Farewell VAE! NVIDIA PixelDiT Challenges SD/FLUX: Breaking Through in Pixel Generation with End-to-End Performance Comparable to Latent Space Models
 11/27 2025
11/27 2025
 633
633
Interpretation: The Future of AI-Generated Content 
Key Highlights
PixelDiT, a single-stage, fully Transformer-based pixel space diffusion model, enables end-to-end training without the need for a separate autoencoder.
Demonstrates that efficient pixel modeling is the key to practical pixel space diffusion and proposes a dual-level DiT architecture that decouples global semantic learning from pixel-level texture details.
Introduces pixel-level AdaLN modulation and pixel token compression mechanisms to achieve dense per-pixel token modeling.
PixelDiT achieves high image quality in both class-conditional image generation and text-to-image generation, significantly outperforming existing pixel space generation models and approaching state-of-the-art latent space diffusion models. 
Summary Overview
Problems Addressed
Deficiencies in Two-Stage Pipelines: Traditional latent space diffusion models rely on pre-trained autoencoders, leading to:
Lossy reconstruction: The reconstruction process of autoencoders loses high-frequency details, limiting the fidelity of generated samples.
Error accumulation: Errors from the diffusion process and autoencoder reconstruction accumulate.
Difficulty in joint optimization: The two-stage pipeline hinders end-to-end joint optimization.
Challenges in Pixel Space Modeling: Direct diffusion in pixel space faces a trade-off between computational efficiency and generation quality:
High computational cost: Global attention computation on dense pixel-level tokens is complex and expensive.
Loss of details: Using large image patches to reduce computation weakens pixel-level modeling, resulting in poor texture detail generation.
Proposed Solution
PixelDiT Model: A single-stage, end-to-end, fully Transformer-based diffusion model.
Core Design: Adopts a dual-level architecture to decouple the learning of image semantics and pixel details:
Patch-level DiT: Uses large image patches to perform long-range attention on shorter token sequences, capturing global semantics and layout.
Pixel-level DiT: Performs dense per-pixel token modeling to refine local texture details.
Applied Technologies
Pixel-level AdaLN Modulation: Uses semantic tokens from the patch level to conditionally modulate each pixel token, aligning pixel-level updates with global context.
Pixel Token Compression Mechanism: Compresses pixel tokens before performing global attention and then decompresses them afterward. This enables per-pixel token modeling while maintaining the computational efficiency of global attention.
Achieved Results
Image Generation Quality: Achieves FID 1.61 on ImageNet 256×256, significantly surpassing previous pixel space generation models.
Scalability: Successfully extends to text-to-image generation and performs direct pretraining in a 1024×1024 pixel space. Achieves 0.74 on GenEval and 83.5 on DPG-bench, with performance approaching the best latent space diffusion models.
Advantages: Avoids VAE artifacts: Direct operation in pixel space better preserves content details in image editing tasks. Efficiency and detail coexistence: The dual-level design combines efficient pixel modeling, achieving high training efficiency and fast convergence while retaining fine details. 



Methodology
PixelDiT, a Transformer-based diffusion model, performs denoising directly in pixel space. This work aims to make pixel token modeling computationally more efficient while maintaining the convergence behavior and sample quality of latent space methods.
Dual-Level DiT Architecture
As shown in Figure 2, this work adopts a dual-level Transformer organization that concentrates semantic learning on a coarse-grained patch-level pathway and utilizes specialized Pixel Transformer (PiT) modules for detail refinement in the pixel-level pathway. This organization allows most semantic reasoning to occur on low-resolution grids, reducing the burden on the pixel-level pathway and accelerating learning, consistent with observations in literature [11, 28, 29].
