The First Open-Source LLM-Based Audio Model! Step-Stellar Unveils Step-Audio-EditX: Making Voice Editing a Breeze!
 11/07 2025
11/07 2025
 622
622
Decoding the Future of AI-Generated Audio 
Article Link: https://arxiv.org/pdf/2511.03601 Open-Source Link: https://github.com/stepfun-ai/Step-Audio-EditX Demo Link: https://stepaudiollm.github.io/step-audio-editx/
Key Highlights
First Open-Source LLM-Based Audio Editing Model: Step-Audio-EditX is the first open-source audio model based on large language models (LLMs), excelling in expressive and iterative audio editing (covering emotions, speaking styles, and paralinguistic features) with robust zero-shot text-to-speech (TTS) capabilities.
Innovative Large-Margin Data-Driven Approach: The model's core innovation lies in training solely on large-margin synthetic data, eliminating reliance on embedded priors or auxiliary modules. This method enables decoupled and iterative control over voice attributes.
Paradigm Shift: This work represents a fundamental shift from traditional representation-level decoupling methods to data-driven control, demonstrating effective emotional and stylistic control through post-training with large-margin data alone.
 Figure 1: Comparison of Step-Audio-EditX with Closed-Source Models. (a) Step-Audio-EditX outperforms Minimax and Doubao in zero-shot cloning and emotional control. (b) Emotional editing with Step-Audio-EditX significantly improves emotional control in audio outputs across all three models after just one iteration, with continued overall performance enhancement as iterations increase.
Figure 1: Comparison of Step-Audio-EditX with Closed-Source Models. (a) Step-Audio-EditX outperforms Minimax and Doubao in zero-shot cloning and emotional control. (b) Emotional editing with Step-Audio-EditX significantly improves emotional control in audio outputs across all three models after just one iteration, with continued overall performance enhancement as iterations increase.
Problems Addressed
Limited Control in Zero-Shot TTS: Despite significant advancements in generating high-quality speech, zero-shot TTS still derives emotional, stylistic, and accent attributes directly from reference audio, preventing independent and fine-grained control over these properties.
Difficulty in Decoupling Voice Attributes: Existing methods attempt to control outputs by adding style instructions before input text but face challenges in decoupling voice attributes, often resulting in cloned voices that fail to effectively follow given style or emotional instructions.
High Data Collection Costs: Traditional methods require extensive high-quality, finely annotated data to train expressive TTS systems, making data collection and annotation prohibitively expensive.
Proposed Solutions and Applied Technologies
1. Model Architecture: Step-Audio-EditX employs a unified framework with three core components:
2. Large-Margin Synthetic Data: An efficient data construction method is introduced. Using zero-shot voice cloning technology, audio pairs with identical linguistic content but significantly different emotions or styles (i.e., 'large-margin') are generated for the same speaker. These contrasting sample pairs enable the model to focus on learning variations in emotions and styles during training.
3. Two-Stage Post-Training Strategy:
Supervised Fine-Tuning (SFT): The model is fine-tuned using constructed large-margin data to enable zero-shot TTS and diverse audio editing capabilities.
Reinforcement Learning (RL): The PPO algorithm is employed, incorporating human annotations and preference data generated by LLM-as-a-Judge, to further enhance model stability in zero-shot TTS and expressiveness in handling challenging editing tasks (e.g., generating sad speech from happy prompts).
Achieved Results
Architecture
Overview
In previous work, Step-Audio introduced an Audio-Edit synthesis model for generating data with nuanced emotional expressions and diverse speaking styles. In this report, the previous model and the same audio tokenizer are retained. Key modifications include expanding the range of emotions and speaking styles, adding zero-shot TTS and paralinguistic editing capabilities, and reducing model parameters from 130B to 3B. Leveraging large-margin synthetic data, the 3B model demonstrates superior and more stable performance than the previous version.
