Replicate the 'Matrix' bullet time! SpaceTimePilot: Transform videos into controllable 4D games with rewind/speed change/camera movement at your command
 01/06 2026
01/06 2026
 424
424
Interpretation: AI Generates the Future 
Key Highlights
First video diffusion model to achieve joint spatial and temporal control: SpaceTimePilot is the first model capable of joint spatial (camera perspective) and temporal (motion sequence) control over dynamic scenes from a single monocular video.
Introduces animation time embedding mechanism: Proposes an effective animation time embedding mechanism that explicitly controls the motion sequence of output videos, enabling fine-grained temporal manipulation such as slow motion, reverse playback, and bullet time.
Proposes time warping training scheme: Addresses the lack of paired video datasets with continuous temporal variations by designing a simple yet effective time warping training scheme that simulates diverse temporal differences through augmenting existing multi-view datasets, aiding model learning of temporal control and spatial-temporal decoupling.
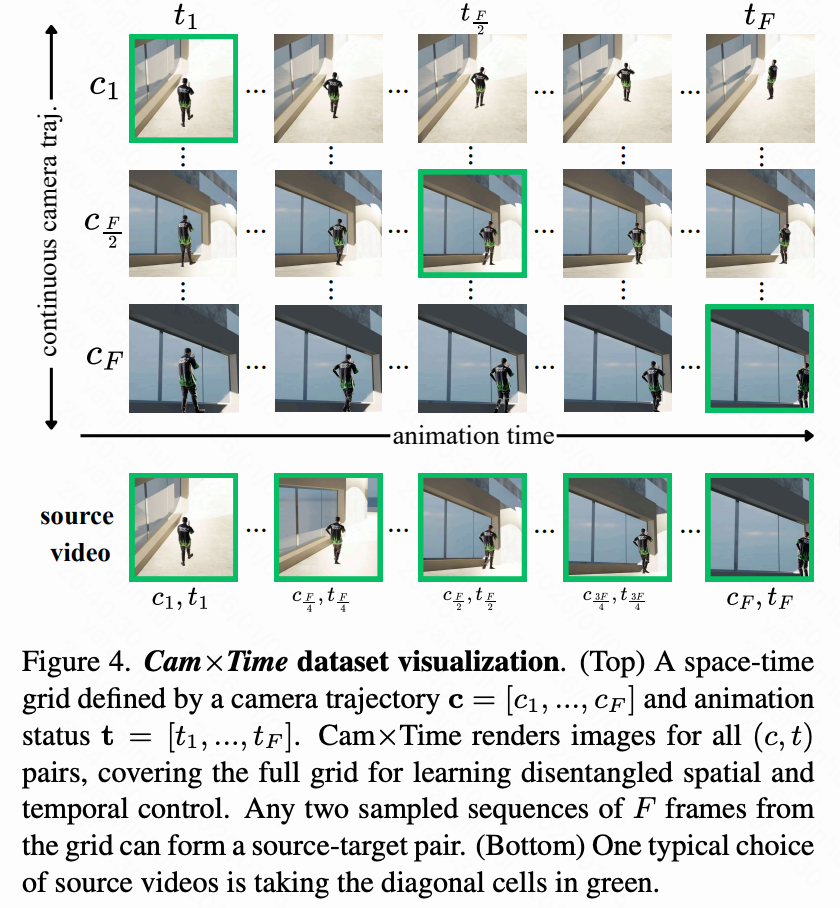
Constructs Cam×Time synthetic dataset: Builds the first synthetic, spatially-temporally fully-covered rendering dataset, Cam×Time, which provides completely free spatial-temporal video trajectories in scenes, offering critical supervision for model learning of decoupled 4D representations through dense spatial-temporal sampling.
Improves camera conditioning mechanism: Introduces an improved camera conditioning mechanism that allows camera changes from the first frame and incorporates source-aware camera control, jointly injecting source and target video camera poses into the diffusion model, significantly enhancing camera control precision and robustness.
Supports longer video generation: By adopting a simple autoregressive video generation strategy, SpaceTimePilot can generate arbitrarily long continuous video clips, enabling flexible multi-round generation and supporting exploration across extended spatial-temporal trajectories.
