Under the wave of AI, the cost of building local large models is rapidly decreasing.
 06/14 2024
06/14 2024
 864
864

Hey, have you guys noticed that the technological trends in the past two years have been quite different from previous years?
Large AI models have become the hot favorite in the tech circle.
The increasing demand from users has driven the evolution of AI technology. With the growing number of application scenarios for large language models, they are starting to play an increasingly important role in our lives.
Especially in leisure and entertainment, as well as in practical work, the application of large language models is becoming more and more common. These models, with their natural semantic capabilities, powerful data processing abilities, and efficiency in executing complex tasks, provide users with unprecedented convenience, and even a sense of digital companionship that people never dared to imagine before.
However, with the rapid popularization of large language models, the limitations of cloud-based large models have gradually emerged.

Slow connection, high costs, and data privacy issues that have become hot topics of discussion cannot be easily ignored. Most importantly, cloud-based review systems based on various regulations and ethical considerations further restrict the freedom of large language models.
Local deployment seems to point us to a new path.
With the increasing demand for local large models, many related projects have emerged on Github and Huggingface this year. After much research, I have also followed the trail and obtained a simple method for locally deploying large models.
So, is local deployment a cherry on top or an epic enhancement to our AI experience?
Follow me, let's take a closer look.
What exactly is a local large model?
Before we start, let's talk a bit. Some readers may still not understand the meaning of "local large model" or why it's significant.
In a nutshell.
Currently popular large model applications, such as ChatGPT, Midjourney abroad, and domestic ones like Wenxin Yiyan, iFLYTEK, and KIWI, basically rely on cloud servers to provide various AI services.

(Image source: Wenxin Yiyan)
They can update data in real-time, integrate with search engines, without occupying local computer resources. All computation processes and loads are placed on remote servers, and users only need to enjoy the results.
In other words, with an internet connection, they are indeed impressive.
But once the internet connection is lost, these cloud-dependent AI services can only type "GG" on the keyboard.
In contrast, local large models focus on achieving AI intelligence locally on devices.
Not only does it not have to worry about issues caused by server crashes, but it is also more conducive to protecting user privacy.

After all, large models run on your own computer, and the training data is stored directly on the computer. It's definitely more reassuring than uploading it to the cloud and letting the server calculate it. It also saves on various ethical cloud-based audits.
However, currently, building a local large model on your own computer is not an easy task.
One reason is the high device requirements. After all, local large models need to place the entire computation process and load on your own computer, which will not only occupy your computer's resources but also make it run under medium to high loads for extended periods.
Secondly...
Looking at the plethora of projects on Github/Huggingface, achieving this goal basically requires programming experience. At the very least, you need to install many runtime libraries and execute some command lines and configurations in the console.
Don't laugh, it's not easy for the vast majority of internet users.
So is there any more "one-click" local application that can start a conversation simply by setting it up?
Yes, Koboldcpp.
With the right tools, even beginners can handle local large models.
Briefly, Koboldcpp is an inference framework based on the GGML/GGUF model. It shares the same underlying code as llama.cpp, both using pure C/C++ code without any additional dependencies and can even run directly on the CPU.

(Image source: PygmalionAI Wiki)
Of course, the speed of such operation will be very slow.
To use Koboldcpp, you need to go to Github to download the application version you need.
Of course, I will also provide the corresponding Baidu Disk link for your convenience.
Currently, Koboldcpp has three versions.
koboldcpp_cuda12: The most ideal version currently, as long as you have a graphics card above GTX 750, it can be used, and the model inference speed is the fastest.
koboldcpp_rocm: A version suitable for AMD graphics cards, based on the AMD ROCm open software stack. The inference time under the same specifications is about 3 to 5 times longer than the N card version.
koboldcpp_nocuda: A version that only uses the CPU for inference, with very streamlined functionality. Even so, the inference time under the same specifications is still more than 10 times longer than the N card version.