The system comprises three main components: (1) a dual-codebook audio tokenizer that converts reference or input audio into discrete tokens; (2) an audio LLM that generates dual-codebook token sequences; and (3) an audio decoder that converts the audio LLM-predicted dual-codebook token sequences back into audio waveforms using flow matching. This integrated architecture enables Step-Audio-EditX to perform zero-shot TTS and diverse editing tasks within a unified framework, directly leveraging the rich ecosystem of post-training techniques developed for text LLMs.
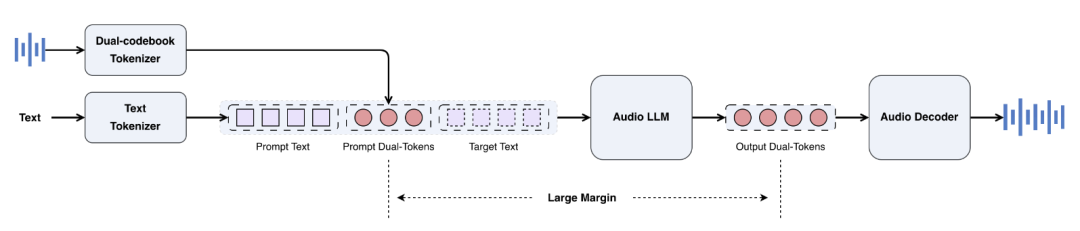 Figure 2: Overview of Step-Audio-EditX Architecture
Figure 2: Overview of Step-Audio-EditX Architecture
Audio Tokenizer
The effectiveness of LLM post-training with large-margin data is investigated by retaining the dual-codebook tokenization framework from the previous Step-Audio model. This framework employs parallel linguistic (16.7 Hz, 1024-codebook) and semantic (25 Hz, 4096-codebook) tokenizers in a 2:3 interleaved ratio. Based on a series of downstream audio tokenizer reconstruction experiments, it is observed that the dual-codebook tokenizer retains substantial emotional, prosodic, and other non-verbal information, indicating suboptimal decoupling. This drawback makes it particularly suitable for validating the effectiveness of our LLM post-training strategy and proposed large-margin data-driven approach.
Audio LLM
The audio LLM utilizes the same architecture as the previous Audio-Edit model, differing only in parameter scale, which is reduced to 3B. To leverage the powerful linguistic capabilities of pre-trained text LLMs, this 3B model is first initialized with a text-based LLM and then trained on a 1:1 mixed dataset of text data and audio dual-codebook tokens. The audio LLM processes text tokens and their corresponding audio dual-codebook tokens in a chat format, subsequently generating dual-codebook tokens as the sole output.
Audio Decoder
The audio decoder consists of a flow matching module and a BigVGANv2 vocoder. Given the output audio tokens, reference audio, and speaker embeddings as conditions, the flow matching module generates Mel-spectrograms, which are further converted into waveforms by the BigVGANv2 vocoder. For the flow matching module, a Diffusion Transformer (DiT) is adopted as its backbone network and trained on 200,000 hours of high-quality speech data. This enhancement significantly improves its Mel-spectrogram reconstruction capability, resulting in substantial improvements in both pronunciation accuracy and timbre similarity.
Data
Consistent with previous work on StepAudio pre-training datasets and methodologies, this report focuses on post-training datasets and their corresponding methods.
SFT Data
Supervised fine-tuning (SFT) is employed to enable the Step-Audio-EditX model to perform zero-shot TTS and diverse audio editing tasks. SFT data can be categorized into several segments: zero-shot TTS, emotional editing, speaking style editing, and paralinguistic editing. Notably, the large-margin dataset primarily targets editing tasks, particularly in emotions and speaking styles.
Zero-Shot Text-to-Speech
A high-quality, professionally annotated internal dataset primarily comprising Chinese and English is used for zero-shot TTS training. Additionally, a small amount of Cantonese and Sichuanese data is employed to guide the model's dialectal capabilities. To ensure synthesized speech exhibits diverse and highly expressive styles and emotions with robust zero-shot performance, the dataset captures voice variations both within individual speakers and across a broad speaker population, totaling approximately 60,000 unique individuals.