Summary Overview
Problems Addressed
Lack of fully decoupled control over spatial variations (camera perspectives) and temporal evolution (scene motion) in dynamic scenes.
4D reconstruction under novel viewpoints often exhibits artifacts and limited rendering quality. Current video diffusion models, despite progress in spatial viewpoint control, cannot freely navigate scenes in both space and time, i.e., lack complete 4D exploration capabilities. Training models that can handle multiple temporal playback forms and camera motions simultaneously is challenging with existing datasets due to insufficient temporal variation coverage or inability to provide paired videos of the same dynamic scene with continuous temporal changes.
Proposed Solution
This paper introduces SpaceTimePilot, a video diffusion model designed to address the aforementioned issues through:
Introducing a new 'animation time' concept that decouples the temporal state of scene dynamics from camera control, enabling natural decoupling of spatial and temporal control. Designing an effective animation time embedding mechanism for explicit control over the motion sequence of output videos during the diffusion process.
Proposing a simple yet effective time warping training scheme that simulates temporal differences by reusing existing multi-view datasets to address the lack of suitable training data.
Introducing a synthetic, spatially-temporally fully-covered rendering dataset named Cam×Time, which provides completely free spatial-temporal video trajectories in a scene to enhance control precision.
Improving the camera conditioning mechanism to allow camera changes from the first frame and using source-aware camera conditioning to jointly inject source and target video camera poses into the diffusion model, providing explicit geometric context.
Adopting an autoregressive video generation strategy to generate longer video clips conditioned on previously generated clips and the source video, supporting longer video sequences.
Applied Technologies
Latent video diffusion backbone: Adopts an architecture similar to modern text-to-video foundation models, incorporating a 3D variational autoencoder (VAE) for latent compression and a Transformer-based denoising model (DiT) operating on multimodal tokens.
Animation time embedding mechanism: Encodes and injects temporal control parameters into the diffusion model via sinusoidal time embeddings and 1D convolutional layers, enabling explicit control over video motion sequences.
Improved camera conditioning: Draws inspiration from ReCamMaster and improves upon it by encoding camera trajectories via E_cam(c) and further integrating source-aware camera conditioning to jointly inject source and target video camera poses into the model.
Time warping training scheme: Simulates diverse temporal variations by applying time warping operations such as reverse, acceleration, freezing, segmented slow motion, and zigzag motion to existing multi-view video datasets.
Synthetic dataset Cam×Time: Rendered in Blender, providing dense and systematically covered training data through exhaustive sampling of the camera-time grid.
Achieved Effects
Unified spatial-temporal control: Enables unified control over camera and time in a single diffusion model, generating continuous and coherent videos along arbitrary spatial-temporal trajectories.
Decoupled spatial and temporal exploration: Allows independent changes to camera perspectives and motion sequences, enabling continuous and arbitrary exploration of dynamic scenes in both space and time.
Flexible motion sequence retiming: Generates new videos with retimed motion sequences, including slow motion, reverse motion, and bullet time.
Precise camera trajectory control: Accurately controls camera motion according to given camera trajectories.
Strong performance: Demonstrates clear spatial-temporal decoupling on both real-world and synthetic data, achieving robust results compared to existing work.
Supports longer video generation: Generates longer and more coherent videos through autoregressive inference schemes, enabling viewpoint changes beyond the input video, such as rotating to the rear of an object or switching from a low angle to a high-altitude bird's-eye view while maintaining visual and motion coherence.
Architectural Approach
The proposed method, SpaceTimePilot, achieves effects such as bullet time and retimed playback from new viewpoints by decoupling spatial and temporal factors during the generation process, as illustrated in Figure 1 above.
Decoupling Space and Time
This paper achieves spatial-temporal decoupling through a dual approach: dedicated temporal representations and specialized datasets.
Temporal Representations
Recent video diffusion models include positional embeddings for latent frame indices, such as RoPE(). However, this paper finds that using RoPE() for temporal control is ineffective as it interferes with camera signals: RoPE() typically restricts both time and camera motion simultaneously. To address spatial-temporal decoupling, this paper introduces a dedicated temporal control parameter . By manipulating , this paper can control the temporal progression of synthesized videos . For example, setting to a constant locks to a specific timestamp in , while reversing frame indices plays backward.