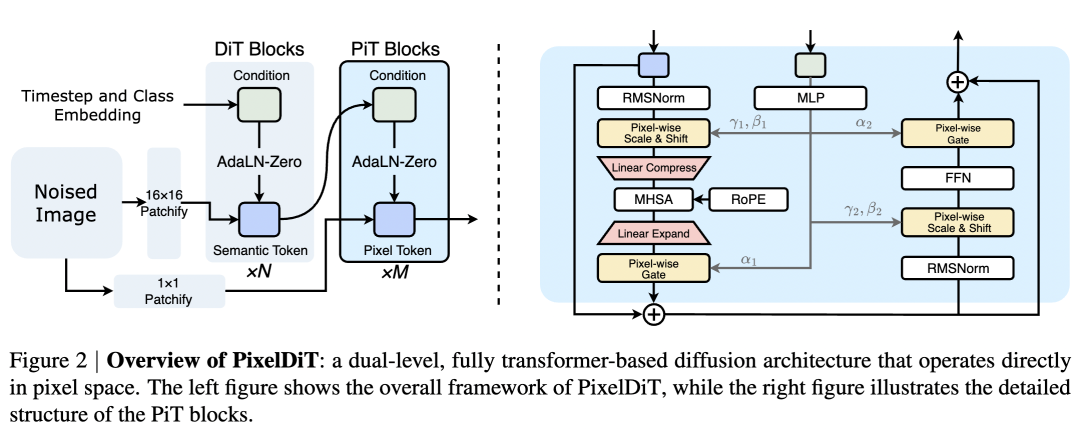
Patch-Level Architecture: Let the input image be . This work constructs non-overlapping patch tokens, where is the number of tokens, and projects them to the hidden layer dimension :
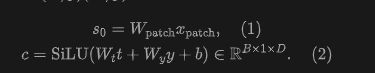
Following literature [7], this work enhances the DiT module by replacing LayerNorm with RMSNorm and applying 2D RoPE in all attention layers. The patch-level pathway consists of enhanced DiT modules; for the -th module, there is:

where the AdaLN modulation parameters are generated from the global conditional vector and then broadcast to patch tokens. This global-to-patch broadcasting applies the same per-feature AdaLN parameters to all patch tokens (i.e., token-independent at the patch level), contrasting with the per-pixel AdaLN used subsequently in the pixel-level pathway.
After modules, semantic tokens are obtained. Following the design spirit of literature [11, 28], this work defines the conditional signal for the pixel-level pathway as , where is the time step embedding. These tokens provide semantic context for the PiT modules through per-pixel AdaLN.
Pixel-Level Architecture: The pixel-level DiT consists of layers of PiT Blocks. It receives pixel tokens and the output of the patch-level DiT as inputs to perform pixel token modeling and generate the final result. The details of each PiT module are described below.
Design Considerations: The patch-level pathway processes only patch tokens to capture global semantics. By delegating detail refinement to the pixel-level pathway, this work can adopt a larger patch size , which shortens the sequence length and accelerates inference while preserving per-pixel fidelity. Additionally, the pixel-level pathway operates at a reduced hidden dimension (e.g., ), ensuring that dense per-pixel computation remains efficient.
Pixel Transformer Module
Each PiT module contains two core components. First, per-pixel AdaLN (pixel-wise AdaLN) achieves dense conditioning at the individual pixel level, aligning per-pixel updates with global context. Second, the pixel token compaction mechanism reduces redundancy among pixel tokens, enabling global attention to operate on a manageable sequence length.
Per-Pixel AdaLN Modulation: In the pixel-level pathway, each image is embedded as 'one token per pixel' through a linear layer:

To align with patch-level semantic tokens, this work reshapes it into sequences, each containing pixel tokens, i.e., . For each patch, this work forms a semantic conditional token summarizing the global context.
