Farewell to Textual Imagination! Kuaishou Kling Team Open-Sources VANS: Bridging the Gap from 'Language Description' to 'Dynamic Demonstration' with Multiple SOTA Achievements
 11/24 2025
11/24 2025
 463
463
Interpretation: AI Generates the Future


Highlights
Pioneering the VNEP Paradigm: Advancing next-generation event reasoning from textual descriptions to dynamic video demonstrations.
Introducing the VANS Framework and Core Joint-GRPO Strategy: Synergistically optimizing visual language models (VLMs) and video diffusion models (VDMs) through reinforcement learning and joint reward mechanisms, generating videos that are both semantically accurate and visually coherent.
Constructing the VANS-Data-100K Dataset: Comprising 100,000 triplets of (input video, question, output video), providing specialized data support for model training and evaluation in VNEP tasks.
Summary at a Glance
Problems Addressed
Modal Limitations: Next-generation event prediction tasks have long relied on textual descriptions as answers, unable to leverage the intuitive advantages of video 'demonstrations' to convey complex physical world information.
Task Challenges: Video-based next-generation event prediction requires models to simultaneously possess multimodal input understanding, instruction-conditioned reasoning, and the ability to generate visually and semantically consistent videos, posing significant challenges to existing models.
Coordination Difficulties: Effectively coordinating VLMs to generate descriptions that are both accurate and easily visualizable, while ensuring VDMs produce videos that are faithful to the descriptions and aligned with the input visual context, remains a challenge.
Proposed Solutions
New Task Paradigm: Pioneering video-based next-generation event prediction, upgrading the answer modality from text to dynamic video.
Core Framework: Introducing the VANS model, integrating VLMs and VDMs through reinforcement learning.
Key Algorithm: Designing Joint Group Relative Policy Optimization (Joint-GRPO) as the core training strategy for VANS, synergistically optimizing both models via joint rewards.
Data Support: Constructing the VANS-Data-100K dedicated dataset to support model training and evaluation.
Technologies Applied
Visual Language Model (VLM): Used to understand multimodal inputs (videos and questions) and generate intermediate descriptions.
Video Diffusion Model (VDM): Used to generate videos based on the VLM's descriptions and input visual context.
Reinforcement Learning: Particularly the Joint-GRPO algorithm, used to align and synergistically optimize VLMs and VDMs.
Shared Reward Mechanism: Driving the Joint-GRPO process to ensure both models work towards a common goal (generating high-quality video answers).
Achieved Results
Breakthrough Performance: VANS achieves state-of-the-art performance in both video event prediction and visualization on procedural and predictive benchmarks.
High-Quality Outputs: Generated video answers exhibit semantic fidelity (accurately reflecting predicted events) and visual coherence (consistent with input context).
Effective Synergy: Through Joint-GRPO, VLMs successfully generate 'visualization-friendly' descriptions, guiding VDMs to produce videos that 'align with descriptions and context'. VANS-Data-100K
Existing NEP datasets are unsuitable for VNEP tasks due to poor video quality and lack of diverse instructional questions. To address this gap, we constructed the VANS-Data-100K dataset, comprising 30,000 procedural and 70,000 predictive samples. Each sample includes an input video, question, and multimodal answer (text and video), specifically tailored for VNEP tasks. As shown in Figure 3 below, our data construction process involves four stages.

Raw Data Collection: Data was gathered from two distinct sources to cover procedural and predictive scenarios. Procedural data utilized high-definition videos from COIN and YouCook2 to ensure clear step demonstrations. Predictive data was sourced from general scene datasets and short films, rich in narrative and causal dynamics.
Shot Segmentation: Raw videos were segmented into coherent clips. Procedural videos were split using real timestamps, while predictive videos employed shot boundary detection models. Clips shorter than 3 seconds were filtered out to ensure action completeness.
Clip Selection: Gemini-2.5-Flash served as an automatic quality filter to select optimal 3-5 second clips. For procedural data, clips best matching given captions were chosen. For predictive data, detailed captions were generated for each clip, ensuring selected clips were both high-quality and semantically representative.
