DeepSeek Takes the Stage! AI Newcomers Shake Up Rankings—Is the Red Packet War Just for Show?
 02/13 2026
02/13 2026
 513
513
Red packets take center stage, models follow closely behind.

During the 2026 Year of the Horse Spring Festival, the intensity of AI competition even eclipsed the excitement of red packet giveaways.
ByteDance, Alibaba, and Tencent simultaneously ramped up their AI efforts on a massive scale: leveraging red packets, free orders, Spring Festival Gala interactions, and local life integrations—all vying for user engagement. Meanwhile, the BAT trio (Baidu, Alibaba, Tencent) continuously advanced their foundational models, with intensive updates in video generation (Seedance 2.0), imaging (Qwen-IMAGE-2.0), multimodal, and voice models, leaving virtually no gaps unaddressed.
However, the competition in foundational models quickly extended beyond giants like ByteDance, Alibaba, and Tencent to include DeepSeek and other "AI Rising Stars."
On the evening of February 11, DeepSeek's new model version went live, further pushing the boundaries of long-context and complex task capabilities. Almost simultaneously, Zhipu unveiled its next-gen flagship GLM-5, emphasizing Agent and programming capabilities; MiniMax also launched MiniMax M2.5, continuing its multimodal and application-oriented approach.
The near-simultaneous moves by these three companies escalated the "model showdown" in this Spring Festival AI battle to new heights.
Giants compete on two fronts—user access points and model innovation—while startups focus on foundational capabilities, betting big on foundational models. The competition that will truly define 2026 and beyond is unfolding right now.
Spring Festival AI Battle: Red Packets at the Forefront, Model Competition in the Background
On February 12, Alibaba's QianWen announced that its "3 billion Spring Festival free orders" campaign had processed 120 million AI-powered orders in six days, with users engaging in 4.1 billion interactions. Earlier, Tencent Yuanbao reported that five days into its Spring Festival campaign, the daily usage of Yuanbao's AI image generation feature surged 30-fold, with session durations increasing by over 80%.

Image source: QianWen, Yuanbao
If the first half of this year's Spring Festival AI battle was purely about gaining user access points, the second half became more complex, with both giants and startup large model companies focusing intensely on iterating foundational models.
This point was actually mentioned in Leikeji's previous report, "Everything for Agents: QianWen, Step, and Gemini Ignite the '3.5 Model Battle,' Will the Spring Festival Be the Key Moment?" including:
- Overseas models like GPT-5.3-Codex and Claude Opus 4.6;
- Domestically released models like Kimi 2.5, Step 3.5 Flash, SeedDance 2.0, and Seedream 5.0;
- The newly released GLM-5, MiniMax M2.5, and DeepSeek V3 series updates;
- And upcoming models like Doubao 2.0, Qwen 3.5, and Gemin 3.5.
DeepSeek V4's major move hasn't arrived yet, but deepening "long-context" capabilities is a key highlight.
Given that DeepSeek did not release an official blog post, this updated model is likely not V4 but rather an update to the V3.2 series (or possibly V3.5).
However, this can also be seen as a "gray version" ahead of the V4 release. According to the latest report by The Information, internal preliminary testing of DeepSeek V4 shows its programming capabilities have already surpassed Claude's (specific model not specified).
From the unified DeepSeek responses received by netizens, the changes in DeepSeek's new model focus on two key areas: million-level long-context support and knowledge base updates.
