Broadcom Thor Ultra Makes Its Debut, Heralding the Arrival of the 800G AI Ethernet Era
 10/17 2025
10/17 2025
 739
739
Produced by Zhineng Zhixin
Broadcom has officially rolled out the industry's inaugural 800GbE AI Ethernet Network Interface Card (NIC) that complies with the Ultra Ethernet Consortium (UEC) standard—the Thor Ultra.
Ethernet technology has taken another significant leap forward in the realm of AI cluster interconnection. It has achieved remarkable breakthroughs in crucial performance indicators, including bandwidth, latency, and congestion control. By harnessing the power of programmable RDMA, PCIe Gen6 interfaces, and engaging in in - depth collaboration with the Tomahawk 6 series of switch chips, it offers an open, efficient, and scalable solution for AI infrastructure. Ethernet is steadily emerging as the core architecture for next - generation AI computing networks, gradually supplanting InfiniBand.

Part 1: The Technical Architecture of Broadcom Thor Ultra
The design of the Broadcom Thor Ultra 800GbE NIC is centered on fulfilling the extremely high - performance requirements of AI data centers.
In comparison to its predecessor, Thor Ultra integrates the new BCM57708 controller chip, which can support throughput capabilities of up to 800Gbps.
This implies that each NIC can simultaneously handle PAM4 SerDes signals of up to 200G or 100G. It enables long - distance passive copper connections while maintaining the industry's lowest bit error rate (BER). Its high - precision signal processing capability ensures stable links, effectively minimizes data transmission jitter, and enhances the efficiency of Job Completion Time (JCT).

Regarding physical interfaces, Thor Ultra features an OCP 3.0 - compliant form factor design and adopts the OSFP112 interface format.
This interface supports a 112G PAM4 SerDes signal rate, providing a scalable hardware foundation for interconnecting AI training servers, accelerators (XPUs), and high - speed switches.
Moreover, Thor Ultra achieves up to 128GB/s of host communication bandwidth through a PCI Express Gen6 x16 host interface. This offers a more abundant array of data pathways for GPUs, TPUs, and custom XPUs in future AI clusters.
To meet the stringent data security demands in AI clusters, Thor Ultra incorporates a PSP (Packet Security Processor) acceleration module. This module enables line - speed encryption and decryption operations at the network level.
This hardware - level offloading mechanism substantially reduces the computational load on host CPUs or XPUs, thereby enhancing overall computational efficiency.
In terms of security, Thor Ultra also supports signed firmware and device - level attestation. This ensures the integrity of the boot process and firmware loading, thus preventing potential security attacks.
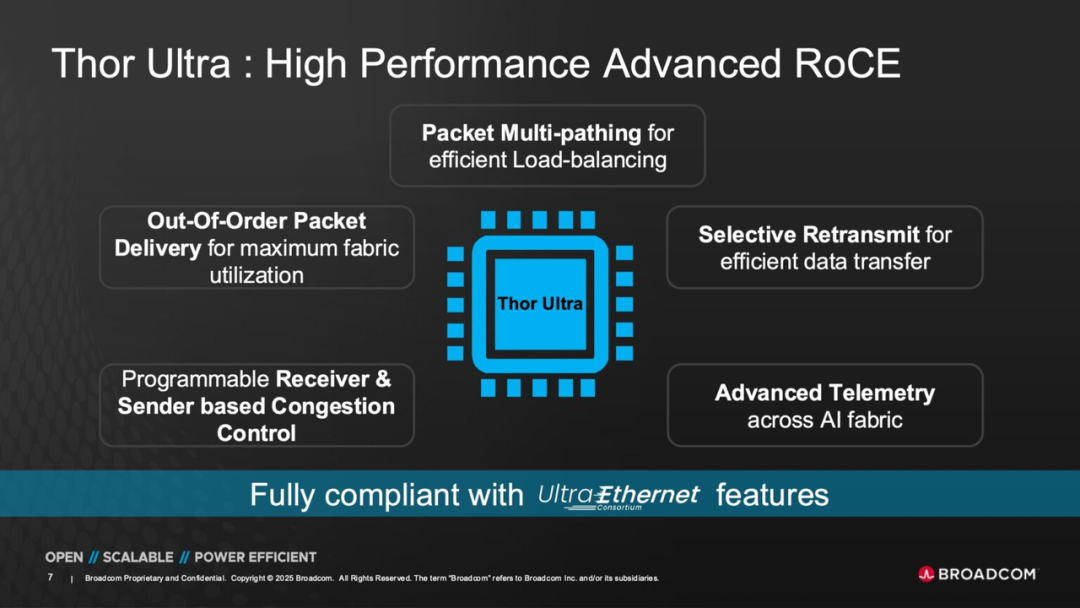
Part 2: RDMA Innovation and the AI Networking Ecosystem
The core technological breakthrough of Thor Ultra lies in its reconstruction of the Remote Direct Memory Access (RDMA) protocol.
