AI Red Packets During Spring Festival: Essentially a Large-Scale Microdata Harvesting Operation
 03/03 2026
03/03 2026
 458
458

For a long time, we have assumed there is a physically isolated firewall between our lives and the online world.
However, in recent years, the internet seems to have become less 'secure.'
In the field of information security, there is a concept called 'Practical Obscurity.'
This is not uncommon in daily life: if someone can go through all your posts on Tieba and compare your speaking habits on Weibo and Xiaohongshu, there is a high chance they can identify you.
Nevertheless, most people do not have the leisure or willingness to invest the time and effort to do this.
But now that the internet has entered the AI era, the situation has changed.
The emergence of large language models (LLMs) has suddenly reduced the firewall behind online aliases to dust.
Remember last week when Anthropic accused a domestic AI company of malicious distillation, only to be countered by users asking, 'Are you showing off your ability to use metadata to prevent users from remaining anonymous?'
Just a few days later, Anthropic broadcast another shocking fact to the world: without metadata, as long as you can use large models, anonymity can be invalidated!
01
De-anonymization Method: Structured Matching
Anthropic's security research team has made a new discovery.
They, along with ETH Zurich, published a highly disruptive paper on the internet: 'Large-scale online deanonymization with LLMs.'
Calling it 'disruptive' is no exaggeration because the core argument of the paper is:
On the internet, for large-scale unstructured text, by utilizing existing APIs and public models, large language models can, at a low cost of up to $4, associate people's anonymous accounts with their real identities with extremely high accuracy.
In fact, de-anonymization is not a new topic in the computer industry.
In 2006, Netflix, then a streaming giant whose main business was mailing DVD rentals, decided to host an algorithmic competition to more accurately recommend movies to users. Whoever could improve the prediction accuracy of the existing movie recommendation system by 10% would win a $1 million prize.
Designing algorithms requires data. Although big data technology did not exist at the time, Netflix still released a massive dataset containing viewing data from approximately 500,000 real users and 100 million movie rating records.
Undoubtedly, such private data had to be desensitized before being made public. Netflix removed all personally identifiable information, such as real names, emails, addresses, and credit card numbers, leaving only movie-related information.
Netflix also confidently assured the world that the released data would not contain any information that could identify individuals.
To those who do not watch movies, the released data might seem like garbage, but the outcome exceeded expectations:
Two security researchers, Narayanan and Shmatikov, broke through Netflix's defenses without attacking its servers or using any hacking techniques.
The researchers employed a method called linkage attack and introduced the Internet Movie Database (IMDb) as an auxiliary dataset.
They keenly observed that many people, while anonymously rating movies on Netflix, also liked to write public reviews on IMDb. Therefore, they used crawlers to obtain a large number of public user profiles, directly acquiring sensitive information such as users' real names, usernames, residences, as well as public movie reviews and dates.
The next step was simple: using this movie-related information, they played a game of 'match-up' with Netflix's 100 million publicly released data points.
Although many people watch popular movies, each person's combination and timeline of movie-watching are extremely unique, almost one-of-a-kind.
Like fingerprints, relying on the public profiles on IMDb, the two researchers successfully linked anonymous reviews to users' real identities.
And that's when disaster struck.
Once accounts were determined to be linked, users' complete viewing histories were thoroughly exposed, and various private information was forced into the open, leading to a class-action lawsuit against Netflix. Although a costly out-of-court settlement was reached, the planned second competition was permanently canceled.
This was one of the earliest 'de-anonymization' attacks. Although seemingly simple, it established a core concept in modern information security:
Microdata itself is a form of identification, very similar to the metadata used in Anthropic's defense against distillation.
However, this attack from 18 years ago had a fatal weakness: it required structured data.
Simply put, attackers obtained exact movie names, ratings, timestamps, and other information from IMDb's public profiles, packaging them into a highly standardized data format, where nothing extra or missing was allowed.
Only with such data packets could they play 'match-up' in the database. Therefore, this method was ineffective against the random comments we post on social platforms today.
But unexpectedly, 18 years later, in the AI era, large language models brought a technological turning point.
02
Industrial-Scale Pipeline for De-anonymization: The ESRC Framework
Anthropic's researchers discovered that existing large language models could act as perpetual-motion detectives to play this game of 'match-up.'
