The VLA Model and Its Architecture for Ideal Intelligent Driving
 04/22 2025
04/22 2025
 730
730
In our previous article, "End-to-End Large Model 2.0 - VLA (Vision Language Action) for Autonomous Driving in 2025", we introduced the VLA model. Now, numerous companies have announced their plans to launch this model structure in the latter half of 2025. Among them, Ideal Auto stands out as one of the pioneers in adopting the VLA model for intelligent driving. The VLA model seamlessly integrates perception (via a 3D encoder), reasoning (using a language model), and decision-making (via a diffusion policy) into a unified, trainable end-to-end large model. Furthermore, Ideal Auto claims that its VLA model will concurrently support external multimodal interactions, such as voice interaction with the driver and specific visual inputs from the surroundings, thereby enabling intelligent driving that comprehends, perceives, and navigates effectively.

This article delves into and shares the nuances of Ideal Auto's intelligent driving VLA algorithm based on available information. The Ideal VLA model architecture comprises four core modules:
- V-Spatial Intelligence: Utilizes input from the car's sensors to perform 3D modeling for perception and the vehicle's own modality, creating an understanding of the driving environment and the vehicle itself. This information is then tokenized.
- L-Linguistic Intelligence: A large language model that serves as the AI's "tokenization tool," where tokens are the language of AI. External inputs, like driver voice commands, are also tokenized, allowing for unified language-based reasoning.
- A-Action Policy: Generates actions. Similar to human drivers, it reasons about the current environment and vehicle conditions to produce a driving path. It creates multimodal driving trajectories using diffusion models, enabling interaction and negotiation with other traffic participants.
These three steps constitute the Ideal VLA model's structure, progressing from perception to processing and ultimately generating motion trajectories, all within a single trainable model. Now, how is this model trained? Ideal Auto employs Reinforcement Learning, feeding the model with data and conclusions desired by humans to ensure correct responses in similar future situations. The company adopts the world model approach, akin to NVIDIA's "combining 3D reconstruction and generation technology to create a high-fidelity virtual environment mirroring the physical world," similar to NVIDIA's Cosmos. Human-provided cases are then used for reinforcement learning training and closed-loop verification.
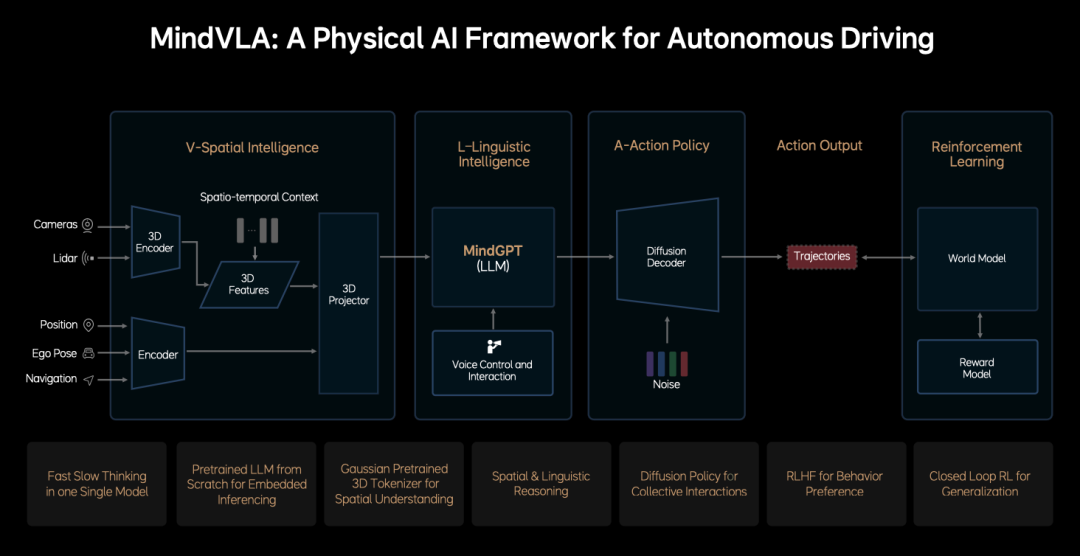
Detailed Construction of the Ideal VLA Model Architecture:
- Input from Sensors: Such as cameras.
- 3D Spatial Encoder: Encodes camera and LiDAR information in 3D, refining them into 3D features to form a 3D spatial understanding. Self-supervised learning trains 3D Gaussian representations, generating multi-scale geometric and semantic information using RGB images from real driving data without manual annotation. Additionally, the vehicle's own information, like orientation and navigation, is encoded, forming tokens for 3D spatial understanding.