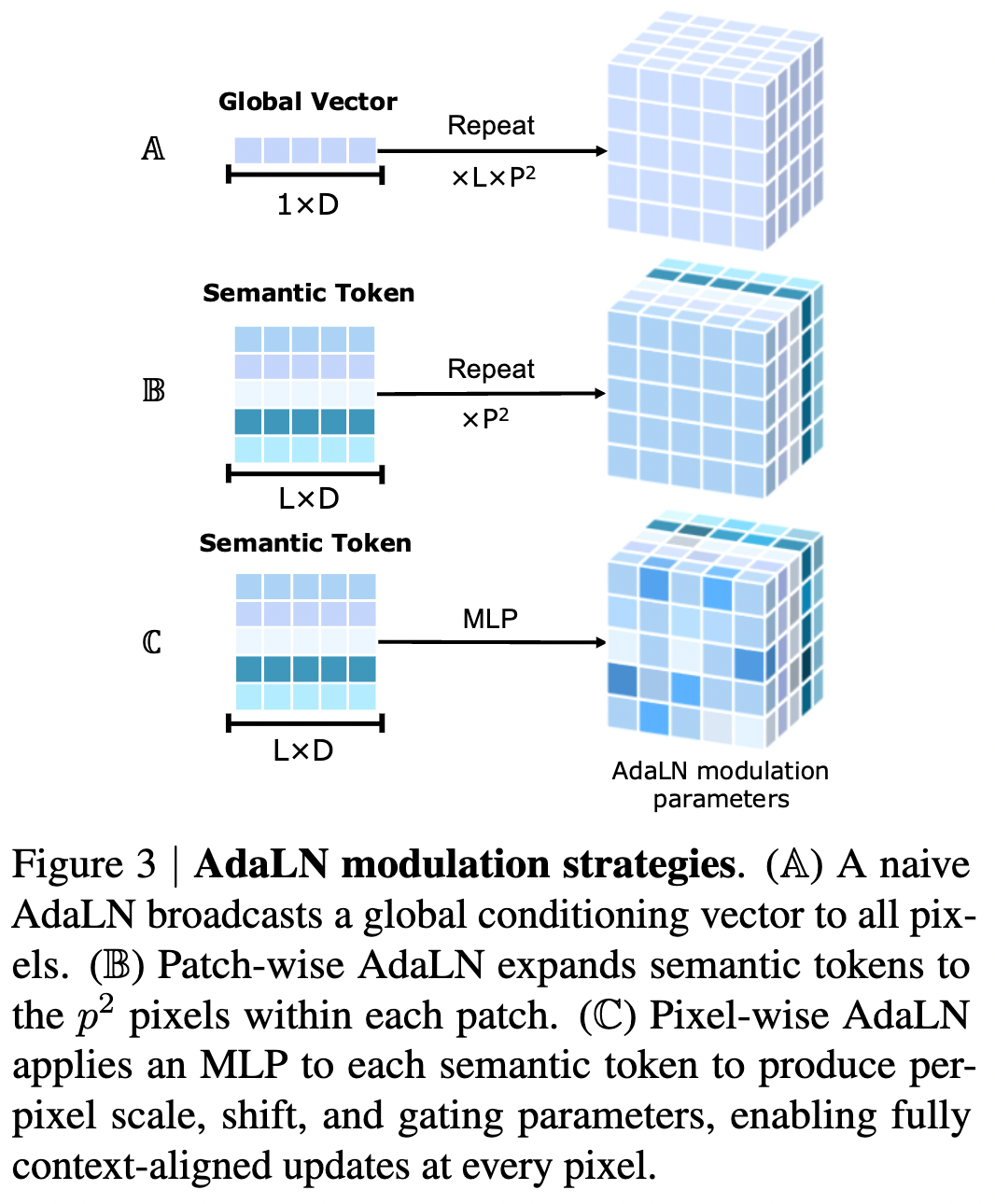
As shown in Figure 3(B), a direct patch-level modulation would repeat the same parameters for all pixels within a patch. However, this fails to capture dense per-pixel variations. Instead, this work expands into groups of AdaLN parameters through linear projection , assigning independent modulation to each pixel:
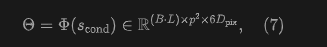
and divides the last dimension of into six groups, each of size , resulting in . These modulation parameters are learnable and, as shown in Figure 3(C), differ at each pixel. They are applied to through per-pixel AdaLN, achieving pixel-specific updates; in contrast, patch-level AdaLN broadcasts the same set of parameters to all pixels within a patch, failing to capture such spatial variations.
Pixel Token Compaction: In the pixel-level pathway, directly performing attention computation on all pixel tokens is computationally infeasible. Therefore, this work compresses pixel tokens within each patch into a single compact patch token before global attention and then expands the attention-weighted representation back to pixels. This reduces the attention sequence length from to , i.e., by a factor of ; when , this yields a 256-fold reduction while preserving per-pixel updates through per-pixel AdaLN and learnable expansion.
This work instantiates the compaction operator through a learnable 'flattening' operation: a linear mapping jointly mixing spatial and channel dimensions , paired with an expansion operator . This 'compression-attention-expansion' pipeline maintains the efficiency of global attention. Unlike the lossy bottleneck in VAEs, this mechanism only momentarily compresses representations for attention operations. Critically, this compaction operation is purely to reduce the computational overhead of self-attention; it does not harm fine-grained details, as high-frequency information is preserved through residual connections and learnable expansion layers that effectively bypass the pixel token bottleneck.
