Inference Efficiency: The Overlooked AI "Achilles' Heel"
 08/28 2025
08/28 2025
 746
746

"The larger the parameters, the dimmer the bulb?"
Author | Wang Zi
Produced by | JiXin
The International Energy Agency's (IEA) 2025 baseline scenario reveals that global data centers consumed approximately 415 terawatt-hours (TWh) of electricity in 2024, accounting for 1.5% of global electricity use. By 2030, this figure could double to 945 TWh, with AI computing servers contributing nearly half of this increment.
In the tech industry, it is a well-established fact that the lifeblood of computing power is electricity.
This implies that enterprises with extensive computing requirements must also shoulder equally substantial energy bills.
In the latter stages of the AI race, the focus shifts to power grids and clean energy.
Yet, apart from "adding power," perhaps there exists another viable path:
How much electricity do large models consume?
Let's delve into the magnitude:
Bigger models + longer training → higher energy consumption
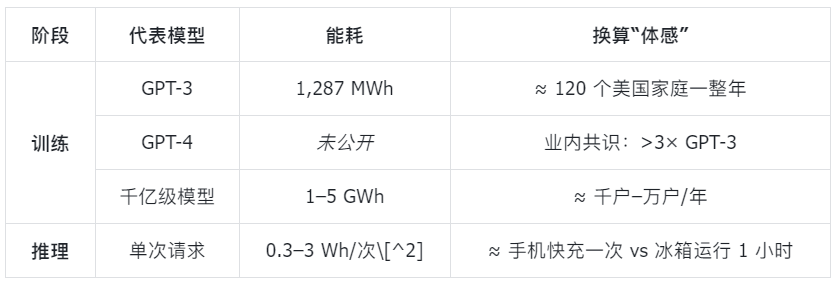
0.3–3 Wh/inference serves as a conservative range for "environmental estimation." Using this range to calculate a "1 billion inferences/day" scenario:
Daily electricity consumption = 1 billion inferences × (0.3–3 Wh/inference) × PUE
= 0.33–4.7 GWh
≈ 16,000–160,000 households/day[^3]
The economic cost for enterprises:
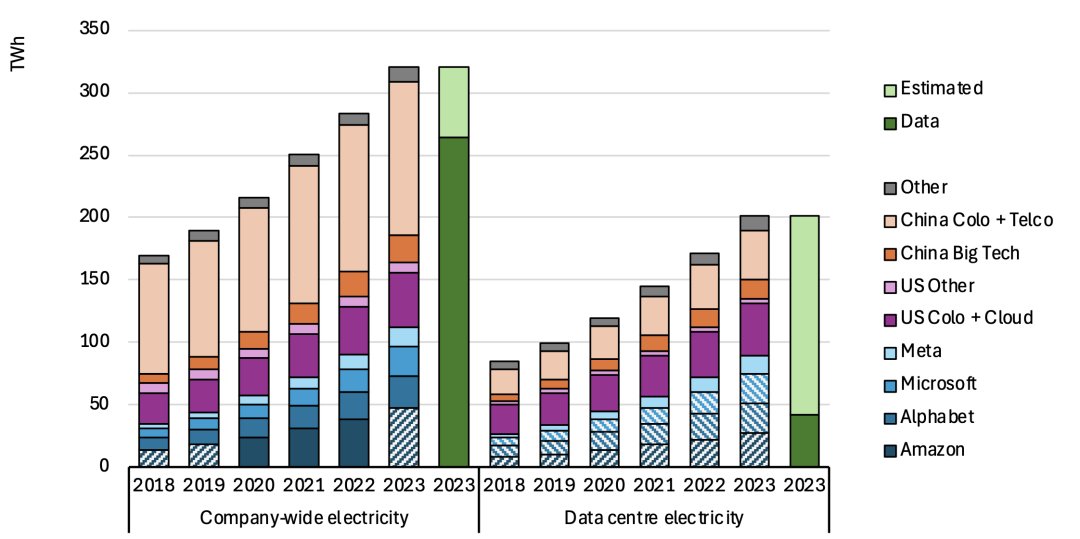
Figure: Estimated electricity consumption of large data center operators and technology companies from 2018–2023
Image source: IEA 4E TCP / EDNA, "Data Centre Energy Use: Critical Review of Models and Results", 2025.03
Energy becomes a pivotal component of long-term operating costs: Early McKinsey calculations suggest that large model deployments can drive annual electricity bills for enterprises ranging from tens of thousands to hundreds of thousands of dollars (primarily due to inference loads), transforming into a quantifiable operating expense—especially as inference becomes the largest unit of electricity consumption for "continuous operations".
Infrastructure site selection significantly impacts return on investment: Data indicates that by 2030, data center electricity demand in the United States will account for nearly half of the country's electricity growth. Grid reconstruction and new capacity bottlenecks make site selection prefer "areas with cheap and reliable electricity." Some companies are opting to build large model infrastructure in regions with abundant wind energy and lower prices, such as Inner Mongolia and Gansu.
