Nvidia's Throne Unsteady: ASIC Emerges as a Serious Threat, Exposing Three Key Vulnerabilities
 07/09 2025
07/09 2025
 617
617
Even a powerhouse like Nvidia encounters numerous challenges.
A few days ago, Nvidia made history once again.
On July 3, Nvidia's market capitalization briefly reached $3.92 trillion, surpassing Apple's previous record of $3.915 trillion, making it the publicly traded company with the highest market valuation in history. The rapid advancement of AI computing power has propelled this GPU manufacturer to unprecedented heights.
Particularly since the end of 2024, the Blackwell platform, with significant improvements in both performance and energy efficiency, has dispelled external doubts. In the latest earnings call, Nvidia's founder and CEO Jensen Huang revealed that this new platform contributed nearly 70% of the company's data center revenue in the first quarter of 2025 alone.
However, just as Nvidia's market capitalization peaked and its aura intensified, cracks began to emerge within its ecosystem. A prime example is OpenAI, a significant Nvidia customer. Almost concurrently with Nvidia's market valuation peak, The Information quoted OpenAI insiders stating that the company is using Google's self-developed TPU chips to provide computing power support for ChatGPT and other products.

TPU server, image/Google
Although subsequent responses from OpenAI deliberately downplayed the "shift," emphasizing that it was merely a test and "there are no plans for large-scale adoption" at present, even a test by a company that has personally defined a new era of AI is enough to trigger high sensitivity in the market.
Simultaneously, this brought Google's seventh-generation TPU, Ironwood, released earlier, back into the spotlight. This dedicated AI chip tailored for inference scenarios not only targets Blackwell in terms of performance per watt but also exhibits strong attractiveness in terms of cost and deployment flexibility.
More importantly, what truly poses a structural challenge to Nvidia is the ASIC chip camp, which prioritizes "efficiency" over "versatility." Cloud giants like Google, Amazon, and Meta are continuously increasing their investment in self-developed accelerators to bypass the high costs of Nvidia GPUs. Meanwhile, startups like Cerebras and Graphcore are redefining "AI-specific computing" from the chip architecture and system design levels, attempting to build a technology path that is entirely different from GPUs.
For Nvidia, the throne of the world's number one is not stable.
As the saying goes, the one who knows a person best is often their rival.
On May 19, Nvidia released a new interconnection architecture, NVLink Fusion, defined as an "AI Engineering Collaboration Platform." By licensing NVLink chip-to-chip (C2C) interconnect and integrating switching modules, third-party vendors can connect their self-developed accelerators or CPUs to the computing power system dominated by Nvidia.
Compared to the closed design of NVLink in the past, Fusion's "semi-open" stance appears inclusive. However, in essence, it still requires partners to rely on Nvidia's ecological track. Any custom chip must be connected to Nvidia's products, and only the 900GB/s NVLink-C2C interface is selectively opened. Therefore, while NVLink Fusion seemingly demonstrates Nvidia's openness, it is more of a defensive move to counteract the UALink Alliance.

Image/UALink Alliance
In October 2024, the UALink Alliance, jointly initiated by AMD, Intel, Google, Meta, Microsoft, AWS, and others, quietly took shape. Subsequently, Apple, Alibaba Cloud, Synopsys, and others joined, rapidly expanding into a vast camp encompassing chip design, cloud services, and IP supply chains.
In April of this year, UALink released the 1.0 version of its interconnection standard, supporting up to 1024 accelerator nodes, 800Gbps bandwidth interconnection, and an open memory-semantics protocol. This is not merely a communication technology but a systematic layout aimed at "de-Nvidiaizing." In the matter of AI chip interconnection architectures, Nvidia perhaps understands better than anyone that what truly deserves vigilance is not a single vendor but an entire ASIC camp that is beginning to break free from GPU dependence and attempting to rebuild the hardware order.
Unlike versatile GPU architectures, ASICs are chips customized for specific tasks, which in the AI era means they can be optimized to the extreme for core computing paths such as inference, training, and streaming. This concept is now deeply rooted within giants such as Microsoft, Meta, and Amazon, all of which are exploring the migration from Nvidia GPU platforms to self-developed AI ASIC chips.
Google is a prime example. The TPU series has evolved to the seventh-generation Ironwood since its launch, designed specifically for inference tasks, with performance per watt directly surpassing Nvidia's Blackwell. OpenAI researchers on the X platform even believe that Ironwood is comparable to, or even slightly superior to, GB200 in performance. More importantly, the TPU series has already supported the large-scale application of the Gemini large model from training to inference.