PixelDiT for Text-to-Image Generation
This work extends the patch-level pathway with a multimodal DiT (MM-DiT) module that fuses text and image semantics, while the pixel-level pathway remains unchanged. In each MM-DiT module, image and text tokens form two streams with independent QKV projections.
Text embeddings are generated by a frozen Gemma-2 encoder. Following literature [36], this work prepends a concise system prompt to user prompts and then inputs the sequence into the text encoder. The resulting token embeddings are projected to the model width and used as the text stream in MM-DiT.
Empirical evidence shows that semantic tokens from the patch-level pathway are sufficient to convey textual intent to pixel updates. Therefore, the pixel-level pathway remains architecturally identical to the class-conditional model: it operates on pixel tokens and is conditioned only through semantic tokens and time steps. Text tokens are not directly routed to the pixel stream.
Training Objective
This work adopts the Rectified Flow formulation in pixel space and trains the model using its velocity-matching loss:

Following literature [31], this paper includes an alignment objective that encourages consistency between mid-level Patch pathway tokens and the features of a frozen DINOv2 encoder. The overall objective function is . The same formula is used for both class-conditional and text-conditional models.
Experiments
The experiments focus on the effectiveness, scalability, and inference efficiency of PixelDiT in two major tasks: class-conditional and text-to-image generation. The overall approach is to first establish a baseline and upper bound for pixel-space DiT on class-conditional generation at ImageNet 256×256, then extend to 1024² text-to-image scenarios to verify the stability and quality of the dual-level architecture under high-resolution and complex semantic conditions.

