Domestic Multimodal Search Makes a Stunning Breakthrough! Qwen3-VL Leads MMEB Rankings: Handles Text, Images, and Videos Across 30+ Languages
 01/12 2026
01/12 2026
 539
539
Analysis: The Future of AI-Generated Content

Key Highlights
- Introduced the Qwen3-VL-Embedding and Qwen3-VL-Reranker models, built on the Qwen3-VL foundational framework.
- Developed an end-to-end, high-precision multimodal search pipeline that maps text, images, visual documents, and videos into a unified representation space.
- The Embedding model achieved a top score of 77.8 on the MMEB-V2 benchmark, supporting Matryoshka Representation Learning (MRL) and quantization for optimal performance and efficiency.

Figure 1: Depiction of a unified multimodal representation space. The Qwen3-VL-Embedding model series represents diverse data sources (text, images, visual documents, and videos) on a common manifold. By aligning semantic concepts across modalities (e.g., linking the text "urban architecture" with its corresponding image), the model achieves a comprehensive understanding of complex visual and textual information.
Problems Addressed
- Multimodal Content Surge: The internet is overflowing with varied data types such as images, documents, and videos, rendering traditional text-only searches ineffective.
- Cross-Modal Semantic Alignment: Requires precise understanding and matching of semantic concepts across different modalities (e.g., pairing the text "urban architecture" with corresponding images).
- Complex Document and Long Video Processing: Existing models often struggle with charts, extensive documents, and videos containing dense information.
- Deployment Efficiency and Storage Costs: High-dimensional vectors incur significant storage and retrieval costs, limiting scalability.
Proposed Solution
- Unified Framework: Built a dual-model architecture with Embedding (retrieval) and Reranker (ranking) models based on the powerful Qwen3-VL foundational model.
- Multi-Stage Training Strategy: Progressively enhanced model capabilities through contrastive pre-training on large-scale synthetic data, multi-task contrastive learning with SFT, and distillation from the Reranker model.
- Data Factory: Constructed an automated data synthesis and cleaning pipeline, generating over 300 million high-quality multimodal training data points.
Applied Technologies
- Multi-Stage Training: Pre-training → Multi-task Fine-Tuning → Distillation and Model Merging.
- Hard Negative Mining: Improved data quality through a two-stage filtering process (recall and relevance filtering).
- Knowledge Distillation: Utilized the Reranker model with a Cross-Encoder architecture to guide the training of the Embedding model.
- Matryoshka Representation Learning (MRL): Enables the model to output vectors of varying dimensions, adapting flexibly to different storage requirements.
- Quantization-Aware Training (QAT): Supports int8 and binary quantization, ensuring storage efficiency.
Achieved Results
- SOTA Performance: Qwen3-VL-Embedding-8B scored 77.8 on MMEB-V2, outperforming all existing models, including closed-source APIs.
- Strong Text-Only Capability: Scored 67.9 on the MTEB multilingual benchmark, maintaining highly competitive text-only retrieval performance.
- Efficient Deployment: Supports up to 32k token input and significantly reduces storage and inference costs through MRL and quantization techniques.
Model Architecture
Figure 2: Overview of Qwen3-VL-Embedding and Qwen3-VL-Reranker Architectures
Qwen3-VL-Embedding and Qwen3-VL-Reranker are designed to perform task-aware relevance judgments on multimodal instances.
- Embedding Model: Adopts a Bi-encoder architecture to generate dense vector representations of instances, using cosine similarity as the relevance metric.
- Reranking Model: Uses a Cross-encoder architecture to provide finer-grained relevance assessments for query-document pairs.
Model Architecture Foundation: Both models are based on the Qwen3-VL backbone network, utilizing causal attention mechanisms. After training on large-scale multimodal, multi-task relevance data, the models retain the backbone's world knowledge, multimodal perception, and instruction-following capabilities while acquiring relevance assessment abilities. This work trained models in two sizes—2B and 8B. Table 1 below summarizes both:

Embedding Method: The Embedding model extracts task-aware dense vectors for multimodal inputs. The input format follows the Qwen3-VL context structure:
- System Message: Passes an instruction (default: 'Represent the user's input.').
- User Message: Passes the multimodal instance to be represented, which can be text, image, video, or a combination thereof. Finally, a PAD token (<|endoftext|>) is appended to the input, and the last-layer hidden state corresponding to this token serves as the dense vector representation of the instance.