Emotional and Speaking Style Editing
Emotional and speaking styles pose significant challenges for expressive text-to-speech systems due to inherent difficulties in defining categorical features and collecting high-quality data. We propose a direct and efficient large-margin synthetic data method that enables zero-shot voice cloning between different emotions and speaking styles for the same speaker while ensuring sufficiently large differences between contrasting sample pairs. Each emotion or speaking style requires only a single prompted audio clip, eliminating the need for costly data collection. Furthermore, this method cleverly transforms complex emotional and stylistic descriptions into a comparative pair-based data construction format. Next, we introduce the proposed method:
Voice Actor Recordings. Voice actors record expressive emotions and speaking styles. For each actor, a roughly 10-second audio clip is recorded for each combination of emotion and style.
Zero-Shot Cloning. For each emotion and speaking style, a triplet is constructed by selecting corresponding emotional and neutral audio clips from the same speaker as prompted audio and processing them through the StepTTS voice cloning interface using text instructions describing the target attributes.
Margin Scoring. To evaluate the generated triplets, a scoring model is developed using a small set of manually annotated data. This model assesses audio pairs on a 1-10 scale, with higher margin scores corresponding to more desirable outcomes.
Margin Selection. Samples are selected based on a margin score threshold. This threshold is adjusted for different emotions and styles, with a general lower limit set at 6 points.
Notably, audio clips within each triplet are generated using identical emotional or stylistic text prompts, encouraging the model to focus solely on variations in emotions and styles during SFT training.
Paralinguistic Editing
Paralinguistic cues, such as breaths, laughter, and filled pauses (e.g., 'uhm'), are crucial for enhancing the naturalness and expressiveness of synthesized speech. We achieve paralinguistic editing capabilities by employing a 'semi-synthetic' strategy that leverages the NVSpeech dataset, a highly expressive speech corpus with rich annotations for various paralinguistic types, enabling the construction of comparative quadruplets for model training. Unlike triplets, quadruplets are constructed using NVSpeech's original audio and transcriptions as target outputs, while StepTTS voice-cloned audio synthesized from the original transcriptions with paralinguistic labels removed serves as inputs.
Since paralinguistic editing is an editing task performed in the time domain and exhibits significant intrinsic margin differences, a margin scoring model is unnecessary for data filtering. A small subset of quadruplet data is sufficient to effectively elicit the model's paralinguistic editing capabilities.
Reinforcement Learning Data
To align our model with human preferences, two distinct methods are employed to construct two types of preference datasets: one based on human annotations and another utilizing the LLM-as-a-Judge approach.
Human Annotations. Real-world prompted audio and corresponding text prompts are collected from users, and 20 candidate responses are generated using the SFT model. Annotators then rate each of these 20 responses on a 5-point scale based on criteria such as correctness, prosody, and naturalness, constructing 'select/reject' pairs. Only pairs with a score difference greater than 3 are selected.
LLM-as-a-Judge. A comprehension model rates model responses for emotional and speaking style editing on a 1-10 scale. Preference pairs are then generated based on these scores, with only pairs exhibiting a score difference greater than 8 retained in the final dataset.
These selected large-margin pairs are used to train the reward model and PPO.
Training
The post-training process aligns the model's outputs with zero-shot TTS, various editing tasks, and human preferences. This alignment is achieved through a two-stage approach: first, SFT, followed by Proximal Policy Optimization (PPO).
Supervised Fine-Tuning
The SFT phase enhances the model's zero-shot text-to-speech synthesis and editing capabilities by employing different system prompts in a chat format. For zero-shot TTS tasks, the prompted waveform is encoded into dual-codebook tokens, subsequently detokenized into string format and integrated into the speaker information of the system prompt. The text to be synthesized serves as the user prompt, input in a chat format, with the generated dual-codebook tokens returned as the system's response. For editing tasks, all operations are defined under a unified system prompt. The user prompt includes the original audio and instructions describing the editing operations, with the system response providing the edited audio tokens. The model undergoes fine-tuning for one epoch using a learning rate ranging from 1 × 10 to 1 × 10.