Setup and Scaling
This work instantiates three model scales (B/L/XL), trained on ImageNet-1K for class-conditional tasks, with PixelDiT-XL as the default. Training details emphasize stable optimization and convergence speed: bfloat16 mixed precision, AdamW, EMA, phased settings for high gradient clipping thresholds, and a Rectified Flow-based training paradigm. For text-to-image, Gemma-2 is used as the frozen text encoder, with MM-DiT fusion introduced at the patch-level pathway; pre-trained at 512×512, followed by fine-tuning at 1024² with approximately 26 million pairs, covering various aspect ratios. During inference, FlowDPM-Solver (a DPMSolver++ variant in Rectified Flow form) is used, with 100 steps as the default for class-conditional and 25 steps for text-to-image to balance quality and latency.
Class-Conditional Generation (ImageNet 256×256)
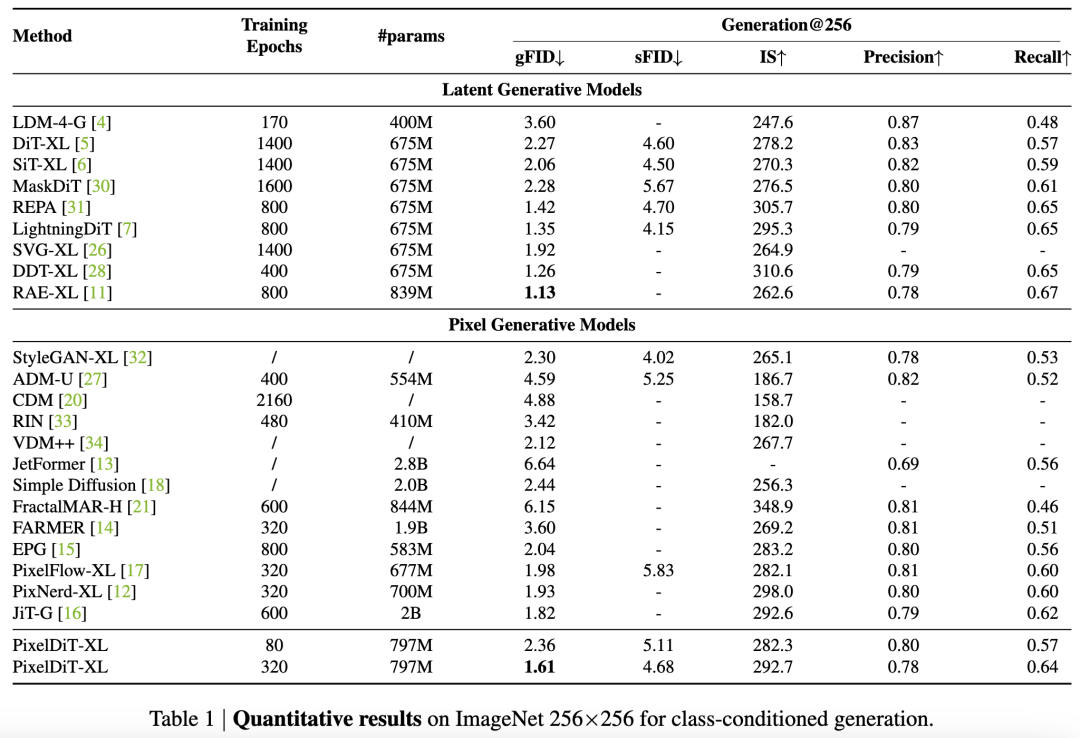
On standard 50K sampling evaluation, this work reports gFID, sFID, IS, Precision–Recall. Compared to representative pixel generation methods (e.g., PixelFlow-XL, PixNerd-XL, JiT-G), PixelDiT-XL achieves better or comparable gFID with significantly lower training cycle overhead and attains 1.61 gFID and 4.68 sFID with an IS of 292.7 and Recall of 0.64 under long training (320 epochs), demonstrating the potential to approach or even rewrite existing upper bounds in pixel space. Compared to latent-space DiT series (e.g., DiT-XL, SiT-XL, MaskDiT, LightningDiT, REPA/RAE), this work, though not reliant on VAEs, achieves competitive quality and diversity metrics, further approaching the best with longer training and optimized CFG interval settings.
Text-to-Image (512×512 and 1024²)