Question-Answer Pair Generation: Gemini-2.5-Flash generated question-answer pairs based on video-caption sequences. The VLM simulated diverse questions—focusing on logical next steps for procedural tasks and hypothetical scenarios for predictive tasks—while generating chain-of-thought reasoning and ground-truth answers. A self-checking mechanism ensured logical rigor and prevented information leakage. More dataset details are provided in Appendix A.
VANS
Figure 4 below illustrates the overall architecture of VANS. The input question is tokenized and fed into the VLM along with high-level ViT visual features extracted from the input video. The VLM performs instruction-based reasoning to generate textual captions describing the predicted next event, serving as semantic guidance for the VDM. To ensure visual consistency, the VDM conditions on both the generated captions and low-level visual cues—extracted by tokenizing n sampled input frames via a VAE and concatenating these tokens into the VDM's conditional latent space. This design maintains fine-grained visual correspondences when generating new scenes.
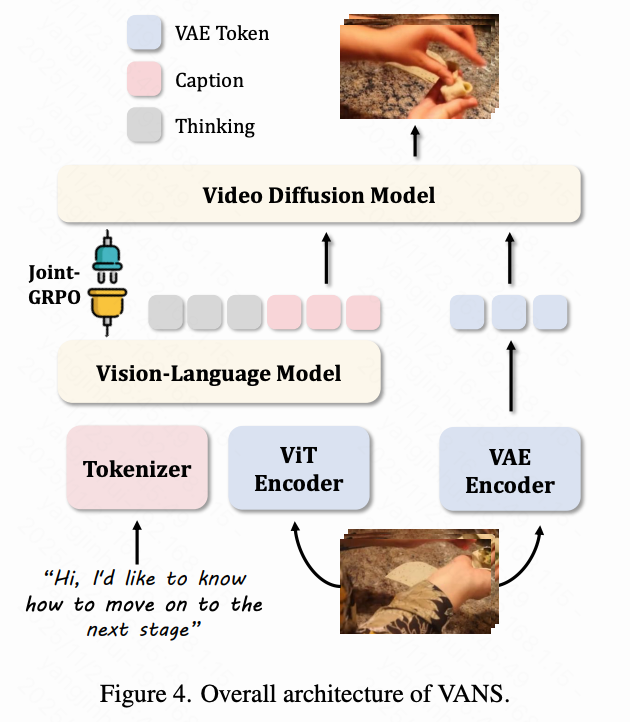
Fundamental Limitation: The VLM and VDM are optimized independently. The VLM is trained for textual accuracy without feedback on whether its descriptions yield visually plausible videos. Conversely, the VDM must reconcile two conditional signals (the VLM's specific captions and input visual context). While supervised fine-tuning (SFT) equips the VDM with foundational capabilities, achieving consistent semantic accuracy and visual fidelity requires further optimization. This separation creates a semantic-visual gap, with both models operating without awareness of each other's constraints and capabilities. To address this, we propose Joint-GRPO to harmonize the two models into a cohesive VNEP system.
GRPO Foundations
GRPO is a reinforcement learning (RL) algorithm designed to align model outputs with human preferences or complex objectives. Its core idea is to evaluate generated sample quality via a reward function and adjust the model's policy to increase the probability of high-reward generations. For each input context, the policy model generates a set of trajectories, each receiving a reward reflecting its quality. GRPO computes normalized advantages to measure each trajectory's performance relative to the group average:
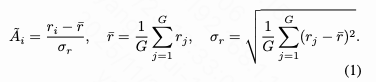
The policy model is then optimized using the following GRPO objective function:
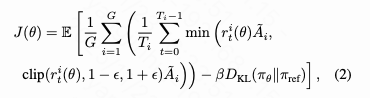
where denotes the probability ratio for the -th trajectory. A clipping mechanism and KL divergence term ensure training stability by preventing drastic policy updates.
