What’s the Convolutional Neural Network Often Referenced in Autonomous Driving?
 11/17 2025
11/17 2025
 615
615
In the realm of autonomous driving, Convolutional Neural Networks (CNNs) are a frequently discussed technology. CNN, an acronym for Convolutional Neural Network, is a deep learning model tailored for processing grid-like data, such as images. Given that images can be perceived as two-dimensional grids made up of pixels, CNNs are particularly prevalent in image processing.
A Convolutional Neural Network can be succinctly described as a technology that “begins locally and gradually abstracts.” Through a series of learnable operations, the network can autonomously detect fundamental features like edges, corners, and textures from raw pixel data. These features are then progressively integrated into higher-level semantic information, ultimately enabling perceptual tasks such as “recognizing a cat.”
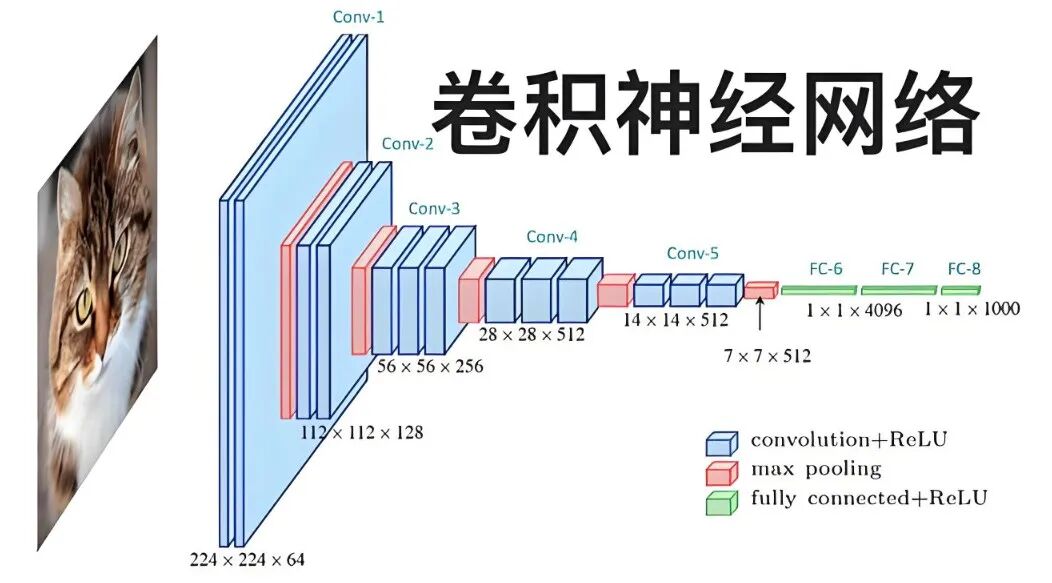
Image Source: Internet
Compared to traditional fully connected networks, CNNs boast not only fewer parameters but also enhanced adaptability to translational variations of objects within images. Consequently, they exhibit superior performance in terms of computational efficiency and generalization capabilities.
Core Components and Working Principles
To gain a clear understanding of CNNs, it is crucial to grasp two key concepts: “convolutional kernel sliding” and “hierarchical abstraction.” Convolutional operations entail sliding a small window across the image pixel by pixel. Each time, the pixel values within the window are multiplied pointwise with a set of trainable weights (referred to as the convolutional kernel or filter) and then summed to yield a single value in the output feature map.
The objective of this training process is to fine-tune the parameters of these convolutional kernels so that they can extract meaningful features. Since the convolutional kernels are significantly smaller than the entire image and share parameters across the image, this design, which incorporates “local connections” and “parameter sharing,” substantially reduces the number of network parameters.
A convolutional layer is typically followed by a nonlinear activation function, such as ReLU, which sets negative values to zero, thereby introducing nonlinearity and enabling the network to model more complex relationships. Subsequently, downsampling operations like max pooling are performed, which select the maximum value within a local region for output. This not only reduces data dimensionality and compresses information but also enhances the network’s robustness to translations.
Through the stacking of multiple convolutional and pooling layers, the network incrementally combines low-level feature information (such as edges and textures) into mid-level feature information (such as corners and local shapes) and further abstracts it into high-level feature information (such as object parts or semantic concepts). At the network’s conclusion, these features are “flattened” and fed into fully connected layers or processed through global pooling. Finally, a classifier (such as softmax) outputs the probabilities for each category.

Image Source: Internet
Convolution is not confined to two-dimensional images; it can be extended to one-dimensional data (such as speech and time series) and three-dimensional data (such as volumetric data in medical imaging). For multi-channel inputs (e.g., the RGB channels of a color image), the convolutional kernel is equipped with a set of weights for each channel. The calculations are performed independently for each channel and then summed to generate a single-channel feature map. To extract diverse types of features, multiple convolutional kernels can be employed simultaneously to produce multiple feature maps (also known as output channels).
Training, Optimization, and Common Techniques
The fundamental training process for CNNs is akin to that of other neural networks. It involves defining a loss function (e.g., cross-entropy loss for classification tasks), computing gradients through backpropagation, and updating network parameters using optimizers (such as Stochastic Gradient Descent (SGD) or Adam). In convolutional layers, backpropagation essentially entails differentiating the convolutional operation to calculate and update the gradients of the convolutional kernels and input data.
During the training of Convolutional Neural Networks, the selection of hyperparameters, including learning rate, batch size, and weight initialization, is of paramount importance, as they collectively influence the stability of the training process and the ultimate performance of the model. To mitigate overfitting and enhance the model’s generalization capabilities, several practical techniques can be employed.
