End-to-End Pixel Diffusion with a Heaven-Sent Cheat Code! Peking University & Huawei, etc., Open-Source DeCo: Surpassing SD3, OmniGen2, and Others in Image Generation Quality
 11/26 2025
11/26 2025
 629
629
Interpretation: The Future of AI-Generated Content 

Key Highlights
DeCo Decoupling Framework: DiT focuses on low-frequency semantic modeling (using downsampled input); a lightweight pixel decoder reconstructs high-frequency signals.
Innovative Frequency-Aware Loss Function: Converts signals to the frequency domain via DCT; assigns adaptive weights based on JPEG quantization tables; enhances visually significant frequencies while suppressing high-frequency noise.
DeCo Achieves Leading Performance in Pixel Diffusion Models: FID scores of 1.62 (256×256) and 2.22 (512×512) on ImageNet, narrowing the gap with two-stage latent diffusion methods. The pre-trained text-to-image model also achieves SOTA results in system-level evaluations on GenEval (0.86) and DPG-Bench (81.4).
By implementing specialized division of labor through architectural-level decoupling, DeCo provides a new design paradigm for pixel diffusion models while maintaining the advantages of end-to-end training.
Summary Overview
Problem Addressed
Core Conflict: Pixel diffusion models must simultaneously model high-frequency signals (details, noise) and low-frequency semantics (structure, content) within a single diffusion Transformer, leading to excessive model burden, inefficiency, and compromised generation quality.
Specific Drawbacks:
High-frequency noise interferes with DiT's learning of low-frequency semantics.
A single model struggles to balance tasks with two distinct characteristics in the vast pixel space.
Traditional methods result in slow training and inference speeds, with output images exhibiting noise and reduced quality.
Proposed Solution
Core Framework: Introduces the DeCo frequency-decoupled pixel diffusion framework.
Core Idea: Decouples the generation of high- and low-frequency components, allowing different components to specialize.
Specific Measures:
DiT focuses on low-frequency semantic modeling using downsampled input.
A lightweight pixel decoder, guided by DiT's semantic output, specializes in reconstructing high-frequency signals.
A frequency-aware flow matching loss function is proposed to optimize training.
Applied Technologies
Architectural Decoupling: Adopts a dual-path architecture with DiT as the semantic backbone and a lightweight pixel decoder.
Frequency-Aware Loss: Utilizes discrete cosine transform (DCT) to convert signals to the frequency domain and assigns adaptive weights to different frequency components based on JPEG quantization table priors, emphasizing visually significant frequencies and suppressing high-frequency noise.
End-to-End Training: Maintains the advantages of end-to-end pixel diffusion training while enhancing efficiency through decoupling design.
Achieved Results
Leading Performance: Achieves outstanding performance among pixel diffusion models on ImageNet, with FID scores of 1.62 (256×256) and 2.22 (512×512), significantly narrowing the gap with mainstream latent diffusion methods.
Comprehensive Excellence: The pre-trained text-to-image model achieves leading scores in system-level evaluations on GenEval (0.86) and DPG-Bench (81.4).
Quality Improvement: Effectively enhances visual fidelity and mitigates high-frequency noise interference through decoupling design and frequency-aware loss.
Proven Effectiveness: Experimental results validate the effectiveness of decoupling high- and low-frequency component modeling in pixel diffusion.
Methodology
Overview
This section first reviews conditional flow matching in baseline pixel diffusion and then introduces the proposed frequency-decoupled pixel diffusion framework.
Conditional Flow Matching. Conditional flow matching provides a continuous-time generative modeling framework that transports samples from a simple prior distribution (e.g., Gaussian) to a data distribution conditioned on labels and time by learning a velocity field. Given a forward trajectory constructed by interpolating between clean images and noise, the objective of conditional flow matching is to match the model-predicted velocity with the true velocity:
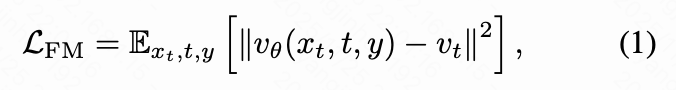
where the linear interpolation of trajectory is defined as:
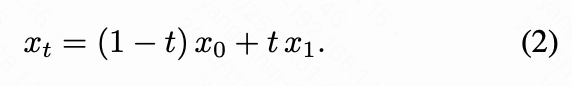
The true velocity can be derived as the time derivative of :
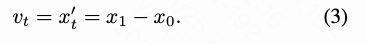
In baseline pixel diffusion, trajectory is typically tokenized via a patch embedding layer (rather than a VAE) to achieve image downsampling. In our baseline and DeCo experiments, we uniformly adopt a 16×16 patch size for DiT input. The baseline method feeds the patchified trajectory into DiT, which predicts pixel velocities via a depatch layer. This approach requires DiT to simultaneously model high-frequency signals and low-frequency semantics, but high-frequency signals (particularly noise) are difficult to model and interfere with DiT's learning of low-frequency semantics.
