CUHK & ByteDance Jointly Launch DreamOmni3: Unlocking Combined "Doodle + Text-Image" Input, Redefining Multimodal Generation and Editing
 01/05 2026
01/05 2026
 507
507
Interpretation: The Future of AI Generation 

Demonstration of DreamOmni3's Capabilities, Featuring Doodle-Based Editing and Generation Functions
Key Highlights
Introduces two highly practical tasks for unified generation and editing models: doodle-based editing and doodle-based generation. These tasks can be combined with language and image instructions, enhancing the creative usability of unified models and providing clear task definitions for targeted optimization and future research.
Proposes a pipeline for constructing a high-quality, comprehensive dataset for doodle-based editing and generation.
DreamOmni3: A framework supporting text, image, and doodle inputs, capable of handling complex logic. It accurately understands the intent expressed in doodles while maintaining editing consistency. It also incorporates positional and index encoding schemes to distinguish doodles from source images, ensuring compatibility with existing unified generation and editing architectures.
Establishes the DreamOmni3 Benchmark, built on real-world image data, demonstrating significant effectiveness in practical application scenarios.
Summary Overview
Problems Addressed
Limitations of Text Instructions: Existing unified generation and editing models rely on text instructions, which struggle to accurately describe editing positions, details, and spatial relationships intended by users.
Insufficient Interactive Flexibility: Lack of understanding of user-drawn sketches (e.g., doodles, box selections) limits intuitive and precise creation in graphical interfaces.
Data Scarcity: Shortage of multimodal editing and generation training data combining sketches, images, and text.
Difficulty in Handling Complex Edits: Traditional binary masks struggle with complex editing tasks involving multiple sketches, images, and instructions.
Proposed Solutions
Defines Two New Task Categories:
Sketch Editing: Includes sketch + instruction editing, sketch + multimodal instruction editing, image fusion, and doodle editing.
Sketch Generation: Includes sketch + instruction generation, sketch + multimodal instruction generation, and doodle generation.
Constructs a Data Synthesis Pipeline: Automatically generates training data by extracting editable regions from the DreamOmni2 dataset and overlaying hand-drawn graphics (boxes, circles, doodles) or cropping images.
Designs the DreamOmni3 Framework:
Adopts a joint input scheme, simultaneously feeding the original image and an image with sketches, using color to distinguish editing regions and avoiding binary masks.
Shares index and positional encodings between the two images, ensuring precise localization of sketch regions and editing consistency.
Establishes Benchmark Tests: Builds a comprehensive evaluation benchmark covering the aforementioned tasks to drive related research.
Applied Technologies
Multimodal Data Synthesis: Utilizes Refseg service to locate editing objects, combining hand-drawn annotations, image cropping, and sketch generation techniques to construct datasets.
Joint Encoding Mechanism: Uses identical index and positional encodings for the original and sketch images, enhancing the model's perception and alignment capabilities for sketch regions.
Unified Architecture Design: Compatible with RGB image inputs, extending DreamOmni2's positional offset and index encoding schemes to support multi-image input differentiation.
Sketch Understanding and Editing: Achieves joint understanding and generation of multi-region, multi-type editing intents through color-distinguished sketch inputs.
Achieved Effects
Enhances Interactive Flexibility: Supports user-specified editing positions and content through sketches, lowering the creative barrier.
Improves Editing Precision: The model accurately localizes sketch regions, enabling fine-grained editing and generation under complex multimodal instructions.
Open-Sources Data and Models: Publicly releases synthetic data, models, and code to promote research in related fields.
Superior Experimental Performance: DreamOmni3 excels in constructed benchmark tests, validating the framework's effectiveness and generalization capabilities.
Methodology
Synthetic Data
The greatest challenge in scribble-based editing and generation lies in data scarcity. This work requires constructing a dataset incorporating language, images, and scribbles as instructions, developing the ability to perform complex edits combining these three instruction types, and thereby realizing more intelligent editing tools. DreamOmni2 effectively unified language and image instructions, introducing multimodal instruction editing and generation tasks along with corresponding training data. Thus, this work directly extends DreamOmni2's multimodal instruction editing and generation data to include scribbles as instructions.
Scribble-Based Editing Tasks: As shown in Figure 2(a) below, this work subdivides scribble-based editing into four tasks:
Scribble and Multimodal Instruction-Based Editing: Utilizes the Refseg service to locate editing objects in reference and target images. As user-drawn shapes are often imperfect, this work manually created 30 different box and circle templates as scribble symbols, simulating human drawing habits through random perspective transformations.
Scribble and Instruction-Based Editing: Uses the same data as step (1) but removes the reference image.
Image Fusion: Extracts editing objects from the reference image and pastes them into corresponding positions in the source image.