Time Embedding. To inject temporal control into the diffusion model, this paper analyzes several methods. First, time can be encoded like frame indices using RoPE embeddings. However, this paper finds it less suitable for temporal control. Instead, sinusoidal time embeddings applied at the latent frame level are adopted, providing stable continuous representations of each frame's temporal position and offering a favorable trade-off between precision and stability. This paper further observes that each latent frame corresponds to a continuous time block and proposes using embeddings of raw frame indices to support finer temporal control granularity. To achieve this, a time encoding method is introduced, where . First, sinusoidal time embeddings are computed to represent the time sequence, , , where . Next, two 1D convolutional layers are applied to project these embeddings into latent frame space progressively, . Finally, these temporal features are added to camera features and video token embeddings, updating Equation (1) as follows:
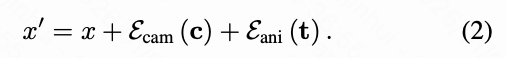
In the following, this paper compares the proposed method with alternative conditioning strategies, such as using sinusoidal embeddings where is directly defined in , and using MLPs instead of 1D convolutions for compression. This paper qualitatively and quantitatively demonstrates the advantages of the proposed method.
Dataset
To enable temporal manipulation in the proposed method, paired training data containing time remapping examples is required. Achieving spatial-temporal decoupling further necessitates data containing camera and temporal control examples. To the best of this paper's knowledge, no publicly available datasets currently meet these requirements. Only a few prior works, such as 4DiM and CAT4D, attempt to address spatial-temporal decoupling. A common strategy is joint training on static scene datasets and multi-view video datasets. The limited control variability in these datasets leads to confusion between temporal evolution and spatial motion, resulting in entangled or unstable behavior. This paper addresses this limitation by augmenting existing multi-view video datasets with time warping and proposing a new synthetic dataset.
Time Warping Augmentation. This paper introduces simple augmentations to add controllable temporal variations to multi-view video datasets. During training, given a source video and a target video , a time warping function is applied to the target sequence, generating a warped video . Source animation timestamps are uniformly sampled, . Warped timestamps introduce nonlinear temporal effects (see Figure 3, top b-e): (i) reverse, (ii) acceleration, (iii) freezing, (iv) segmented slow motion, and (v) zigzag motion, where animation repeats backward. After these augmentations, the paired video sequences differ in both camera trajectories and temporal dynamics, providing clear signals for the model to learn decoupled spatial-temporal representations.