DeCo Framework. To separate high-frequency generation from low-frequency semantic modeling, we propose the frequency-decoupled framework DeCo. As shown in Figure 3 below:
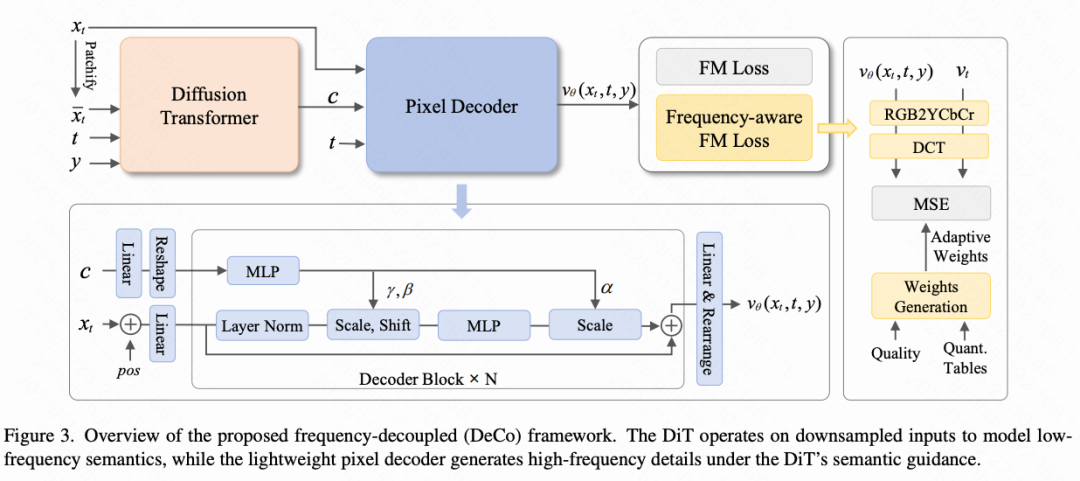
DiT is used to generate low-frequency semantics from a downsampled low-resolution input , as follows:
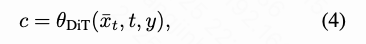
where denotes time, and represents a label or text prompt. As described later, the lightweight pixel decoder then conditions on DiT's output low-frequency semantics and combines a full-resolution dense input to generate additional high-frequency details, ultimately predicting pixel velocities as follows:
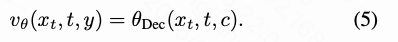
This new paradigm leverages the pixel decoder to generate high-frequency details, enabling DiT to focus on semantic modeling. This decoupling mechanism separates modeling tasks for different frequencies into distinct modules, accelerating training and enhancing visual fidelity.
To further emphasize visually significant frequencies and ignore insignificant high-frequency components, we introduce a frequency-aware flow matching loss function . This loss function reweights different frequency components using adaptive weights derived from JPEG perceptual priors. Combined with the standard pixel-level flow matching loss and REPA alignment loss from the baseline, the final objective function can be expressed as:
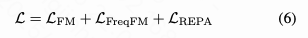
Pixel Decoder
As shown in Figure 3 above, the pixel decoder is a lightweight attention-free network composed of linear decoding blocks and several linear projection layers. All operations are local linear computations, enabling efficient high-frequency modeling without the computational overhead of self-attention.
Dense Query Construction. The pixel decoder directly takes a full-resolution noisy image as input (without downsampling). Each noisy pixel, concatenated with its corresponding positional encoding, is projected via a linear layer to form dense query vectors:
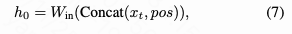
where , , and denote the original image's height and width (e.g., 256), and represents the pixel decoder's hidden dimension (e.g., 32). Relevant ablation experiments are presented in Table 4(c) and (d) below.