Doodle Editing: Crops editing objects from the target image, generates sketches, and places them back into the source image.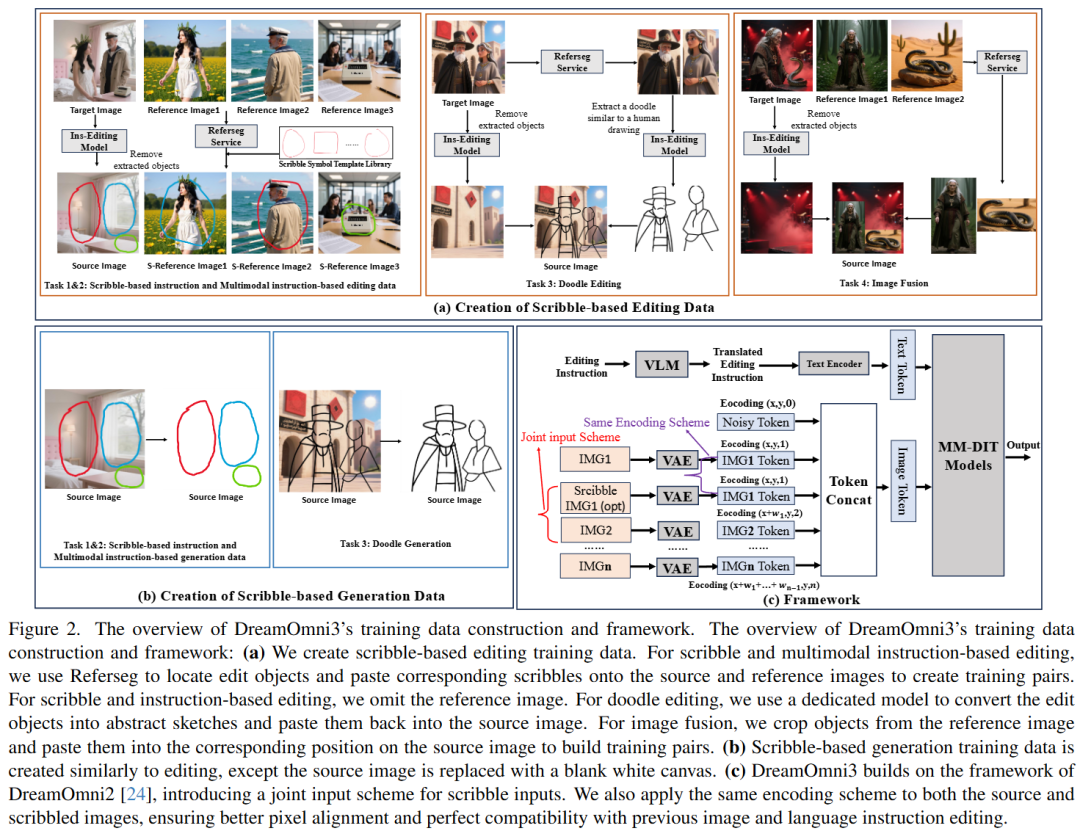
Scribble-Based Generation Tasks: As shown in Figure 2(b) above, this work subdivides scribble-based generation into three tasks:
Scribble and Multimodal Instruction-Based Generation: Uses Refseg to locate editing objects in images and marks circles or boxes on a blank canvas.
Scribble and Instruction-Based Generation: Removes the reference image from step (1)'s data.
Doodle Generation: Similar to doodle editing, places the final sketch on a white canvas, allowing the model to generate corresponding objects and backgrounds based on the sketch and instructions.
Dataset Scale: This dataset is built upon DreamOmni2's multi-reference image generation and editing training dataset.
Scribble-Based Editing Dataset: Includes approximately 32K training samples for scribble multimodal instruction editing, 14K for scribble instruction editing, 16K for image fusion, and 8K for doodle editing. Notably, the first two categories cover a wide range of editing categories (e.g., abstract attributes like design styles, color schemes, and hairstyles, as well as adding, removing, or modifying various objects, people, and animals). The latter two categories primarily focus on adding specific objects to images.
Scribble-Based Generation Dataset: Contains 29K scribble multimodal instruction generation samples, 10K scribble instruction generation samples, and 8K doodle generation samples. The first two categories involve specific object generation and abstract attribute references, while doodle generation primarily focuses on generating specific objects.
Framework and Training
Current unified generation and editing models primarily focus on instruction-based editing and theme-driven generation. DreamOmni2 extended this to multi-reference image generation and editing, but the input format for doodle instructions remains unexplored.
In DreamOmni3, this work considered two input schemes: one using binary masks similar to inpainting, and another involving joint input of the source image and a source image with doodles. As doodles inevitably alter parts of the source image while requiring consistency in non-edited regions, it is essential to retain source image details while inputting doodle information.
