Positioning in the 'Three Abacus' Strategy: Huawei Bets on the Token Economy Era
 08/18 2025
08/18 2025
 729
729

Amidst the aura of the 'First Year of AI Agents', does the AI Agent track represent mere illusory prosperity?
Content/Shannan
Editor/Yong'e
Proofreader/Mangfu
In 2025, with AI applications flourishing globally, the AI inference segment has expanded significantly due to rapid industry development.
'The volume of inference calculations required today is 100 times greater than when large language models first emerged, and this is merely the beginning,' said NVIDIA CEO Jen-Hsun Huang in February of this year.
Similarly, Morgan Stanley analysts estimate that over 75% of US electricity and compute demand will be dedicated to inference in the coming years.
Behind this hundredfold increase in demand for inference compute lies the core logic of enterprise AI application deployment: Inference performance directly influences user experience and the viability of business models. Consequently, the AI inference pie has become a must-win profit for infrastructure enterprises.
Huawei's recently launched UCM Inference Memory Data Manager has been hailed by the industry as a major breakthrough in AI inference technology. However, Huawei's true intention in positioning itself in AI inference extends far beyond the tool gains of a single technology; it aims to construct a grand chessboard of an AI ecosystem.
Part 1: AI Enters Deep Waters, Inference Becomes a Singular Point of Growth
Amidst the AI wave, opportunities and challenges coexist upstream and downstream in the industry chain, with AI inference bearing the brunt and emerging as an important battleground and growth explosion point.
The latest white paper from China Securities Co., Ltd. reveals a significant trend: As AI compute consumption shifts structurally from training to inference, domestic compute consumption is growing rapidly. Taking ByteDance as an example, its Token consumption nearly doubles every three months and reached 16.4 trillion Tokens by the end of May. At this growth rate, mainstream cloud service providers will soon feel the strain on compute power, resulting in a compute gap – the average Token consumption per Agent task has risen to the order of 100,000.
However, pricing logic in emerging markets often defies conventional wisdom and is not solely determined by demand. Facing the blue ocean of large models, giants, startups, operators, and various other enterprises have flocked in, and the ToB market has not escaped the curse of price competition.
Since May last year, Alibaba Cloud first initiated a price reduction for large models, followed immediately by Baidu announcing that its two main Wenxin models, ERNIE Speed and ERNIE Lite, would be completely free. Then, in June of this year, the Doubao large model 1.6 was released, further lowering the price threshold to 2.6 yuan per million Tokens.
Behind the price war, the processing cost and quality of Tokens have become key factors in competition within the large model industry, and AI inference capabilities have become a critical singular point for driving growth. Yan Junjie, founder and CEO of MiniMax, asserts, 'In the next one to two years, the inference cost of the best models may be reduced by an order of magnitude.'
However, technological gaps cannot be ignored. According to Huawei data, the output speed per user for major foreign large models (such as OpenAI O3-mini, Google Gemini, etc.) has reached the range of 200 tokens/s (with a latency of 5ms), while domestic models are generally below 60 tokens/s (with a latency of 50-100ms).
OpenAI O3 mini outputs about 10 times more Tokens per second than a certain domestic open-source large model, immediately revealing a difference in user experience, with OpenAI's response speed being much faster than domestic large models. This shows that there is still significant room for growth in the Chinese AI inference market.
As Zhou Yuefeng, Vice President of Huawei and President of the Data Storage Product Line, stated, 'In the AI era, the dimensions of model training, inference efficiency, and experience are all characterized by the number of Tokens. The Token economy has arrived.'
Seizing the first-mover advantage in the Token era is Huawei's most explicit strategic positioning in AI inference, marking Huawei's first abacus.
Part 2: Horizontal Analysis of Huawei UCM AI Inference Capabilities
Focusing on Huawei's newly launched AI inference technology, UCM, what are its core competitiveness and market positioning?
Huawei UCM is an inference acceleration suite centered on KV Cache (Key-Value Cache), integrating multiple types of cache acceleration algorithm tools. It can hierarchically manage KV Cache memory data generated during the inference process, expand the inference context window, and achieve high-throughput, low-latency inference experiences, thereby reducing the cost of inference per Token.
In simple terms, Huawei UCM functions like an intelligent dispatch system in a kitchen. It can classify and store various ingredient lists (KV Cache) needed by chefs when cooking, using whiteboards, binders, and filing cabinets of different sizes (multi-level caching). Coupled with various memory management tools (cache algorithm tools), it enables chefs to easily remember extra-long menus (expand context), thus serving dishes faster (low latency), able to serve more guests (high throughput), and saving labor (reducing the cost per Token). Ultimately, the customer's (using AI) experience is fast service, good service, and affordable prices.