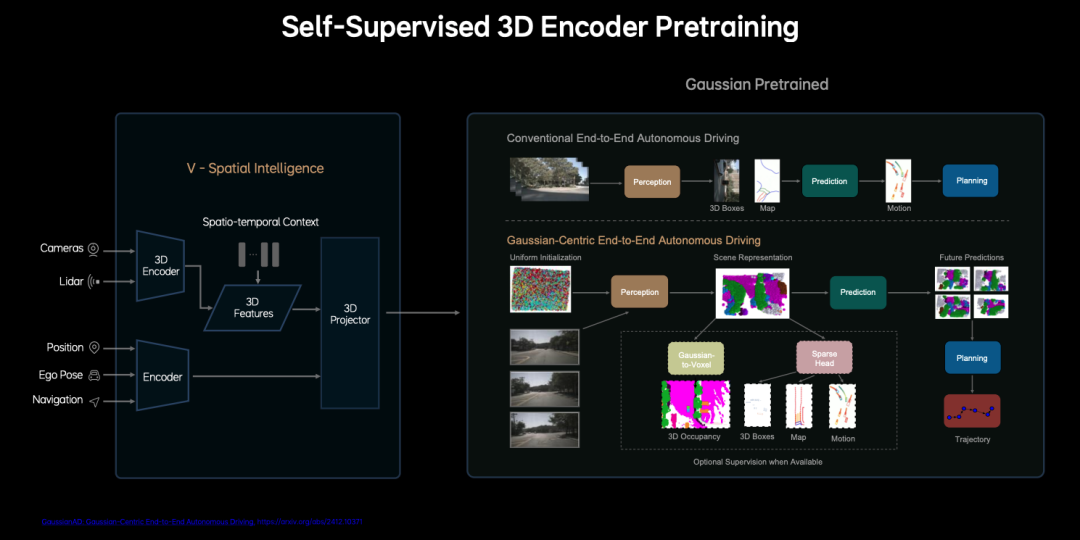
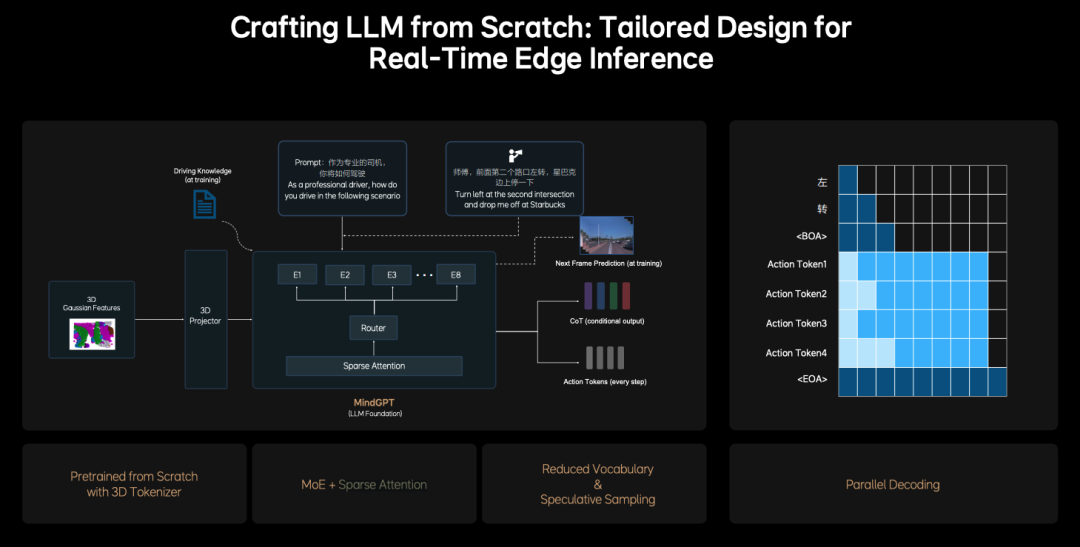
- Language Model (MindGPT): Ideal Auto asserts that its LLM large language model is built from scratch and is proprietary, integrating driving knowledge, logical reasoning abilities, and 3D spatial understanding. MindGPT optimizes reasoning efficiency through the Sparse Attention mechanism and Mixture of Experts (MoE) architecture, achieving an output of 10 Hz (conclusions in 100 ms) and adapting to in-vehicle chip computational limitations (like Orin X).
- Sparse Attention and Mixture of Experts (MoE): Methods adopted by popular models like DeepSeek this year. Ideal Auto uses fixed, concise CoT templates to balance real-time performance and logical depth.
- Behavior Generator (Diffusion Policy): Generates multimodal driving trajectories using diffusion models, predicting vehicle and other vehicles' trajectories, and enabling interaction and negotiation. The ODE sampler accelerates the generation process, achieving stable output in 2-3 steps to meet real-time requirements.