Reinforcement Learning
Reinforcement learning further enhances the model's stability in zero-shot TTS, as well as its capabilities and expressiveness in executing editing instructions. These enhancements are particularly pronounced when significant differences exist in emotional and stylistic features between the source prompted waveform and target edited output, such as generating sad speech from a happy prompt or converting loud speech into a whisper. This reinforcement learning approach offers a novel perspective for addressing these challenges, shifting the focus from achieving ideal voice representation decoupling to improving the construction of large-margin pairings and the effectiveness of reward model evaluation.
Reward Model Training. The reward model is initialized from a 3B-parameter SFT model and trained using a combination of large-margin data generated by human annotations and LLM-as-a-Judge, optimized with Bradley-Terry loss. This model is a token-level reward model trained directly on large-margin dual-codebook token pairs, avoiding the need to convert tokens back into waveforms using an audio decoder during reward calculation. The model undergoes fine-tuning for one epoch, with the learning rate following a cosine decay strategy, an initial value of 2 × 10, and a lower limit set at 1 × 10.
PPO Training. After obtaining the reward model, we employ the PPO algorithm for further training, utilizing the same prompt seeds as those used in reward model training, but only selecting the most challenging prompts from the SFT model. During the PPO training phase, the critic model is pre-warmed 80 steps ahead of the actor model. The optimizer uses an initial learning rate of 1 × 10 and follows a cosine decay schedule with a lower bound of 2 × 10. The clipping threshold ε for PPO is set to 0.2, and the KL divergence penalty coefficient β is 0.05.
Evaluation
Accurately and comprehensively evaluating a model's performance in synthesizing emotions, styles, and paralinguistic speech poses a significant challenge. To address this issue, we first introduce the construction of a comprehensive and reproducible benchmark in Section 5.1. Then, in Section 5.2, we utilize this benchmark to demonstrate the advantages of our Step-Audio-EditX model.
Evaluation Benchmark
Introducing Step-Audio-Edit-Test, a benchmark that leverages the LLM-as-a-judge model to assess a model's performance in emotions, speaking styles, and paralinguistics. All evaluated audio is generated through zero-shot voice cloning and subsequently scored using the Gemini-2.5-Pro¹ model.
Speaker Selection. The speaker set used for zero-shot cloning includes eight speakers (2 male and 2 female for both Chinese and English). Chinese speakers are sourced from the Wenet-Speech4TTS corpus, while English speakers are drawn from the open-source GLOBE-V2 and Libri-Light datasets, respectively.
Emotion. The emotion test set covers five categories: happiness, anger, sadness, fear, and surprise. Each category contains 50 Chinese and 50 English prompts, with the textual content of each prompt designed to align with its corresponding target emotion.
Speaking Style. The test set includes seven speaking styles: childlike, elderly, exaggerated, chanting, enthusiastic, coquettish, and whispering. Each style contains 50 Chinese and 50 English prompts, with content matching its target style.
Paralinguistics. The paralinguistic test set includes ten paralinguistic labels per speaker: breath, laughter, surprise-oh, affirmation-mm, murmuring, surprise-ah, surprise-wow, sigh, question-eh, and dissatisfaction-hum. Each label contains 50 LLM-generated Chinese samples and 50 English samples.
Emotion and Speaking Style Evaluation. To evaluate emotions and speaking styles, we provide the Gemini-2.5-Pro model with a predefined set of categories (5 emotions and 7 styles) in the prompt and instruct it to classify the audio. The final accuracy for each category is calculated as the average across all speakers.
Paralinguistic Style Evaluation. To assess paralinguistic editing performance, we designed a specialized evaluation prompt for the Gemini-2.5-Pro model, adopting a strict 1-3 point scoring standard (3 = perfect, 2 = flawed, 1 = failed). This prompt guides the model to actively inspect specific evaluation points in the audio—for example, whether annotations like [laughter] or [sigh] are accurately inserted. Particular emphasis is placed on the most common failure mode—"omission," where the audio may sound fluent but lacks essential paralinguistic elements specified in the instructions. Finally, the model's performance in paralinguistic editing tasks is evaluated by calculating the overall average score generated by the Gemini-2.5-Pro model.
