CVPR 2026 | 'Pixel-Level Alignment Master' VA-π: FID Drops by 50% in 25 Minutes of Fine-Tuning
 03/03 2026
03/03 2026
 574
574
Affiliations: Huazhong University of Science and Technology, National University of Singapore
Interpretation: The Future of AI Generation 
In today's rapid advancement of visual autoregressive (AR) models, we have grown accustomed to treating the Tokenizer and generator as a perfect black-box combination. However, when we return to the essence of the matter, we must confront the 'elephant in the room': Why does the Tokenizer flawlessly reconstruct images, yet when the AR model spontaneously generates Token sequences, the decoded images often suffer from structural distortions and unnatural artifacts?
VA-π (Variational Policy Alignment) delves into the structural logic behind this phenomenon, proposing an extremely lightweight and elegant post-training framework. This research abandons the brute-force approach of merely pursuing engineering benchmarks and instead fundamentally bridges the gap between generation and reconstruction using mathematically elegant variational inference (VI) and reinforcement learning (RL).
Highlights: Minimal Compute Cracks 'Implicit Misalignment'
Current visual AR models suffer from a critical underlying disconnect: The Tokenizer learns to perfectly restore real pixels, while the AR generator merely optimizes Token likelihood probabilities in a discrete space. This lack of 'real physical pixel perception' causes Tokens generated by the AR model during inference to easily deviate from the true distribution manifold (Off-manifold).
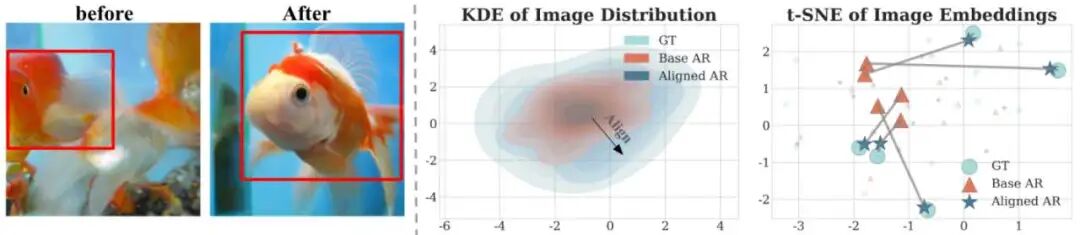
To completely break down the barrier between pixels and Tokens, VA-π offers a stunning solution:
Ultimate training efficiency: Say goodbye to expensive and unstable RLHF compute clusters! With just 8 A100 GPUs and 1% of ImageNet data, fine-tuning takes approximately 25 minutes to achieve transformation.
Leapfrog quality improvement: On LlamaGen-XXL, VA-π reduces the FID metric by nearly half (from 14.36 to 7.65), while the Inception Score (IS) soars from 86.55 to 116.70.
Elegant mathematical deconstruction: Innovatively introduces policy gradients within a variational framework, completely solving the dual challenges of 'non-differentiability' and 'computational explosion' in pixel-level feedback optimization, while cleverly mitigating the 'exposure bias' in autoregressive generation.
Methodology Deep Dive: Reshaping Generation Logic with Variational Inference 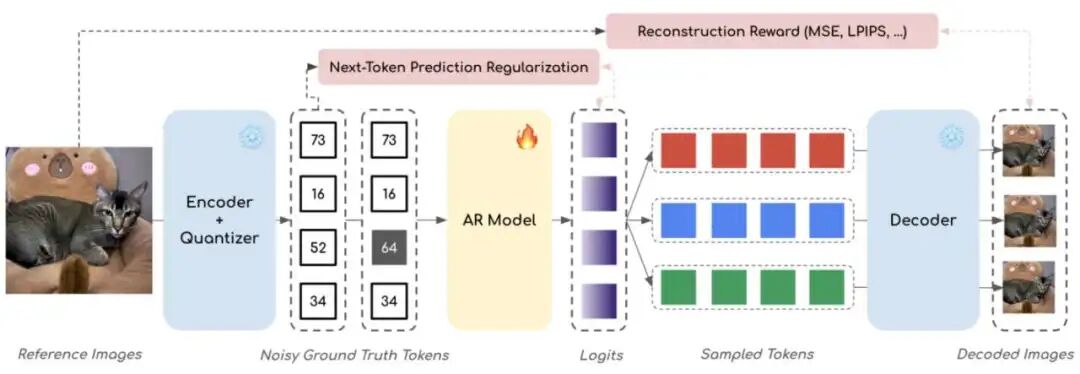
Using real pixel errors to guide discrete Token generation immediately encounters two mountains in practice: 'non-differentiability' and 'computational space explosion.' How does VA-π rigorously derive solutions to overcome these?