Reranking Method: The Reranking model employs a Pointwise ranking approach.
- System Message: Passes an instruction to judge relevance, requiring answers to be only 'yes' or 'no.'
- User Message: Contains the specific query and document to be evaluated.
- Output: Obtains a relevance score by calculating the probabilities of the model predicting the next token as 'yes' or 'no.'


Data
To equip the model with universal representation capabilities across different modalities, tasks, and domains, a large-scale dataset was curated. The distribution of different categories within the dataset is shown in Figure 3. However, both publicly available and proprietary internal data exhibit significant imbalances across these dimensions, with notable scarcity in specific scenarios. To address these challenges, data synthesis was employed to construct a balanced training corpus, ensuring robust coverage of all modalities, tasks, and domains.

Dataset Format
The complete dataset comprises multiple sub-datasets, denoted as . Each sub-dataset is defined by a quadruple , structured as follows:
- Instruction (Instruction, ): A textual description defining the specific relevance criteria and task objectives for the sub-dataset.
- Queries (Queries, ): A collection of query objects. Each can consist of text, images, videos, or any multimodal combination thereof.
- Corpus (Corpus, ): A repository of document objects. Similar to queries, each can be a single modality or a multimodal combination of text, images, and videos.
- Relevance Labels (Relevance Labels, ): This component identifies the relationships between queries and documents, represented as . For each query , denotes the set of relevant documents (positive samples), while represents the set of irrelevant documents (negative samples).
Representative dataset examples are shown in Appendix A.
Data Synthesis
Data synthesis was employed to construct various sub-datasets . Specifically, the method introduced in Qwen3 Embedding was extended to a multimodal scenario. As shown in Figure 4, a diverse set of seed multimodal content (e.g., images/videos from the web) was first curated. Then, Qwen3-VL-Instruct was utilized to generate: (1) synthetic instructions, (2) synthetic queries, and (3) pseudo-relevance labels.
The specific process is as follows:
- Seed Content Curation: A large number of images and videos were collected from public datasets and web scraping, followed by deduplication and safety filtering to form the seed corpus .
- Instruction Generation: For each item in , Qwen3-VL-Instruct was prompted to generate instructions describing potential retrieval tasks. For example, 'Generate a search query for this image' or 'Describe a user query matching this video clip.'
- Query Generation: Based on the instructions and content, the model generated corresponding queries. To increase diversity, the model was prompted to generate queries at different granularities (e.g., coarse-grained categories vs. fine-grained descriptions) and across different modalities (e.g., text queries, relevant image queries).
- Pseudo-Label Generation: Initially generated queries were paired with seed content as positive samples, forming . To further refine these labels, an early version of the Embedding model trained on preliminary data was used to perform retrieval, and the filtering techniques described in the next section were applied.
This synthetic approach enabled the creation of large-scale, diverse, and task-specific training data, addressing the scarcity of naturally occurring multimodal retrieval data.
Positive Sample Optimization and Hard Negative Mining
Hard negatives play a crucial role in contrastive representation learning. To improve the quality of positive pairs and identify effective hard negatives, an automated two-stage mining pipeline was implemented: Recall and Relevance Filtering.
- Recall: For each sub-dataset , an Embedding model was used to extract representations for all queries and documents . For each query , the Top-K most relevant candidate documents were retrieved based on cosine similarity, with their relevance scores denoted as .
- Relevance Filtering: Finally, relevance labels were optimized based on relevance scores to eliminate noise:
- Positive Refinement: A query was retained only if at least one positive document had a score , where is a hyperparameter serving as the score threshold. If no such candidate document existed, the query was discarded.
- Hard Negative Selection: For a valid query , the average score of its optimized positive samples was calculated. Any non-positive document was selected as a hard negative only if its score satisfied , where is a small safety margin to prevent the inclusion of 'false negative' samples.
Training Strategy
To train our Qwen3-VL-Embedding and Qwen3-VL-Reranker models, a multi-stage training pipeline was adopted, as shown in Figure 5. This approach aimed to mitigate data imbalances between large volumes of weakly supervised data and scarce high-quality samples. The model was first pre-trained on large-scale weakly supervised, noisy data to establish a baseline for relevance understanding and enhance generalization capabilities. Subsequently, fine-tuning was performed on high-quality, task-specific datasets to guide the model toward more precise relevance scoring and fine-grained interactions. Beyond these reasons, another objective of the multi-stage training strategy was to iteratively improve data quality and model performance. As training progressed through consecutive stages, the model's capabilities continuously enhanced. This improvement, in turn, facilitated more effective data mining, optimizing the quality of the training data. This iterative cycle ultimately led to substantial overall performance gains in the model.