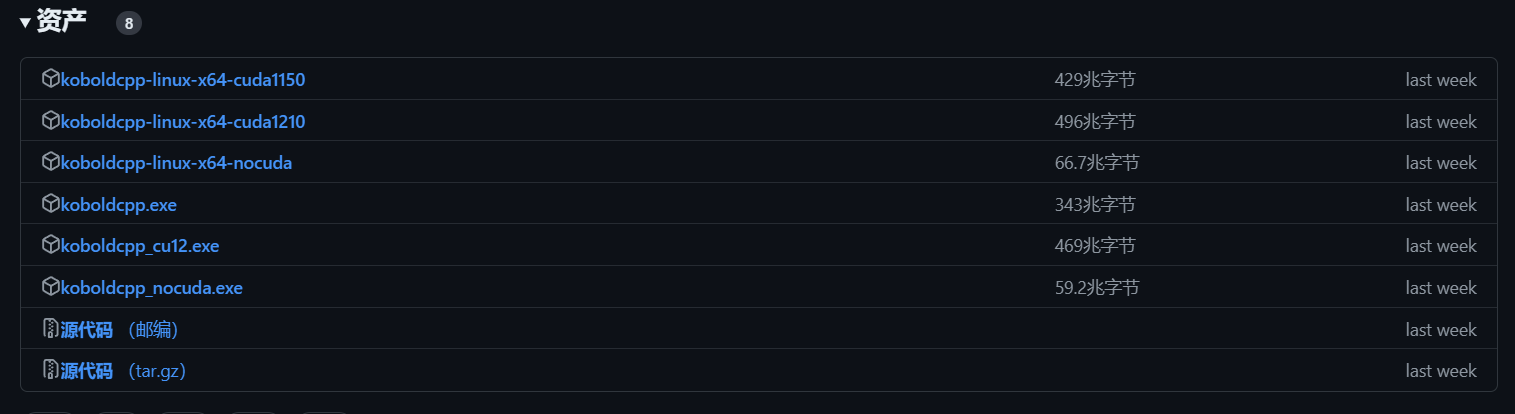
(Image source: Github)
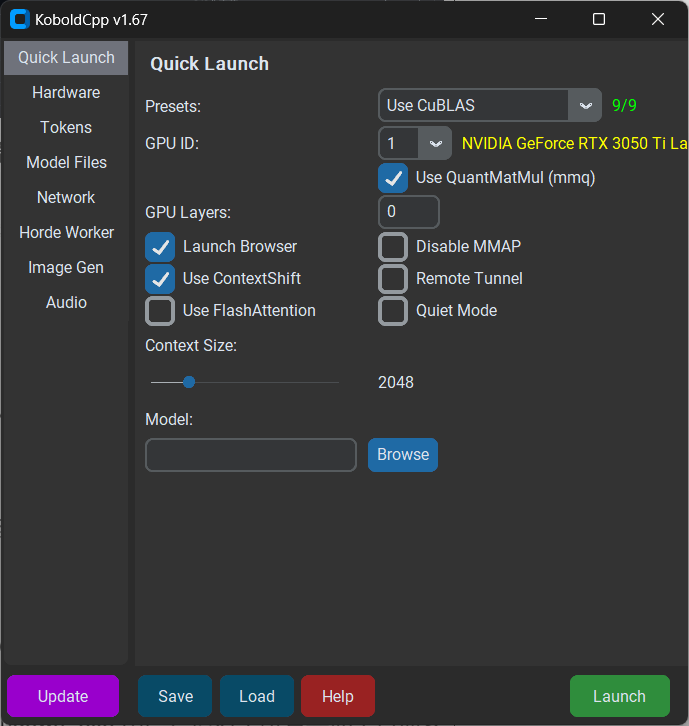
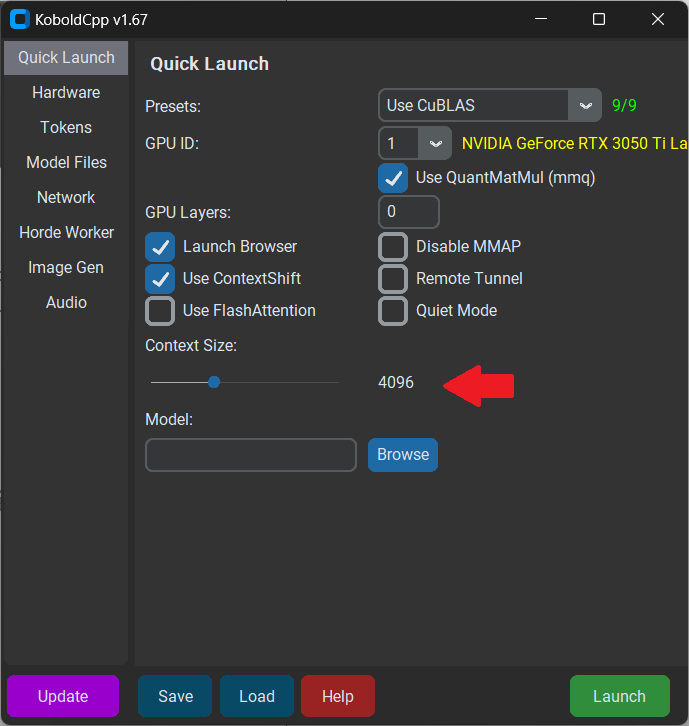
After opening the software, you can first take a look at the Presets options.
