OpenAI Explores TPU Testing: Shifts in the AI Chip Market Landscape
 07/09 2025
07/09 2025
 568
568

Produced by Zhineng Zhixin
A subtle game is unfolding between Google TPU and OpenAI, influencing AI computing power resource allocation, supplier dynamics, and market trends.
Contrary to media reports suggesting a large-scale adoption of Google TPU by OpenAI to replace NVIDIA GPUs, the reality is more nuanced. OpenAI has only conducted limited testing and has not embarked on a large-scale migration.
Driven by factors such as chip performance, supply agreements, infrastructure compatibility, and deployment costs, OpenAI remains committed to the technical path dominated by NVIDIA and AMD.
Google TPU is gradually being opened up at the cloud service level, yet significant hurdles remain in upending the existing computing power landscape.

Part 1: TPU Testing and Inertia in AI Infrastructure Selection
Market speculation about OpenAI's potential switch to Google TPU for model training and inference has been intense, but progress has been slow.
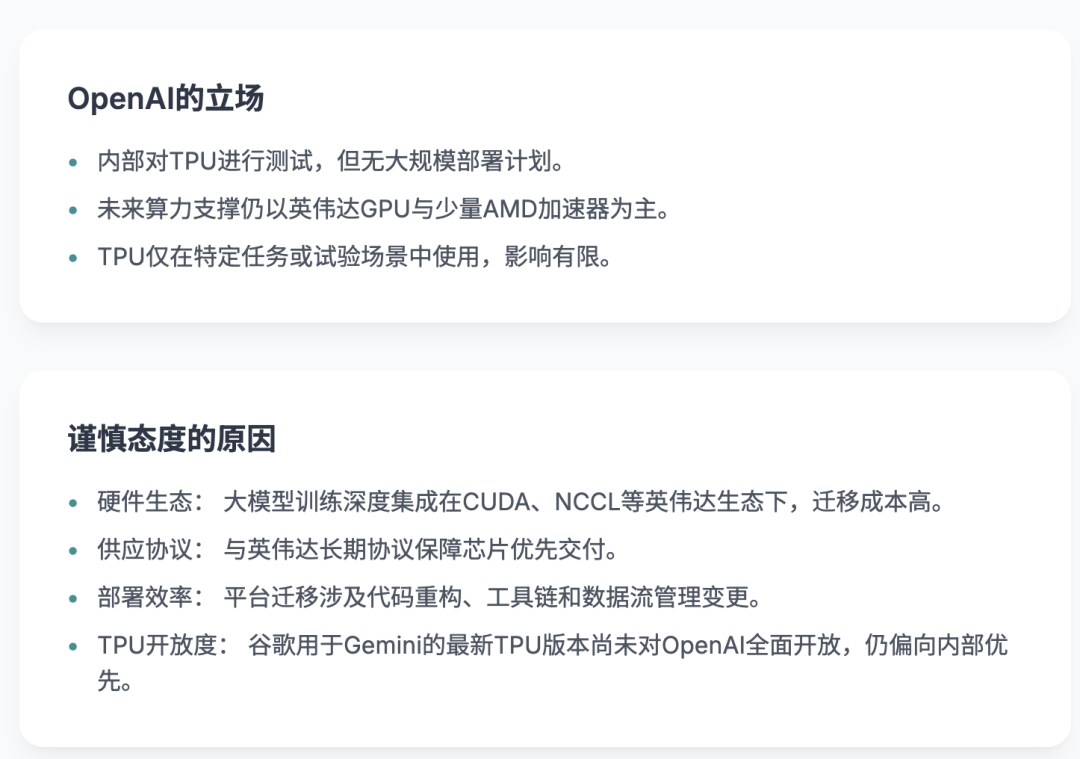
OpenAI has clarified that while it is testing TPU internally, there are no plans for large-scale deployment, and its future computing power support will continue to be dominated by NVIDIA GPUs with a minor complement of AMD accelerators.
Currently, TPU is used in specific tasks or experimental scenarios, with limited actual impact. This cautious approach reflects a deep consideration of hardware ecosystem, deployment efficiency, and platform migration costs.
OpenAI's large model training tasks demand high parallelism and stability, deeply integrated with the NVIDIA ecosystem including CUDA and NCCL. Switching to TPU would entail not only code reconstruction but fundamental changes to the deployment toolchain and data flow management.
Long-term supply agreements with NVIDIA, ensuring priority chip delivery, further complicate the decision to switch hardware platforms.
Currently, while OpenAI has procured some TPU services on Google Cloud, most are basic versions.
Google's latest TPU, used for its Gemini large model, is not yet available to OpenAI. TPU still carries the stigma of being "self-developed and self-used." Despite Google's efforts to promote commercialization, high-performance computing resources are prioritized for internal use.
In terms of AI chip deployment strategy, OpenAI adopts a diversified and exploratory approach, with NVIDIA leading and AMD supplementing, reflecting the structural dependence on heterogeneous computing resources and emphasis on platform stability among large AI enterprises.
Despite TPU's efficiency advantages in certain matrix computation tasks, OpenAI is reluctant to abandon the optimization achievements and system stability it has accumulated on the GPU platform.
Part 2: Google TPU's Cloud Expansion and Ecosystem Breakthrough Challenges
Google TPU emerged from the growing computational demands of its AI services, focusing on neural network training and inference, leveraging a dataflow architecture and matrix multiplication acceleration units to tackle large model computational challenges.