Multi-Stage Training
The following three-stage training strategy was implemented:
- Stage 1: Contrastive Pre-training. To align multimodal representation spaces and enhance world knowledge understanding across various modalities, tasks, and domains, contrastive pre-training was first conducted on the Qwen3-VL-Instruct model. In this stage, 300 million synthetic multimodal pairs generated using the synthetic pipeline described in Chapter 3 were utilized. These data encompassed a wide range of domains and tasks, providing a foundation for robust representation learning. The resulting model is denoted as Qwen3-VL-Embedding: s0.
- Stage 2: Multi-task Contrastive Learning. In this stage, the s0 model was fine-tuned on a high-quality dataset containing 40 million samples. This dataset was mined from synthetic pools as well as public and proprietary data sources by leveraging the retrieval capabilities of the s0 model. This stage not only refined the Embedding model with higher-quality data but also trained the Qwen3-VL-Reranker using specific subsets of retrieval data. The resulting Embedding model is denoted as Qwen3-VL-Embedding: s1.
- Stage 3: Distillation and Model Merging. To further enhance retrieval performance, the scoring capabilities of the Qwen3-VL-Reranker model were leveraged to distill its knowledge into the Embedding model. Using the s1 model, we mined 4 million hard negative samples to create a training set focused on challenging distinctions. This process produced Qwen3-VL-Embedding: s2. Finally, to maintain general capabilities and balanced performance across a wide range of tasks, the weights of the s2 model were merged with those of the s1 model, yielding the final model, Qwen3-VL-Embedding: s3.
Implementation Details
- Base Models: The Qwen3-VL-Embedding and Qwen3-VL-Reranker series are
The training process of the Embedding model utilized a multi-task learning approach, integrating various loss functions such as the InfoNCE loss, CoSent loss, MRL loss, binary quantization loss, and distillation loss.
Retrieval Tasks. When dealing with retrieval tasks, we opted for the InfoNCE loss. Given a query within a batch, its corresponding positive document, and a set of negative documents, the loss is calculated as follows:
Here, the symbol $text{cos}$ represents cosine similarity, and $tau$ stands for a temperature hyperparameter. We relied on in-batch negatives and supplemented them with hard negatives, which were mined as detailed in Section 3.3.
Semantic Textual Similarity (STS) Tasks. For STS tasks, aiming to capitalize on fine-grained similarity scores, we employed the CoSent loss:
In this formula, $mathcal{P}$ and $mathcal{N}$ denote the sets of positive and negative sample pairs, respectively, while $lambda$ serves as a scaling factor.
Classification Tasks. In classification tasks, we treated label descriptions as queries and inputs (such as images or videos) as documents. The loss function is similar to the previous one, but when constructing negative samples, we only included samples from different classes and excluded any samples from the same class to prevent false negatives.
Knowledge Distillation. During Stage 3, knowledge distillation was implemented to align the score distributions of the Embedding model with those of the Reranker teacher model. For a given query and a set of candidate documents, the distillation loss is defined as:
Here, $p^{text{teacher}}$ and $p^{text{student}}$ represent the softmax-normalized score distributions of the teacher and student models on the candidate documents, respectively.
Matryoshka Representation Learning (MRL). To enable flexible embedding dimensions, we adopted MRL. For a set of nested dimensions $d_1 lt d_2 lt cdots lt d_K$, the total loss is computed as:
In this equation, $text{emb}_{d_i}$ denotes the embedding truncated to the first $d_i$ dimensions, and $alpha_i$ is a weighting coefficient.
Quantization-Aware Training. To ensure high performance even after binary quantization, we incorporated quantization loss during the training phase. As suggested by Zhang et al. (2025c), instead of directly binarizing the embeddings, we used a pseudo-quantization regularization term to encourage binarization-friendliness:
Here, $mathbf{e}$ represents the embedding vector, and $text{sg}$ denotes the stop-gradient operation. This approach encourages the embedding vectors to cluster near the vertices of a hypercube.
Loss Function for the Reranker Model
We framed re-ranking as a binary classification problem: given a query-document pair, the model predicts either a "yes" token (indicating relevance) or a "no" token (indicating non-relevance).
The loss function is given by:
where $P(text{yes}|mathbf{q},mathbf{d})$ denotes the probability assigned by the VLM. For positive pairs, the label $y$ is set to "yes," while for negative pairs, it is set to "no." This loss function motivates the model to assign higher probabilities to correct labels, thereby enhancing ranking performance (Dai et al., 2025).
During the inference stage, the final relevance score is computed by applying the sigmoid function to the difference between the logits of the "yes" and "no" tokens:
Evaluation Results