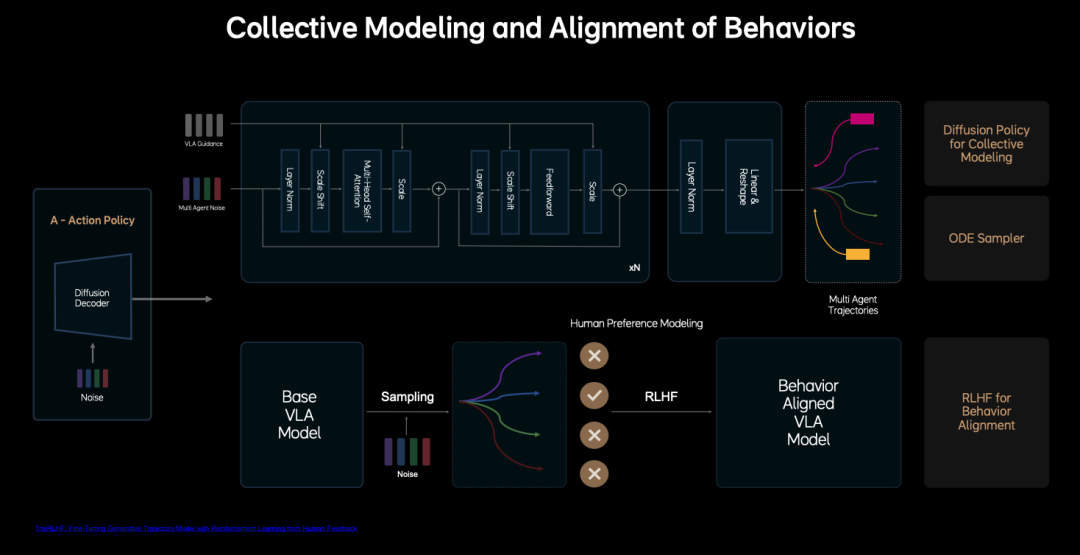
The true end-to-end model's allure lies in integrating and connecting these parts, using a common set of tokens for lossless and real-time information transmission. Model training involves constructing parameters like weights for these tokens. Ideal Auto's reinforcement learning (RL) framework relies on a highly realistic world model created by combining scene reconstruction and generation technology, addressing the training bias issue in traditional RL due to insufficient environmental realism. Self-supervised learning reconstructs dynamic 3D scenes from multi-view RGB images, generating multi-scale geometric and semantic information. 3D Gaussians represent the scene as point clouds, with each point containing position, color, transparency, and a covariance matrix, enabling efficient rendering of complex environments.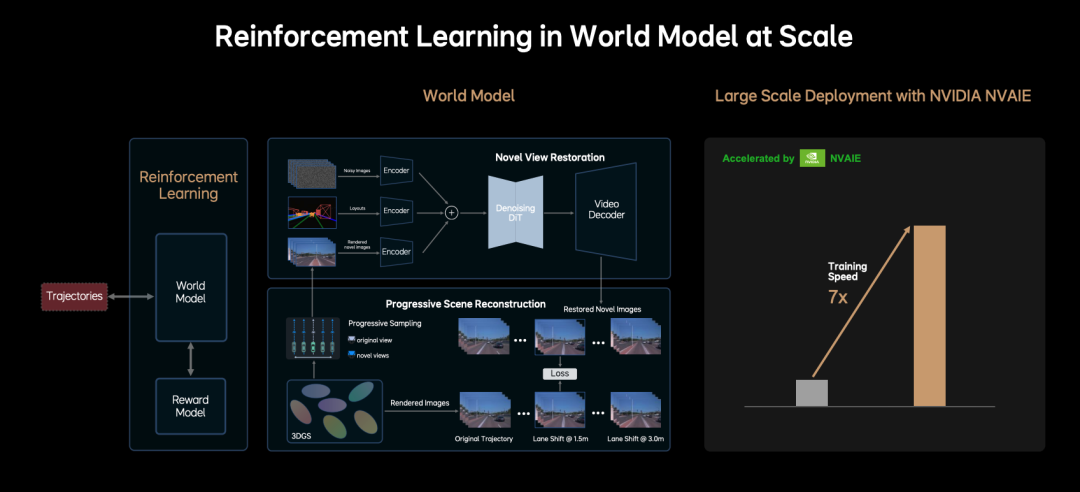
This approach allows the VLA model's training (end-to-end + language model) to be based on cloud-based virtual 3D environments, conducting millions of kilometers of driving simulations, potentially replacing some real-vehicle testing. In conclusion, the information presented here is primarily public and leans towards technical promotional content from Ideal Auto. Its effectiveness will need practical validation. However, this article offers a general understanding of its algorithm structure, ideas, and related core technologies. Furthermore, if Ideal Auto's model proves successful, it could be applied to other Physical AI applications, such as robots.
Reproduction and excerpts are strictly prohibited without permission - References: Ideal Auto 2025 GTC Presentation ppt - VLA: A Leap Towards Physical AI in Autonomous Driving. Join our knowledge platform to access a vast amount of first-hand information in the automotive industry, including the above references.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






