Securing 6 SOTA Awards with Strength! UniCorn Bridges Understanding and Generation, Achieves Multimodal Cognitive Reconstruction Through 'Introspection'
 01/09 2026
01/09 2026
 491
491
Interpretation: The Future of AI Generation

Key Highlights
Conduction Aphasia: Formalizes the phenomenon of 'strong understanding but weak generation' in unified multimodal models as 'conduction aphasia.'
UniCorn Framework: A self-improvement framework that requires no external data or teacher supervision. It divides a single model into three roles: Proposer, Solver, and Judge, achieving capability enhancement through self-play. Demonstrates comprehensive SOTA performance, consistently outperforming previous comparable methods. Achieves SOTA on TIIF (73.8), DPG (86.8), CompBench (88.5), and UniCycle (46.5).
UniCycle Benchmark: Introduces a new benchmark based on text-image-text (T2I2T) cycle consistency to validate the recovery of multimodal alignment.
Problems Addressed
Mismatch Between Understanding and Generation: Existing unified multimodal models (UMMs) excel in cross-modal understanding but struggle to leverage this internal knowledge for high-quality generation (i.e., 'conduction aphasia').
Dependence on External Supervision: Traditional enhancement methods often rely on expensive externally annotated data or powerful teacher models for distillation, limiting model scalability and autonomous evolution capabilities.
Proposed Solution
Self Multi-Agent Sampling: Leverages the UMM's contextual learning ability to assign three roles to the model:
Proposer: Generates challenging prompts.
Solver: Generates images based on the prompts.
Judge: Evaluates generation quality and provides feedback.
Cognitive Pattern Reconstruction: Transforms interaction trajectories from self-play into training data:
Caption: Maps generated images back to text, solidifying semantic grounding.
Judgement: Learns to predict scores, calibrating internal value systems.
Reflection: Learns to convert 'failed' samples into 'successful' ones, internalizing self-correction mechanisms.
Applied Techniques
Multi-role Self-play: Enables collaboration among different roles within the same parameter space.
Rejection Sampling: Utilizes scores from the internal Judge to filter high-quality data.
Chain-of-Thought and Reflexion: Introduces reasoning steps during generation and evaluation, constructing reflection trajectories by contrasting positive and negative samples.
Cycle Consistency Evaluation: Quantifies information retention through T2I2T (text-image-text) cycles.
Achieved Results
SOTA Performance: UniCorn achieves state-of-the-art (SOTA) performance on six general image generation benchmarks, including TIIF (73.8), DPG (86.8), CompBench (88.5), and UniCycle (46.5).
Significant Improvements: +5.0 improvement on WISE and +6.5 on OneIG compared to the base model.
Data Efficiency: Surpasses models trained on 30k GPT-4o-distilled data (IRG) using only 5k self-generated data, demonstrating the scalability of fully self-supervised improvement.
 Figure 2: UniCorn Visualization Results Methodology
Figure 2: UniCorn Visualization Results Methodology
The motivation is elaborated by first analyzing the mismatch between generation and understanding capabilities in UMMs. Based on these observations, UniCorn is proposed—a simple yet elegant post-training framework that achieves self-improvement without any external annotated data or teacher models.
Motivation
This is analogous to a child who associates the word 'apple' with the fruit and can spontaneously name it upon seeing one. Cognitive symmetry enables bidirectional mapping between internal concepts and external expressions. This alignment resembles escaping Plato's cave: true intelligence must transcend observation of surface data and grasp the reciprocal relationship between appearances and their underlying sources.