On GenEval and DPG-Bench, this work focuses on evaluating robustness in text alignment, counting, color/location attributes, and compositional relationships. PixelDiT-T2I achieves 0.78 on GenEval Overall at 512×512 and 0.74 at 1024²; on DPG-Bench, scores are 83.7 and 83.5, respectively. Compared to recent systems in pixel space, PixelDiT-T2I achieves higher or more balanced composite scores; against mainstream latent-space diffusion systems (e.g., SDXL, Hunyuan-DiT, Playground), it shows near-equivalent or comparable performance at 1024² across some dimensions while maintaining a more compact parameter size. This indicates the competitiveness of dual-level DiT in semantic consistency and compositional control at high resolutions, narrowing the gap between pixel-space and latent-space in large models.
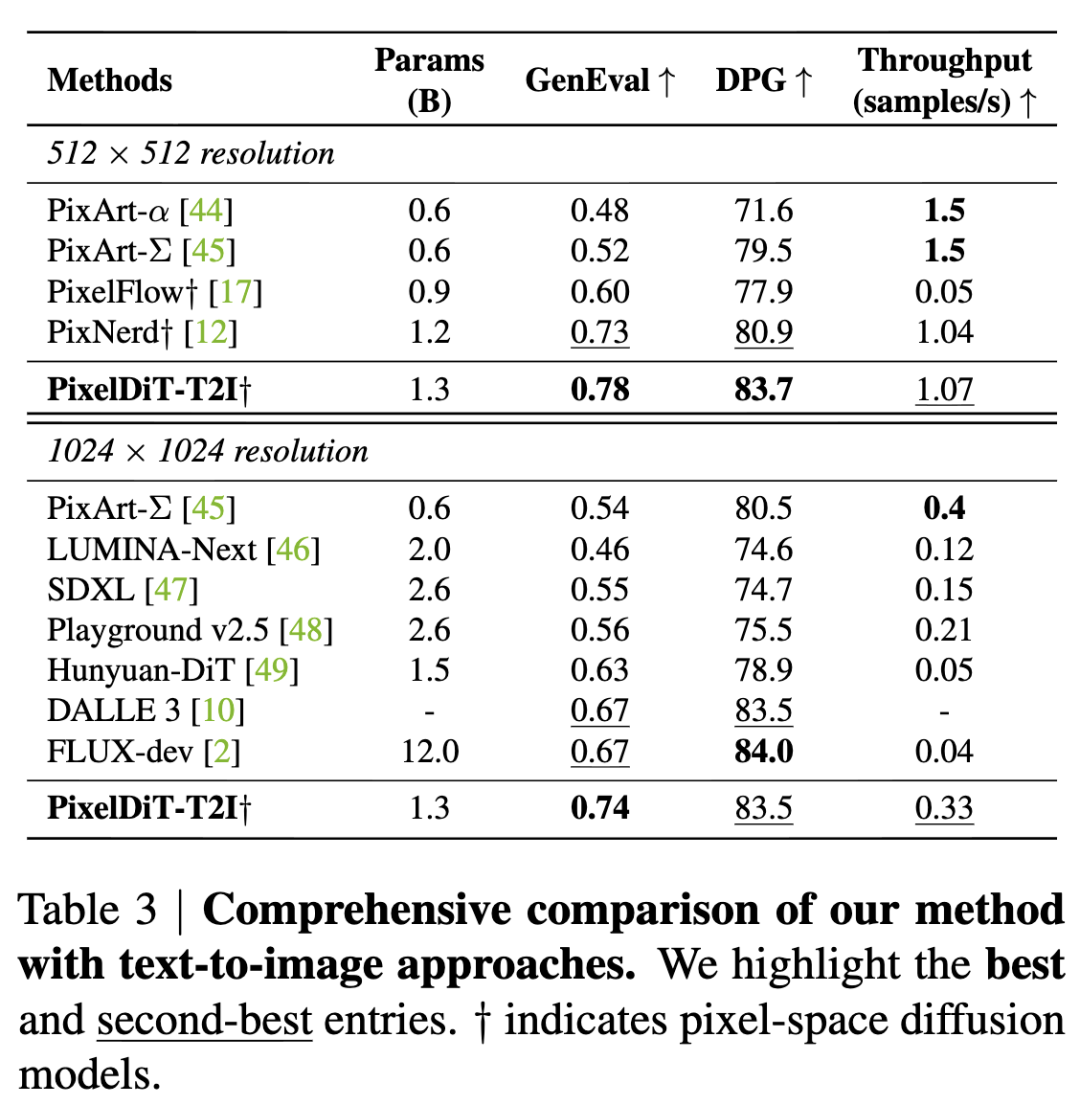
Sampling Strategy and Hyperparameter Sensitivity
Regarding samplers, FlowDPM-Solver, with a 100-step comparison without CFG (vs. Euler/Heun), balances favorable gFID/sFID and IS/Precision/Recall trade-offs, making it the default choice. In terms of steps, as training maturity increases (e.g., 400K, 1.6M steps), the benefits of increasing sampling steps become more pronounced; 100 steps yield the best metrics for class-conditional tasks, with diminishing returns after 50 steps. The scale and effective interval of CFG significantly impact the quality-diversity balance: earlier stages (80 epochs) favor stronger guidance applied throughout (e.g., 3.25, [0.10,1.00]), while longer training (320 epochs) prefers milder guidance with truncated intervals (e.g., 2.75, [0.10,0.90]), achieving the best overall results with the lowest gFID and high recall.
Ablation Experiments
Contribution of Core Components