Compared to traditional binary mask methods, the proposed joint input scheme of the source image and doodle-modified source image offers two key advantages:
Simplicity and Efficiency: Joint input is more concise. When multiple doodles exist in reference or source images, binary masks become cumbersome, as each doodle requires a separate mask, significantly increasing computational load. Additionally, using binary masks makes it difficult to linguistically link doodles between two images. In contrast, joint input allows color-based differentiation during drawing, enabling simple language instructions to establish correspondences using image indices and doodle colors.
Better Model Integration: Existing unified generation and editing models are trained on RGB images. The joint input scheme uses masks in the original RGB space of the source image, better leveraging the model's existing image-text understanding capabilities and seamlessly integrating with its original capabilities, thereby creating a more unified and intelligent creative tool.
Framework Design: As shown in Figure 2(c) earlier, this work adapted the DreamOmni2 framework for scribble instruction input. The joint input scheme is optional:
When the source image in an editing task contains doodles, both the source image and the doodle-modified source image are simultaneously input into the MM-DIT model.
If the reference image contains doodles, the joint input scheme is not used, as pixel-level consistency in non-edited regions of the reference image is unnecessary, and additional inputs would unnecessarily increase computational costs.
For scribble-based generation tasks, the joint input scheme is also not used, as pixel-level preservation is unnecessary.
Encoding Strategy: Using the joint input scheme introduces two challenges: (1) adding an extra image affects the indexing of subsequent input images; (2) the model must correctly map pixel relationships between the source image and the doodle-modified source image. To address these, this work employs identical index encoding and positional encoding for the source image and the doodle-modified source image. Experiments show that this encoding effectively resolves the aforementioned issues, seamlessly integrating doodle editing capabilities into the existing unified framework.
Training Details: During training, the joint training scheme of DreamOmni2's VLM (Qwen2.5-VL 7B) and FLUX Kontext was used. Training employed LoRA with a Rank of 256. By utilizing LoRA, Kontext's original instruction editing capabilities were preserved. As DreamOmni2's multi-reference generation and editing capabilities were trained separately using two LoRAs, this work also used separate LoRAs for its generation and editing models to ensure compatibility. The entire training process took approximately 400 A100 hours.
Benchmark and Evaluation
This work introduces scribble-based editing and generation tasks integrating language, image, and scribble instructions. To advance this field, the DreamOmni3 Benchmark was established. Comprising real images, this benchmark accurately assesses model performance in realistic scenarios. Test cases cover the four editing tasks and three generation tasks proposed in this work, with diverse editing categories including abstract attribute edits and specific object edits.
As traditional metrics (e.g., DINO and CLIP) are insufficient for evaluating these complex tasks, this work adopted VLM-based evaluation criteria, focusing on four aspects:
Accuracy in Following Instructions for Generation and Editing.
Consistency of Appearance, Objects, and Abstract Attributes.
Avoidance of Severe Visual Artifacts.
Alignment Between Generated or Edited Content and Specified Doodle Regions.
Only tasks meeting all these criteria are considered successful. Comparisons between VLM evaluations and human assessments showed high consistency.
Experiments
This section quantitatively and qualitatively verifies DreamOmni3's performance in scribble-based editing and generation tasks.
Scribble-Based Editing Evaluation
Comparative Models: Compared with open-source models like Omnigen2, Qwen-image-Edit-2509, DreamOmni2, and Kontext, as well as closed-source commercial models like GPT-4o and Nano Banana.
Quantitative Results: As shown in Table 1 below, success rates were calculated using Gemini 2.5, Doubao 1.6, and human evaluations. DreamOmni3 achieved the best result in human evaluations (0.5750), surpassing GPT-4o (0.5875, but slightly lower in human evaluation) and Nano Banana. In contrast, other open-source models performed poorly.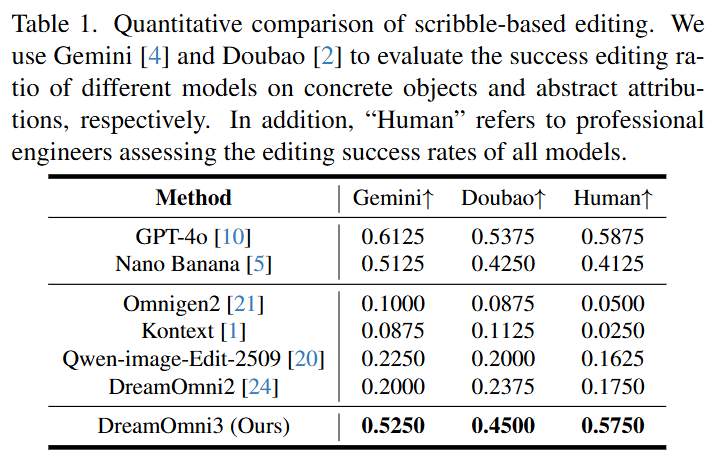
Qualitative Results: As shown in Figure 3 below, DreamOmni3 demonstrated more accurate editing results and better consistency. GPT-4o often exhibited image yellowing and pixel mismatches in non-edited regions, while Nano Banana showed noticeable copy-paste traces and proportional errors.