Compared to the industry, Huawei UCM's differentiated advantage lies in its shift from single-point compute modules to system-level optimization. Li Guojie, Chief AI Storage Architect of Huawei's Data Storage Product Line, stated that there are many open-source solutions in the industry with similar directions, some of which have implemented a certain layer or some components, but no commercial end-to-end complete solution has been seen, and UCM is the first full-process, full-scenario, and evolvable systematic solution.
This also marks a strategic shift from relying on single-point compute modules to optimizing overall system efficiency in AI inference engines.
Furthermore, UCM is a countermeasure under the blockade. The United States has comprehensively banned the export of HBM2E and higher-level high-bandwidth memory to China since January 2, 2025. This poses an obstacle to AI development that relies on advanced hardware.
Compared to ordinary memory (DDR), HBM has a conveyor belt width more than 10 times greater and can achieve parallel transmission through thousands of micro-channels, but the drawback is its high cost. In AI servers, the cost of HBM accounts for about 20% to 30%.
UCM can achieve on-demand flow between storage media such as HBM, DRAM, and SSD based on memory heat, while integrating multiple sparse attention algorithms to achieve deep coordination between storage and computation, increasing TPS (Tokens Processed per Second) by 2 to 22 times in long-sequence scenarios, thereby reducing the cost of inference per Token.
A foreign media report by TEKEDIA pointed out that the 'core appeal' and service selling point of UCM is clear: If software can more fully tap the performance potential of ordinary memory, then Chinese suppliers (such as Huawei and other vendors) can still provide competitive AI inference services without relying so heavily on scarce and expensive high-bandwidth memory (HBM).
'This is crucial because the global HBM market is growing rapidly – this year it is worth about $34 billion and is expected to reach $98 billion by 2030 – and its supply is basically monopolized by SK Hynix, Samsung, and Micron, all non-Chinese companies, completely out of China's control.'
It can be seen that the significance of UCM goes far beyond improving AI inference efficiency. Its deeper strategic intention is to build a technical path for vendors, including Huawei, to reduce reliance on HBM memory, lower the external dependence on key hardware, and enhance supply chain resilience and autonomous controllability.
This is Huawei's second abacus in the complex international environment.
Part 3: Open Source Foundation, the Outline of the 'Industrial Empire' Begins to Emerge
'Most startups rely on state-of-the-art models in their early stages, which are usually closed ecosystems with their own inference mechanisms. However, in the future, more and more enterprises will start looking for alternatives, such as training their own models or using open-source models to alleviate some economic pressures. There are already many powerful open-source models on the market, and there will be more in the future,' said Danila Shtan, CTO of Nebius.
Huawei announced plans to officially open source UCM in September of this year, with the first release on the MoEngine community, followed by gradual contributions to mainstream inference engine communities in the industry and sharing with all Share Everything (shared architecture) storage vendors and ecological partners in the industry.
This open-source initiative will attract more developers and enterprises to participate in the construction of the AI inference ecosystem, promote the co-construction and maturation of the entire mechanism by frameworks, storage, and GPU vendors, stimulate innovation vitality, and accelerate technology iteration and optimization.
However, open sourcing UCM is not a money-losing 'charity.' When storage vendors, cloud service providers, and even competitors in China and globally widely adopt UCM, an AI inference infrastructure layer based on Huawei's technology stack and autonomous controllability will rise strongly. At that time, a super-ecological network dominated by Huawei, covering the full stack of compute hardware, inference frameworks, and application deployment, will emerge, and the outline of a new 'industrial empire' will become apparent.
According to incomplete statistics, the 'key allies' in the AI inference ecosystem centered around UCM include, but are not limited to: Tuowei Information, Digital China, iSoftStone, and Hengwei Technology at the compute hardware layer; Huahai Chengke, Glingo, Cambricon, and Montage Technology at the inference framework layer; and Runda Medical, Sysware, CloudTop Technology, and Goland at the application deployment layer.
Open source is also an ecological investment. By empowering partners and growing the ecosystem, Huawei will gain feedback from a wider range of application scenarios, stronger standard discourse power, and a more solid market foundation. This virtuous cycle of 'feeding technology evolution with commercial success' is not a kind of 'feeding war with war' wisdom? And this is Huawei's third abacus in betting on AI inference.
The wheel of technological innovation rolls forward, and the 'thinking' and inference capabilities of models will only become more powerful. Huawei's 'three abacuses' in betting on AI inference – seizing the first-mover advantage in the Token economy, breaking through the HBM blockade, and building an autonomous ecosystem – have been clearly positioned. For other AI vendors, building an autonomous, powerful, and open technical ecosystem is also a strategic task that cannot be delayed.
The window of opportunity for Chinese enterprises is narrowing, and the battle to build core competitiveness has already begun.
END
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
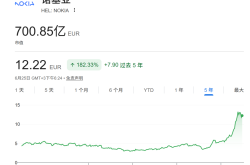
Why Is Nokia Making a Comeback in the AI Era?