Globally, the chats between each user and AI form a vast and chaotic unstructured dataset, and large language models excel at extracting users' microdata from these casual conversations:
Ordering takeout reveals where you live, searching for recipes reveals what you like to eat, and even modifying code reveals your bad habit of naming variables in pinyin.
Friends who frequently use AI in daily life surely understand that we tell AI far more than this, and such rich information is sufficient for AI to convert it into structured features and perform a the entire internet (global network) match.
To prove that this unique attack method of large language models can operate automatically in user databases on the scale of millions, the research team did not rely on simple prompts for verification, as in daily conversations. Instead, they designed a modular pipeline called the ESRC framework.
The framework's name is composed of the initials of four stages: Extraction, Search, Reasoning, and Calibration.
Step 1: Extraction
The content people post anonymously online in daily life is often casual, with semantically vague and meaningless text scattered everywhere. Sometimes, people do not even know what they are saying, let alone expect a model to understand.
Therefore, researchers first used lightweight large models to filter these texts, removing meaningless replies like 'experience +3' and spam such as pure links.
Subsequently, the filtered text was sent to advanced models, which were required to output a comma-separated list of core details.
In this way, a seemingly meaningless piece of anonymously sent text could be transformed into a valuable sequence of information, such as ['24 years old', 'student', 'currently living in Beijing', 'owns a dog named Coco'], similar to a list in Python.
Step 2: Search
With valid anonymous information and a database containing real identities, the game of 'match-up' could begin.
However, facing hundreds of millions of tokens and millions of users daily, if large language models were to compare them two by two, the time complexity would be O(N²), making the API costs paid to AI vendors unbearable.
Therefore, Anthropic's research team introduced vector retrieval technology and called upon OpenAI's text-embedding-3-large model as a translator.
The previously extracted list of core details would be translated into a high-dimensional vector containing thousands of numbers, known as a dense vector.
The information we inadvertently tell AI is stored in these dense vectors. The more similar people's interests and hobbies are, the closer their dense vectors are in vector space.
At this point, an open-source tool developed by Facebook, the 'FAISS library,' comes into play: it calculates cosine similarity to find the real identities that best match the anonymous information.
In this way, the model does not need to search for a needle in a haystack in an ultra-large user pool but only needs to compare against the group of people that best match the anonymous information.
Step 3: Reasoning
It should be noted that traditional embedded vector retrieval technology, which relies on calculating cosine similarity, can only narrow down the scope but cannot directly achieve high-precision matching because relying on probabilities calculated from vectors for associative matching is unreliable.
Compared to traditional computer algorithms, the greatest advantage of large language models lies in their ability to actively engage in 'reasoning.'
Therefore, researchers handed over the top 100 candidate real identities that best matched the anonymous information to top large language models, which would draw conclusions through intense reasoning.
Large language models can look for both similarities and contradictions.
Suppose a candidate matches most of the features in the core information list, such as '24 years old,' 'student,' and 'owns a dog,' but their IP shows they are in the United States, and the target account is often active in the early morning hours.
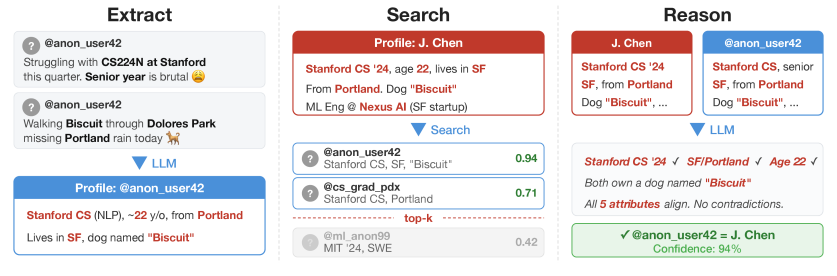
In vector space, their anonymously posted information might be extremely close to their real identity, but the reality is quite the opposite. At this point, large language models can, like humans, use these obvious contradictions to eliminate high-similarity but incorrect options.
Step 4: Calibration
For real-world security attacks, a rule must be followed: it is better to miss than to make a false positive. Therefore, the calibration phase must answer a question: the large language model has found a person, but is this result trustworthy?
It is easy to understand when applied to real-life scenarios: out of curiosity, inferring who a person is based on their anonymously posted content can lead to unnecessary embarrassment if the judgment is wrong, rendering previous efforts futile.
Therefore, when large language models match anonymous information with real identities, the result must either be correct or non-existent; incorrect matches are absolutely not allowed.