Table 4 quantifies the contributions of each pixel modeling component across different model variants. Note that labels A–C in Table 4 correspond to the design schematics in Figure 3. Specifically, this work uses a 30-layer, patchified DiT performing denoising directly in pixel space as the baseline model (labeled “Vanilla DiT/16”). This baseline operates only on patch tokens without dedicated pixel-level pathways, treating each patch as a high-dimensional vector. It achieves a gFID of 9.84 at 80 epochs.
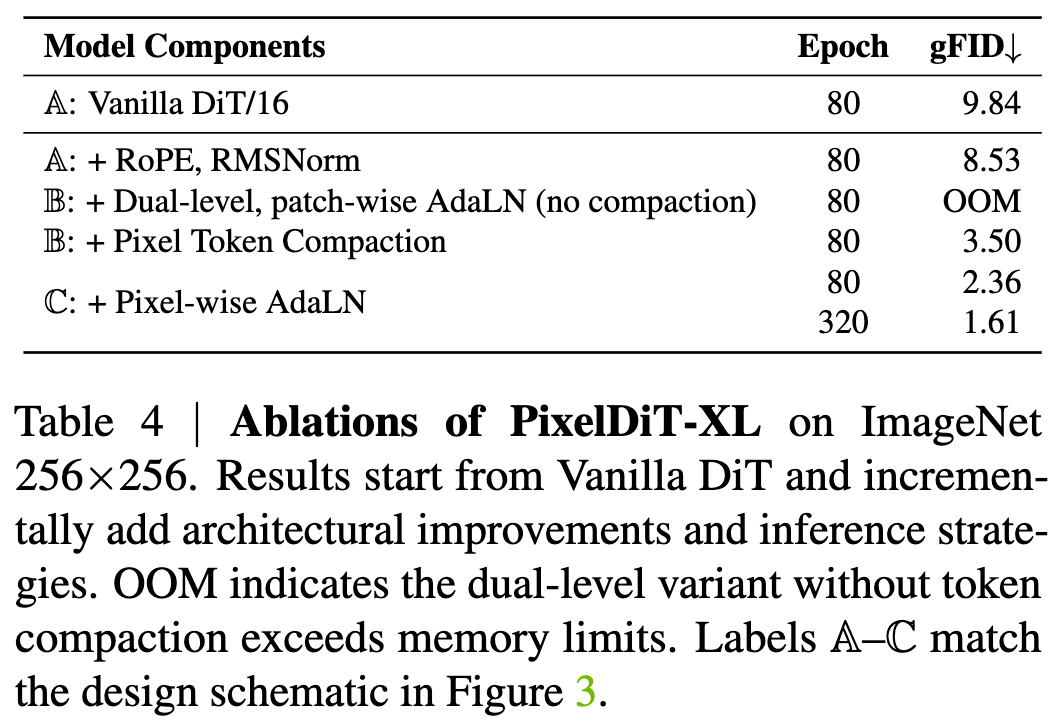
Introducing a dual-level architecture without pixel token compaction leads to quadratic growth in global attention computation with pixel count, causing out-of-memory (OOM) errors. Adding pixel token compaction resolves this bottleneck by shortening the global attention sequence length from pixels to patches, significantly improving quality to 3.50 gFID within the same 80-epoch budget.
Incorporating pixel-wise AdaLN further aligns pixel-level updates with semantic context from the patch-level pathway, improving gFID to 2.36 at 80 epochs and reaching 1.61 at 320 epochs.
Comparisons among model variants A, B, and C demonstrate the importance of each proposed component. More importantly, the contrast between the complete PixelDiT model C and Vanilla DiT/16 A shows that pixel-level token modeling plays a crucial role in pixel generation models. Without pixel modeling, where visual content is learned only at the patch level, the model struggles to learn fine details, and visual quality significantly declines.
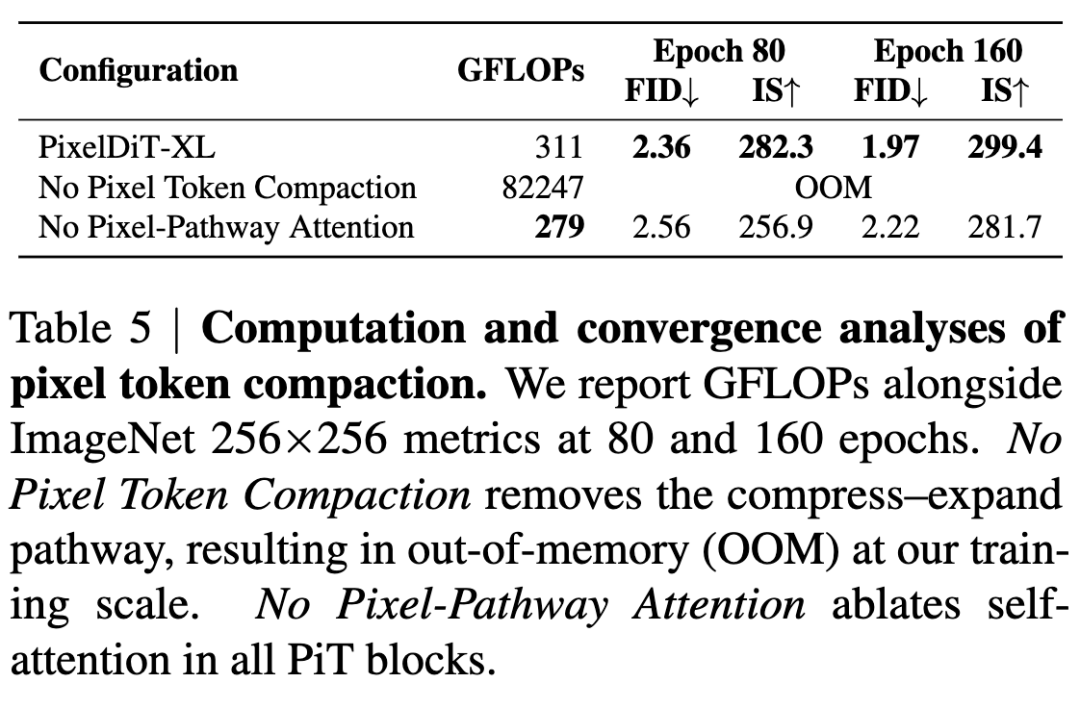
Analysis of Pixel Token Compaction
Token compaction is crucial for enabling feasible training in pixel space. Global attention on pixel tokens incurs memory usage and FLOPs, generating billions of attention entries even at resolutions, as shown by the 82,247 GFLOPs reported for this variant in Table 5. Utilizing pixel token compaction to group pixels into patches reduces sequence length to , resulting in a times reduction in attention overhead.