On the homepage of the software, Presets are divided into multiple different modes such as old N card, new N card, A card, Intel graphics card, etc.
By default, starting without setting any parameters will only use the CPU's OpenBLAS for fast processing and inference, and the running speed will definitely be slow.
As an N card user, I chose CuBLAS, which is only available for Nvidia GPUs. You can see that my laptop's graphics card has been recognized.
(Image source: Leitech)
For users without Intel graphics cards, you can use CLblast, an open-source computing library launched by OPENCL and suitable for production environments. Its biggest feature is more emphasis on versatility, but I have not conducted detailed performance tests.
Another section that needs to be adjusted on the homepage is Context Size.
To get a better contextual experience, it's best to adjust it to 4096. Of course, the larger the Size, the more context it can remember, but the inference speed will also be significantly affected.
(Image source: Leitech)
Moving down, it's time to load the large model.
Currently, open-source large models are mainly downloaded from huggingface.co. If you don't have access to overseas resources, you can also download them from domestic HF-Mirror mirror sites or the modelscope community.
Based on my personal experience, I recommend two good local large models:
CausalLM-7B
This is a local large model trained on Qwen's model weights based on LLaMA2. Its biggest feature is native support for Chinese. Users with graphics card memory below 8G are recommended to download CausalLM-7B, while those above 8G can download CausalLM-14B for better results.
(Image source: modelscope)
MythoMax-L2-13B
A large model with English as its native language, characterized by strong literary qualities. It can write fluent and readable novel texts upon request. The drawback is that it can only obtain ideal output content through English input. It is recommended for ordinary consumers to use MythoMax-L2-13B.
If you only want to use a large language model, no other adjustments are needed. Simply click Start, and the model you selected will be loaded locally.
Generally speaking, you will still need to deploy a frontend for the large model before you can use it.
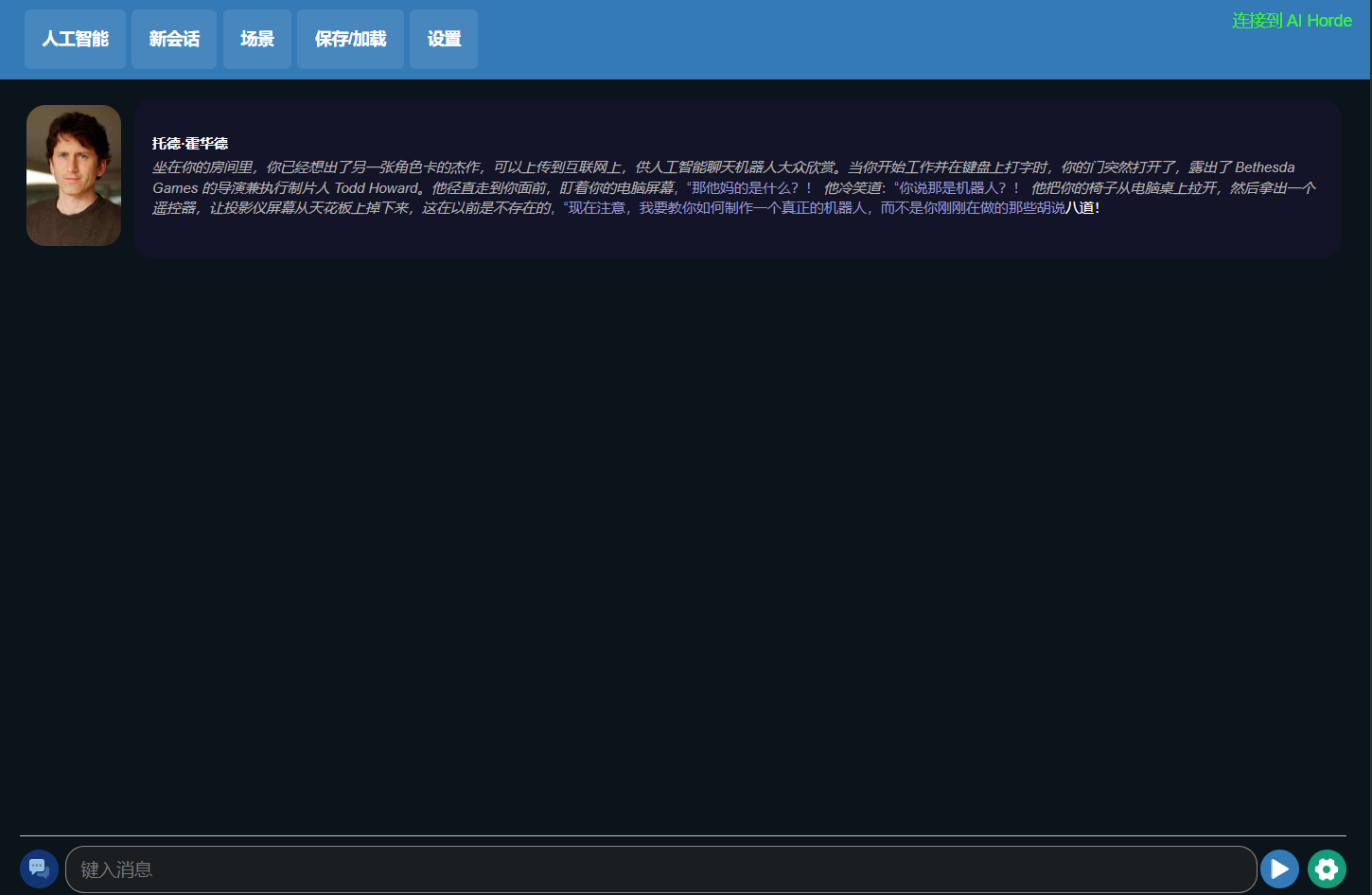
However, the biggest feature of Koboldcpp is that it adds a multifunctional Kobold API port based on llama.cpp.
This port not only provides additional format support, stable diffusion image generation, good backward compatibility, but also a simplified frontend called Kobold Lite with persistent stories, editing tools, save formats, memory, world information, author notes, characters, and scene customization capabilities.
Roughly, the interface looks like this.
(Image source: Leitech)
The functionality is also straightforward.