Evaluation Results
This section details our model's performance on the Step-Audio-Edit-Test benchmark and demonstrates its superior editing accuracy and scalability when editing audio generated by various closed-source TTS systems.
Emotion and Speaking Style Editing Results
The evaluation employs an iterative approach for audio emotion and speaking style editing. The process begins with zero-shot cloning as the initial audio iteration, followed by N rounds of iterative editing. The output of the Nth round is denoted as iterationN. In this specific setup, N is configured to 3. For most use cases, two editing iterations are sufficient to meet desired standards.
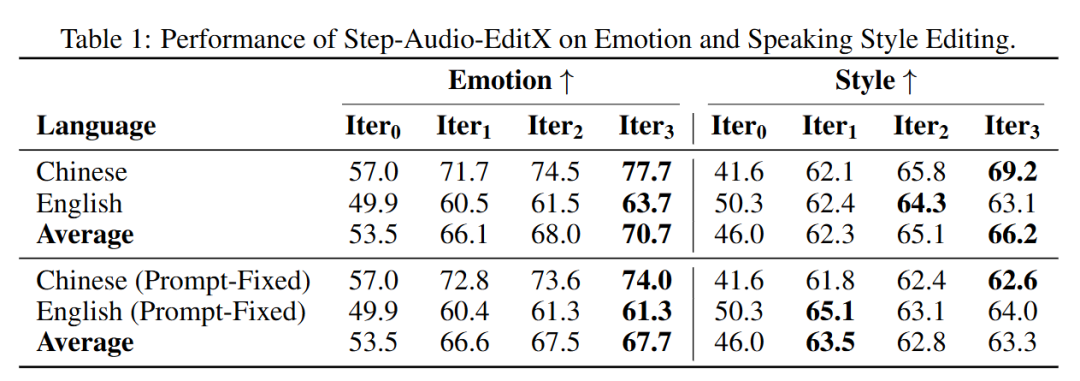
Iterative Editing Results. As shown in Table 1, after the initial editing of Iter audio, significant improvements are observed in both emotion and speaking style accuracy. Furthermore, as the number of editing iterations increases, accuracy in both emotion and speaking styles is further enhanced.
Prompt Audio Ablation Study. Since the performance improvements in subsequent iterations (starting from Iter) are attributed to the combined effects of the dual codebook and prompt audio, we conducted an ablation study to isolate the impact of prompt audio. In this study, the prompt audio remained unchanged across all iterations. As shown in the "Prompt-Fixed" section of Table 1, accuracy in emotions and speaking styles consistently improved with increasing editing iterations. This clearly demonstrates the effectiveness of our large-margin approach.
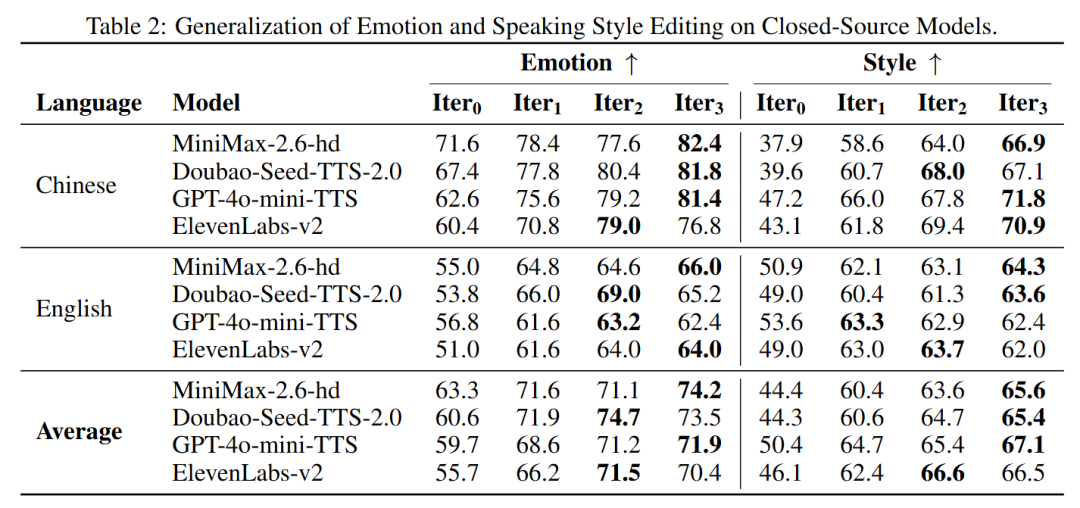
Generalization Ability on Closed-Source Models. The emotion and speaking style generalization capabilities of the Step-Audio-EditX model were evaluated on a series of leading closed-source TTS systems, including GPT-4o-mini-TTS¹, Eleven_Multilingual_v2², Doubao-Seed-TTS-2.0³, and MiniMax-speech-2.6-hd. For each TTS system, one male and one female built-in voice were selected to synthesize speech directly from the source text. Subsequently, three iterative edits were applied to the