Within the VA-π (Variational Policy Alignment) framework, the research team doesn't apply superficial patches but returns to rigorous mathematical theory. As shown in the framework diagram, VA-π is a lightweight post-training framework that achieves pixel-space distribution alignment by optimizing the AR generator.
Below are the four core derivation steps through which VA-π breaks the black box and achieves direct pixel-level alignment:
1. Resolving 'Computational Explosion': Evidence Lower Bound (ELBO) Alignment via Variational Inference
In autoregressive visual generation, our ultimate goal is to maximize the likelihood of real images in pixel space. However, directly computing this integral in discrete Token space is extremely difficult (Intractable).
Drawing inspiration from VAEs, VA-π introduces a variational posterior distribution learned by the AR model to approximate the true posterior. Extremely cleverly, VA-π uses the Teacher Forcing mechanism to construct this posterior distribution—predicting the next Token given the true prefix. This ensures the posterior distribution highly concentrates on Token sequences that can be faithfully restored to the original image, completely avoiding manifold deviation (Off-manifold) caused by error accumulation during Free-running sampling.
Based on this, the research team derives an elegant Evidence Lower Bound (ELBO) optimization objective:
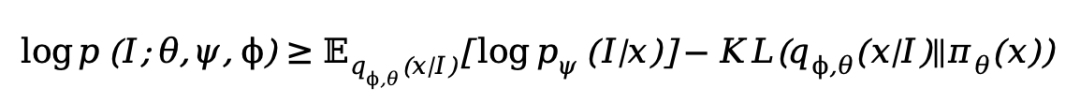
This formula provides two training signals with strong physical meaning:
Reconstruction Term: Provides pixel-level supervision, forcing sequences generated by the AR model under Teacher Forcing to restore the original image.
Prior Regularization Term: Constrains the generated Token distribution to maintain the native language modeling capabilities of the pre-trained AR model.
2. Eliminating Exposure Bias: Simplifying Regularization to Noisy Next-Token Prediction
In the above ELBO formula, the KL regularization term measures the difference between the Teacher-forced distribution and the model's own Free-running distribution. Minimizing this KL divergence essentially directly minimizes the notorious exposure bias in autoregressive generation.
To efficiently achieve this, VA-π introduces contextual noise. By injecting kernel noise with perturbation rate into the true prefix, we obtain a noisy prefix. Ultimately, this complex regularization term is elegantly simplified into a noisy Next-Token prediction loss:
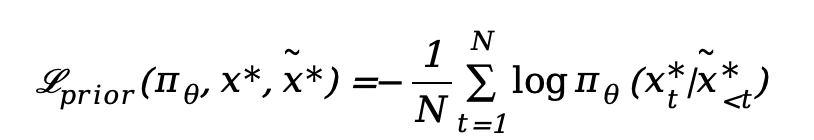
This forced 'difficulty increase' compels the model to generate high-quality Tokens even in noisy contexts, significantly boosting inference robustness.
3. Breaking 'Non-Differentiability': Introducing Reinforcement Learning with Reconstruction Reward
Although ELBO provides an optimization direction, the reconstruction term includes a quantizer and discrete Teacher-forcing sampling, completely blocking gradients (non-differentiable). Relying solely on straight-through estimators (STE) still cannot resolve biases introduced by categorical distribution sampling.