Traditional RDMA encounters challenges in large - scale AI cluster environments, such as insufficient multipath utilization, packet sequence dependency, inefficient retransmission, and delayed congestion control.
Thor Ultra tackles these issues by introducing a series of groundbreaking RDMA enhancement mechanisms that conform to the UEC (Ultra Ethernet Consortium) standard.
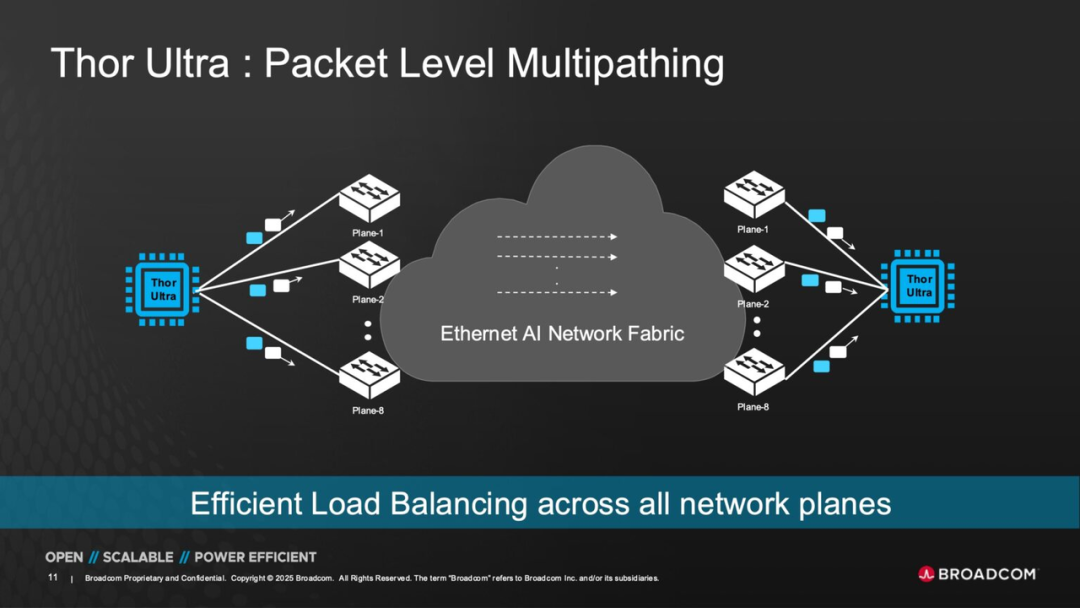
● First is Packet - Level Multipathing. This mechanism allows data packets to be dynamically shunted across different network paths, achieving real - time load balancing.
Compared to traditional flow - level multipathing, the packet - level approach enables more fine - grained bandwidth resource scheduling. It effectively reduces the likelihood of network hotspots and bottlenecks, thereby improving overall network utilization.
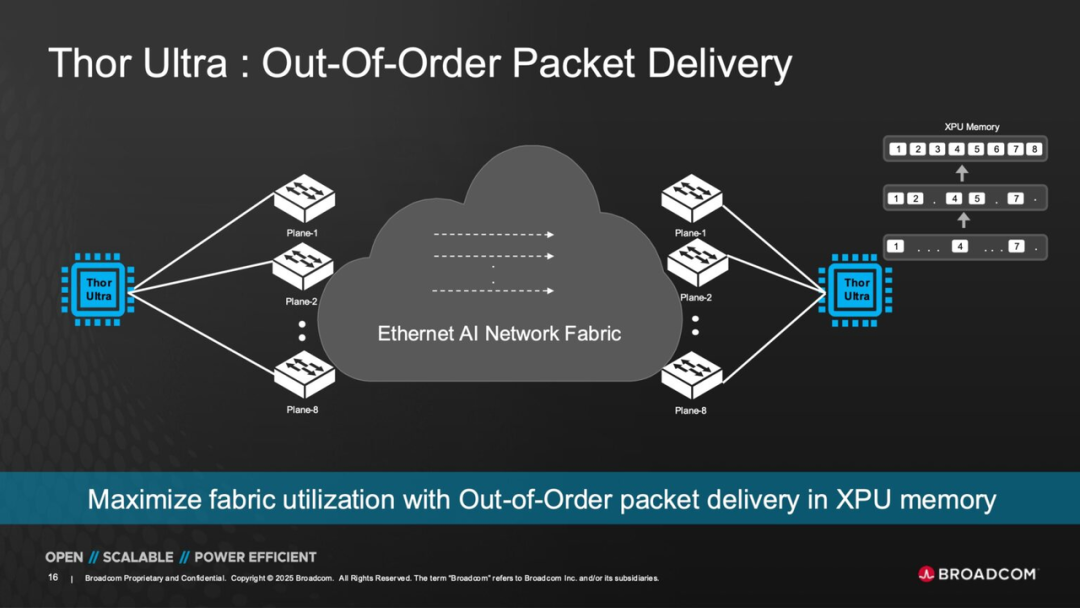
● Second, Out - of - Order Packet Delivery enables the receiving end to directly write data into XPU memory without waiting for the complete restoration of packet sequence order. This improvement significantly cuts down on latency and enhances the real - time performance of parameter synchronization during AI training.