Image/Google
Simultaneously, in addition to long-time rival AMD, new chip vendors such as Meta and AWS are also trying to "catch up" with Nvidia GPUs. Based on its collaboration with Broadcom, Meta's first AI ASIC chip, MTIA T-V1, has been reported to have specifications that may exceed Nvidia's next-generation Rubin chip. AWS, building on its collaboration with Marvell, has initiated the development of different versions of Trainium v3, with mass production expected to begin in 2026.
According to a recent report by Nomura Securities, Google's TPU shipments are estimated to be between 1.5 million and 2 million in 2025, and AWS's Trainium and Inferentia shipments are estimated to be between 1.4 million and 1.5 million. When Meta and Microsoft begin large-scale deployments, it is expected that shipments will surpass Nvidia GPUs (5 million to 6 million) for the first time in 2026.
In terms of startups, Cerebras, the AI chip "unicorn" that developed the world's largest chip, is leading the innovation of training chip architectures with its WaferScale Engine (WSE), which has been implemented in multiple government and scientific supercomputing projects. Graphcore, acquired by SoftBank, has experienced setbacks but continues to seek breakthroughs in its neural network processing architecture (IPU). Tenstorrent, Rebellions, and other newcomers are continuously accumulating customers and shipments in niche areas such as AI inference and edge computing.
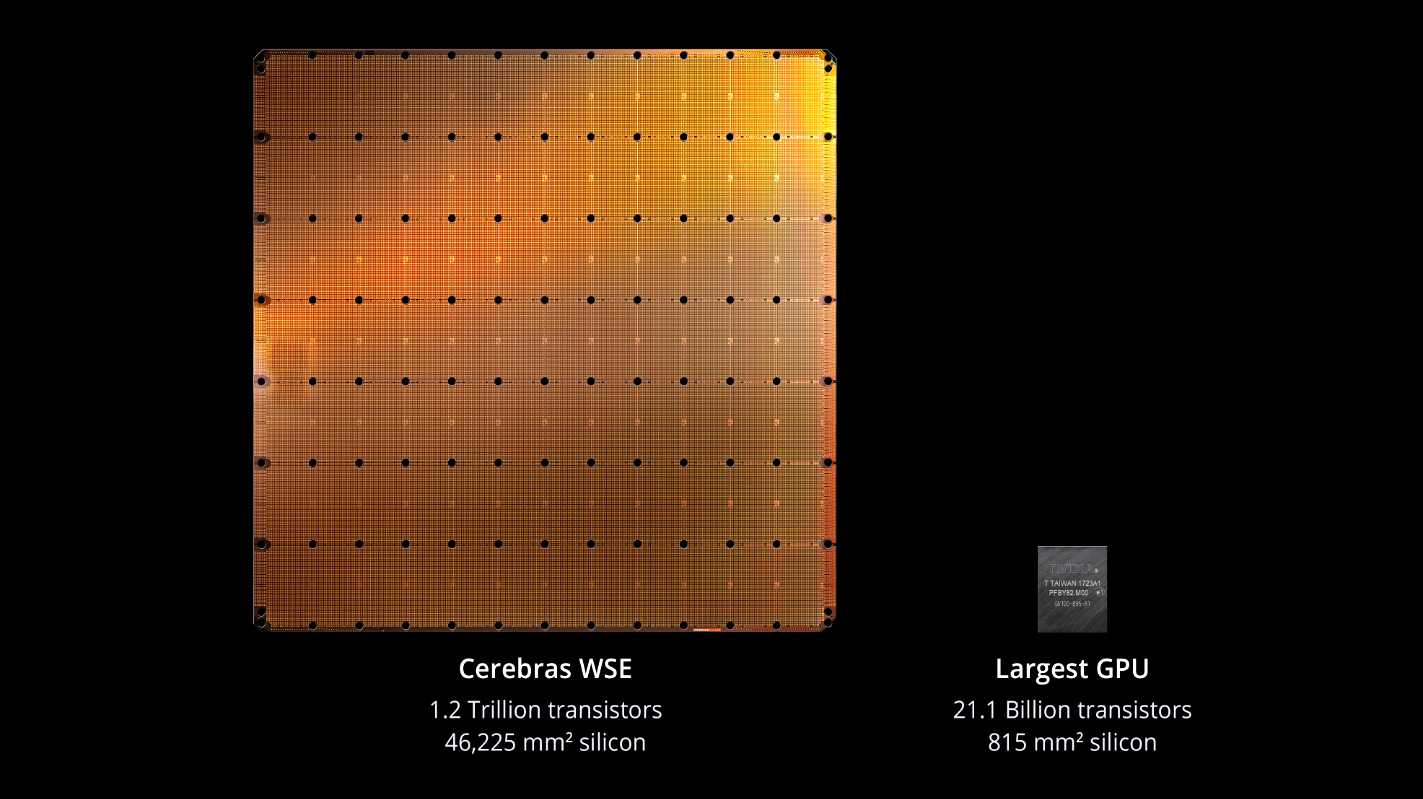
The world's largest chip, image/Cerebras
Nvidia, of course, understands this undercurrent, which is why it chose to respond with NVLink Fusion. But the reality is that more and more players are no longer satisfied with playing a supporting role. The rise of ASICs is not just an iteration of technical routes but a systemic challenge led by giants, driven by alliances, and endorsed by ecosystems. While Nvidia is certainly powerful, it remains vigilant in the face of such opponents.