Scribble-Based Generation Evaluation
Quantitative Results: As shown in Table 2 below, DreamOmni3 outperforms Nano Banana in both human evaluation (0.5349) and model evaluation, and performs comparably to GPT-4o. Existing models (including GPT-4o) often fail to remove scribble traces in generated results and are not optimized for such tasks. 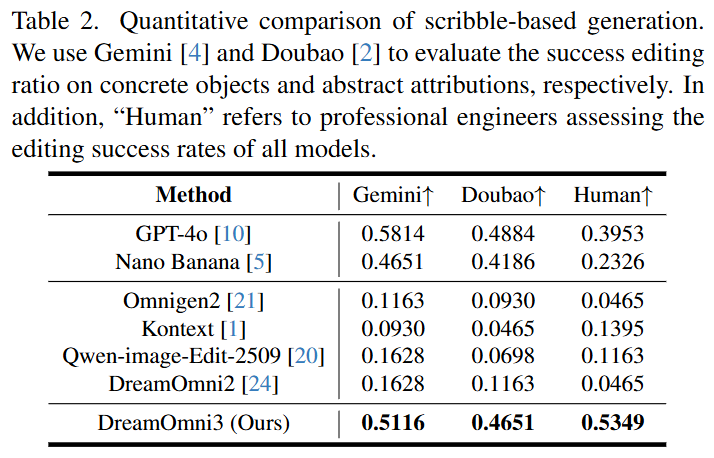
Qualitative Results: As shown in Figure 4 below, open-source models often retain scribbles in their outputs, while DreamOmni3 can generate natural and instruction-compliant images. 
Ablation Experiments
Joint Input: As shown in Table 3 below, four schemes are compared. The results indicate that training with our dataset and incorporating joint input (Scheme 4) significantly improves editing tasks, as scribbles obscure source image information, and joint input ensures pixel-level consistency. 
Index and Position Encoding: As shown in Table 4 below, using the same index and position encoding for both the source image and scribble image yields the best results. This facilitates pixel-level alignment and maintains index consistency with subsequent reference images. 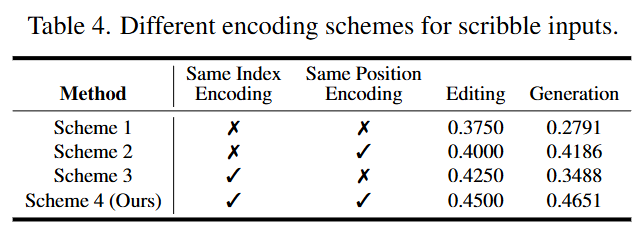
Summary
Current unified generation and editing models primarily perform image editing based on textual instructions. However, language often struggles to accurately describe editing locations and capture all details in user intent. To enhance this capability, this work proposes two tasks: scribble-based editing and generation, allowing users to simply use a brush for editing in a graphical user interface (GUI). This approach combines language, image, and scribble instructions, offering higher flexibility.
On this basis, DreamOmni3 is introduced, addressing the challenge of limited training data. Using DreamOmni2 data, this work develops a Referseg-based data creation scheme, generating high-quality, precise datasets integrating scribble, text, and image instructions.
Furthermore, this work addresses issues with the model framework, as binary masks fail to meet complex real-world demands. When multiple masks exist, they are difficult to distinguish and describe linguistically. To solve this, this work proposes a scribble-based method, easily distinguishing different masks through brush colors, enabling the handling of any number of masks. Since scribbles may obscure some image details, this work introduces a joint input scheme, simultaneously feeding the original image and the scribbled image into the model. This work further optimizes the scheme by using the same index and position encoding to preserve details while maintaining accurate editing capabilities.
References
[1] DreamOmni3: Scribble-based Editing and Generation
-
![]()
Apple Slashes Prices, Xiaomi Holds Clearance Sale, Huawei Surprises: Smartphone Titans Clash in 'Three Kingdoms Showdown' at 618 Shopping Festival
-
![]()
Can Huang Renxun’s Last-Minute China Trip Ease NVIDIA’s Growing Concerns?
-
![]()
Li Jian's Vision, Honor's Reality
-
![]()
OpenAI and Anthropic Clash on Wall Street as Financial Giants Take Sides
-
![]()
AMD's AI Developer Day: Computing Power Competition Enters the Era of Local Agents
-
Masayoshi Son Bets $60 Billion on OpenAI, SoftBank Panics Inside
-
![]()
Insta360's Profit Puzzle: Liu Jingkang Unveils the Strategy
-
Baseus Caught in the 'Middle Zone': Struggles Against OEM and Unbranded Competitors