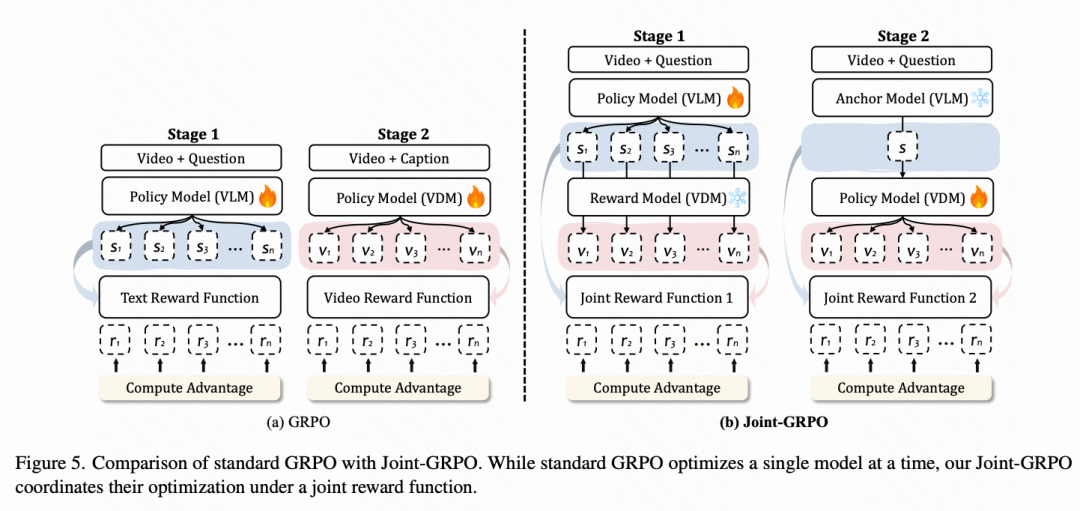
Joint-GRPO
While standard GRPO effectively aligns single models, it faces fundamental limitations in multi-model scenarios like VNEP, where models are optimized in isolation. Applying GRPO separately to the VLM and VDM fails to bridge the semantic-visual gap, as it does not incentivize mutually reinforcing outputs. Conversely, single-stage joint training of both models introduces attribution problems: when generated videos are of poor quality, it becomes difficult to determine whether the issue stems from the VLM's captions or the VDM's generation process. This can lead to reward hacking and training instability, generating conflicting gradient signals.
To resolve this attribution problem and achieve effective synergistic guidance, we propose Joint-GRPO. This method coordinates the VLM and VDM through a structured two-stage optimization process using a joint reward function. Our key insight is that both models must be guided collaboratively: the VLM's reasoning must be visually grounded to effectively direct the VDM, while the VDM's generation must remain faithful to the VLM's predictions and the visual context.
Stage 1: Visualization-Friendly VLM Tuning. We first align the VLM's reasoning with the VDM's generation results by optimizing the VLM's policy while keeping the VDM frozen. For an input video and question, we sample K textual captions, each generating a corresponding video via the frozen VDM. The VLM's joint reward is computed as:
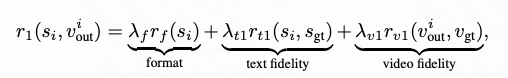
where , , and are weight coefficients for each reward term, defined as follows:
ensures output adherence to the specified instruction format: 1 point if the response follows a 'reasoning-first, answering-second' template; 0 otherwise. measures semantic similarity between generated and ground-truth captions using ROUGE-L. evaluates visual coherence between generated and ground-truth videos using CLIP similarity.
This composite reward guides the VLM beyond mere linguistic correctness. Relying solely on may produce linguistically correct but visually unrealistic captions that the VDM cannot execute. Conversely, using only provides indirect and ambiguous feedback, failing to effectively direct the VLM's reasoning. The joint reward encourages the VLM to generate captions that are not only semantically accurate but also visually plausible and executable by the VDM, internalizing the VDM's capabilities and constraints.
Stage 2: Context-Faithful VDM Adaptation. Building on the visually grounded captions obtained in Stage 1, we optimize the VDM's policy to faithfully render these captions while maintaining consistency with the input visual context, addressing cross-modal alignment challenges. We use the frozen VLM from Stage 1 as an anchoring model. As shown in Figure 5 below, the 'currently improved' VLM generates candidate anchoring captions (samples with excessively low semantic similarity to ground-truth are discarded and regenerated to ensure quality). The resulting visually grounded captions serve as conditional inputs for the VDM.