The moment its market capitalization surged to $3.92 trillion, Nvidia stood at the pinnacle of the global capital market. But beneath this dazzling height, more and more problems are beginning to surface. From industrial dependence to product structure and ecological strategy, Nvidia still faces the possibility of being backlashed by the success logic it has created itself.
The first vulnerability is the concentrated dependence on ultra-large-scale customers. Currently, approximately 88% of Nvidia's revenue comes from its data center business, with the majority concentrated in the hands of a handful of cloud computing giants: Microsoft, AWS, Alibaba, Meta, Google, and the increasingly ambitious OpenAI. These customers are not only developing their own AI chips but have also formed the UALink Alliance, weakening the dominance of Nvidia GPUs with their own hands.
Google has TPU, Amazon has Trainium, Meta and Microsoft have launched the MTIA and Maia series accelerators, respectively. While OpenAI is testing Google's TPU, news of its self-developed AI chips continues to emerge. These customers do not need Nvidia, but they do not want to rely "only" on Nvidia.
The second vulnerability lies in cost-effectiveness. The Blackwell platform has brought almost overwhelming improvements in computing power, especially the leap in training and inference performance of the GB200 architecture. However, at the same time, the complexity, power consumption, and cost of this generation of products have also increased significantly. According to HSBC, the price of a GB200 NVL72 server is as high as approximately $3 million, deterring many customers.

GB200 NVL72, image/Nvidia
This extreme design strategy has indeed locked in the high-end market but also brought two side effects: one is excluding small and medium-sized customers, and the other is pushing customers to seek cheaper and more energy-efficient alternatives. When AI inference becomes the mainstream task, cost-effectiveness is often more important than absolute performance, and this is precisely the area where ASIC and other specialized chips excel.
Furthermore, for large customers such as cloud vendors, they were willing to pay for performance in the early stages. However, as deployment scales expand, models standardize, and budgets tighten, even large vendors increasingly hope to have more autonomy and negotiation space. When Nvidia becomes a "must-have," it means that the industry chain has already begun to explore options for "whether it is possible not to use it," and the success of Google's TPU is even more of an incentive.
The third vulnerability lies in Nvidia's ecological barriers. Nvidia CUDA is currently the most powerful AI programming ecosystem in the industry, but its high degree of closure has gradually turned it into a world "belonging to Nvidia." Against the backdrop of the rise of open ecosystems such as the UALink Alliance, OneAPI, MLIR, and others, more and more developers and system designers are beginning to pursue cross-platform compatibility and heterogeneous collaboration rather than tying their fate to a company's toolchain.
CUDA was once Nvidia's moat, but it has now become, to a certain extent, an "ecological wall" that restricts the free flow of developers. As more vendors expect to switch flexibly between different architectures, the barriers of CUDA may also become a reason for them to turn away.
Looking back, while Nvidia is still the strongest AI chip vendor today, standing at the pinnacle of technology, products, and market valuation, the peak is never the end; it is only the starting point for more challenges. More crucially, what Nvidia faces is not the risk of a single technology replacement but a decentralization led by customers. As mentioned earlier: Nvidia's world number one position is not stable.
Nvidia Google OpenAI
Source: Lei Technology
Images in this article are from: 123RF Licensed Image Library Source: Lei Technology
-
![]()
Internet Valuation Logic Shifts: From Scale Narrative to Profit Accountability
-
VOYAH Struggles to Find Its Niche in the Competitive Auto Market
-
![]()
Maxwell Technologies Gains Indirect Stake in Precision Optics via New Venture
-
![]()
Raising 1.8 Billion! This Domestic Optical Inspection 'Little Giant' is Going Public
-
China's AI 'Normandy Moment': The Explicit and Implicit Threads of BATL
-
![]()
Starting at 4999 Yuan! Nubia RedMagic Gaming Tablet 5 Pro Review: Impressive Performance, But Hefty Price Tag
-
![]()
ByteDance Initiates First Major Management Reform
-
![]()
AI is Quietly Destroying a Trillion-Dollar Industry