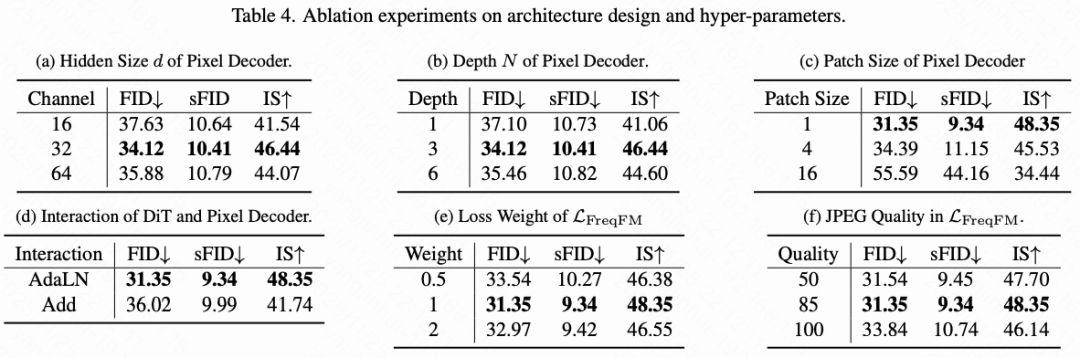
Decoder Block. For each decoder block, DiT's output is linearly upsampled and reshaped to match the spatial resolution of , yielding . An MLP then generates modulation parameters for adaptive layer normalization:

where denotes the SiLU activation function. We adopt AdaLN-Zero [43] to modulate dense decoder queries in each module as follows:
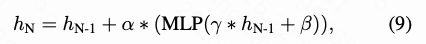
where the MLP consists of two linear layers with SiLU activations.
Velocity Prediction. Finally, the decoder's output is mapped to pixel space via linear projection and reshaping operations, yielding the predicted velocity . This velocity incorporates high-frequency details generated by the pixel decoder and semantic information from DiT.
Frequency-Aware FM Loss
To further encourage the pixel decoder to focus on perceptually important frequencies and suppress irrelevant noise, we introduce a frequency-aware flow matching loss.
Spatial-Frequency Transformation. We first convert the predicted and true pixel velocities from the spatial domain to the frequency domain. Specifically, we convert the color space to YCbCr and perform block-wise 8×8 discrete cosine transform (DCT) according to JPEG standards. Denoting this transform as , we have:
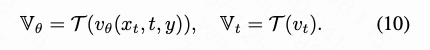
Perceptual Weighting. To emphasize visually significant frequencies and suppress minor frequencies, we use JPEG quantization tables as visual priors to generate adaptive weights. Frequencies with smaller quantization intervals have higher perceptual importance. Thus, we use the normalized reciprocal of the scaled quantization table at quality level as adaptive weights, i.e., . When the quality level ranges from 50 to 100, the corresponding scaled quantization table can be obtained according to JPEG preset rules:
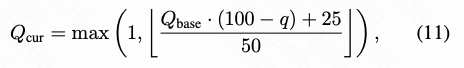
where denotes the base quantization table defined in JPEG standards. Based on the adaptive weights , the frequency-aware flow matching loss is defined as follows:
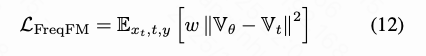
Empirical Analysis
To verify that DeCo effectively achieves frequency decoupling, we analyze the DCT energy spectra of DiT's output and pixel velocities (Figure 4 below).

Compared to the baseline method, our pixel decoder successfully preserves all frequency components in the pixel velocities. Meanwhile, the high-frequency energy in DeCo's DiT output is significantly lower than the baseline, indicating that high-frequency components have been transferred from DiT to the pixel decoder. These observations confirm that DeCo achieves effective frequency decoupling. The results in Table 4(c)(d) further demonstrate that this successful decoupling benefits from two key architectural designs:
Multi-Scale Input Strategy. The multi-scale input strategy is crucial: through this approach, the pixel decoder can easily model high-frequency signals on the high-resolution original input, while enabling DiT to focus on modeling low-frequency semantics from the low-resolution input where high-frequency signals have been partially suppressed. Notably, our DiT adopts a 16×16 patch size, significantly larger than PixelFlow's [6] 4×4 patches, making it more suitable for semantic capture than detail reconstruction.
Interaction mechanism based on AdaLN. Adaptive Layer Normalization provides a powerful interaction mechanism between DiT and the pixel decoder. In this framework, DiT functions similarly to the text encoder in traditional text-to-image models, providing stable low-frequency semantic conditions. The AdaLN layer then modulates the dense query features in the pixel decoder, conditioned on the DiT output. Experiments confirm that this modulation mechanism is more effective in fusing low-frequency semantics with high-frequency signals than simple methods like UNet, which use upsampling to stack low-frequency features.