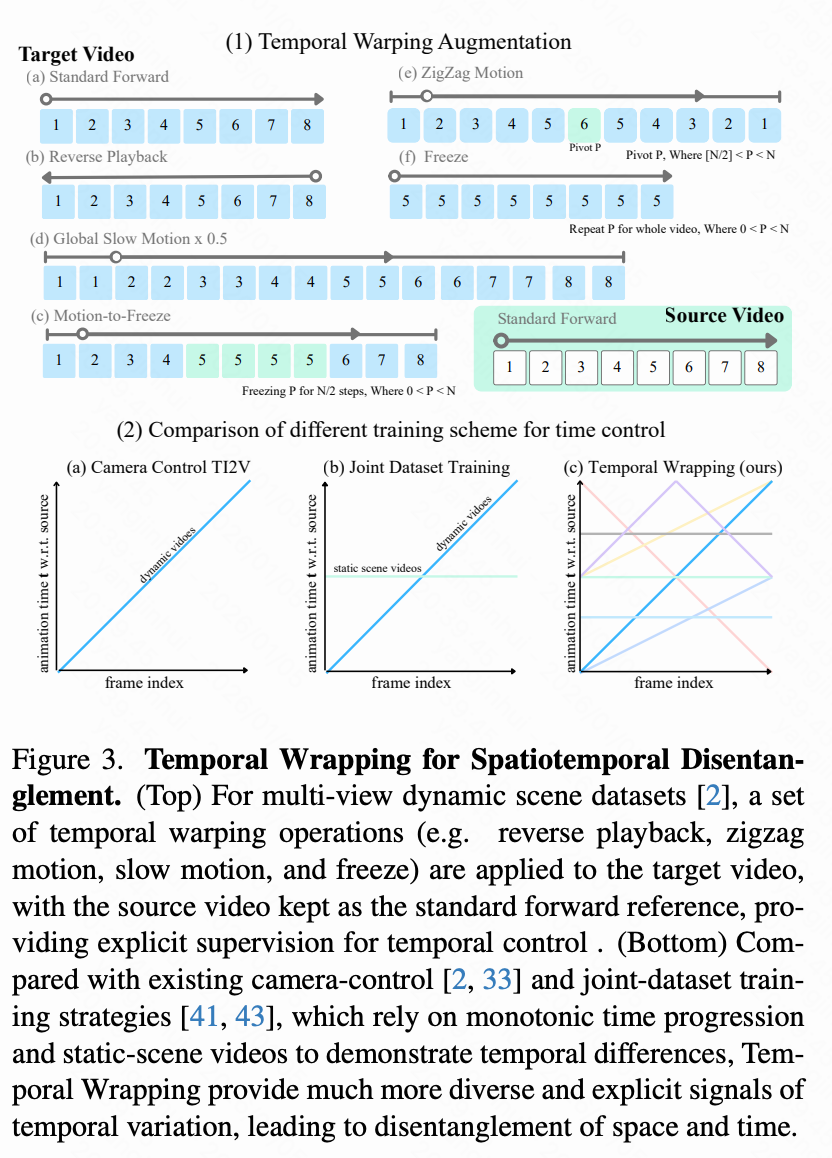
Synthetic Cam×Time Dataset for Precise Spatial-Temporal Control. While time warping augmentation encourages strong decoupling between spatial and temporal factors, achieving fine-grained and continuous control—i.e., smoothly and precisely adjusting temporal dynamics—benefits from a dataset systematically covering both dimensions. To this end, this paper constructs Cam×Time, a new synthetic spatial-temporal dataset rendered in Blender. Given a camera trajectory and an animated subject, Cam×Time exhaustively samples the camera-time grid, capturing each dynamic scene across different camera perspectives and temporal state combinations , as shown in Figure 4 below. The source video is obtained by sampling the diagonal frames of the dense grid (Figure 4, bottom), while the target video is obtained through more free-form continuous sequence sampling. This paper compares Cam×Time with existing datasets in Table 1 below. While real videos with complex camera path annotations, such as [23, 32, 53], exist, they either do not provide temporally synchronized video pairs or only offer static scene pairs. Synthetic multi-view video datasets provide dynamic video pairs but do not allow training temporal control. In contrast, Cam×Time enables fine-grained manipulation of camera motion and temporal dynamics, achieving bullet time effects, motion stabilization, and flexible control combinations. This paper designates a portion of Cam×Time as a test set, aiming to use it as a benchmark for controllable video generation. This paper will release it to support future research on fine-grained spatial-temporal modeling.

Precise Camera Conditioning
This paper's goal is to achieve complete camera trajectory control in target videos. In contrast, previous Novel View Synthesis methods assume that the first frames of the source and target videos are identical and that the target camera trajectory is defined relative to it. This stems from two limitations. First, existing methods ignore the source video trajectory, leading to poor source features computed using the target trajectory to maintain consistency:
Second, they are trained on datasets where the first frames of the source and target videos are always identical. The latter limitation is addressed in this paper's training dataset design. To overcome the former, this paper designs a source-aware camera conditioning approach. This paper uses a pre-trained pose estimator to estimate the camera poses of the source and target videos and jointly injects them into the diffusion model to provide explicit geometric context. Thus, Equation (2) is extended as:
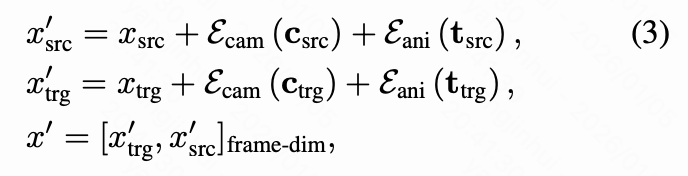
where represents the input to the DiT model, which is the concatenation of target and source tokens along the frame dimension. This formulation provides the model with source and target camera context, enabling spatially consistent generation and precise control over camera trajectories.