To analyze the role of attention in the pixel-level pathway, this paper includes an ablation experiment labeled “No Pixel-Pathway Attention,” which removes attention operations and retains only pixel-wise AdaLN and MLP at the pixel level. As shown in Table 5, although this variant reduces GFLOPs, its performance consistently lags behind the complete PixelDiT model across different training iterations (e.g., from 80 to 160 epochs), with noticeable degradation in both gFID and IS. This indicates that compact global attention is necessary for aligning local updates with global context.
Impact of Model Scale and Patch Size
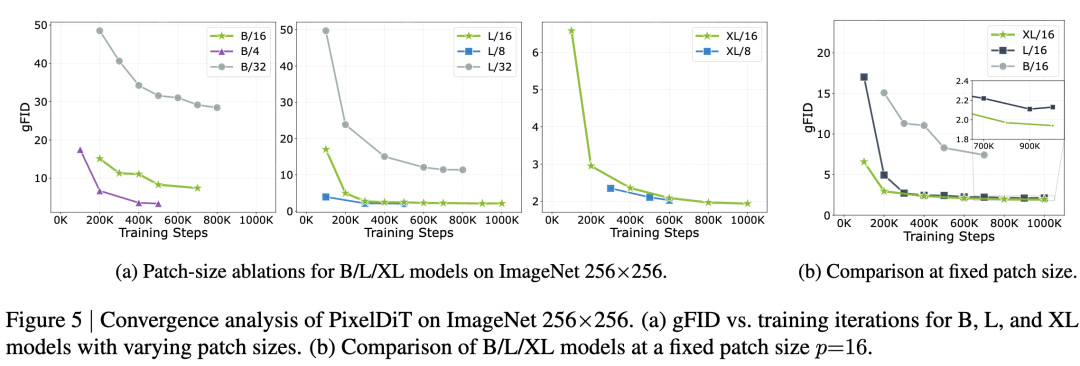
This paper investigates the effect of patch size on the performance of models of different scales: PixelDiT-B, PixelDiT-L, and PixelDiT-XL. For all evaluations, the same CFG guidance scale of 3.25 and interval of are used. This paper assesses patch sizes of 4, 8, 16, and 32 on ImageNet 256×256; Figure 5(a) visualizes the corresponding convergence behavior.
For the Base model, reducing to and significantly accelerates convergence: at 200K iterations, gFID drops from 48.5 (B/32) to 15.1 (B/16) and 6.7 (B/4), with B/4 ultimately reaching 3.4 gFID at 500K iterations. Larger models follow a similar trend, but the gains from extremely small patches diminish as model scale increases. For PixelDiT-L, using instead of only moderately improves gFID (from 2.72 to 2.15 at 300K iterations), while for PixelDiT-XL, the gap between and narrows further... (Note: The original text is truncated here.)
Conclusion
This paper revisits diffusion modeling in pixel space and demonstrates that, with appropriate architectural design, pixel-space diffusion Transformers can achieve high fidelity and efficiency without relying on pre-trained autoencoders. PixelDiT decomposes pixel modeling into a dual-level Transformer design, introducing pixel-level AdaLN and pixel token compression techniques to decouple global semantics from pixel-level token learning while maintaining manageable attention computation. Experiments on class-conditional image generation and text-to-image generation tasks show that this design significantly narrows the performance gap between latent-space and pixel-space methods and achieves strong performance at high resolutions.
Although pixel-space diffusion requires higher computational costs than latent-space methods due to the higher dimensionality of raw data, this work effectively narrows the efficiency gap. Overall, PixelDiT demonstrates that the primary obstacle to practical pixel-space diffusion is not the representation space itself but the lack of efficient pixel modeling architectures.
References
[1] PixelDiT: Pixel Diffusion Transformers for Image Generation
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