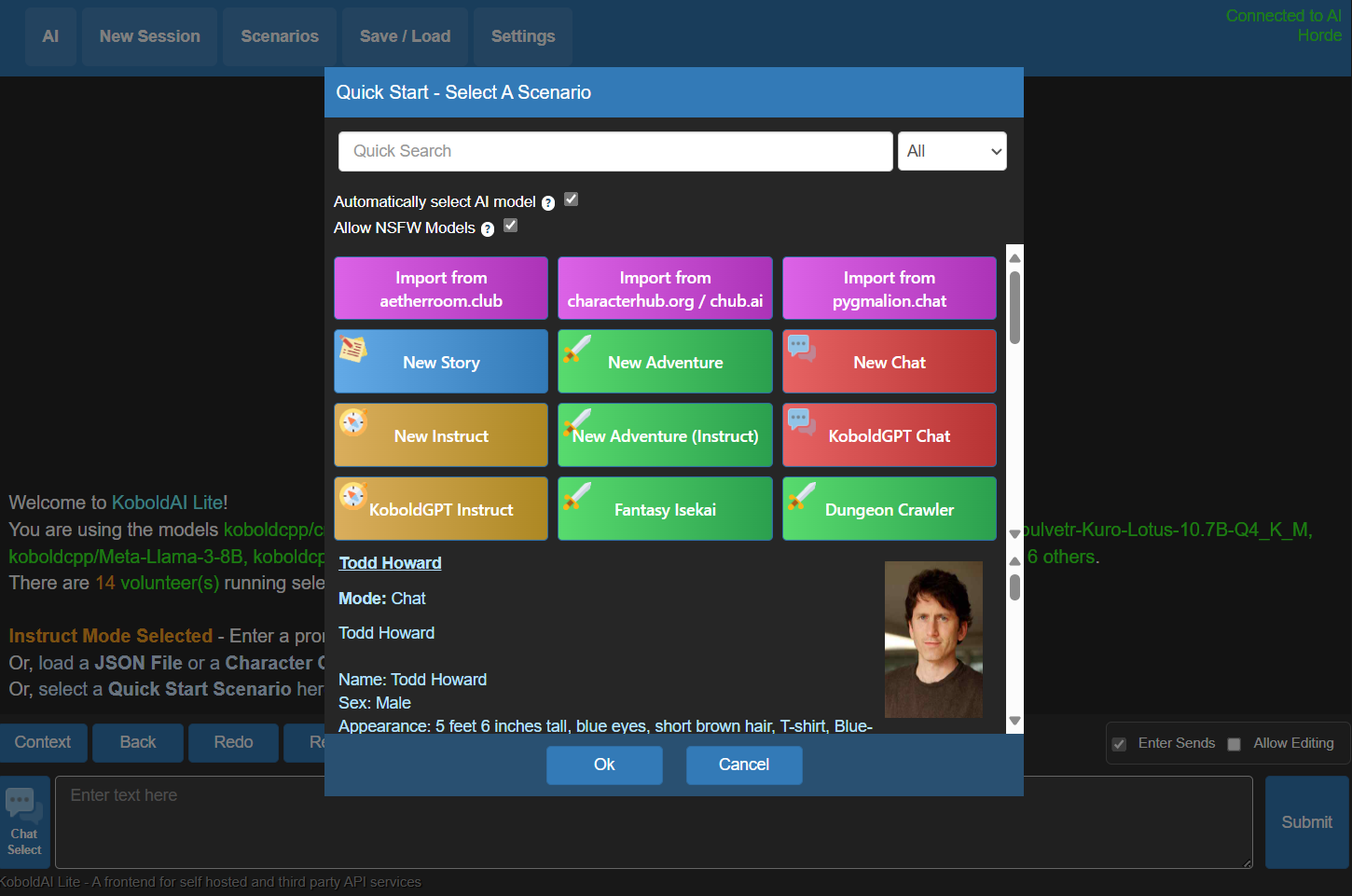
Artificial intelligence and new sessions go without saying. Clicking on "Scene" at the top allows you to quickly start a new conversation scenario or load the corresponding character cards.
(Image source: Leitech)
Like this, load the AI conversation scenarios you have.
"Save/Load" is also straightforward, allowing you to save your current conversation and load it at any time to continue.
In "Settings," you can adjust some AI conversation options.
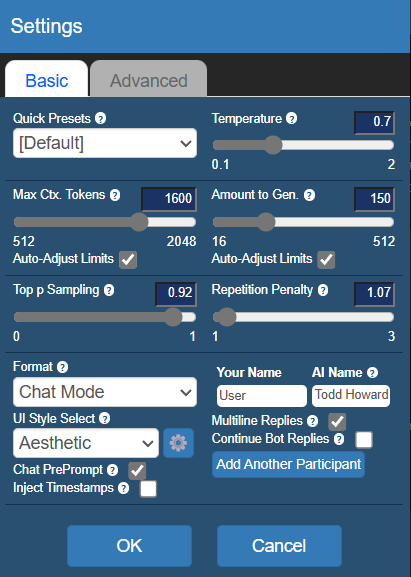
(Image source: Leitech)
Among them, Temperature represents the randomness of the conversation. The higher the value, the less controllable the generated conversation will be, and it may even exceed the character's set range.
Repetition Penalty can inhibit repetitive conversations and make the AI reduce repeated statements.
Amount to Gen. is the upper limit of the generated conversation length. The longer the limit, the longer it will take. The key point is that in actual experience, an excessively high generation limit will cause the AI to ramble, and I don't recommend setting this value above 240.
Max Ctx. Tokens is the upper limit of keywords that can be fed back to the large model. The higher the data, the closer the context relationship, and the slower the generation speed will be.
After completing the settings, you can engage in a smooth conversation with todd howard.