MMEB-V2 Benchmark: Qwen3-VL-Embedding-8B achieved an impressive overall score of 77.8, demonstrating exceptional performance across all subtasks, including image, video, and visual document retrieval. It outperformed models such as VLM2Vec, GME, and closed-source models like Google Gemini Embedding and OpenAI text-embedding-3-large.
Visual Document Retrieval: On multiple benchmarks, including VisRAG and ViDoRe, the Qwen3-VL-Embedding and Reranker series models showcased dominant performance, surpassing models like ColPali and ColQwen2.
Text Benchmarks: Despite being a multimodal model, Qwen3-VL-Embedding-8B achieved an average score of 67.9 on the MMTEB text-only benchmark, which is comparable to the performance of pure text Embedding models of similar scale.
Reranking Performance: Qwen3-VL-Reranker-8B significantly outperformed baseline models in most re-ranking tasks, showing substantial improvements over its 2B version.
Ablation Experiments

MRL and Quantization: Experiments revealed that performance declined as dimensions decreased. However, within a reasonable range (e.g., from 1024 to 512), the performance loss was minimal (~1.4%), while achieving a 50% reduction in storage. Int8 quantization incurred almost no precision loss, whereas binary quantization exhibited more noticeable performance degradation at lower dimensions.
Spatiotemporal Granularity Impact: Increasing the number of tokens for images and frames for videos improved performance, but with diminishing marginal returns. Excessively long contexts could even lead to a slight decline in performance.
Multi-Stage Training Effects: Ablation studies indicated that the transition from S0 to S1 (multi-task fine-tuning) yielded significant improvements. S2 (distillation) substantially enhanced retrieval task performance at the expense of some classification capabilities. The final S3 (merging) successfully balanced all capabilities, achieving optimal overall performance.


Conclusion
This report introduces Qwen3-VL-Embedding and Qwen3-VL-Reranker, a series of cutting-edge models designed for multimodal retrieval. By integrating a multi-stage training pipeline with high-quality multimodal data and leveraging the multimodal knowledge and general understanding capabilities of the Qwen3-VL base model, the Qwen3-VL-Embedding and Qwen3-VL-Reranker model series have achieved unprecedented performance across a wide range of multimodal retrieval benchmarks while maintaining strong pure text capabilities.
Furthermore, by incorporating Matryoshka Representation Learning (MRL) and Quantization-Aware Training (QAT), the Qwen3-VL-Embedding series exhibits exceptional practical deployment characteristics, significantly reducing computational costs for downstream tasks while maintaining superior performance. Looking ahead, promising research directions include extending support for more modalities, developing more efficient training paradigms, enhancing compositional reasoning capabilities, and establishing more comprehensive evaluation protocols. This work believes that these models represent a significant advancement in multimodal retrieval technology and hopes they will drive further innovation in this rapidly evolving field.
References
[1] Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
-
![]()
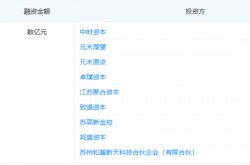
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’