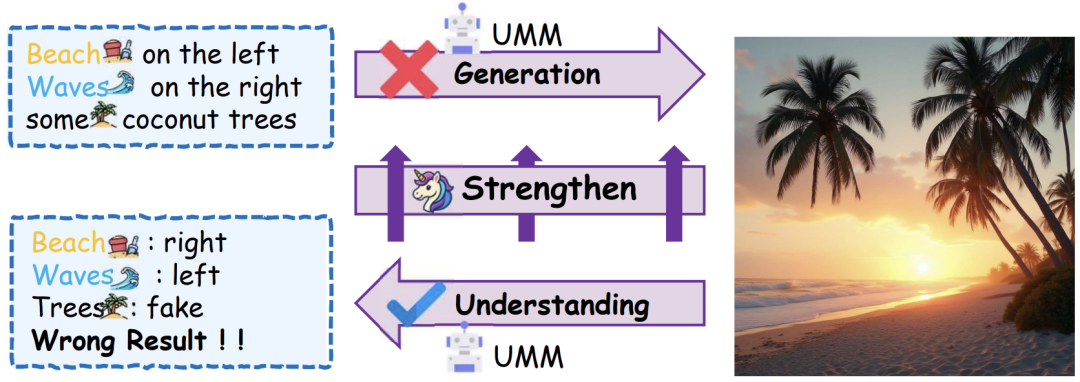 Figure 1: Motivation for UniCorn. UMMs often exhibit an understanding gap: they can accurately comprehend and critique errors in images but fail to generate the same scenes correctly. This conduction aphasia motivates our framework to leverage the model's exceptional internal understanding to strengthen and refine its generation capabilities through independent feedback.
Figure 1: Motivation for UniCorn. UMMs often exhibit an understanding gap: they can accurately comprehend and critique errors in images but fail to generate the same scenes correctly. This conduction aphasia motivates our framework to leverage the model's exceptional internal understanding to strengthen and refine its generation capabilities through independent feedback.
However, current UMMs suffer from functional deficits akin to conduction aphasia: while models demonstrate profound understanding, their generative performance remains fragmented, unable to produce what they inherently comprehend. Bridging this gap is crucial; without harmonizing the two processes, the model remains a 'passive observer,' capable of passive symbol grounding but unable to utilize them. Thus, mastering the synergy between understanding and generation is not merely a functional upgrade but a critical step toward achieving the cognitive integrity required for AGI.
On one hand, as shown in Figure 3, current UMMs exhibit strong perceptual and understanding capabilities. Specifically, when serving as a reward model for text-to-image (T2I) generation, UMMs demonstrate sophisticated mastery of cross-modal semantics. This indicates that the model has internalized a robust 'world model' and possesses the latent knowledge required to discern high-quality visual-text alignment.
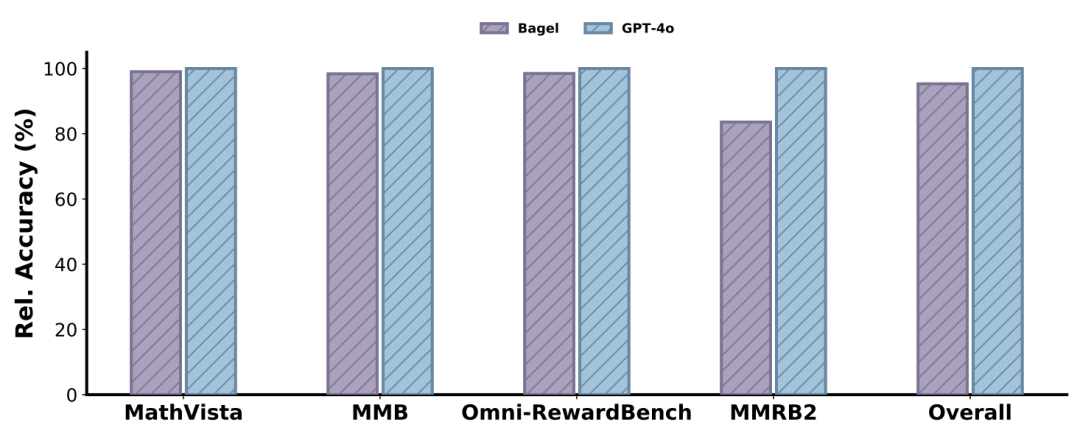 Figure 3: Results of BAGEL and GPT-4o on four understanding benchmarks. For Omini-RewardBench and MMRB2, T2I tasks were evaluated. Performance was standardized using GPT-4 results for better visualization.
Figure 3: Results of BAGEL and GPT-4o on four understanding benchmarks. For Omini-RewardBench and MMRB2, T2I tasks were evaluated. Performance was standardized using GPT-4 results for better visualization.
