Kimi and Minimax Vie for Dominance in the 'Next DeepSeek' Era
 07/01 2025
07/01 2025
 894
894


The six titans aspire to replicate DeepSeek's success.
Original Tech News, AI New Tech Team
Recently, at the 36Kr WAVES conference, a fascinating segment sparked intense discussions: a dialogue between investors from Kimi and Minimax. With DeepSeek's emergence, China's large model landscape has been revolutionized. Industry leaders have evolved from the original six titans to today's five foundational models. As the six titans lose market focus, Kimi and Minimax, which have been relatively quiet, have taken new actions: Kimi open-sourced the programming model Kimi-Dev, and its first agent, Kimi-Researcher, has begun small-scale testing for in-depth research. Meanwhile, Minimax open-sourced the first reasoning model Minimax-M1 and achieved advancements across multiple areas, including large models, video generation, and audio generation, over five consecutive days.
From a product standpoint, Kimi focuses on agents, with in-depth research as its primary direction, seemingly aiming to make an impact in finance, academia, and other fields. Despite competition from players like Zhipu, Kimi's focus on foundational model capabilities keeps it out of the reach of large companies centered on life services. Conversely, Minimax appears intent on making amends for past misses. After failing to integrate with DeepSeek, it continues to push forward with a comprehensive layout. This suggests that as large model competition enters its second phase, more variables are at play. Judging by various assessments, Kimi and Minimax's new products show promising results. Without a buffer period after R2, representatives from the six titans are attempting to bring their respective strengths into the next phase. Reports indicate that both Kimi, which frequently clashes with DeepSeek in research papers, and Minimax, which once bet on the same technical path as DeepSeek, seem reluctant to give up. With large companies joining the large model race, Kimi and Minimax, among the six titans, are seeking their own survival strategies. To some extent, the competition mode is evolving, and as the bubble dissipates, the increasingly business-savvy six titans anticipate the start of the next cycle.
01
Kimi and Minimax Unveil Their Competitive Edges
'A year ago, it was all about user acquisition and market share, but now it's back to the technological frontier and strong cognition. I believe this is more suitable for entrepreneurial teams centered on technical experts. Because user acquisition is an opportunity for large companies, and they are doing quite well.' ZhenFund partner Dai Yusen said at the dialogue discussing Kimi and Minimax. Indeed, recently, compared to large companies competing in vertical applications like education and healthcare, Kimi and Minimax seem eager to showcase their underlying technological strengths. On June 20, Kimi officially announced that Kimi-Researcher (In-depth Research) had begun small-scale grayscale testing. According to official sources, the model is an agent, and Kimi-Researcher is a new-generation agent model trained using end-to-end autonomous reinforcement learning (end-to-end agentic RL) technology. It is specifically designed for in-depth research tasks. As a beta user, it's evident that Kimi aims to create a product that is 'highly practical' and 'reliable'. Official data shows that each task performs an average of 23 steps of reasoning, autonomously sorts out and resolves needs, plans an average of 74 keywords, finds 206 websites, and judges and filters out the top 3.2% of content with the highest information quality, eliminating redundant and low-quality information. The average report length exceeds 10,000 words, with an average of about 26 high-quality, traceable sources cited. Clearly, Kimi targets vertical sectors requiring low-hallucination research. Feedback from platforms like Xiaohongshu indicates that users in academia, finance, and law, which frequently require in-depth exploration, have given Kimi-Researcher positive reviews.
Professional review blogger mactalk commented: 'In-depth research is not new, but the content generated by Kimi is excellent in terms of sources and format. Kimi's in-depth research function not only provides an analysis report but also generates a webpage. Seeing the webpage gives you the feeling that it should be an equally important interaction method as text.' Meanwhile, Minimax is also showcasing its capabilities with a brand-new model. According to GeekPark reports, as a reasoning model, Minimax-M1 ranks among the top two globally in long-context understanding ability, including all closed-source and open-source models, and offers high cost-effectiveness in both training and reasoning. M1 continues to use the MoE architecture, but innovations in attention mechanisms and reinforcement learning algorithms distinguish it sharply from other reasoning models. The model has a total of 456 billion parameters, natively supports input of context lengths up to 1 million tokens, and currently has the longest output length of 80k tokens among all models. In evaluations of professional context capabilities, M1's performance surpasses all open-source models, including DeepSeek-R1-0528 and Qwen3-235B, and even OpenAI GPT-4 and Claude 4 Opus, trailing only slightly behind the SOTA Gemini 2.5 Pro.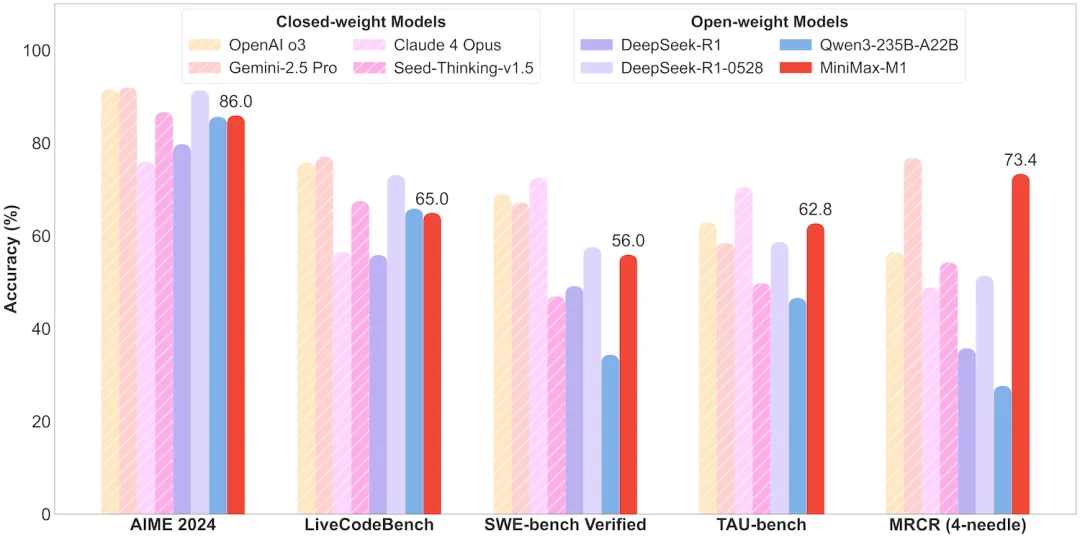