To break this deadlock, VA-π cleverly shifts perspective, treating the AR generator as a policy and using reinforcement learning to maximize the reconstruction reward (i.e., negative reconstruction loss). Given a reference image , true Tokens , and the decoder-restored image , the intrinsic reward is defined as:
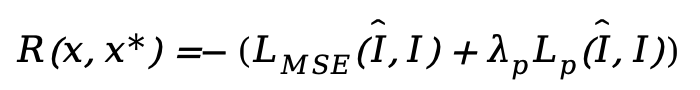
To avoid expensive multiple forward passes by the AR model, noisy Token sequences are also used here. Maximizing this reward directly guides the AR model to generate sequences perfectly aligned in pixel space.
4. Ultimate Fusion: VA-π Policy Optimization with GRPO
At this point, VA-π possesses an RL-based reconstruction reward (Eq. 10) and Next-Token regularization (Eq. 9). This perfectly aligns with the reinforcement learning paradigm of 'policy optimization + KL penalty'!
VA-π adopts the advanced GRPO algorithm to integrate these two into a unified and extremely stable training process. The final VA-π optimization objective is as follows:
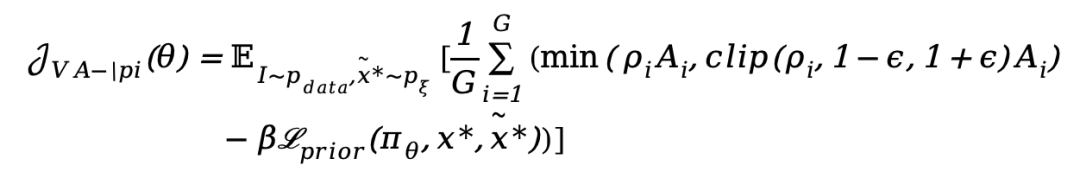
Experimental Showcase: All-Around, Multi-Scale Extreme Pressure Testing
Rigorous theoretical support yields exceptionally solid experimental data. To verify VA-π's universality, the research team conducted comprehensive evaluations on two challenging visual generation tasks: Class-to-Image (C2I) and Text-to-Image (T2I) generation.
Experimental configurations were extremely restrained:
Base Models: Covered pure visual autoregressive benchmark LlamaGen (including 775M XL and 1.4B XXL versions), as well as the current popular unified multimodal large model Janus-Pro 1B.
Minimal Compute: For C2I tasks, only 12.8K extremely small samples from ImageNet-1k were used, with 100 fine-tuning steps (approximately 20-25 minutes). Stable exploration was achieved without relying on classifier-free guidance (CFG).
1. C2I Core Achievements: 25-Minute Fine-Tuning, FID Drops by 50%
On the authoritative ImageNet-1k validation set (50,000 images), VA-π competed against strong opponents including AR-GRPO (an RL method relying on external reward models) and traditional STE methods. The results showed overwhelming superiority.
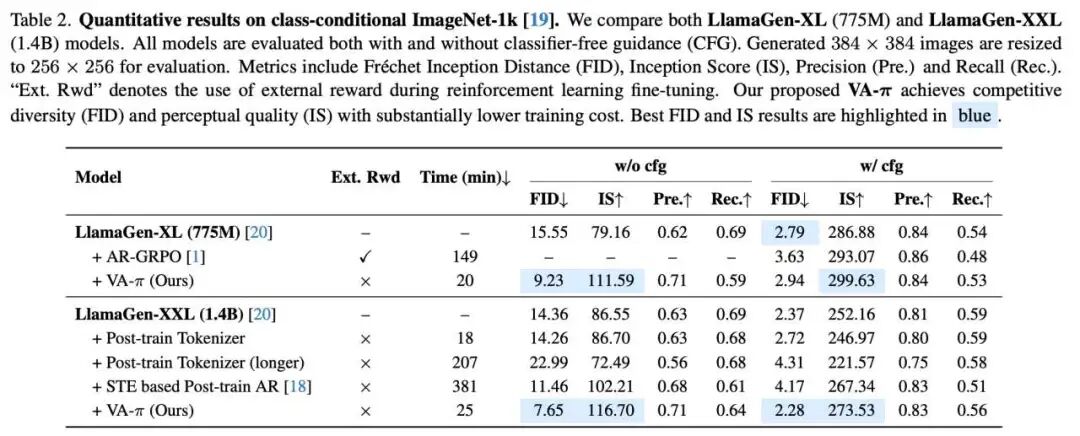
LlamaGen-XXL (1.4B) Transformation: After just 25 minutes of post-training, VA-π reduced the XXL model's FID by nearly 50% (14.35 → 7.65) while significantly boosting the Inception Score (IS) by 30.16. This completely shatters the myth that previous methods couldn't achieve both fidelity and diversity.