On the other hand, the model's generative capabilities remain significantly constrained, primarily due to its failure to bridge the gap between internal recognition and active synthesis. This functional separation means that the UMM's sophisticated internal understanding remains a 'silent passenger' during generation, unable to inform or correct its outputs. Based on this observation, the key insight of this paper is that the UMM's powerful understanding capabilities can be repurposed as an autonomous supervisory signal to guide its generative behavior. By converting latent explanatory depth into explicit guidance, this paper facilitates tighter coupling between the two processes, ultimately restoring the cognitive symmetry necessary for truly integrated multimodal intelligence.
Problem Definition
This paper investigates UMMs that process interleaved image-text inputs and outputs. UMMs are formalized as a policy that maps a multimodal input sequence to an interleaved multimodal output sequence . This unified input-output formulation supports image-to-text (I2T) understanding and text-to-image (T2I) generation. This paper operationalizes understanding as I2T and generation as T2I, leveraging the model's stronger I2T understanding capabilities to supervise and improve its weaker T2I generation capabilities.
UniCorn
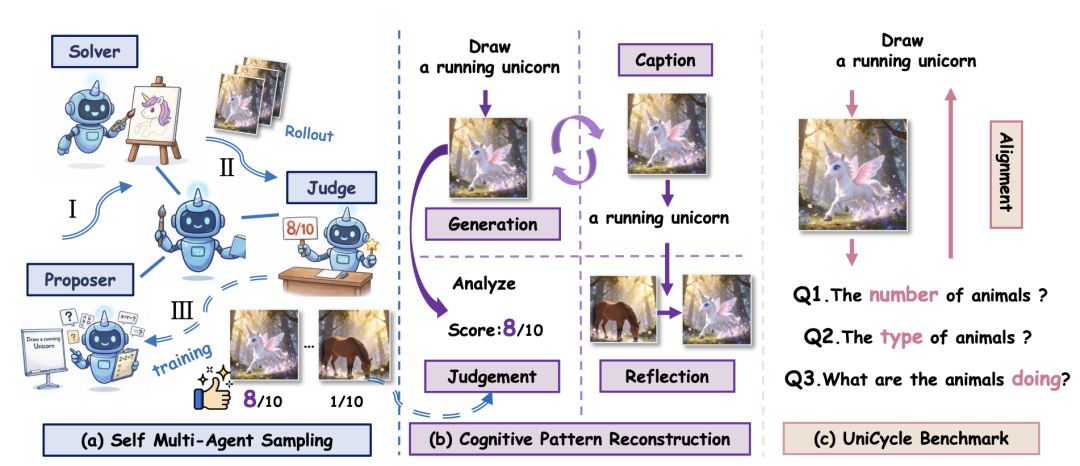 Figure 4: Overview of the UniCorn Framework. (a) Illustrates self-multi-agent collaboration for high-quality data sampling. (b) Details the cognitive pattern reconstruction process, which reorganizes data to facilitate robust and efficient learning. (c) Proposes the UniCycle benchmark evaluation to verify whether the model can accurately reconstruct key textual information from its own generated content.
Figure 4: Overview of the UniCorn Framework. (a) Illustrates self-multi-agent collaboration for high-quality data sampling. (b) Details the cognitive pattern reconstruction process, which reorganizes data to facilitate robust and efficient learning. (c) Proposes the UniCycle benchmark evaluation to verify whether the model can accurately reconstruct key textual information from its own generated content.
UniCorn operates through two core stages: Self Multi-Agent Sampling and Cognitive Pattern Reconstruction (CPR). First, the UMM simultaneously assumes three roles: Proposer, Solver, and Judge, simulating a collaborative cycle. Then, the CPR stage reconstructs these raw interactions into three training modes: caption, judgement, and reflection, which are combined with high-quality self-sampled T2I generation data for post-training. Critically, the entire process is fully autonomous, requiring no external teacher models or human-annotated data.
Stage 1: Self Multi-Agent Sampling
LLMs are naturally suited for self-play in multi-task settings. For UMMs, interleaved multimodal inputs and functional diversity enable prompting, generation, and judgment to coexist within a shared model, achieving conditioned role behavior under different prompts. This paper leverages this property to functionalize a single UMM as collaborative roles, bridging the gap between understanding and generation through internal synergy.
