How Do Extreme Lighting Conditions Impact Autonomous Driving Cameras?
 01/12 2026
01/12 2026
 630
630
Automotive cameras play a pivotal role as perception hardware in autonomous driving systems, serving as the vehicle's "eyes" to perceive roads, pedestrians, traffic signals, and surrounding obstacles. Under optimal conditions, these cameras can capture highly detailed and clear images. However, real-world traffic environments are incredibly complex, with frequent occurrences of backlighting, low-light conditions at night, or sudden shifts in illumination.
Under such extreme lighting conditions, automotive cameras may inevitably encounter issues like overexposure, underexposure, or excessive regional contrast. These problems not only reduce the accuracy of target detection but also introduce significant errors into depth estimation algorithms, directly affecting the vehicle's ability to assess its environment.
Challenges in Backlit Scenes
Backlighting is a common scenario in daily driving, such as when a vehicle drives directly toward the sun or exits a tunnel during dusk. In these situations, light shines directly into the camera, causing intense localized brightness in the captured image while other areas appear much darker.
In high dynamic range scenes, ordinary cameras struggle to capture details in both bright and dark areas simultaneously with a single exposure. Once the contrast between light and dark exceeds the camera's processing capabilities, it must compromise between an "overly dark image" and "localized overexposure," resulting in the loss of significant image details.
Traditional cameras often suffer from severe localized overexposure or loss of detail in shadowed areas under backlighting conditions. To address this, autonomous driving cameras employ optimization strategies, with many visual systems now utilizing High Dynamic Range (HDR) imaging technology.
The core idea of HDR is to synthesize a wider-range image from multiple images with different exposure levels, preserving details in both bright and dark areas. HDR captures multiple images with varying exposures and then fuses and tone-maps them to better represent global illumination information in a single frame. This enables the camera to capture more details even under strong backlighting, providing more stable input data for subsequent target detection and depth estimation.
Another approach involves using software algorithms to enhance image contrast and texture details, often combined with deep learning models to improve target visibility under complex lighting conditions. This solution can also significantly enhance target segmentation performance in nighttime or low-light environments.
Nevertheless, backlighting remains a highly challenging scenario for camera perception. If lighting conditions change too rapidly, the system may still encounter issues. For instance, when a vehicle exits a tunnel, the camera may not have enough time to adjust exposure before the scene abruptly switches from darkness to intense brightness. The high demand for dynamic adaptability poses a severe challenge to the response speed and stability of real-time visual systems.
Difficulties in Nighttime and Low-Light Environments
Nighttime and low-light conditions present challenges opposite to those of backlighting. In these environments, insufficient light results in minimal light reaching the camera's sensor, increasing image noise and blurring details. For visual perception, the presence of noise significantly impacts performance because many deep learning-based target detection and segmentation models assume a certain level of clarity and contrast in the input images. Once image quality declines, the judgment capability of these algorithms deteriorates.
To address low-light and nighttime environments, various image enhancement technologies based on deep learning models or image processing algorithms have emerged in recent years to improve image clarity. For example, low-light image enhancement algorithms can decompose illumination and reflection components in an image, enhancing the illumination part to make details in dark areas more visible. Such technologies help subsequent recognition networks better understand image content.
Additionally, some algorithms are specifically optimized for nighttime semantic segmentation tasks, dynamically adjusting images using techniques like adaptive image filtering to enable easier recognition of scenes under varying lighting conditions by neural networks.
However, these enhancement methods still have limitations. They rely on training data, and some training sets may not cover all extreme lighting conditions, limiting the algorithm's generalization ability in real-world scenarios. Furthermore, in real-time applications, image enhancement and deep learning inference consume significant computational resources, requiring hardware design to carefully balance performance and power consumption.
Errors in Depth Estimation Under Extreme Lighting
In addition to target detection, cameras are frequently used to estimate depth information in a scene. Monocular cameras infer depth from changes in object size, texture gradients, and motion within an image. However, this inference is essentially a mapping from two-dimensional to three-dimensional space, and errors in this inference can amplify under poor lighting conditions. For instance, regions with significant brightness variations can cause the visual system to misjudge texture edges or object contours, affecting the accuracy of depth estimation.