We then sample M output videos. The VDM's core task is to generate compliant new scenes by dynamically attending to and preserving relevant visual elements (e.g., identity IDs, backgrounds) from the input video's VAE tokens under semantic content guidance. Its reward function is defined as:
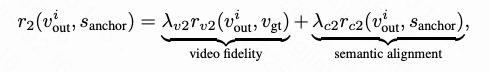
where and are balancing coefficients, defined as:
maintains visual quality and coherence with the input video, using the same metrics as Stage 1. measures semantic alignment between the output video and anchoring caption using CLIPScore.
This joint reward design addresses core cross-modal alignment challenges: ensuring output visual plausibility and continuity; and enforcing strict adherence to described events, preventing the VDM from ignoring captions and merely reconstructing or slightly modifying the input video.
Through these two optimization stages, the VLM and VDM co-evolve into a synergistic organic whole. The unique complementary roles of each reward component and training reward curves are detailed in Appendix B.
Experiments
We evaluate VANS's effectiveness through experiments and compare it with cutting-edge solutions.
Experimental Setup
Benchmarks. We sampled 400 procedural and 400 predictive samples from our dataset to construct evaluation benchmarks, with source videos derived from established benchmark datasets like [2,8,51,54] to ensure reliable ground-truth text and video answers. The evaluation set was strictly separated from training data, with no overlapping videos or questions.