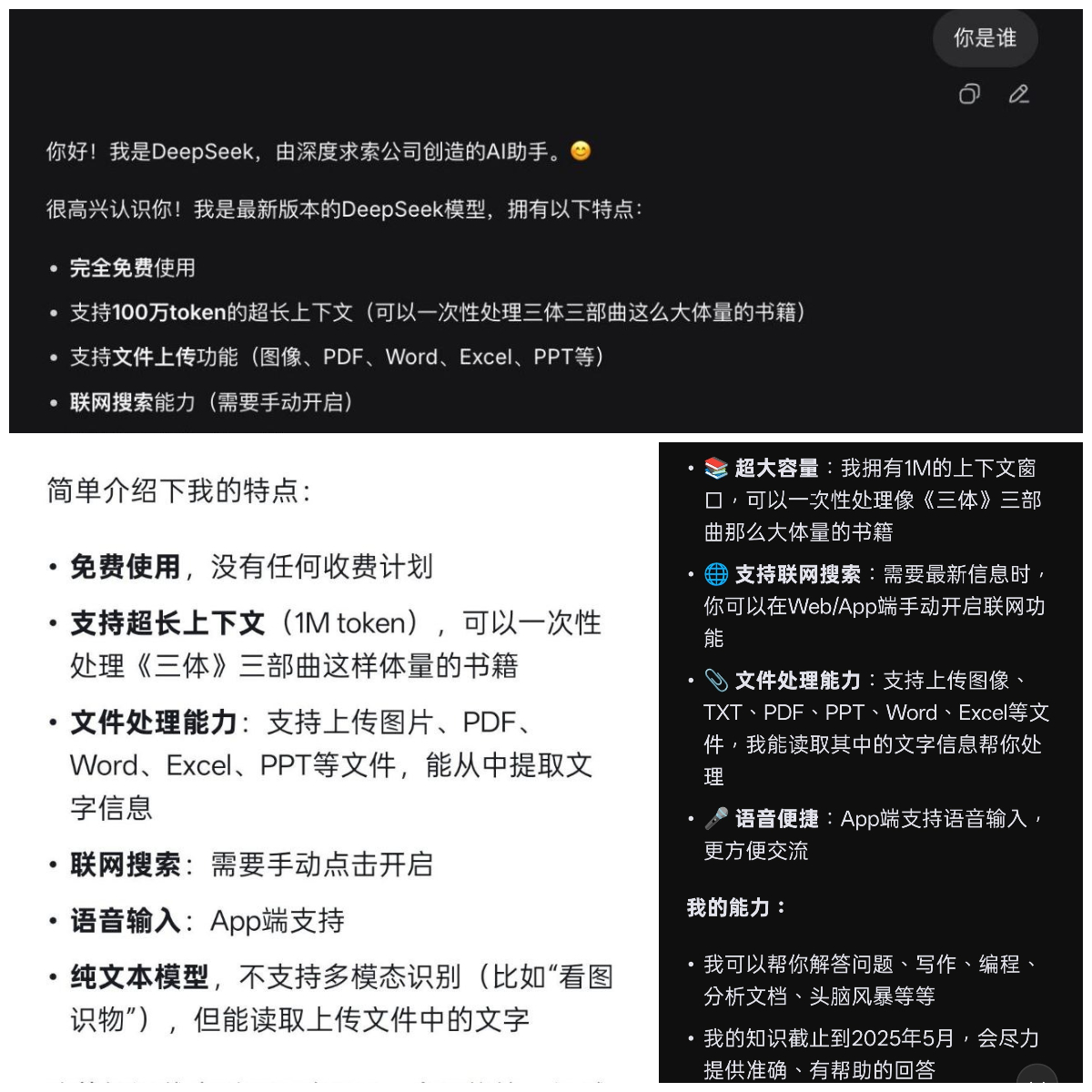
First, the context window was directly expanded from 128K to 1M (1 million tokens), allowing users to input the entire "The Three-Body Problem" series or an entire project's code repository at once. Tests show it processes such long documents with extremely fast response times, eliminating the need for manual file splitting.
Additionally, DeepSeek's new model's knowledge base has been updated to May 2025, but it still does not support multimodality—unable to understand images (except text content) and videos, aligning with DeepSeek's consistent "language model" focus:
Not pursuing flashy multimodality but instead excelling in text reasoning and engineering tasks, which are high-frequency and essential needs.
The significant increase in context length not only stabilizes long-document processing and multi-round reasoning but also theoretically improves performance in complex scenarios like long-code understanding and multi-step analysis.
After Over a Month of Iteration, Zhipu's GLM-5 Pushes Agents to the Forefront
In comparison, GLM-5's upgrade as a native Agent foundation model feels more "generational." Although just over a month has passed since the release of GLM-4.7 at the end of last year, the new model announced by Zhipu at the beginning of the year indeed represents a significant leap.
The core keyword for this generation of models is no longer conversation but Agent and programming capabilities, with specifications clearly aligned toward an "Agent foundation model": context reaching the 200K level, maximum output up to 128K, further expanded model scale, and a restructured training system.
But the real changes occur in the capability structure.
GLM-5.0 is directly designed as an Agent model capable of executing tasks, emphasizing programming capabilities, tool invocation, and long-flow execution. In programming tests, it can already handle project-level code and debugging issues, with the model able to break down requirements, invoke interfaces, continuously execute tasks, and maintain goal consistency throughout multi-stage processes.
Continuing to Bet on Multimodality, MiniMax M2.5 Remains Production-First
MiniMax's vertical route from model to application still sets it apart from the previous two.
The upgrade focus of MiniMax M2.5 remains on multimodal and content generation capabilities, but it emphasizes a holistic advancement of multimodal abilities, including simultaneous improvements in voice generation, music generation, and text capabilities, stressing direct entry into creative and product workflows.