Experiments
This paper conducts ablation experiments and baseline comparisons on the ImageNet 256×256 dataset. For class-to-image generation tasks, detailed comparisons are provided at ImageNet 256×256 and 512×512 resolutions, reporting FID, sFID, IS, precision, and recall. For text-to-image generation tasks, results on GenEval and DPG-Bench are reported.
Baseline Comparison
Experimental Setup. All diffusion models in the baseline comparison are trained for 200,000 steps at ImageNet 256×256 resolution using a large DiT variant. The core architectural improvement over the baseline is replacing the last two DiT blocks with the proposed pixel decoder. During inference, 50-step Euler sampling is used without classifier-free guidance. This paper compares against the two-stage DiT-L/2 requiring VAE, as well as recent pixel diffusion models like PixelFlow and PixNerd. DDT is adapted as a pixel diffusion baseline (PixDDT), and JiT is integrated into our baseline (with REPA) for fair comparison.
Detailed Comparison. As shown in Table 1 below, our DeCo framework significantly outperforms the baseline across all metrics with fewer parameters while maintaining comparable training and inference costs. Notably, through frequency decoupling architecture alone, DeCo (without FM loss) reduces FID from 61.10 to 34.12 and increases IS from 16.81 to 46.44. When combined with frequency-aware FM loss, DeCo further lowers FID to 31.35 and continuously improve (continuously improves) other metrics. Compared to the two-stage DiT-L/2, our VAE-free DeCo model achieves comparable performance while significantly reducing training and inference overhead. Among other pixel diffusion methods: DeCo is more efficient and performs better than the multi-scale cascaded model PixelFlow; outperforms the single-scale attention-based PixDDT; and achieves superior FID compared to recent PixNerd while reducing training and inference costs.
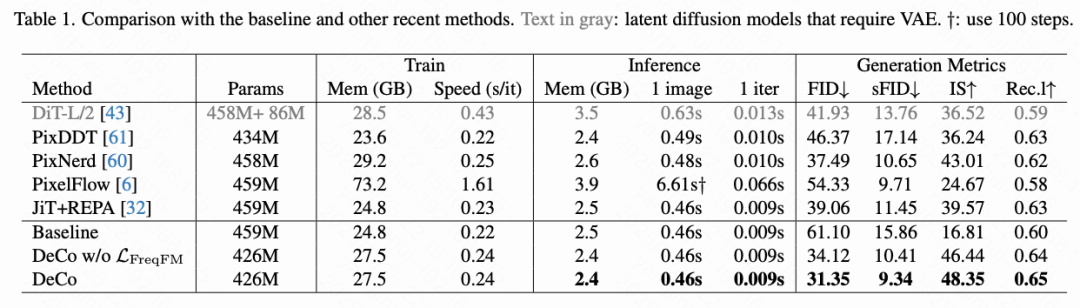
JiT points out that high-dimensional noise interferes with limited-capacity models' learning of low-dimensional data. By predicting clean images and anchoring the generation process to the low-dimensional data manifold, it successfully reduces FID from 61.10 to 39.06 (Table 1 above). Our DeCo shares similar motivation—preventing high-frequency signals containing high-dimensional noise from interfering with DiT's ability to learn low-frequency semantics—but proposes an architectural solution: introducing a lightweight pixel decoder to focus on modeling high-frequency signals, freeing DiT to learn low-frequency semantics. DeCo also mitigates the negative impact of high-frequency noise (e.g., camera noise) in clean images, thus achieving better FID (31.35 vs. 39.06) than JiT.
Class-to-Image Generation
Experimental Setup. For class-to-image generation experiments on ImageNet, we first train for 320 epochs at 256×256 resolution, followed by 20 epochs of fine-tuning at 512×512 resolution. During inference, 100-step Euler sampling is used with CFG [18] and guidance scale [29], measuring inference latency on a single A800 GPU.