Evaluation Metrics. Following [16], we used BELU@1/2/3/4 and ROUGE-L to assess textual prediction quality. For videos, we employed Fréchet Video Distance (FVD), CLIP Video Score (CLIP-V)↑, and CLIP Text Score (CLIP-T) to evaluate visual quality and semantic alignment.
Baseline Models. As existing methods were not designed for VNEP, we established baselines by adapting top models from related fields, including: (1) Video extension model Video-GPT; (2) Cascaded pipelines combining leading VLMs (Gemini-2.5-Flash, Qwen-2.5-VL-3B, and their NEP-fine-tuned version TEMPURA) with VDMs (Wan-2.1-1.3B, FilmWeaver); (3) Unified model Omni-Video.
Implementation Details. This paper adopts Qwen2.5-VL-3B as the VLM and Wan-2.1-1.3B as the VDM to initialize VANS. For Video-GPT, this paper provides the input video and leverages its native video continuation capability. For VANS and other baseline methods, this paper provides the input video and corresponding questions to perform NVEP.
Main Results
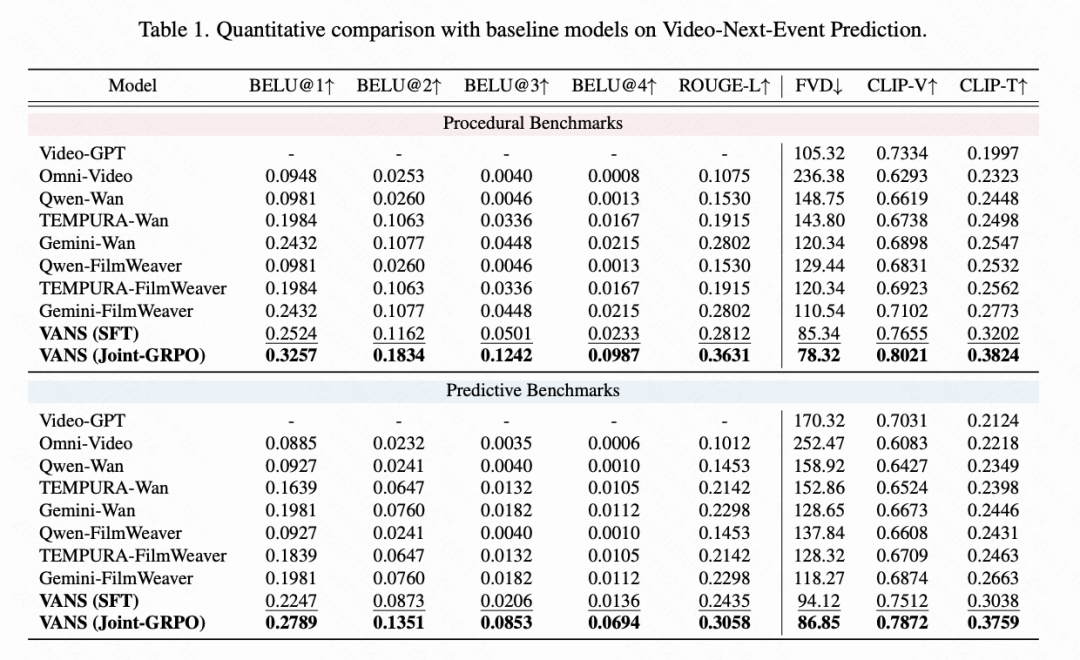
Quantitative Comparison. Table 1 below demonstrates that VANS outperforms all baseline models. In procedural benchmarks, VANS (with Joint GRPO) achieves a ROUGE-L score of 0.3631 and a CLIP-V score of 0.8021, surpassing the strongest cascaded baseline (Gemini-FilmWeaver combination with 0.2802 and 0.7102) and unified