Ruthless Supremacy Over Complex RL Routes: On LlamaGen-XL (775M), VA-π (with CFG=2.0) achieved the highest IS score of 299.63, directly surpassing the complex AR-GRPO method. Most crucially, VA-π required no training of any external reward model and was 7.5 times faster in training (only 20 minutes needed)!
2. T2I Core Achievements: No External Rewards Needed, Unified Multimodal Large Models
VA-π's horror (formidable) aspect lies in its extremely strong (extremely strong) generalization capability. Despite using no text alignment (Text-alignment) or human preference rewards during training, it still shone brilliantly in the GenEval benchmark.
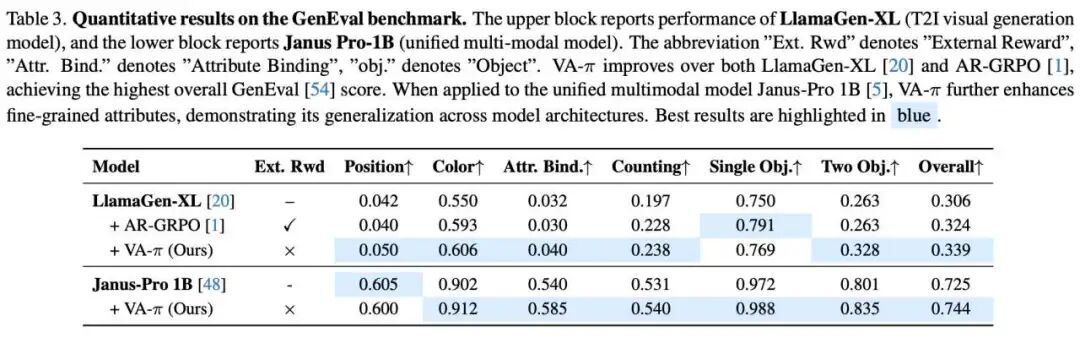
Comprehensive Superiority Over AR-GRPO: On LlamaGen-XL, VA-π outperformed AR-GRPO in most GenEval subtasks, particularly showing significant progress in complex semantics like 'color understanding,' 'counting,' and 'dual-object composition.' More interestingly (as shown in Table 1), on CLIP and HPS v2 metrics evaluating image-text consistency, VA-π—without explicit text preference fine-tuning—actually defeated AR-GRPO, which was specifically optimized for this! This fully proves the enormous generalization benefits brought by 'bottom-level pixel-level alignment.'
Empowering Unified Multimodal Large Models: When we inserted VA-π into Janus-Pro 1B, the model's visual composition ability and semantic grounding capability further leaped (GenEval composite score 0.725 → 0.744). Particularly notable improvements occurred in 'attribute binding' and 'dual-object relationships.' This indicates that VA-π provides a highly scalable general mechanism for large multimodal systems to bridge 'Token-level and perception-level differences' in text-conditional generation.
3. Rejecting 'Black-Box Alchemy': Rigorous Ablation Experiments Prove
To investigate why VA-π is so efficient, the research team conducted extremely hardcore dissections of reward composition, regularization terms, and contextual noise.