● Third, the Selective Retransmission mechanism optimizes error recovery strategies. It only retransmits lost or corrupted data packets instead of recovering entire session - level data. This not only improves bandwidth utilization efficiency but also reduces latency jitter, especially in high - concurrency AI training tasks.

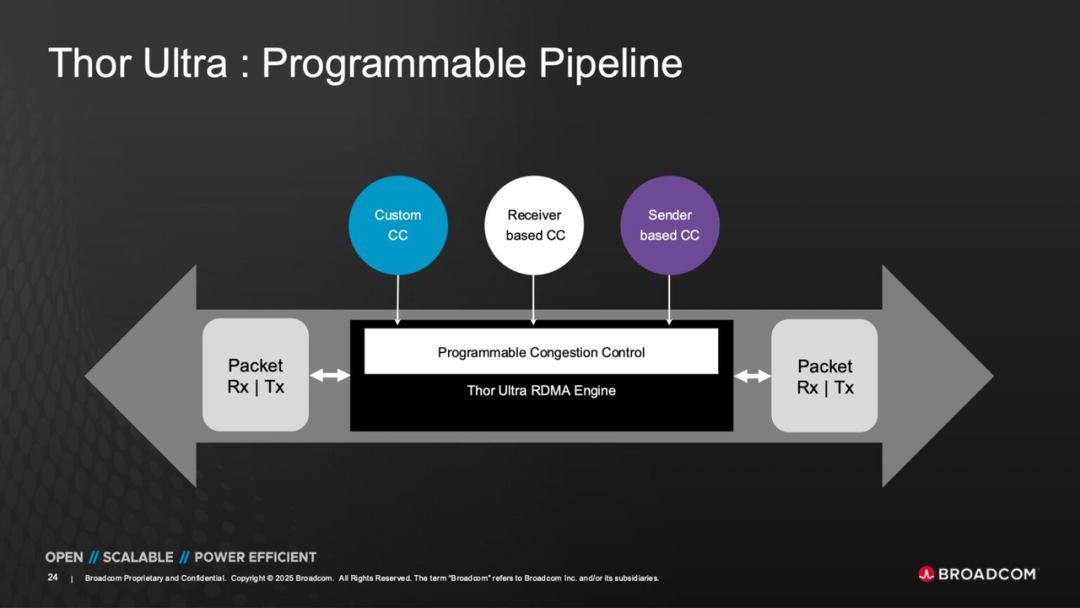
In terms of congestion management, Thor Ultra features a Programmable Congestion Control Pipeline. This pipeline supports bidirectional algorithm optimization based on both the receiver's and sender's perspectives.
This means that users or system software can customize congestion response strategies according to different AI workload characteristics. This enables the achievement of the optimal balance between bandwidth and latency during training or inference phases.
Thor Ultra, together with Broadcom's Tomahawk 6, Tomahawk Ultra, and Jericho 4 series of switch chips, forms a complete AI networking ecosystem.
Within this open architecture, Thor Ultra supports UEC - standard packet pruning and congestion signaling (CSIG) functions. This enables proactive coordination with switch - side rate limiting or route reallocation upon detecting network congestion. This end - to - end collaborative mechanism constructs an AI networking structure with adaptive flow control capabilities.
In this architecture, Ethernet is gradually replacing traditional InfiniBand solutions.
Compared to InfiniBand, the Ultra Ethernet system in which Thor Ultra operates offers distinct advantages in terms of compatibility, scalability, and ecological openness.
It can seamlessly collaborate with optical modules, XPUs, and switches from different vendors. It also facilitates elastic expansion and multi - tenant management for cloud computing platforms. This open and interoperable characteristic is the key to driving AI network standardization and large - scale deployment.
Summary
AI Ethernet technology has entered the 800GbE era. This era is marked not only by a doubling of bandwidth but also by architectural openness and standardization.
By adhering to UEC specifications, Broadcom enables Ethernet to achieve latency control capabilities comparable to those of InfiniBand in AI training, inference, and high - performance computing. At the same time, it retains the flexibility of an open ecosystem and general - purpose hardware.
The collaboration between Thor Ultra and Tomahawk series switches positions Broadcom with a complete layout that spans from switching to endpoints in the AI data center networking stack.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