After the large language model completes reasoning, the attacker will obtain many matching results, with one anonymous account corresponding to one real identity, temporarily denoted as a pair. Among thousands of such pairs, some are inevitably correct while others are not.
To address issues such as the unreliability of vector similarity and the possibility of models overlooking subtle contradictions during reasoning, the research team added a calibration mechanism:
They set up a slightly cheaper model to act as a referee and had each pair in the matching results engage in 1v1 PK. The referee model had to determine which pair appeared more likely to be the same person.
After each round of PK, the system updated the scores for each pair of matching results based on the outcome. After thousands of comparisons, an extremely reliable confidence ranking was ultimately obtained.
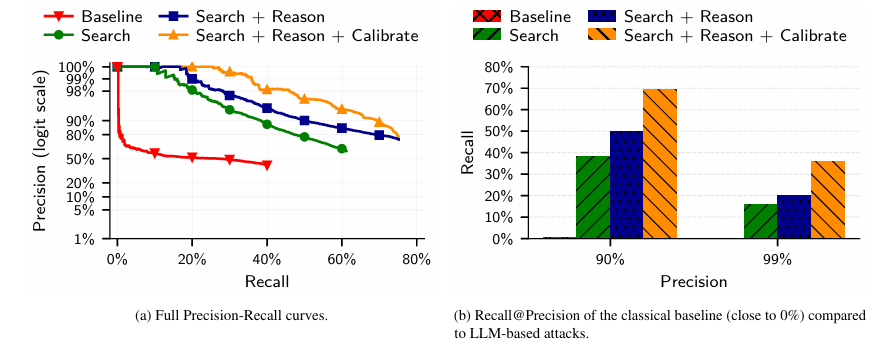
The results showed that this method could significantly improve the system's recall rate at over 99% precision, making the matching relationships more reliable.
03
Experimental Results of De-anonymization: Comprehensive Defeat
To assess the effectiveness of the ESRC framework, Anthropic's research team designed three scenarios that simulated real-world conditions, and the results were somewhat alarming.
The first was a dimensional reduction attack from autonomous Agents.
The research team first built a large language model Agent with web search capabilities and attempted to have it link desensitized geek forum accounts to real LinkedIn professional identities.
This experiment was almost identical to the process of a human-powered search. The attacker only needed to provide the desensitized geek forum profile, and the Agent could autonomously generate search terms, call upon search engines, and cross-compare evidence obtained from web pages.
The research team set an accuracy requirement of 90%, under which the Agent successfully restored 67% of user identities, taking only a few minutes.
More frighteningly, the average search cost per user was only $1-4!
This means that large-scale, highly customized 'human-powered searches' have become economically feasible.
Next, one might wonder: if real professional identities are easily discovered, what about two anonymous accounts on different platforms?
The large model's response was: no difference.
To simulate two anonymous accounts of the same user on different platforms, the research team divided posts by Reddit users into two categories: one for general movie sections and the other for niche movie sections.
But the results were still astonishing: even without privacy data such as age and occupation that could easily form strong associations, and relying only on subjective movie reviews and aesthetic preferences, the ERSC framework could still accurately link the two anonymous accounts.
Cold, hard data showed that as long as the same user mentioned 10 movies on both anonymous accounts, the probability of being accurately linked reached 48.1%.
Some might argue that people's interests and discussion topics change over time, making past accounts completely irrelevant to current ones.
Unfortunately, the model still successfully bridged the gap of time.
The research team divided comments from 10,000 users into a one-year period, using comments from the previous year as the query set and comments from the following year as the candidate pool.
Experiments proved that even with completely different social news and topics from different periods, large language models could still discern subtle clues, accurately finding a user's 'past self' from a candidate pool containing thousands of distractors based on writing style, interests, and even demographic characteristics.
04
Current State of De-anonymization: Indefensible
Whether it is the 2008 Netflix incident or the simulated experiments by Anthropic's research team, we find that the data scale involved was actually not large.