Reward and Regularization Are Indispensable (Table 4): If only pixel-level reconstruction rewards (LMSE/Lp) are used, the model rapidly deviates from the pre-trained AR distribution, leading to complete collapse (FID skyrockets to 38.76). Only when introducing the prior regularization term as an auxiliary guardrail can perfect stabilization of Token-level likelihood be achieved, reaching the optimal alignment balance (FID 7.65). 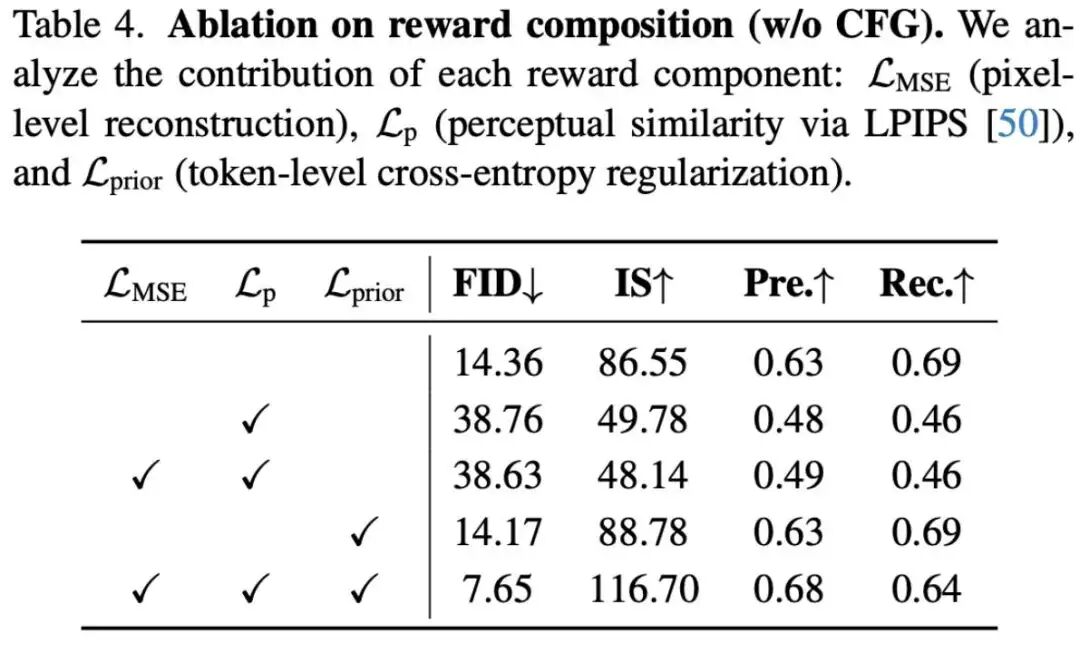
Lightweight CE regularization excels (Fig 4): When comparing KL divergence with cross-entropy (CE) regularization, CE demonstrates superior stability. More importantly, across a broad range of weight intervals (e.g., ), the model achieves an optimal balance between fidelity and diversity, eliminating the need for heuristic parameter tuning. 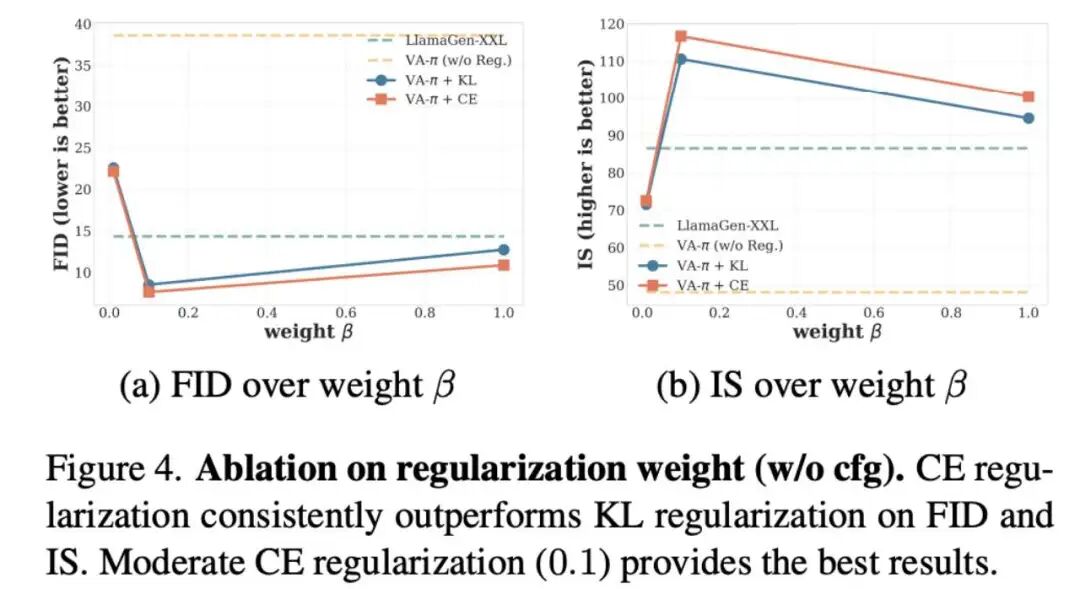
The golden ratio of contextual noise (Table 5): Addressing "Exposure Bias," experiments explore the impact of injected noise ratios . Results show that moderate noise perturbation is the optimal solution for bridging training-inference distribution mismatches, achieving the highest composite score (0.339) in GenEval tests. Both noise-free and excessive noise conditions directly weaken the model's final performance. 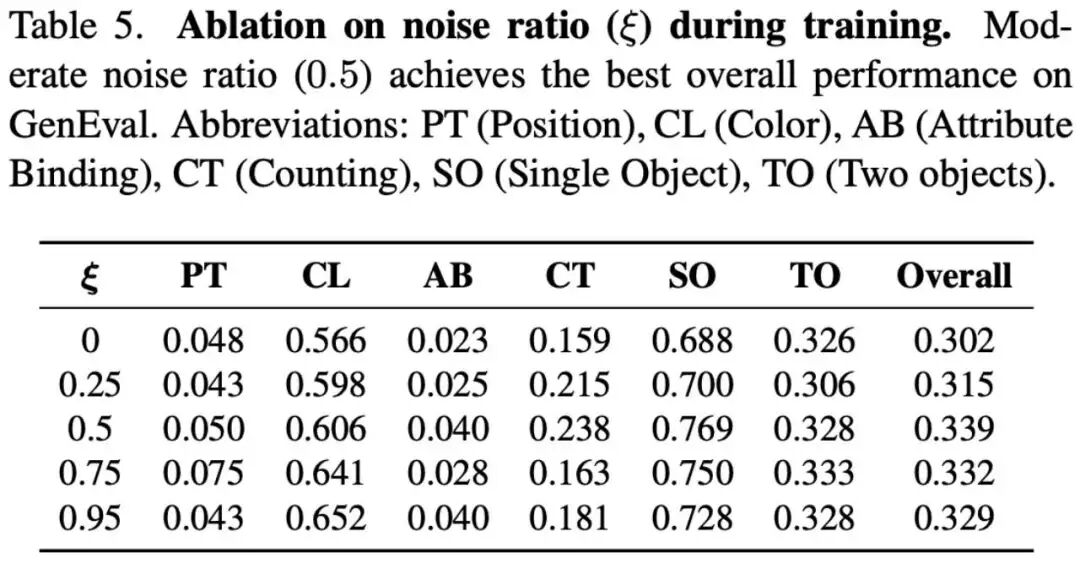
4. Visualization of Results
Class-Conditional Image Generation (ImageNet-1K): We present qualitative comparison results for class-conditional image generation (C2I) on ImageNet-1K categories. All samples use identical decoding settings (CFG = 1.0, temperature = 1.0, top-k = 0, top-p = 1.0). 
ImageNet C2I: kite.
Text-Conditional Image Generation (GenEval): We showcase T2I (text-to-image) qualitative comparison results based on GenEval prompts. All samples use identical decoding settings (CFG = 5.0, temperature = 1.0, top-k = 0, top-p = 1.0).
 GenEval: attribute binding.
GenEval: attribute binding.
Summary: Why does VA-π achieve pixel-level alignment?
Pixel-level intrinsic rewards fully bridge the gap between isolated "token probability optimization" and "real-world physical vision," making AR strategies directly responsible for final reconstruction quality and fundamentally eliminating latent misalignments between tokenizers and generators.
Teacher-forcing based on variational inference (ELBO) reduces complex online multi-step trial-and-error into highly efficient single-pass forward computation, perfectly avoiding computational explosions in long-sequence exploration while achieving pixel-level guidance with minimal computational resources.
ELBO's natural regularization terms enforce "preservation of native distributions" as a robust constraint, ensuring strict autoregressive consistency even when pursuing extreme pixel-level feedback and preventing generative manifold deviations.
References
[1] VA-π: Variational Policy Alignment for Pixel-Aware Autoregressive Generation
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