Proposer: The Proposer aims to generate a diverse and challenging set of prompts for the unified multimodal model, subsequently used to generate training images. To achieve this, inspired by LAION-5B and COYO-700M, this paper categorizes all T2I task prompts into ten categories and designs fine-grained generation rules for each. Next, this paper prompts the UMM to generate an initial batch of prompts and acts as a Judge to select the best candidates for subsequent iterations. Utilizing the LLM's strong in-context learning (ICL) capability, initial examples serve as few-shot demonstrations to guide subsequent prompt generation. To further enhance diversity, this paper introduces a dynamic seeding mechanism. After generating a predetermined number of prompts, several examples are sampled from the prompt pool for evaluation and then used to construct new demonstrations for guiding the next round of prompt generation. Compared to previous methods that directly rely on training sets or use external models to construct prompts, this approach requires no external data and generates more diverse prompts, improving generalization.
Solver: The Solver is responsible for generating diverse outputs based on the prompts proposed by the Proposer. Thus, this paper encourages the UMM to generate images under random seeds and different hyperparameters. Following DeepSeek-R1's approach, this paper performs 8 rollouts per prompt to achieve a favorable trade-off between sample quality, diversity, and computational efficiency.
Judge: The Judge scores the images generated by the Solver based on the Proposer's prompts, with these scores subsequently used for rejection sampling during training.
Previous works relied on keyword-based heuristic reward functions or powerful external models to provide dense reward maps. Such reward Judges depend heavily on parameter tuning and the performance of external models, which vary across tasks, severely limiting the generalization capability of self-improvement. As shown in Figure 3, UMMs demonstrate strong reward modeling capabilities. Thus, this paper follows the widely adopted 'LLM as Judge' paradigm, formulating reward assessments for all T2I tasks using discrete scores from 0 to 10. To further improve judgment quality, this paper migrates Generation Reward Models—which have shown immense potential in LLMs—to T2I evaluation. Specifically, this paper designs task-specific scoring criteria for each category and encourages the model to explicitly articulate its reasoning process before generating final scores.
Stage 2: Cognitive Pattern Reconstruction
Through self multi-agent rejection sampling using the Proposer-Solver-Judge pipeline, this paper obtains a batch of high-quality prompt-image pairs. While these pairings reflect mappings from abstract concept spaces to high-dimensional visual manifolds, directly optimizing such cross-domain alignment remains stochastic and inefficient, often leading to mode collapse. To transcend this 'black-box' optimization, this paper draws inspiration from metacognitive theory, which identifies monitoring, evaluation, and regulation as pillars of robust learning. Based on this insight, this paper proposes a tripartite data architecture that recycles and structures neglected trajectories from the self-play loop. By replaying these latent interactions as explicit caption, judgement, and reflection modes, this paper grounds abstract concepts in visual features, provides evaluative signals, and encodes self-correction processes. This design transforms previously discarded internal 'stream of consciousness' into structured supervisory signals, fostering cognitive symmetry without external intervention.
Description (CAPTION): To establish robust semantic grounding, this paradigm ensures the model internalizes the conceptual essence of its own creations by optimizing inverse mappings. By taking the highest-scoring image as input and its original prompt as ground truth, the model learns to anchor abstract concepts within specific visual manifolds it can synthesize, thereby reinforcing bidirectional cognitive symmetry between internal concepts and external manifestations.
Judgement (JUDGEMENT): This paradigm focuses on assessment calibration to refine the model's internal value system. The model is trained to predict evaluation signals for any generated pair, formulated as . By leveraging task-specific scoring criteria and reasoning trajectories provided by the judge, the model develops a keen awareness of potential gaps between current outputs and ideal targets, providing critical diagnostic signals for stabilizing the generation process.
Reflection (REFLECTION): Inspired by Reflexion, this paradigm introduces iterative conditioning to enhance the model's self-evolutionary capacity. Utilizing multiple solver-derived derivations , this work employs judge-assigned rewards to identify quality-contrasted pairings, particularly selecting high-reward 'winning' images and low-reward 'losing' images from the same prompt. Subsequently, this work constructs reflection trajectories, formulated as , explicitly encoding transitions from suboptimal to superior states. By learning to transform low-quality manifestations into optimized counterparts , the model internalizes a self-corrective mechanism for generation errors, effectively mitigating mode collapse without external supervision.