Support for longer video clips
Finally, to demonstrate the full potential of our camera and time control, we employ a simple autoregressive video generation strategy, generating each new clip conditioned on the previously generated clip and the source video , to create longer videos.
To enable this during inference, we need to extend our training scenario to support conditioning on two videos, with one serving as and the other as . The source video is directly taken from multi-view datasets or our synthetic dataset, as described earlier. is constructed similarly to —using time warping augmentation or sampling from the dense spatiotemporal grid of our synthetic dataset. When applying time warping, and may come from the same or different multi-view sequences representing the same time interval. To maintain full control flexibility, we do not enforce any other explicit associations between and beyond specifying the camera parameters relative to the selected source video frame.
Note that not constraining the source and target videos to share the same starting frame (as mentioned earlier) is crucial for achieving flexible camera control in longer sequences. For example, this design enables extended bullet-time effects: we can first generate rotations up to 45° around a selected point (), then continue from 45° to 90° (). Conditioning on two consecutive source clips allows the model to leverage information from newly generated viewpoints. In the bullet-time example, conditioning on the previously generated video enables the model to integrate information from all newly synthesized viewpoints, rather than merely relying on the viewpoints at corresponding moments in the source video.
Experimental Comparison with State-of-the-Art Baselines: Temporal Control Evaluation
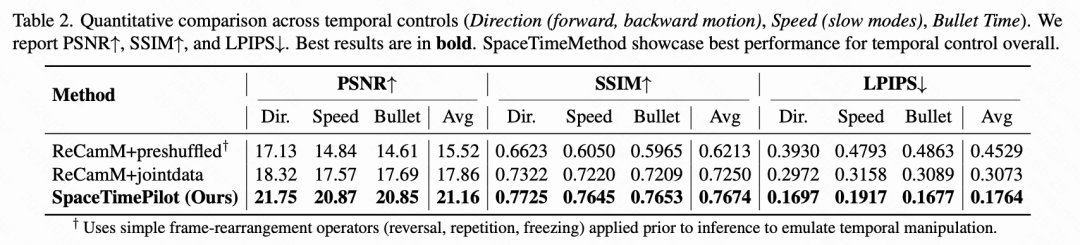
First, we evaluate the model’s temporal reordering capability. To exclude errors caused by camera control, we condition SpaceTimePilot at a fixed camera pose, varying only the temporal control signal. Experiments are conducted on the unreleased Cam×Time test set, which contains 50 scenes rendered with dense full-grid trajectories that can be retimed into arbitrary temporal sequences. For each test case, we use a source video with a moving camera but set the target camera trajectory to the first-frame pose. We then apply a series of temporal control signals, including reverse, bullet time, zigzag, slow motion, and normal playback, to synthesize corresponding retimed outputs. Since we possess ground-truth frames for all temporal configurations, we report perceptual losses: PSNR, SSIM, and LPIPS.
We consider two baselines: (1) ReCamM+preshuffled: the original ReCamMaster combined with input reshuffling; (2) ReCamM+jointdata: following [41, 43], we train ReCamMaster using additional static scene datasets, such as [18, 53], which provide only a single temporal pattern.
While frame shuffling may succeed in simple scenarios, it fails to decouple camera and temporal control. As shown in Table 2 below, this approach exhibits the weakest temporal controllability. Although incorporating static scene datasets improves performance, especially in the bullet-time category, reliance on a single temporal control mode remains insufficient for robust temporal consistency. In contrast, SpaceTimePilot consistently outperforms all baselines across all temporal configurations.