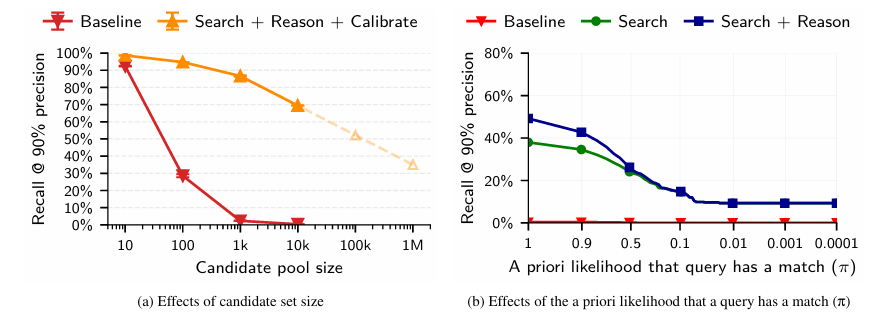
One of the most intuitive and correct ideas is that the difficulty of achieving de-anonymization through precise matching depends on the size of the candidate pool.
If the candidate's real identity is expanded to millions or tens of millions, can the attack method using the ERSC framework still be effective?
Traditional statistical algorithms clearly cannot; they would collapse even with a few hundred people, with the recall rate dropping directly to zero.
However, the ERSC attack based on large language models is different; it demonstrates a frightening log-linear decay characteristic. Even with millions of people, the large language model can still maintain a 35% recall rate at a 90% precision level.
What's even more frightening is that this attack method cannot be defended against by users or platforms.
For users, traditional privacy protection methods are mostly designed for structured data.
We can blur ages into age ranges or turn off location services to avoid position information being obtained.
But in life and online, a person always has to speak. Even with the most advanced text purification techniques for de-sensitization, large language models can still infer some characteristics from these unstructured texts and contextual contexts.
For platforms, it is impossible to block this attack method at the API level.
Platforms can use firewalls to intercept attacks when they see hackers targeting vulnerabilities; but what if the platform sees a user request like, 'Help me see which of these two movie reviews is better written'?
The attack method is precisely contained within these seemingly completely normal user requests, and model providers cannot determine whether the caller is conducting a de-anonymization attack or working normally.
At this point, the asymmetry between defense costs and attack costs in the field of cybersecurity has been completely reversed.
05
Conclusion
In the past, when facing the internet, we would always think: I'm just an ordinary person; who would bother to unmask me?
The monetization logic hidden in the commercial world probably doesn't think so.
If we look back at the just-passed Spring Festival, several leading large model platforms in China unexceptionally launched incentive policies for AI assistants.
Whether it was cash red envelopes from Yuanbao or free milk tea from Qianwen, the fierce marketing campaigns involving billions of yuan in cash from several platforms caused their daily active user data to soar during the Spring Festival, but the retention rates were quite dismal after the holiday.
From the perspective of past internet operation thinking, this was certainly not a successful user acquisition activity. Each company spent a lot of money, but the ROI did not improve. Users happily took the benefits and left, and still, few people actively used the products.
However, after reading this paper, I feel a sense of dread.
Perhaps this was not a failed user acquisition marketing campaign but a large-scale microdata harvesting operation disguised as a Spring Festival event.
Recall what people did with AI during the Spring Festival holiday?
Learning New Year greetings, querying New Year's Eve dinner recipes, making travel plans, ordering takeout milk tea, and even writing reasons for requesting leave after returning to work.
These unstructured natural languages are just casual chats to users and mere nonsense in front of traditional algorithms.
But in the eyes of AI companies that generally possess ESRC capabilities, this information means value, and large language models are precisely the microscopes for discovering value.
AI companies do not need high user retention; on the contrary, as long as users open the chat box, even if they only chat for a few minutes, the large language model can accurately extract high-value information such as age, place of residence, occupation, family structure, spending power, and even personality from brief and vague requests.
In the hands of AI companies, the attack method of the ESRC framework is precisely the strongest weapon for accurately depicting user personas.
In the past, ByteDance might need to analyze the Douyin short videos a user has watched in the past month, Tencent might need to analyze a thousand historical articles a user has read on WeChat, and Alibaba might need to analyze hundreds of products a user has purchased on Taobao to vaguely piece together what kind of person the user is.
But now, with the overflowing semantic understanding and reasoning capabilities of large language models, AI can easily complete precise 'de-anonymization' positioning in massive data with just a few casual conversational fragments.
These extracted high-quality user tags are precisely the most valuable assets for achieving precise ad targeting, cross-platform data monetization, and future model training.
And we have no room for resistance.
In any case, we can only accept one fact: for a long time, the anonymous mechanism that has supported free expression on the internet has lost its meaning in the face of LLMs.
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