These three data types are combined with high-quality self-sampled T2I generation data to fine-tune the UMM. Note that the entire reconstruction process is rule-based and introduces no additional complexity.
UniCycle
To assess whether internal collaboration yields genuine multimodal intelligence rather than merely task-specific performance gains, this work introduces UniCycle, a cyclic consistency benchmark measuring information preservation through text-image-text cycles. Given an instruction, UniCycle evaluates whether a unified multimodal model can recover key semantics of the instruction from its own generated image via subsequent visual understanding.
Building on TIIF, this work generates QA pairs to explore instruction-implied attributes from generated images, extending the original TIIF benchmark from T2I to Text-to-Image-to-Text (T2I2T) settings. After annotation, 1,401 TIIF-style instances were obtained, covering over a dozen task categories and spanning multiple question formats including multiple-choice, binary (yes/no), and open-ended questions.
For evaluation, given a prompt , the model first generates an image and then independently answers each question conditioned on the generated image. An external judge model assesses whether each predicted answer aligns with both the initial prompt and reference answer , producing a score for each question.
This work defines a unified metric to quantify this T2I2T consistency. Let denote the question set associated with prompt . This work defines:
where represents the judge's score for question , defined as a binary metric for non-text questions and as the proportion of correctly recovered keywords for text-type questions to enable finer-grained, continuous measurement.
Final Soft and Hard scores are obtained by averaging across all prompts.
Experiments
Experimental Setup:
Base Models: Primarily uses the BAGEL model for experiments, while also validating method generality on Janus-Pro.
Benchmarks: Covers six image generation benchmarks including TIIF, WISE, OneIG-EN, CompBench, DPG, Geneval, and understanding benchmarks MME, MMB.
Comparison Models: Includes generation-specialized models like SD3 Medium, FLUX.1 dev, and unified multimodal models like Janus-Pro, Show-o2, T2I-R1.
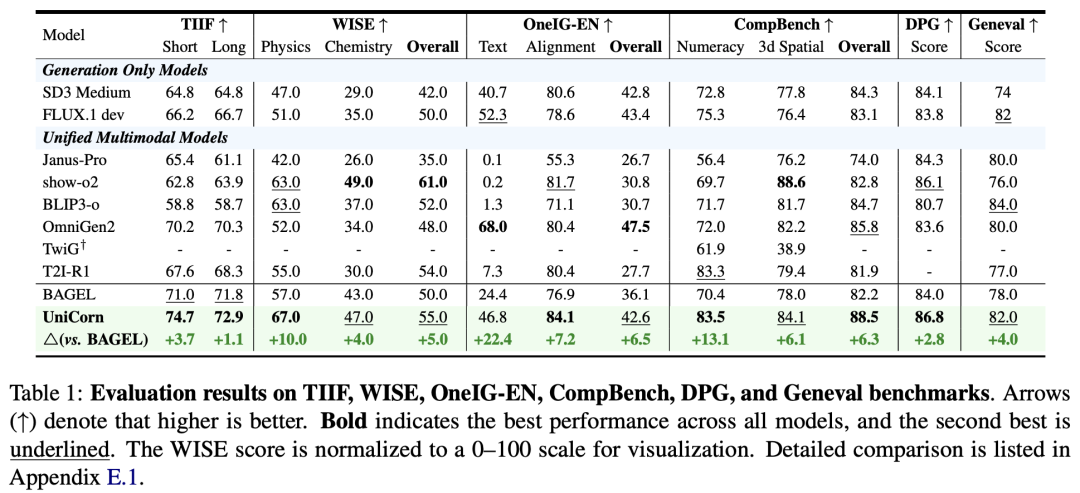
 Figure 5: Qualitative comparison between UniCorn, BAGEL, and UniCorn under different data settings. Our approach jointly balances visual aesthetics, prompt fidelity, and generated authenticity.
Figure 5: Qualitative comparison between UniCorn, BAGEL, and UniCorn under different data settings. Our approach jointly balances visual aesthetics, prompt fidelity, and generated authenticity.