models (Omni-Video with 0.1075 and 0.6293). More importantly, Joint GRPO provides significant improvements over the SFT version (e.g., ROUGE-L increases from 0.2812 to 0.3631, CLIP-V from 0.7655 to 0.8021), demonstrating the effectiveness of our Joint GRPO strategy. Video-GPT, a video extension model, achieves the lowest CLIP-T score (0.1997) due to its direct frame generation without event reasoning.
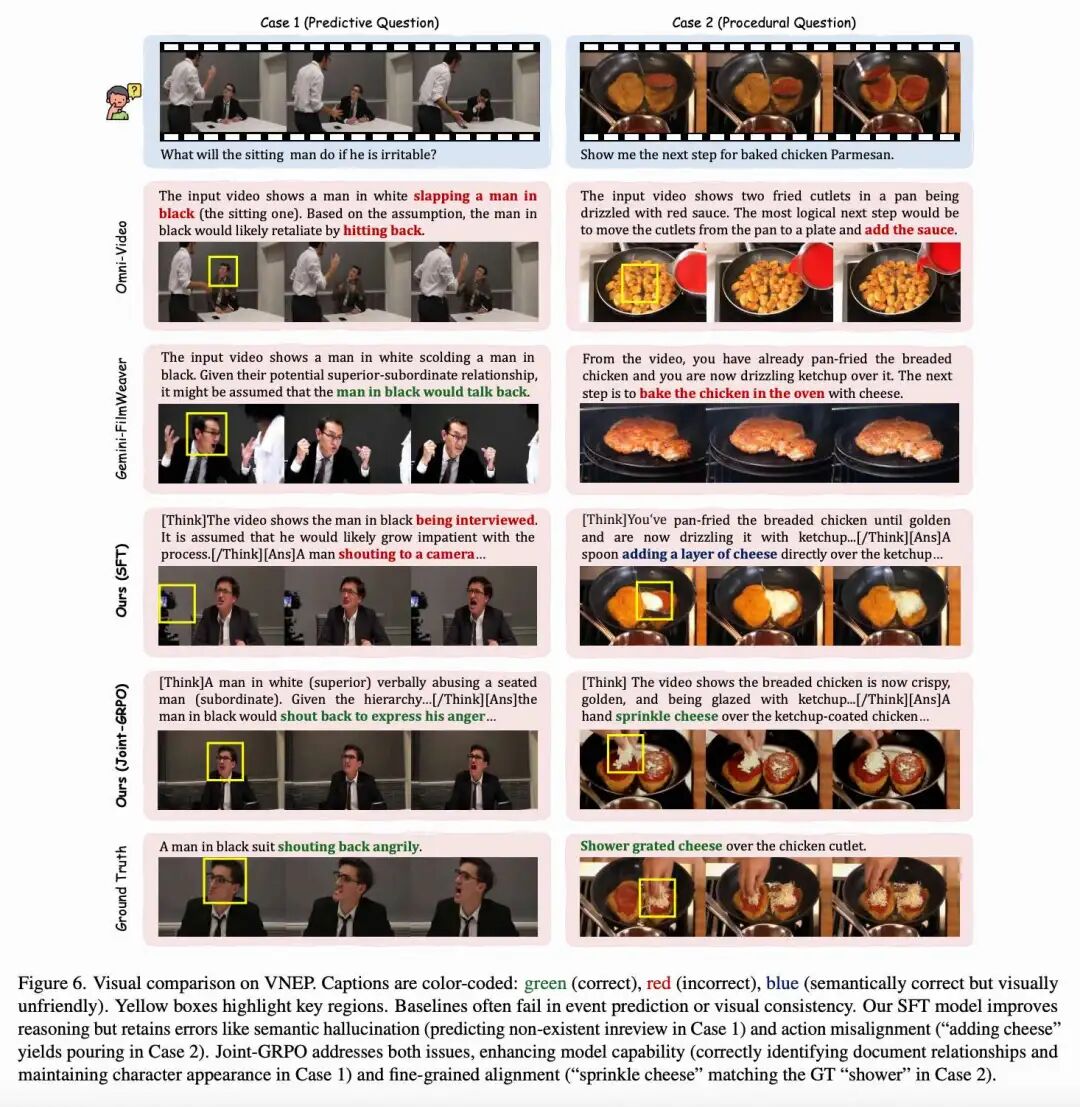
Qualitative Comparison. As shown in Figure 6 below, baseline models often make errors in event prediction or visual consistency: for example, Omni-Video misinterprets an argument as a fight and generates characters that deviate from input features; while SFT-trained VANS improves reasoning capabilities, it still exhibits two key limitations—component-level errors (e.g., VLM hallucinations generating non-existent text like "inreview" in Case 1) and semantic-visual misalignment (e.g., the instruction "add cheese" in Case 2 results in a pouring action instead of a realistic "sprinkling" action). VANS with Joint GRPO enhances component capabilities and achieves semantic-visual alignment through precise captions like "sprinkle cheese" and their corresponding visual representations of the "sprinkling" action.
Ablation Experiments
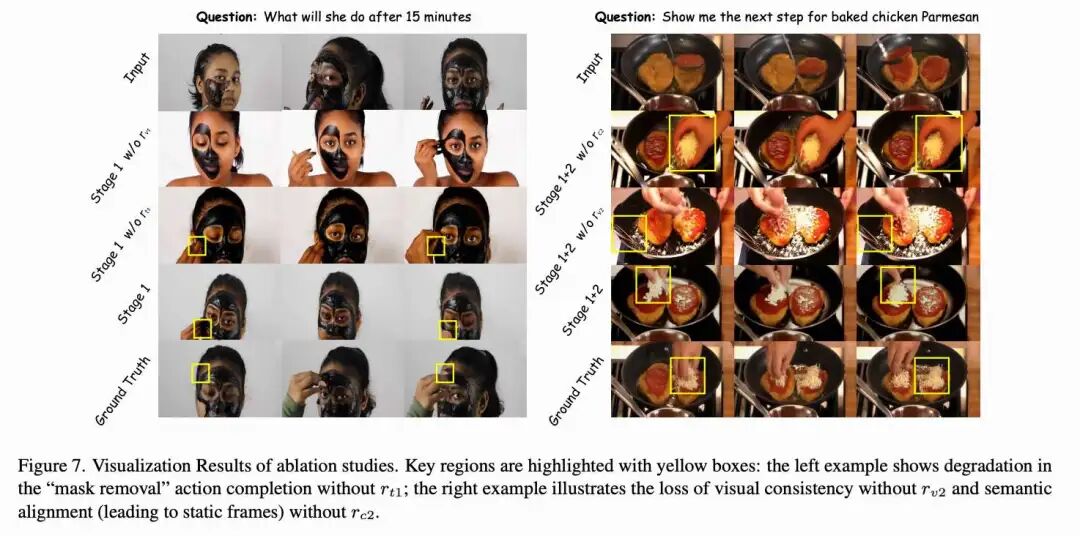
This paper validates the design of Joint GRPO through ablation studies, with results presented in Table 2 and Figure 7 below.