For a long time, TPU primarily served Google's internal applications like Gemini, search, maps, and photos, supporting billions of users.
Only recently has Google officially commercialized TPU and opened it up to external customers, aiming to create a more competitive AI infrastructure platform.
Amidst a global shortage of NVIDIA GPUs and high training costs, TPU commercialization is expected to generate new revenue and weaken NVIDIA's monopoly.
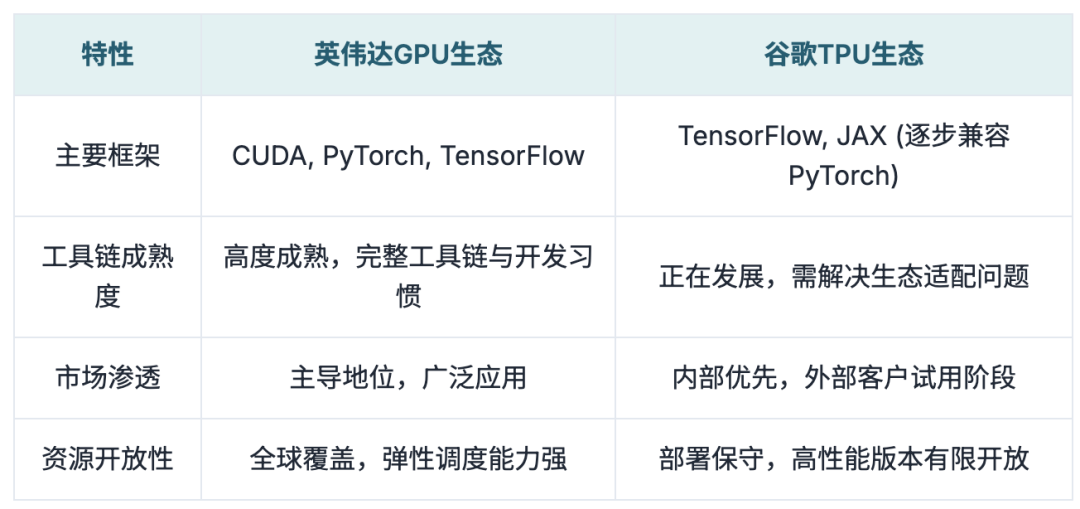
However, challenges persist. TPU natively supports TensorFlow and JAX, with gradual PyTorch compatibility. Yet, in the GPU-dominated large model ecosystem, a mature toolchain and development habits have already formed.
From model fine-tuning and parallel orchestration to deployment optimization, the GPU ecosystem is highly advanced. For GPU-dependent companies (like OpenAI, Anthropic, Meta), switching to TPU entails reconstructing the entire training architecture, tool system, and underlying logic, with high migration costs, long cycles, and deployment timeline disruptions.
TPU's deployment strategy remains conservative. Versions like v5p, v5e, and Trillium are available in select North American, European, and Asian regions but still lag behind NVIDIA in global resource coverage, elastic scheduling, and isolation guarantees.
Additionally, the TPU platform's openness is limited. For instance, Trillium, which supports Gemini, is not fully released, further limiting its penetration in the ultra-large model training market.
While some customers (like Apple and Anthropic) have begun TPU trials, these are mostly driven by resource redundancy or specific task considerations and have not yet formed a stable substitution trend.
As a latecomer in the AI chip field, TPU boasts technical advantages but must address ecosystem adaptation, user mindset shifting, and toolchain completeness to transition from an internal tool to a general-purpose cloud platform.
While its openness is increasing, it has yet to establish a lasting influence among core customers like OpenAI.
In the short term, GPUs will continue to dominate the AI computing architecture, with TPUs and other accelerators serving as supplements. Unless new open-source tools and deployment frameworks supporting cross-platform and standardized development emerge, the market landscape is unlikely to shift significantly.
Currently, TPU functions more as a high-performance supplement rather than an industry transformer. For Google to achieve large-scale TPU breakthroughs, it must not only push performance boundaries but also benchmark NVIDIA in ecosystem connectivity, development experience, and platform openness.
The AI chip market competition is far from over, and the real battle for TPU has just begun.
Summary
OpenAI's statement on limited TPU testing underscores that in ultra-large AI companies, chip partner choice is influenced by performance, deployment inertia, ecosystem integration, and supply relationship stickiness.
OpenAI will continue to rely on NVIDIA as its core, partially adopt AMD, and explore self-developed chips to prepare for future expansion and cost reduction.
-
![]()
Internet Valuation Logic Shifts: From Scale Narrative to Profit Accountability
-
VOYAH Struggles to Find Its Niche in the Competitive Auto Market
-
![]()
Maxwell Technologies Gains Indirect Stake in Precision Optics via New Venture
-
![]()
Raising 1.8 Billion! This Domestic Optical Inspection 'Little Giant' is Going Public
-
China's AI 'Normandy Moment': The Explicit and Implicit Threads of BATL
-
![]()
Starting at 4999 Yuan! Nubia RedMagic Gaming Tablet 5 Pro Review: Impressive Performance, But Hefty Price Tag
-
![]()
ByteDance Initiates First Major Management Reform
-
![]()
AI is Quietly Destroying a Trillion-Dollar Industry