Main Results:
Comprehensive Performance Improvement: UniCorn surpasses the base model BAGEL and other strong competitors across multiple benchmarks. For example, achieving 74.7 on TIIF (+3.7 vs BAGEL) and 86.8 on DPG (surpassing GPT-4o's 86.2).
UniCycle Performance: In the proposed UniCycle benchmark, UniCorn achieves the highest Hard score (46.5), significantly outperforming the base model (36.6) and others, demonstrating its advantage in unified multimodal intelligence.
Ablation Experiments:
Data Modalities: Removing cognitive modality reconstruction (C, J, R) and retaining only generated data leads to severe mode collapse (MME-P score plummet). Incorporating these modalities stabilizes generation and improves quality.
Architectural Generality: Applying the UniCorn method to Janus-Pro similarly brings significant improvements (TIIF +3.2, WISE +7.0).
Scaling Law: As self-generated data volume increases from 1k to 20k, model performance continuously improve (continuously improves). With only 5k data, UniCorn outperforms IRG models trained on 30k GPT-4o-distilled data and DALL·E 3 on TIIF, demonstrating extremely high data efficiency.
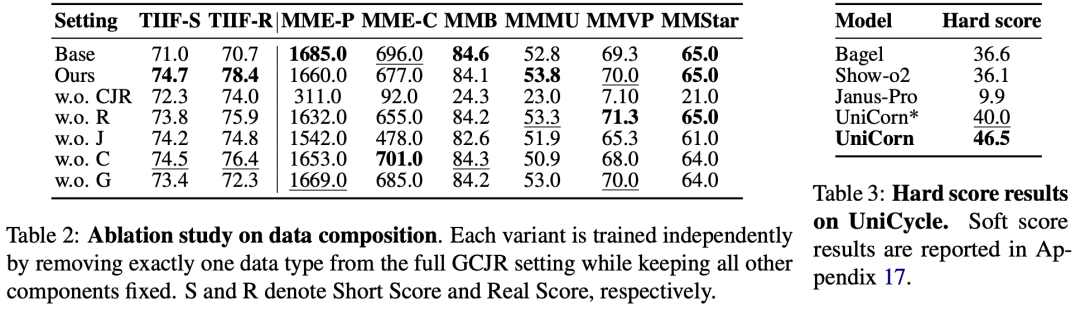
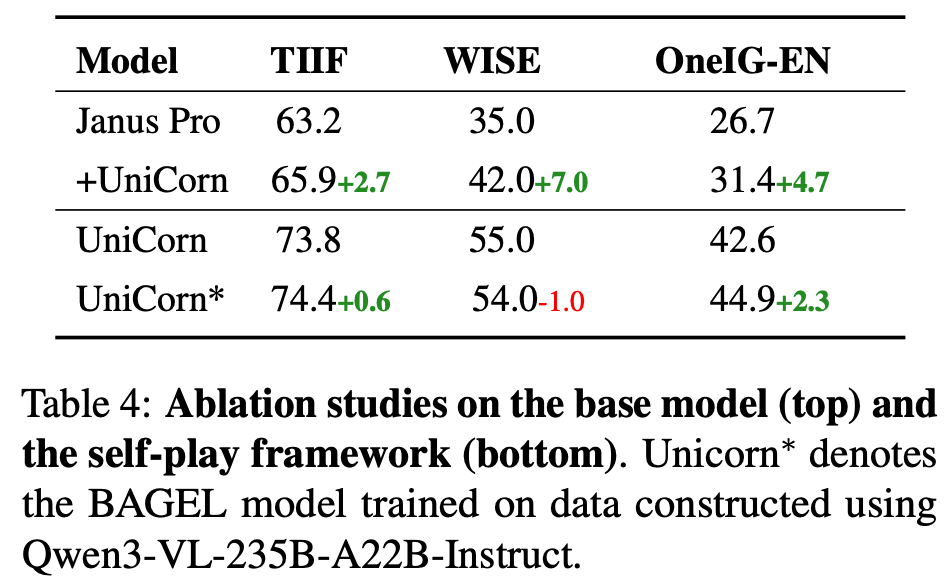
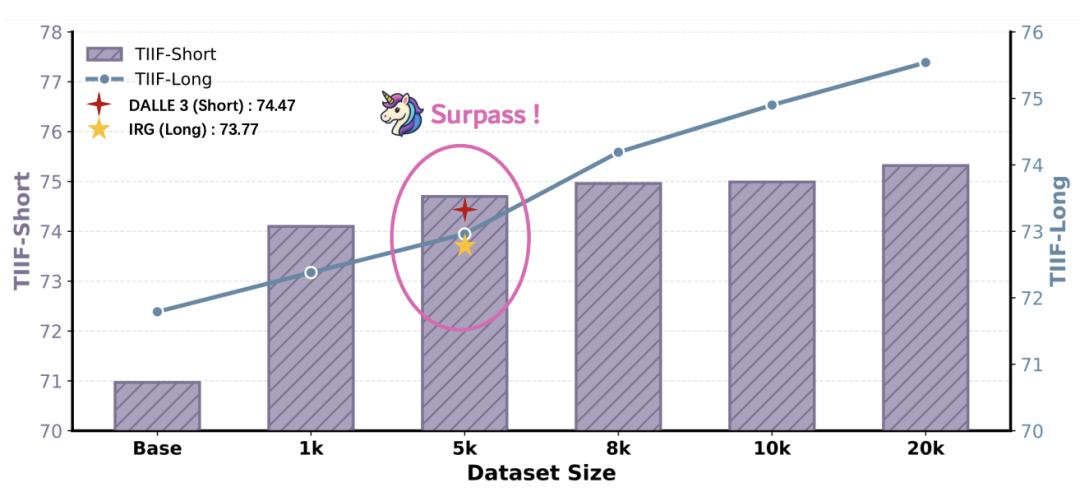 Figure 7: Data scaling results on TIIF. Scores continuously improve as dataset size expands. Notably, UniCorn surpasses many powerful models using only 5k training data.
Figure 7: Data scaling results on TIIF. Scores continuously improve as dataset size expands. Notably, UniCorn surpasses many powerful models using only 5k training data.
Analytical Conclusions:
Necessity of Self-Play: Constructing data with stronger external models (e.g., Qwen3-VL) (UniCorn*) did not yield significant benefits, even performing worse than fully self-supervised UniCorn on UniCycle, suggesting external supervision may bring disproportionate costs and lack unified coordination.
Mechanism Validation: Qualitative analysis shows UniCorn effectively balances visual aesthetics, prompt fidelity, and authenticity, bridging the gap between understanding and generation by transforming understanding into generative supervision. Conclusion