Besides advancements in foundational models, Minimax has also made significant strides in multiple fields such as agents and multimodality. 'Have you seen 'Daniel Wu Teaches You English' on Douyin recently? Minimax provides the technical support behind it. When I first heard it, I couldn't tell if it was a real person or AI, and it wasn't until later that I found out it was a Minimax client. It's impressive,' mentioned Yunqi Capital partner Chen Yu. With highly practical agents and outstanding large models, Kimi and Minimax are attempting to initiate a comprehensive race. From a deeper perspective, the two companies aim to break the public's inherent mindset regarding the large model sector.
02
Aspiring to a DeepSeek-style Victory
Compared to DeepSeek's brilliance, Kimi and Minimax, looking back, must harbor regrets. Yang Zhilin, with a background from Tsinghua University and a Ph.D. from Carnegie Mellon University's Language Technology Institute (LTI), studied under Ruslan Salakhutdinov, the head of AI at Apple, and William W. Cohen, the chief scientist of Google AI. Such an academic background far exceeds that of ordinary entrepreneurs in technological credibility. Moreover, his entrepreneurial experience in areas like cyclic intelligence has proven himself in enterprise-level AI implementation, convincing capital that he not only understands technology but also knows how to do business. High-frequency and rapid funding allowed its valuation to soar rapidly. His technical background, management experience, and abundant resources made Yang Zhilin a star in the pre-DeepSeek era. More importantly, Kimi's first battle was fought beautifully, elevating long-text technology to the height of a 'breakthrough for Chinese AGI', precisely matching capital's expectations. However, it cannot be denied that DeepSeek's explosive popularity somewhat overshadowed Kimi's voice. Nonetheless, Kimi's technological strength remains on par with DeepSeek. In basic research, on February 18, DeepSeek and Dark Side of the Moon almost simultaneously released their latest papers, with topics directly 'colliding' – both challenging the core attention mechanism of the Transformer architecture to enable more efficient processing of longer contexts. More interestingly, the names of the technical stars and founders of the two companies appeared in each other's papers and technical reports. Such collisions have occurred frequently recently. Similarities in hiring for legal, medical, and other directions subtly suggest that Kimi remains a formidable competitor to DeepSeek.
On the other hand, Minimax's regrets are more direct. According to media reports, Minimax adopted the same technical route as DeepSeek earlier. In the second half of 2023, when most domestic large model vendors were still iterating dense models, Minimax founder and CEO Yan Junjie invested over 80% of their R&D and computing resources into an uncertain endeavor – MoE (Mixture of Experts). In January 2024, Minimax launched abab6, becoming the first MoE large model in China. Since then, the MoE architecture has completely replaced the dense architecture, becoming a new direction for technological iteration in the large model field, and the MoE architecture is precisely what the year's breakout DeepSeek applies. Although a general comparison between the two is not feasible, the visible gap between them can be verified.
Objectively speaking, Kimi and Minimax, whose technological strength is comparable to DeepSeek, have long been unable to gain matching market influence. From this perspective, not being defeated by large companies but being surpassed by DeepSeek also makes the two companies aspire to a true turnaround in the next cycle, namely the competition for agents. As Dai Yusen said, 'We didn't invest in Kimi because of large models, but because of the team. It's still early in the technological revolution, and they remain one of the AI startups with the best teams in China and one of the AI startups with the most resources. If we believe that AI is a very big deal, with the best team and the most resources, you can still accomplish many interesting things.' Whether the second half of AI will still follow the current model dominated by large companies with DeepSeek making key breakthroughs remains a puzzle.
