstep execution and dynamic mask control)
In recent years, some NPU chips have begun integrating SIMT front-ends (still biased towards heterogeneous pipelines overall). Although GPGPU's control units are weak, they have optimized designs for parallel computing, such as hardware thread switching, memory access control, and latency hiding. NPU has almost no control units and is more appropriately defined as a "Calculator/Coprocessor" rather than a traditional "Processor Unit (PU)."
Analyzing from the traditional "processor-coprocessor" architecture framework, the positioning can be summarized as follows: NPU's typical architecture is "CPU+NPU"; GPGPU is "CPU+GPU+DSA (Domain-Specific Architecture)", exemplified by NVIDIA's "CPU+CUDA Core+Tensor Core". Notably, GPU and DSA are not parallel coprocessors but form a hierarchical relationship where "CPU controls GPU, and GPU controls DSA".
02
Why is GPGPU Needed?
Why does a GPU control domain-specific architectures (DSA)? Or more fundamentally, why do GPUs need control units?
Early graphics cards and today's NPU share similar structures but differ in tasks. Unlike floating-point coprocessors integrated into CPUs, graphics cards have existed independently since their inception. The limitation of physical bus distance makes real-time CPU control of graphics cards difficult; as task complexity increases, integrating real-time control logic into graphics cards becomes inevitable - a classic "control transfer" strategy in hardware design. NVIDIA not only built-in such control units but also innovatively abstracted the SIMT programming model, a breakthrough in parallel computing.
In recent years, as AI tasks become more complex and varied, the expansion of control units has become an objective trend. Although SIMT is no longer the optimal programming model for AI chips, AI computing still falls within parallel computing and faces common parallel computing issues. NVIDIA's GPU design, which seemingly only "patched a tensor computing core" onto the original architecture, lacked revolutionary innovation but exceeded expectations in practical application.
GPGPU's importance stems from researchers' inability to predict AI technology's evolution in the next 5-10 years. Choosing NPU shifts adaptation pressure entirely to the software level, potentially optimal at a specific stage but with non-negligible side effects. Starting from training scenario needs, introducing SIMT front-ends in the next generation of NPU is a natural choice.
Objectively, NPU performs well in inference scenarios but faces significant challenges in training scenarios, at least an order of magnitude more difficult than inference. Even with an advantage in performance-per-watt, NPU has not achieved a crushing breakthrough over GPU in actual performance, and cloud scenarios have limited sensitivity to power consumption.
In NPU implementation, the following issues also exist:
First, usability lags behind GPU. Developers are particularly sensitive to toolchain friendliness, caring more about usability and experience. NPU's simple address control module can only handle access blocking of the same address by different instructions, lacking the latency hiding mechanism for threads in the SIMT architecture. To unleash NPU performance, developers must deeply understand its multi-level memory mechanism and design targeted segmentation schemes, but L1 memory block capacity and bank conflict issues make segmentation granularity difficult to control, further increasing the usage threshold. Moreover, DSAs like NPU have not undergone a brutal convergence process, with significant differences between generations and architectures provided by different companies.
Second, high ecological barriers. If domestic GPUs are directly compatible with the CUDA ecosystem, operators and inference engine frameworks can be reused after recompilation, significantly reducing migration costs. Investing in NPU incurs significant software costs, often requiring developers to work overtime to adapt operators, optimize performance, and build deep learning engine frameworks. Except for a few capable companies (even requiring on-site chip manufacturer support), most enterprises cannot afford such costs. Customers, without the pressure of "being completely unable to purchase GPUs," would not choose to invest more in NPU than GPU.
Third, development is difficult and closed, restricting downstream developer growth. In the GPU ecosystem, developers can independently develop operators and perform performance optimizations with a relatively low threshold. However, in the NPU system, except for a few large companies, most developers rely on SDKs and solutions provided by manufacturers, making independent in-depth optimizations difficult.
03
Domestic NPU Enterprises May Introduce SIMT Front-ends and Shift to GPGPU Route
GPGPU's SIMT model was designed for efficiently processing large-scale parallel and data-intensive tasks, particularly suitable for graphics rendering and scientific computing. This model allows a group of threads (i.e., a warp) to synchronously execute the same instruction, with each thread independently operating on different data, making it highly efficient for datasets with numerous homogeneous operations. For complex tasks, especially those highly parallelizable with low data correlation and converging branching behavior, the SIMT model's advantages are even more prominent.
From a hardware perspective, NPU has many merits, explaining why GPGPU's tensor computing cores have continued to increase in recent years, becoming a core performance metric. NPU is an architecture born for AI but faces more challenging growth compared to GPU's environment. On one hand, it must endure its own immature architecture; on the other, it must withstand GPU's absorption of its technical characteristics and market encirclement, making its development difficulty evident.
For scenarios like large language models (LLM), involving both extensive matrix multiplication (GEMM) calculations and the need to continuously respond to new demands, to reduce software development thresholds, either the SIMT model must be adopted or reliance on out-of-order execution and data prefetching mechanisms is necessary. NPU's architectural design was limited by the technological horizon at that time, making it difficult to predict future trends. The SIMT + tensor computing cores route, maintaining compatibility with CUDA's API and source code, has become the mainstream choice of NVIDIA's current competitors, with obvious advantages.
Many domestic NPU enterprises began development in edge scenarios, initially focusing on power consumption optimization with limited AI algorithm types. The NPU architecture was less sensitive to bandwidth, theoretically alleviating High Bandwidth Memory (HBM) issues. However, these AI chip enterprises did not foresee the explosive growth of large AI models early on, leading to a misalignment between early architectural design and later surging AI computing power demand. A core issue in the domestic AI chip field is insufficient emphasis on programmability and versatility at the decision-making level, with too many resources invested in specific scenario optimization, presenting impressive performance in promotional data but mediocre average performance in broader application scenarios.
Essentially, GPGPU and the SIMT programming model satisfy large-scale parallel computing needs while ensuring Turing completeness. DSA's problem lies in neglecting ease of use, which it now must address. Notably, as GPUs introduce tensor cores and DMA mechanisms, their native SIMT model has made breakthroughs; NPU is gradually strengthening its control capabilities - both showing a converging fusion trend in technological evolution. Reports now indicate that domestic enterprises will incorporate SIMT front-ends into NPU, gradually addressing shortcomings in general scheduling and programming ease of use.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