UniCorn, a self-supervised post-training framework that unifies multimodal understanding and generation within a single model through multi-agent self-play and cognitive modality reconstruction, distilling internal latent knowledge into high-quality generative signals without external supervision. Extensive experiments, including the UniCycle cyclic consistency benchmark, demonstrate significant improvements in T2I generation while preserving multimodal intelligence, highlighting self-contained feedback loops as a scalable path for unified multimodal models.
Limitations
Despite robust performance in both T2I generation and multimodal understanding, UniCorn has certain limitations. First, the current self-improvement framework operates in a single-round manner, primarily enhancing generative capabilities without significant improvements in understanding metrics. Future work intends to explore multi-round iterative self-play to promote co-evolution of both abilities. Second, the self-play mechanism requires UMM to handle prompt generation, reasoning, and judgment, inevitably introducing additional computational costs. Subsequent research plans to investigate more efficient methods to streamline this process.
References
[1] UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
-
![]()
AIS-3700 Integrated Module | Synchronous Monitoring of PM2.5 and CO₂ for a High-Quality, Healthy Cabin
-
![]()
Alibaba and Google March Together in the Agent Era
-
![]()
"National Shrimp Farming": 50 Days of AI Arbitrage Frenzy and Its Sudden End
-
![]()
NetEase’s Timeless Classics Shine in Q1, Reinforcing Global Expansion
-
From 'Construction' to 'Effective Management': Shenzhen's Innovative Approach Tackles the 'Last Mile' Challenge in Telecom Governance
-
![]()
A New Yardstick in the AI Era Measures the Path of Tech Giants
-
![]()
Daily Earnings of $650 Million Fall Short: What’s Next for NVIDIA’s Growth Trajectory?
-
![]()
Industrial Integration: Kepler Chooses a Smarter Path