Visual Quality Assessment
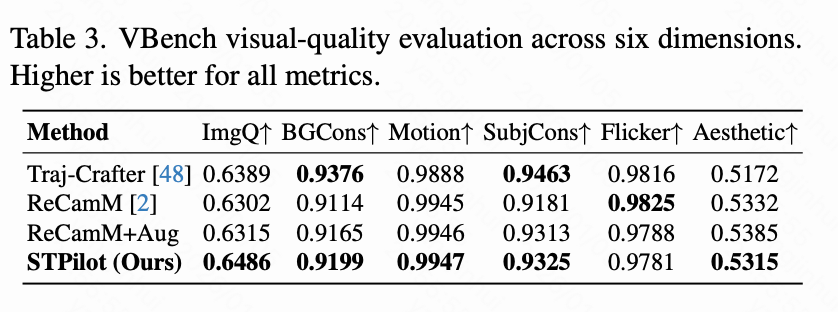
Next, we evaluate the perceptual realism of our 1,800 generated videos using VBench. We report all standard visual quality metrics to provide a comprehensive assessment of generation fidelity. As shown in Table 3 below, our model achieves visual quality comparable to the baselines.
Camera Control Evaluation
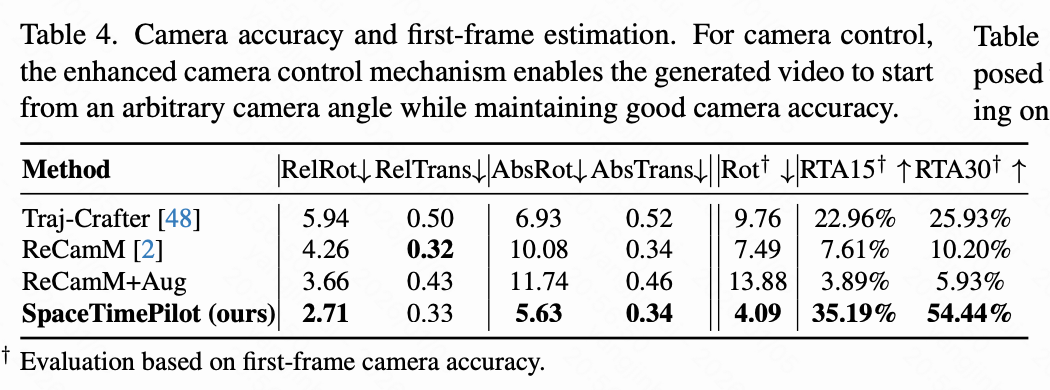
Finally, we assess the effectiveness of the camera control mechanism detailed earlier. Unlike the temporal reordering evaluation above, which relies on synthetic ground-truth videos, we construct a real-world 90-video evaluation set composed of OpenVideoHD, covering various dynamic human and object motions. Each method is evaluated under 20 camera trajectories: 10 starting from the same initial pose as the source video and 10 from different initial poses, generating a total of 1,800 videos. We apply SpatialTracker-v2 to recover camera poses from the generated videos and compare them with the corresponding input camera poses. To ensure consistent scaling, we align the magnitudes of the first two camera positions. Trajectory accuracy is quantified using RotErr and TransErr according to [8], adopting two protocols: (1) evaluating relative to the original trajectory defined by the first frame (relative protocol, RelRot, RelTrans), and (2) evaluating after aligning with the estimated pose of the first frame (absolute protocol, AbsRot, AbsTrans). Specifically, we transform the recovered original trajectory by multiplying it with the relative pose between the generated frame and the source first frame, estimated by DUSt3R. We also compare this DUSt3R pose with the initial pose of the target trajectory and report RotErr, RTA@15, and RTA@30, as translation magnitude is scale-ambiguous.
To measure only the effect of source camera conditioning, we consider the original ReCamMaster (ReCamM) and two variants. Since ReCamMaster was originally trained on datasets where the first frame of the source and target videos is identical, the model always replicates the first frame regardless of the input camera pose. For fairness, we retrain ReCamMaster with more data augmentation to include non-identical starting frames, denoted as ReCamM+Aug. Next, we additionally condition the model on the source camera according to Equation 3, denoted as ReCamM+Aug+. Finally, we also report the results of TrajectoryCrafter.
In Table 4 below, we observe that the absolute protocol consistently yields higher errors, as trajectories must match not only the overall shape (relative protocol) but also be correctly aligned in position and orientation. Interestingly, ReCamM+Aug produces higher errors than the original ReCamM, while incorporating the source camera yields the best overall performance. This suggests that without an explicit reference , exposure to more augmented videos with different starting frames instead confuses the model. The newly introduced source video trajectory conditioning signal achieves significantly better camera control accuracy across all metrics, more reliable first-frame alignment, and more faithful adherence to the complete trajectory than all baselines.