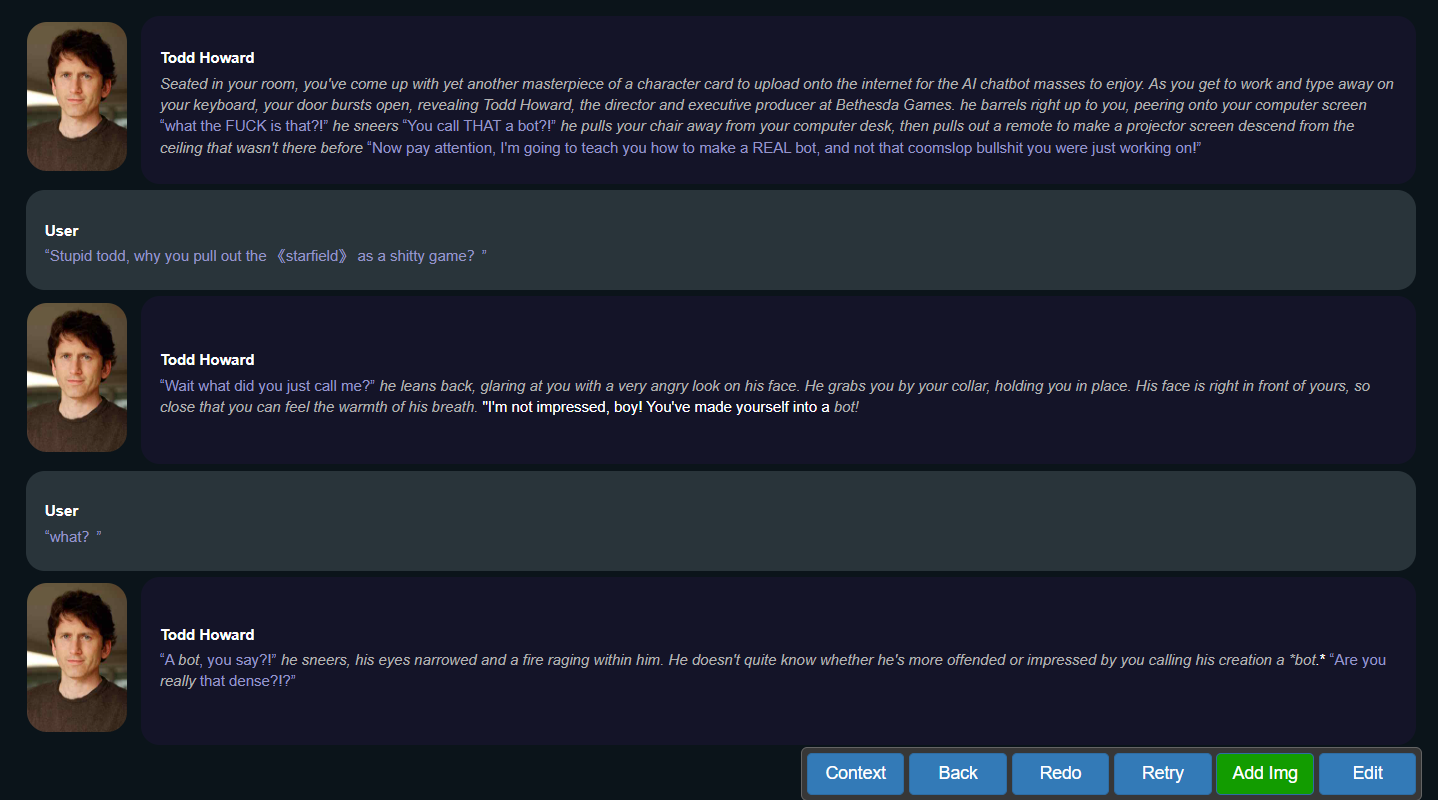
(Image source: Leitech)
Can't continue the conversation?
Clicking the chat tool in the lower left corner allows the large model to automatically generate responses based on your previous text to advance the conversation.

(Image source: Leitech)
Wrong answer, or the conversation is not going the way you want?
Clicking the chat tool in the lower right corner not only allows you to regenerate AI answers but also allows you to edit the replies yourself to ensure that the conversation stays on track.

Of course, besides conversations, Kobold Lite offers more possibilities.