generated audio outputs. As shown in Table 2, the built-in voices of these closed-source systems exhibit considerable contextual capabilities, enabling them to partially convey emotions from the text. After a single edit using Step-Audio-EditX, all speech models demonstrated significant improvements in emotion and style accuracy. Further enhancements were observed in the next two iterations, strongly demonstrating our model's robust generalization ability.
Emotion Control on Closed-Source Models. Due to the limited availability of closed-source systems for emotion and speaking style control, a comparative evaluation was conducted on Doubao-Seed-TTS-2.0 and MiniMax-speech-2.6-hd, selected for their capabilities in zero-shot cloning and emotion control. To meet the minimum audio length requirements of closed-source models and ensure fair evaluation, the prompt audio for all speakers in the Step-Audio-Edit-Test was extended in duration. These extended audios were used for zero-shot cloning, followed by two iterations of emotion editing. Additionally, the cloned voices were employed to generate emotional speech using each closed-source model's native emotion control functionality. The output from this native emotion control was subsequently subjected to another round of editing using our model. The following observations can be made from Table 3:
Compared to the other two models, our Step-Audio-EditX demonstrates higher emotional accuracy in its zero-shot cloning capability. The emotional accuracy of all audio samples improves significantly after just one editing iteration. The effect of applying one iteration of emotion editing to zero-shot cloned audio outperforms the results produced by the closed-source models' native emotion control functionality.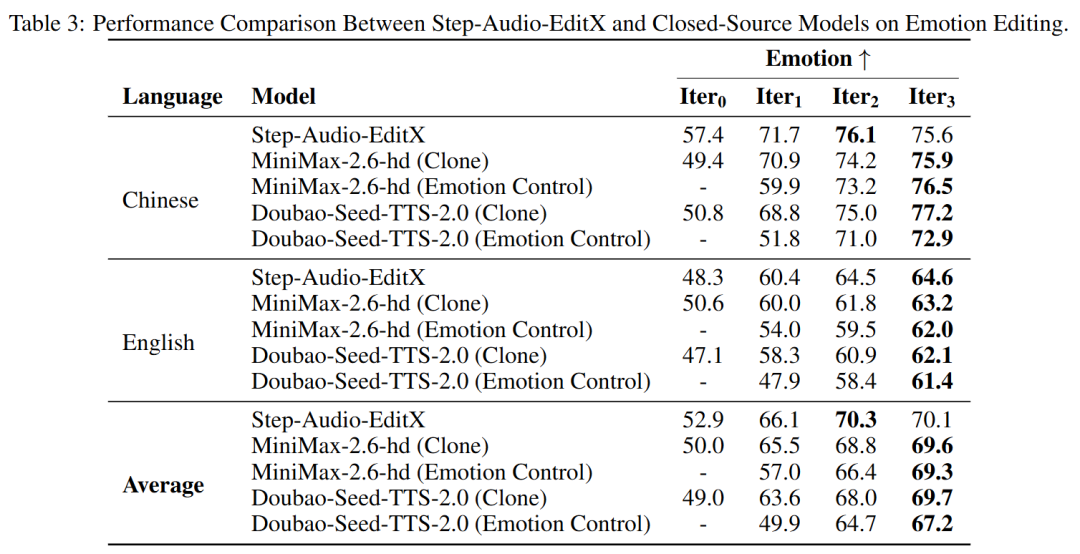 Paralinguistic Results
Paralinguistic Results
Paralinguistic editing can be considered a type of time-domain operation. The effects of a single editing iteration were evaluated using Step-Audio-EditX, and its generalization ability on other closed-source models was assessed.