Enterprises secure green electricity and sign energy agreements to substantially reduce burdens: Google signed a nuclear power agreement with Kairos Power to provide future clean electricity for its US AI data centers. Additionally, GridFree AI's startup business constructs high-efficiency data centers through "on-site power supply," significantly reducing operating budgets. As electricity bills become the primary item on corporate expenses, low-carbon, low-cost power supply has been integrated into business competition strategies.
AI model efficiency equates to financial efficiency: GPT4's inference energy consumption, if converted based on the current total number of queries, is equivalent to the electricity consumption of 35,000 American households per year; the amount of evaporated cooling water could fill more than 500 Olympic-sized swimming pools. These "invisible costs" are becoming increasingly tangible.
The most extreme comparison: GPT5, which is "skipping grades" in terms of both technological capability and cost: It is estimated that each inference consumes up to 18 Wh. Assuming 2.5 billion invocations per day, the daily power consumption is as high as 45 GWh, equivalent to the daily electricity consumption of 1.5 million households or even the output of several nuclear power plants.

This calculation is not solely for enterprises but also for investors.
Capital questions are subtly shifting
In recent years, capital market attention on large models has almost exclusively centered on "parameter size" and "model performance" indicators. However, the winds are changing.
With the steep rise in computing power costs and electricity bills, investors are increasingly recognizing that what truly determines the commercial viability of AI is not the size of the model but its inference efficiency—how many inference results can be produced per watt-hour of electricity.
Positron AI, a startup focused on high-efficiency inference chips, recently secured $51.6 million in funding, with investors stating that "improving inference efficiency is the biggest opportunity." EnCharge AI is planning to raise $150 million, and its chip efficiency is said to be 20 times higher than that of NVIDIA products. The UK startup Lumai is attempting to reduce inference energy consumption using optical computing and has received over $10 million in investment. Etched.ai has secured $120 million in funding based on its energy-saving advantage of "replacing 160 H100 servers with one".
Simultaneously, energy giants are entering the fray. Companies like Chevron and GE Vernova are investing in natural gas power plants specifically for data centers. There are even ideas for "green computing power futures" (i.e., hedging against future AI electricity consumption risks by purchasing clean power quotas in advance). This capital logic deeply intertwines the growth curve of AI with the energy market.
Tech giants are also placing bets on energy through their actions. OpenAI CEO Sam Altman has emphasized multiple times that the future development of AI hinges on energy breakthroughs, particularly nuclear fusion or inexpensive solar energy + storage. He has invested $375 million in the nuclear fusion startup Helion Energy—his largest personal investment to date. Amazon acquired nuclear energy developer X-energy, Microsoft funded the construction of a geothermal energy-driven data center in Kenya, Apple invested in a 100% green power data center powered by hydrogen energy storage in Texas, and launched a project in Houston to convert natural gas electricity to hydrogen green power.
The core contradiction in the large model race is evolving from "whether the model can be built" to "whether the built model can run efficiently, low-carbon, and sustainably".
How to reduce this energy bill?
Answer: Reduce the "electricity per token".
Minimizing the electricity cost required for each inference is no longer merely an engineering optimization but a critical factor in determining whether AI services can scale profitably.
In practical applications, this difference is often magnified:
Scenario 1: Real-time voice assistants. Assuming two products have identical performance but one consumes 10% more electricity per thousand inferences. When electricity costs constitute a significant portion of the overall cost, this 10% efficiency gap might be sufficient to erase profits or even push the product into losses.
Scenario 2: Edge mobile models. On mobile phones or off-grid devices, energy efficiency directly influences user experience. For the same AI function, lower energy consumption translates to longer battery life on mobile phones or the ability to process more user requests with a fixed battery capacity.
In essence, the inference efficiency ratio represents the "unit economics" of AI.
Improving inference efficiency offers a pragmatic solution to alleviate the "large model electricity consumption problem".
Algorithmic Level
Speculative Decoding is considered a significant path in recent years. In their paper "Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding," scholars like Heming Xia reviewed related progress: By initially generating candidates through a lightweight "draft model" and then validating them with a large model, it significantly reduces repeated token-by-token calculations.
Experimental results demonstrate that speculative decoding can provide 2–3 times the inference acceleration and energy consumption reduction, equivalent to doubling the number of invocations supported by the same kWh of electricity. Speculative decoding transforms "energy efficiency" from an abstract algorithmic indicator into a real-world variable that can be directly correlated with electricity bills and battery life.

Looking longer term, if we consider the "inference efficiency ratio" as a consensus indicator for industrial competition, then speculative decoding represents the first generation of technology driving its decline. Future LLM inference is anticipated to approach Moore's Law-style improvements in the metric of "how many tokens can be produced per watt-hour." Only then might the cost curve and energy consumption curve of the AI industry truly experience an inflection point.
Model Compression
FP8/FP4 low precision, structured sparsity, distillation, and small modelization are already implemented in mainstream inference frameworks, typically yielding 30–60% energy savings without significantly compromising accuracy.