Data augmentation is a highly effective strategy. By randomly flipping, cropping, rotating, or adjusting the brightness and contrast of training images, the diversity of the data can be significantly augmented. This compels the model to learn more robust features rather than merely memorizing specific samples from the training set.
Regularization techniques, such as weight decay (L2 regularization) and Dropout (randomly deactivating some neurons), are also efficacious. However, Dropout is typically utilized less frequently in convolutional layers compared to fully connected layers. Batch normalization has now become a standard feature in training deep networks. By normalizing each batch of data, it effectively stabilizes the training process, accelerates convergence, and enables the use of larger learning rates. Additionally, strategies for dynamically adjusting the learning rate during training and the “early stopping” method, which terminates training based on validation set performance, are commonly employed to prevent overfitting.
Beyond the aforementioned training techniques, enhancements at the model architecture level can also profoundly impact training outcomes. The introduction of residual connections is a pivotal breakthrough. By permitting information to flow directly across layers, it effectively alleviates the vanishing gradient problem in deep networks, making it feasible to train ultra-deep networks with hundreds of layers.
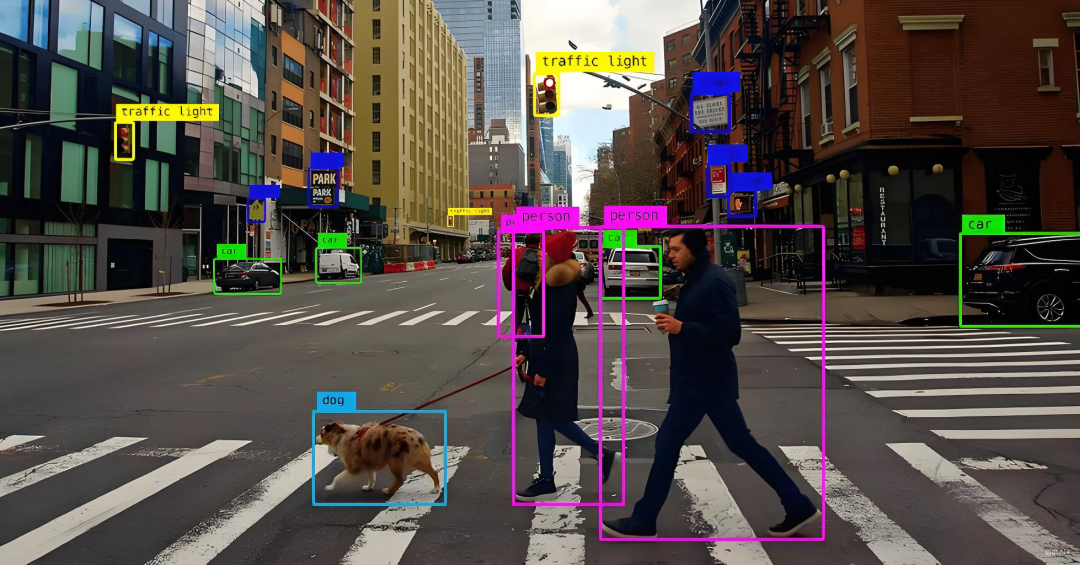
Image Source: Internet
Depthwise separable convolutions prioritize computational efficiency by decomposing standard convolutional operations into two steps: channel-wise convolution and point-wise convolution. This substantially reduces the computational cost and the number of parameters, rendering it particularly crucial for deploying models on mobile devices like smartphones. In practical engineering deployments, techniques such as model compression and quantization are further utilized to optimize trained networks, ensuring their efficient operation in resource-constrained environments.
Key Architectural Evolution and Design Choices
Reviewing the developmental history of Convolutional Neural Networks provides a clear insight into the evolution of their design philosophies. The early LeNet successfully applied convolutional concepts to handwritten digit recognition, validating their effectiveness. Subsequently, AlexNet achieved groundbreaking results in large-scale image classification competitions, significantly propelling the popularity of deep learning. The VGG network underscored the significance of depth by repeatedly stacking small 3x3 convolutional kernels to construct a structurally regular and deep network. The Inception series adopted a different approach by incorporating parallel structures to capture features at varying scales simultaneously. The introduction of residual connections in ResNet fundamentally addressed the training challenges of deep networks. In recent years, to strike a balance between accuracy and efficiency, lightweight architectures such as MobileNet (which utilizes depthwise separable convolutions) and EfficientNet (which employs compound scaling of model depth, width, and resolution) have emerged.
Convolutional Neural Networks have found extensive applications in the field of computer vision, spanning from basic image classification to object detection, semantic segmentation, face recognition, pose estimation, and even image generation and retrieval.
Of course, CNNs also have their limitations. They are inherently less adept than Transformer models, which are based on self-attention mechanisms, at capturing long-range dependencies and global relationships in images. Although the receptive field can be expanded by deepening the network or utilizing large convolutional kernels, this comes at the cost of a significant increase in computational expense. Additionally, their celebrated translational invariance necessitates additional mechanisms to assist in tasks that demand precise localization, such as instance segmentation.

Final Remarks
Through the core philosophy of “local perception, parameter sharing, and hierarchical abstraction,” Convolutional Neural Networks provide a robust and efficient framework for processing grid-like data such as images. The advantages of CNNs stem from their inherently rational structure. By adopting a “start small” approach and employing local connections and weight sharing, they extract features layer by layer from images, progressively integrating simple edges and textures into complex object parts and overall concepts. This design not only substantially reduces the number of parameters to be computed but also renders CNNs naturally proficient at processing image data. Consequently, CNNs offer exceptional recognition capabilities while maintaining high computational efficiency, serving as a steadfast technological foundation in the field of computer vision.
-- END --
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