Qualitative Results
Beyond quantitative evaluation, we demonstrate the advantages of SpaceTimePilot through visual examples. As shown in Figure 6 below, only our method correctly synthesizes camera motion (red box) and animation temporal states (green box). While ReCamMaster handles camera control well, it cannot modify temporal states, such as achieving reverse playback. In contrast, TrajectoryCrafter is confused by reverse frame shuffling, causing the camera pose of the last source frame (blue box) to erroneously appear in the first frame of the generated video. More visual results are shown in Figure 5 below.


Ablation Study
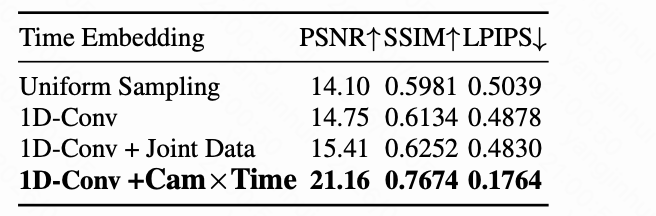
To validate the effectiveness of the proposed temporal embedding module, as shown in Table 5 below, we follow the temporal control evaluation setup above and compare our 1D convolutional temporal embedding with several variants and alternatives discussed earlier: (1) Uniform Sampling: embedding 81 frames uniformly sampled into a 21-frame sequence, equivalent to adopting sinusoidal embedding at the latent frame level; (2) 1D-Conv: using a 1D convolutional layer to compress from to and training with ReCamMaster and SynCamMaster datasets. (3) 1D-Conv+jointdata: Line 2, but additionally including static scene datasets. (4) 1D-Conv (Ours): Line 2, but incorporating the proposed Cam×Time. We observe that the 1D convolutional method, which learns a compact representation by compressing fine-grained -dimensional embeddings into a -dimensional space, significantly outperforms directly constructing sinusoidal embeddings at the coarse level. Incorporating static scene datasets brings only limited improvements, likely due to their limited temporal control modes. In contrast, using the proposed Cam×Time consistently yields the largest gains across all three metrics, confirming the effectiveness of our newly introduced dataset. Furthermore, as shown in Figure 7 below, we present a visual comparison of bullet-time results using uniform sampling and an MLP instead of 1D convolutional compression for the temporal control signal. Uniform sampling produces noticeable artifacts, and the MLP compressor leads to abrupt camera motion, whereas 1D convolution effectively locks the animation time and achieves smooth camera motion.

Conclusion
SpaceTimePilot is the first video diffusion model to provide fully decoupled spatial and temporal control, enabling 4D spatiotemporal exploration from a single monocular video. Our approach introduces a novel “animation time” representation and incorporates a source-aware camera control mechanism that leverages both source and target poses. This is supported by synthetic Cam×Time and time warping training schemes, which provide dense spatiotemporal supervision. These components allow for precise camera and temporal manipulation, arbitrary initial poses, and flexible multi-round generation. In extensive experiments, SpaceTimePilot consistently surpasses state-of-the-art baselines, significantly improving camera control accuracy and reliably executing complex retiming effects, such as reverse playback, slow motion, and bullet time.
References
[1] SpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
-
![]()
Apple Slashes Prices, Xiaomi Holds Clearance Sale, Huawei Surprises: Smartphone Titans Clash in 'Three Kingdoms Showdown' at 618 Shopping Festival
-
![]()
Can Huang Renxun’s Last-Minute China Trip Ease NVIDIA’s Growing Concerns?
-
![]()
Li Jian's Vision, Honor's Reality
-
![]()
OpenAI and Anthropic Clash on Wall Street as Financial Giants Take Sides
-
![]()
AMD's AI Developer Day: Computing Power Competition Enters the Era of Local Agents
-
Masayoshi Son Bets $60 Billion on OpenAI, SoftBank Panics Inside
-
![]()
Insta360's Profit Puzzle: Liu Jingkang Unveils the Strategy
-
Baseus Caught in the 'Middle Zone': Struggles Against OEM and Unbranded Competitors