03
The Survival Logic of AI Companies is Being Reconstructed
Entering June, the AI scene seems livelier than ever. Luo Yonghao's digital human live streaming achieved massive sales, Quark and Yuanbao competed in college entrance examination volunteer reporting, and simultaneously, Doubao launched an AI podcast feature, and senior management at Meituan ordered the first cup of AI takeout coffee. The imagination and application of AI are accelerating their penetration into every corner of life. This rapid evolution seems to confirm what was mentioned at the Sequoia AI Summit: the next round of AI will sell benefits, not just tools. However, debates about the future evolution of agents also persist. Li Guangmi, CEO of Shixiang, once discussed the match between agents and current model capabilities. He believes that 80% of an agent's capabilities today rely on the model engine. For example, with GPT reaching version 3.5, the general paradigm of multi-turn dialogues emerged, making products like chatbots feasible. The rise of Cursor is also due to the model developing to the level of Claude 3.5, enabling its code completion capabilities. Conversely, AI Research Lead Zhong Kaiqi believes: The demand for general agents falls into two categories: information retrieval and light code writing, and GPT-4 has already excelled in this. Therefore, the general agent market is primarily a battleground for large model companies, and it's difficult for startups to grow solely by serving general needs. Instead, startups generally focus on vertical fields.
Returning to our protagonists: When Kimi uses its deep research agent to open the door to vertical professional scenarios, and when Minimax refreshes the boundaries of open-source capabilities with its reasoning model M1, every move by these two companies confirms the same fact: the competition among large models has long surpassed the initial stage of 'parameter comparison' and entered the core battlefield of 'mind capture'. DeepSeek's rise proves that in the game between big factories and startups, the precise coupling of technological breakthroughs and market positioning is enough to reshape industry perceptions – and this is the most urgent goal for Kimi and Minimax at this moment.
From a technical trajectory standpoint, Kimi is banking on 'vertical Agents', endeavoring to carve a niche with the professional tag of 'deep research'. Meanwhile, Minimax seeks differentiation through a linear attention mechanism, fostering an imaginative realm for comprehensive scene penetration via multimodal capabilities. The divergence in their strategies fundamentally embodies distinct interpretations of the 'survival rules for the latter half of AI': Kimi opts to establish roots in vertical categories where large factories have yet to deploy significant resources, leveraging 'high practicability' to counterbalance the traffic benefits of these giants; Minimax, on the other hand, persists in its aspiration for a 'full-stack layout', striving to offset ecological deficiencies with technical cost-effectiveness. However, as Dai Yusen aptly noted, the crux of this competition may hinge on 'investing in teams rather than models'. As DeepSeek redefines capital logic with a technical narrative, the core competitiveness of Kimi and Minimax still resides in the founding teams' capacity to foresee technological trends (such as Yang Zhilin's steadfastness in long-text technology and Yan Junjie's early adoption of the MoE architecture). In an era where large factories are intensifying competition with resource advantages, the breakthrough for startups has never been about 'head-on collisions', but rather, akin to DeepSeek, establishing an irreplaceable cognitive edge in a specific technical dimension, thereby capturing users' attention. The current phase of AI is both a 'marathon' of technological implementation and a 'lightning war' of mental cognition. Each open-source release and iteration of Kimi and Minimax's Agents adds heft to the narrative of 'the next DeepSeek'. As the industry bubble gradually deflates, it may be those teams that can not only anchor deeply in the waters of technology but also etch unique labels in users' minds that truly transcend the cycle. This silent war has just commenced.
Reference materials: Zmubang, 'Yan Junjie Is Not Content'; Zmubang, 'Are Good Days Coming for Minimax?'; Wang Zhiyuan, 'Can Kimi Still Find the Bright Side of the Moon?'; Ifeng Finance, 'Did Kimi and DeepSeek Collide Again?'; Anyong, 'One Year Later, When Investors in Kimi and MiniMax Sit Together Again'; GeekPark, 'Where Are the Opportunities and Values of Agents Under the Game of Giants?'; 36Kr, 'Open Source and IPO? MiniMax Doesn't Want to Be Forgotten This Summer'; Dark Side of the Moon, 'Model is Agent, Kimi-Researcher (Deep Research) Begins Internal Testing'; GeekPark, 'MiniMax-M1 Debuts, MiniMax Proves Once Again That It Is a Model-Driven AI Company'
- The end -
-
![]()
Internet Valuation Logic Shifts: From Scale Narrative to Profit Accountability
-
VOYAH Struggles to Find Its Niche in the Competitive Auto Market
-
![]()
Maxwell Technologies Gains Indirect Stake in Precision Optics via New Venture
-
![]()
Raising 1.8 Billion! This Domestic Optical Inspection 'Little Giant' is Going Public
-
China's AI 'Normandy Moment': The Explicit and Implicit Threads of BATL
-
![]()
Starting at 4999 Yuan! Nubia RedMagic Gaming Tablet 5 Pro Review: Impressive Performance, But Hefty Price Tag
-
![]()
ByteDance Initiates First Major Management Reform
-
![]()
AI is Quietly Destroying a Trillion-Dollar Industry