Hardware Upgrades
In the past, the energy cost of training a single large language model (LLM) could be as high as $140 million, making the entire process nearly economically unfeasible. However, with the iteration of chip architectures, this situation is changing.
NVIDIA claims that its latest Blackwell/GB200 architecture offers a 25-fold improvement in inference efficiency over the previous-generation Hopper (from approximately 10 joules/token to 0.4).
While this is the supplier's statement, it underscores that the electricity required to process natural language tasks of the same scale is significantly reduced, thereby directly lowering operating costs.
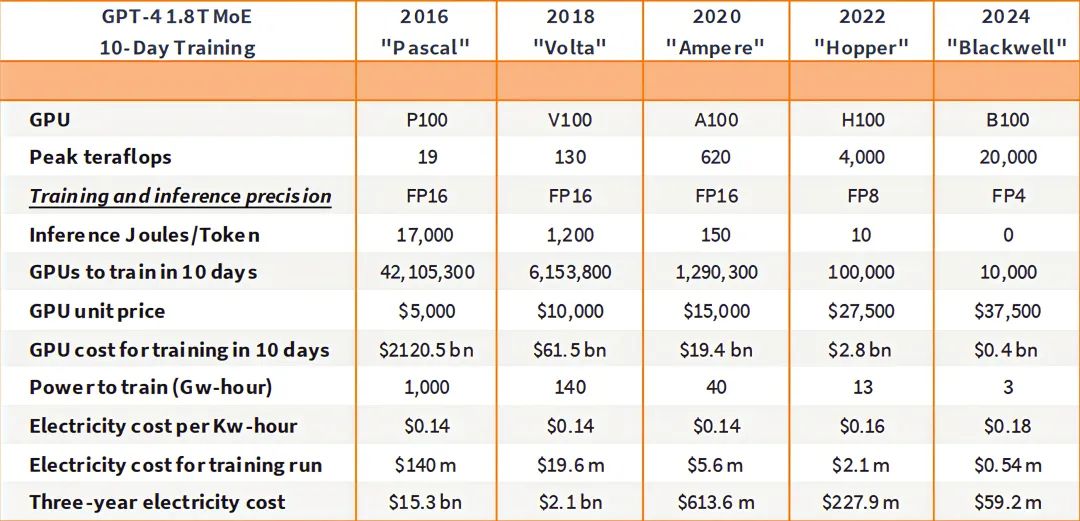
Figure: The iteration of GPUs from Pascal to Blackwell has reduced the electricity bill for training large models from over $140 million to less than $600,000.
Who will secure the late-mover advantage in the next five years?
In the game of computing power and electricity, the United States and China exhibit distinct paths:
United States: "Dare to invest but difficult to supply"—bold capital, rapid technology, but strained grid
On one hand, companies like Amazon, Google, and OpenAI are accelerating their investments in clean energy;
On the other hand, the US grid is issuing warnings—the largest grid operator in the Northeast, PJM, reports that electricity supply will be insufficient to meet the demand of newly built data centers in the coming years; the load growth of data centers in California is linked to real-time electricity prices, highlighting the pressure on grid upgrades.
China: "Can build but difficult to adjust"—large installed capacity, fast supply, but coal power dependence and consumption challenges
Under the "East Data, West Compute" strategy, China's eastern computing power demand is being connected with the west's wind, solar, and hydropower advantages. By the end of 2024, China's wind and solar power installed capacity had exceeded 1.4 billion kilowatts, providing robust green power support for data centers.
The "JLL Data Center Investment Report" reveals that China's data center electricity consumption continues to rise, expected to reach 400 billion kWh by 2030, accounting for approximately 3.7% of the country's total electricity consumption.
Unlike the United States, the Chinese government adopts a "nationwide unified" scheduling approach, massively expanding green power while simultaneously optimizing the layout of the grid and data centers. The challenge lies in balancing the ratio of coal power and clean energy.
-
![]()
Why Are Automakers Flocking to Embodied AI?
-
![]()
The Illusion of Recovery in China's Commercial Rockets: Pre-Designed Endgame Capabilities
-
![]()
Will Choosing the Wrong Technical Route Between World Model and VLA Lead to Elimination?
-
Meituan, with RMB 390 Billion Valuation, Ensnared in the 'Silence Spiral' of Low Stock Prices
-
![]()
iPhone 18 Introduces an Unusual "9GB" Memory Spec—Does Apple Truly Deserve the Title of "Precision Marketing Master"?
-
![]()
From AR Bubble to AI Boom: Rokid Faces a Pivotal Battle
-
![]()
iPhone 18 Adopts Unconventional '9GB' Memory Spec: Is Apple Still the 'Master of Precision'?
-
![]()
Congratulations to Xiaomi on Securing Another 'Global Pioneer' Accolade, Yet a Piece of Advice for Lei Jun: Prioritize the Lower Bound, Not Just Flaunting the Upper Bound