Currently, the use of stereo cameras is increasing. Stereo cameras simulate human binocular vision by using two cameras to calculate depth through parallax, providing more accurate distance information under normal lighting conditions. However, this stereo vision also relies on matching feature points between the two images. When the image quality is poor, the feature matching process is prone to failure, leading to errors in depth estimation.
Of course, depth cameras using time-of-flight (ToF) or structured light can also be employed for depth estimation. These cameras obtain depth information by actively emitting light signals and measuring reflection times, with performance less affected by ambient light. However, their applications are limited in long-distance and outdoor environments, and they come with higher costs and power consumption.
Therefore, relying solely on cameras to obtain accurate depth information under extreme lighting conditions is extremely challenging. This is why monocular systems in autonomous driving need to fuse data from other sensors to achieve a more reliable understanding of the environment.
Algorithmic Compensation and Neural Network Optimization
To compensate for the perception limitations of cameras under complex lighting conditions, autonomous driving systems incorporate neural networks and other algorithmic strategies. Currently, deep learning has become the mainstream method for target detection, segmentation, and depth estimation, capable of learning the effects of lighting variations on pixels from vast amounts of data to adapt to diverse and complex scenarios.
For low-light environments like nighttime, technical solutions employ training strategies such as data augmentation and domain adaptation to enhance model performance. During the image preprocessing stage, specialized low-light enhancement modules can be added to enable the network to extract clearer features, thereby reducing errors in subsequent recognition tasks.
Furthermore, some end-to-end models integrate lighting condition judgment with perception tasks. These models learn during training how to dynamically adjust internal weights based on different lighting conditions, enabling adaptive switching of recognition strategies between bright and low-light scenes to enhance the robustness of autonomous driving systems.
However, neural network compensation cannot completely eliminate all issues. Real-world lighting variations encompass numerous edge cases, some of which may not have appeared in the training data at all, leading to the so-called "long-tail problem." This results in limited generalization ability of the model under unknown lighting conditions.
Camera and Multi-Sensor Fusion Strategies
Considering the perception limitations of cameras in complex environments, current autonomous driving systems do not rely solely on a single sensor. The industry widely adopts multi-sensor fusion solutions, combining sensors with different characteristics such as millimeter-wave radar and LiDAR to enhance the overall robustness and safety of the system.
LiDAR generates high-precision point cloud data by actively emitting and receiving laser beams. Its ranging performance is superior to pure vision-based solutions and is largely unaffected by lighting conditions. In extreme visual scenarios like strong backlighting, even if the camera fails, LiDAR can still provide stable and accurate distance and contour information, effectively compensating for the shortcomings of visual perception. Therefore, multi-sensor fusion is regarded as a key technological path to ensure system safety in complex and dynamic environments.
Sensor fusion can be implemented at different levels. Low-level fusion directly aligns and fuses raw data, offering high computational intensity but better real-time performance. Intermediate-level fusion integrates information at the feature level, balancing accuracy and computational burden. High-level fusion merges outputs from various sensors at the decision level, offering high computational efficiency but lower fault tolerance, making it susceptible to errors from a single sensor.
When designing practical systems, multiple constraints such as autonomous driving level, functional safety requirements, real-time performance, and computational cost must be comprehensively considered to select or design an appropriate fusion architecture, achieving the best balance between performance, safety, and feasibility.
Conclusion
The challenges faced by autonomous driving cameras under extreme lighting conditions are multifaceted. Strong backlighting, nighttime low-light conditions, and sudden changes in illumination can severely impact camera image quality, thereby affecting the accuracy of target recognition and depth estimation. Addressing these issues cannot rely solely on single-point algorithmic fixes; instead, a closed-loop approach must be formed among input quality, model robustness, and multi-sensor collaboration to enable the system to have controllable degradation capabilities in the face of inevitable information loss. Only when the risks posed by lighting variations are incorporated into the overall architecture and safety design can cameras serve as a "reliable and usable" perception source in real-world road environments.
-- END --
-
![]()
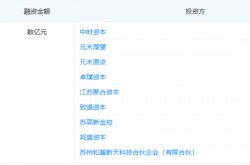
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’