The model continues to use a Mixture of Experts (MoE) architecture, controlling inference costs while maintaining scale, making it more suitable for deployment on the application side. Improvements in voice cloning, emotional expression, and music generation quality bring it closer to being a "production tool" rather than a reasoning model.
Thus, MiniMax's positioning is clear—not to compete on who is the smartest but to make models truly usable in content production, generating content, participating in creation, and entering product workflows.
This path also determines that MiniMax's goal is not benchmarks but deployable production capabilities.
The path differences among the three models become very concrete: DeepSeek pushes long-reasoning capabilities to the extreme, Zhipu pushes the model toward an Agent engineering form, and MiniMax turns multimodal production capabilities into infrastructure. They no longer compete around the same set of metrics but instead build their respective model forms in different capability directions.
However, the commonalities are also evident. Parameter scale is no longer the core selling point, nor is chat experience the main goal; all upgrades point to one thing—models must be able to participate in real tasks, not just provide answers.
One Year After DeepSeek's Explosive Debut, the "AI Rising Stars" Rankings Have Drastically Changed
Rewinding to last year's Spring Festival, the open-source release of DeepSeek-V3 and R1 shocked the global AI landscape and became a watershed for the "AI Rising Stars" camp.
The key was not just that the "models were strong" but that costs were redefined. After low-cost, high-performance reasoning models emerged, industry expectations for foundational models suddenly changed—not just demanding a rigorously trained model but requiring a stronger model at lower costs.
Intense model competition accelerated, coupled with a scarcity of training compute, directly triggered a clear differentiation within the "AI Rising Stars" camp. Baichuan and 01.AI have nearly exited the main battlefield of "cutting-edge foundational models": the former shifted to vertical directions like healthcare, while the latter focused more on enterprise and industry scenarios, with a noticeably slowed update pace.
As foundational models enter a high-investment, high-density iteration phase, only a few teams can sustain compute and R&D pressure long-term.
However, this year's situation is somewhat different, with the most direct point being that DeepSeek V4 has not been released yet. From an external perspective, there may be two explanations.
One is technical reality: reasoning abilities, long-context, and engineering stability are inherently more challenging directions, requiring a longer cycle for a model to leap a full generation, and there were also reports of DeepSeek encountering difficulties during training. The other is more strategic, not just releasing alongside competitors but debuting as the grand finale to gain promotional advantage.
Another easily overlooked change is that this Spring Festival, DeepSeek faces high-intensity model investments from ByteDance, Alibaba, and Tencent, as well as rapid global model iterations, with the most intuitive example being the recently globally explosive ByteDance Seedance 5.0 video model.

Generated by Seedance 5.0, image source: bilibili
Of course, the still-active "AI Rising Stars" are also continuously advancing foundational model iterations on the front lines. Zhipu GLM and Step by Step stars focus more on models, providing more innovative and practical foundational models for the industry.
MiniMax and Moonshot AI's Kimi focus more on "models as applications," not just building models but also developing their native AI applications. MiniMax has even formed a certain product matrix, but both are vertically integrating from foundational models to applications.
This is not simply a matter of "who is stronger" but a more realistic differentiation.
Epilogue
The 2026 Spring Festival hasn't officially begun, but the starting gun for the second half of the large model era has already sounded deafeningly loud.
From the giants' "money-throwing" access point battles to DeepSeek, Zhipu, and MiniMax's model surprises on the fourth night of the Lunar New Year, the way this fight is waged has changed. No longer obsessed with scoring high on benchmarks, the focus has shifted to who can embed deeper into real productivity: whether it's the appetite to swallow millions of lines of code, the hands to autonomously run through engineering processes, or the ears to understand human emotions.
Although DeepSeek didn't unleash the legendary V4 this time, its "1M context" long punch still sent shivers down the spines of many opponents who talk about Agents but can't solve long-term memory issues. Meanwhile, Zhipu and MiniMax's timely showdown proves that the "AI Rising Stars" have shifted from last year's defensive counterattacks to more confident, differentiated offensives.
Suspense remains. Is DeepSeek's long-awaited V4 waiting for a "one-force-defeats-all" grand finale moment, or is it tackling some unknown technical ceiling? In the melee between giants and rising stars, who will be the first to truly convert "model capabilities" into "commercial moats"?
But one thing is certain: In 2026, simply being "good at chatting" won't get you a ticket anymore. When the fireworks fade, only those who can truly integrate into workflows will remain at the table.

DeepSeek QianWen Yuanbao Zhipu MiniMax
Source: Leikeji
Images in this article come from: 123RF Royalty-Free Image Library
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