Paralinguistic Editing Results. As shown in Table 4, significant performance improvements are achieved by adding paralinguistic labels in a single editing iteration.
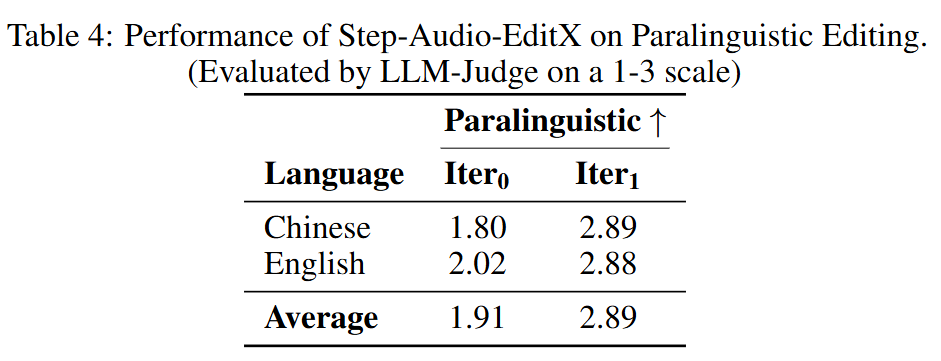
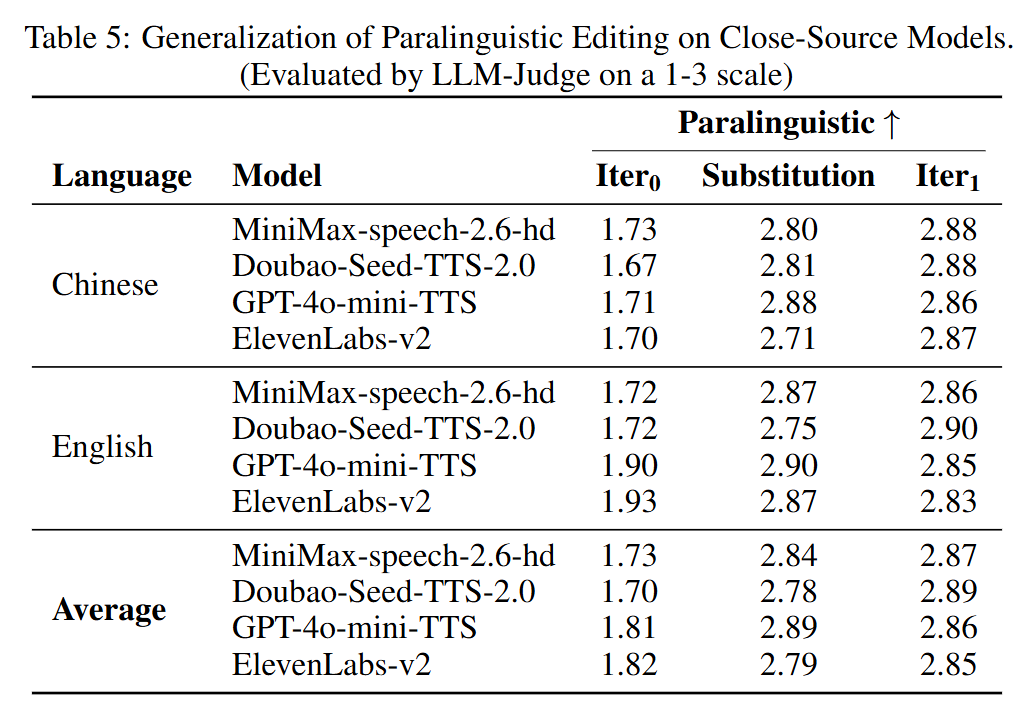
Generalization Ability on Closed-Source Models. The generalization evaluation was conducted identically to the aforementioned assessment. For each closed-source model, one female and one male built-in voice were used to synthesize speech from text with paralinguistic labels removed. A single editing iteration was then applied to the generated audio. Additionally, for comparison, extra audio samples were synthesized by replacing paralinguistic labels with onomatopoeic words (e.g., "[laughter]" → "haha"). After one iteration of paralinguistic editing using Step-Audio-EditX, the performance of paralinguistic reproduction reached a level comparable to that achieved by closed-source models when directly synthesizing native paralinguistic content.