Main Results. Our DeCo achieves leading FIDs of 1.62 and 2.22 on ImageNet 256×256 and 512×512, respectively. At 256×256 resolution, DeCo demonstrates exceptional inference efficiency: generating images in just 1.05 seconds (100 inference steps), compared to 38.4 seconds for RDM and 9.78 seconds for PixelFlow. Regarding training efficiency (Table 1), a single iteration takes only 0.24 seconds, far less than PixelFlow's 1.61 seconds. After the same 320 epochs of training, our model achieves a significantly lower FID (1.90) than the baseline's 2.79 and outperforms recent PixelFlow and PixNerd. As shown in Figure 5 below, DeCo reaches FID 2.57 in just 80 epochs (400,000 steps), surpassing the baseline's performance after 800 epochs and achieving a 10× training efficiency improvement. After 800 epochs of training, DeCo achieves the optimal FID of 1.62 with 250 sampling steps among pixel diffusion models, even comparable to two-stage latent diffusion models. Using the same Heun sampler and 50-step inference, DeCo reaches FID 1.69 at 600 epochs, surpassing JiT's FID 1.86 with fewer parameters and FLOPs. At 512×512 resolution, DeCo significantly outperforms existing pixel-based diffusion methods, setting a new leading FID of 2.22. Additionally, by fine-tuning the ImageNet 256×256 model for 20 epochs after 320 epochs using the PixNerd method, our FID and IS are comparable to those of DiT-XL/2 and SiT-XL/2 after 600 epochs of training.


Text-to-Image Generation
Experimental Setup. For text-to-image generation tasks, we train the model on the BLIP3o [5] dataset (containing approximately 36 million pre-trained images and 60,000 high-quality instruction-tuned data), using Qwen3-1.7B [65] as the text encoder. Complete training takes approximately 6 days on 8×H800 GPUs.
Main Results. Compared to two-stage latent diffusion methods, our DeCo achieves a comprehensive score of 0.86 on the GenEval benchmark, outperforming well-known text-to-image models like SD3 and FLUX.1-dev, as well as unified models like BLIP3o and OmniGen2. Notably, despite using the same training data as BLIP3o, our model still achieves better performance. On DPG-Bench, DeCo attains a competitive average score comparable to two-stage latent diffusion methods. Compared to other end-to-end pixel diffusion methods, DeCo shows significant performance advantages over PixelFlow and PixNerd. These results demonstrate that end-to-end pixel diffusion achieved by DeCo can attain performance comparable to two-stage methods with limited training/inference costs. Visualizations of text-to-image generation effects by DeCo are shown in Figure 1 above.
Further Ablation Experiments
This section conducts ablation studies on the pixel decoder design, interaction mechanism between DiT and the pixel decoder, and hyperparameters of the frequency-aware FM loss. All experiments follow the setup described earlier.
Hidden Dimension of Pixel Decoder. As shown in Table 4(a) above, DeCo performs best when the hidden dimension is [specific value not provided in original]. Too small a dimension limits model capacity, while larger dimensions do not bring additional gains. Therefore, a hidden dimension of 32 is used by default.
Depth of Pixel Decoder. Table 4(b) above shows that a 3-layer decoder performs best: a single layer lacks sufficient capacity, while 6 layers may cause optimization difficulties. With a hidden dimension of 32 and a 3-layer structure, our attention-free decoder contains only 8.5 million parameters and can efficiently process high-resolution inputs.
Patch Size of Pixel Decoder. Table 4(c) above indicates that performance is optimal when the decoder patch size is 1 (directly processing full-resolution inputs). Patchifying the decoder input reduces performance, with the worst performance observed when using the same large patch size of 16 as DiT. This validates the effectiveness of the multi-scale input strategy. All comparative experiments maintain similar parameter counts and computational costs.
Interaction Mechanism Between DiT and Pixel Decoder. Table 4(d) above shows that the simple upsampling and stacking scheme in the style of UNet [46] performs worse than the AdaLN-based interaction. AdaLN [43], using DiT output as semantic conditions to guide feature modulation, provides a more effective interaction mechanism.
Loss Weight. Table 4(e) above indicates that the results are optimal when the loss weight is 1, which is set as the default value.
JPEG Quality Factor. Table 4(f) above studies the influence of the JPEG quality factor: at quality 100 (lossless compression), all frequencies are treated equally, resulting in an FID of 33.84 (close to 34.12 without FM loss); the commonly used quality of 85 performs best, achieving an optimal balance by emphasizing important frequencies while moderately suppressing less important ones; reducing quality to 50 overly suppresses high-frequency signals, slightly degrading performance. Therefore, a JPEG quality of 85 is used in all experiments.
Conclusion
DeCo—An Innovative Frequency-Decoupled Framework for Pixel Diffusion. By using DiT to model low-frequency semantics and a lightweight pixel decoder to model high-frequency signals, DeCo significantly improves generation quality and efficiency. The proposed frequency-aware FM loss further optimizes visual quality by prioritizing perceptually important frequencies. DeCo achieves leading pixel diffusion performance in both class-to-image and text-to-image generation benchmarks, narrowing the gap with two-stage latent diffusion methods.
References
[1] DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