You can connect it to AI voice and AI drawing ports, so that while having a conversation, you can automatically call AI language to dub the generated text or call AI drawing to illustrate the current conversation scene.
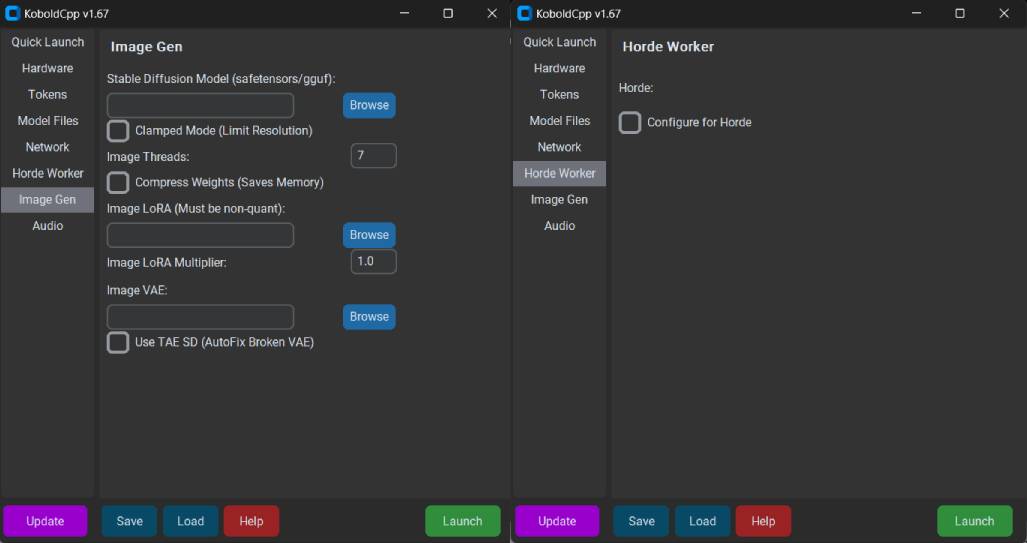
On top of that, you can even use the more advanced SillyTarven frontend to embed GIFs and HTML content into conversations.
Of course, these are for later.
Summary
Okay, the tutorial on deploying local large models ends here.
The software and large models mentioned in the article have all been uploaded to Baidu Disk. Interested readers can access them.
Based on my experience over the past six months, the current characteristic of local large models is "high playability".

As long as your configuration is sufficient, you can fully integrate large language models, AI voice, AI drawing, and 2D digital humans to build your own local digital human. Watching the vivid AI characters on the screen gives one a sense of déjà vu, reminiscent of "serial experiments lain".
However, such open-source large models usually have relatively lagging data, so there will be obvious deficiencies in professional knowledge. Most knowledge bases are only up to mid-2022, and there is no way to access external network resources. This poses significant limitations when assisting with office work or looking up information.
In my opinion, the ideal large language model experience should be a combination of local and cloud interactions.
That is, I can build my own knowledge base locally using my own large model, but when I need timely information, I can also leverage the power of the internet to obtain the latest news. This not only protects the privacy of personal data but also effectively solves the problem of information lag in open-source large models.
As for local character interactions, if you're interested...
Should I release the character cards from Leitech?
Source: Leitech
```-
![]()
Personnel Shuffle: Independent Director Mi Xuming Steps Down from OFILM
-
![]()
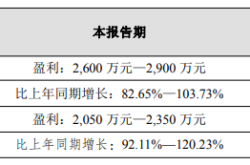
Net Profit Anticipated to Skyrocket by 103%: What Gives This Optical Company a Competitive Edge?
-
In Just One Year, China Unveils Unicorns Valued at 10 Trillion Yuan!
-
![]()
6 Park Companies Shine at WAIC: How Hong Kong Science Park Bridges AI from Research to Industry
-
![]()
Wang Wenjing’s Third Act: Can Yonyou Reinvent Itself in the AI Era?
-
![]()
Performance Coupe Entry Threshold Reduced to 170,000 Yuan: Assessing the 2027 Exeed ES's Prospects
-
![]()
Battery "Crisis" for 4 Million New Energy Commercial Vehicles
-
【Focus】Fluorinated Photosensitive Polyimide (FPSPI): A High-End Subdivision of PSPI with Great Potential in High-Tech Industries