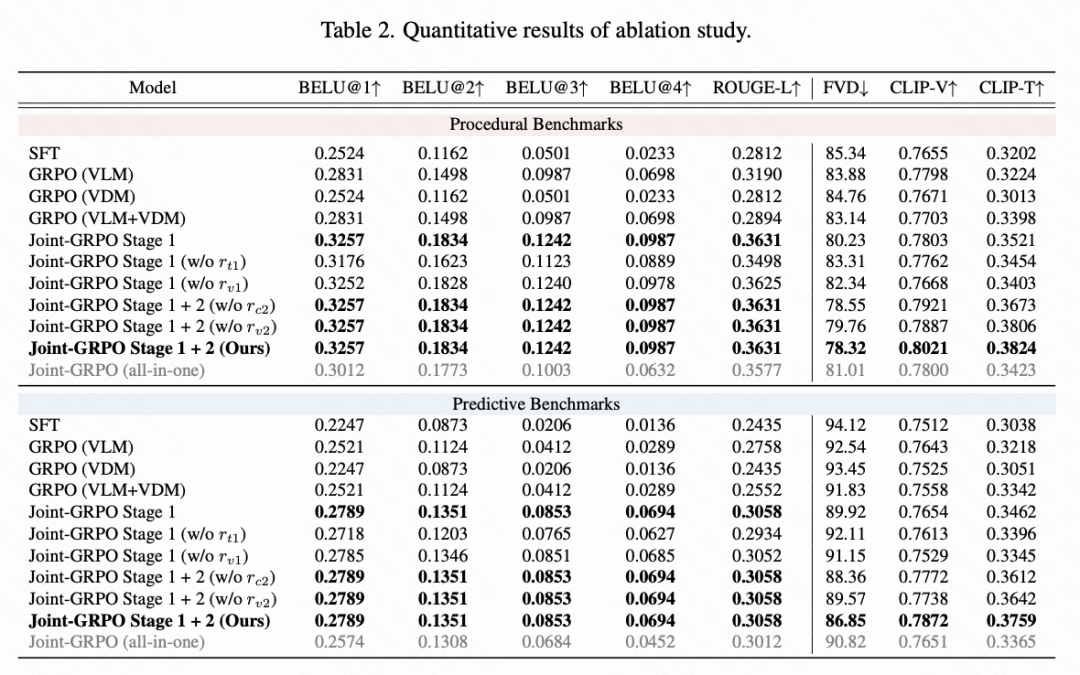
Joint Optimization vs. Isolated Optimization. Joint GRPO outperforms variants applying GRPO solely to the VLM or VDM, as well as schemes involving simple cascading of independently optimized versions. This confirms the necessity of joint optimization for generating coherent caption-video outputs, where the VLM and VDM bridge the semantic-visual gap through collaborative adaptation.
Phased Training Effectiveness. The two-stage design proves critical: using only Stage 1 leads to semantic drift in captions and videos, while an integrated variant causes optimization instability due to reward ambiguity—making it difficult to determine whether low rewards stem from the VLM's caption or the VDM's video generation.
Reward Component Analysis. Further ablation tests validate the contributions of individual reward components: in Stage 1, removing the text fidelity reward reduces caption accuracy (e.g., failing to predict "remove mask"), while removing the video fidelity reward harms visual consistency; in Stage 2, removing the semantic alignment reward leads to reward hacking with static frames, and removing the video fidelity reward reduces output coherence. These findings validate our complete design featuring phased optimization and balanced reward components.
Conclusion
This study pioneers a new task of video-based next event prediction, advancing next event reasoning from textual descriptions to dynamic video demonstrations. To address its unique challenges, this paper proposes the VANS framework, which integrates VLM and VDM through Joint GRPO (a two-stage RL strategy coordinating dual models under a joint reward), and constructs the VANS-Data-100K dataset to provide a critical training and evaluation foundation for this task. Experiments on established benchmarks demonstrate that VANS achieves state-of-the-art performance in both event prediction accuracy and video generation quality.
References
[1] Video-as-Answer: Predict and Generate Next Video Event with Joint-GRPO
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