The evaluation results across emotion, speaking style, and paralinguistic editing tasks confirm that our simple yet powerful approach—large-margin learning combined with reinforcement learning enhancement—provides high accuracy and robust generalization capability. This methodology demonstrates considerable promise for advancing research and enabling practical applications.
Extensions
This large-margin learning approach can be directly extended to various downstream applications. By enforcing a sufficiently large margin between paired data samples, the model can rapidly acquire target editing capabilities through SFT. Subsequently, reinforcement learning can be seamlessly integrated to further enhance performance in challenging scenarios. This section details two practical extensions: (1) speech speed editing for rate control and (2) denoising and silence trimming.
Speech Speed Editing (Speed Editing)
Speech speed editing addresses the need to adjust speech rates across different speakers and scenarios. This is achieved by constructing (text, source audio, accelerated/decelerated audio) triplets, where speed-modified versions for a given speaker are generated through controlled speed perturbation using the SoX-toolkit. Since speech rate variations directly result in significant differences in token sequence lengths, even SFT alone suffices to achieve effective speech speed editing.
Denoising and Silence Trimming (Denoising and Silence Trimming)
Background noise and silent segments in prompt audio can significantly impact the performance of zero-shot voice cloning. The model tends to interpret these acoustic features as part of the speaker's characteristics and subsequently reproduces them in the synthesized audio. While such mimicry may be desirable in certain use cases, it is not in others. To address this issue, we adopted a generative approach that integrates denoising and silence trimming functionalities, enabling targeted editing of both prompt and synthesized audio.
Denoising. Triplets for denoising are constructed as (text, noisy audio, source audio), where audio_source serves as the ground truth reference, and audio_augment is generated through additive noise and reverberation simulation.
Silence Trimming. Triplets are defined as (text, source audio, trimmed audio), where corresponds to the source audio containing silent segments, and refers to the processed version generated by extracting and concatenating speech segments according to timestamps produced by Silero-VAD.
Conclusion
Step-Audio-EditX is an audio model based on large language models, trained using large-margin data and enhanced through reinforcement learning. The model supports zero-shot TTS, iterative editing of emotions and speaking styles, and paralinguistic editing. This study finds that the capabilities of LLMs and the use of large-margin data—often overlooked in previous research—enable the model to overcome limitations in audio representation. Furthermore, the proposed framework can be easily extended to various tasks, including dialect editing, accent editing, voice editing, and imitation. Finally, it is important to note that our audio editing process is not strictly an "editing" operation in the traditional sense. Instead, it functions as a form of conditional regeneration or transfer. For tasks requiring partial modifications while preserving the rest unchanged, our method provides a straightforward and effective mask-based editing approach, ensuring that only specific portions of the edited tokens differ from the original sequence by reconstructing paired data.
References
[1] Step-Audio-EditX Technical Report
-
![]()
Enflame Tech's IPO Journey: Navigating Over 5.9 Billion Yuan in Losses and Soaring Debt in Q1 This Year
-
![]()
Trillion-Yuan Giant Li Shufu 'Streamlines': Could Levc Be the Casualty?
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'






