Why do many automotive companies favor VLA models?
 03/04 2026
03/04 2026
 613
613
Recently, XPENG unveiled its second-generation Vision-Language-Action (VLA) model. As autonomous driving technology advances, the industry is undergoing a profound shift from manual rule-based systems to large-scale physical world models. Early autonomous driving solutions heavily relied on modular architectures, separating perception, prediction, and planning into independent stages.
However, as driving scenarios grow increasingly complex, bottlenecks caused by information loss between modules and limitations of predefined rules have become more pronounced. XPENG is not alone; Li Auto, Geely, and other automakers are also incorporating VLA models into mass-produced vehicles. Why do so many automakers rely on VLA models?
What advantages does VLA have over modular approaches?
Traditional autonomous driving architectures employ a cascaded design. Sensors collect data, which the perception module processes for object detection and semantic segmentation, outputting object labels. Subsequently, the prediction module calculates potential trajectories of surrounding participants, while the planning module generates the vehicle's driving route based on predefined mathematical models.
In this mode, even minor errors in front-end perception can be amplified in subsequent stages. Moreover, since each module relies on predefined manual interfaces, the system struggles to capture subtle, unstructured information from the environment.
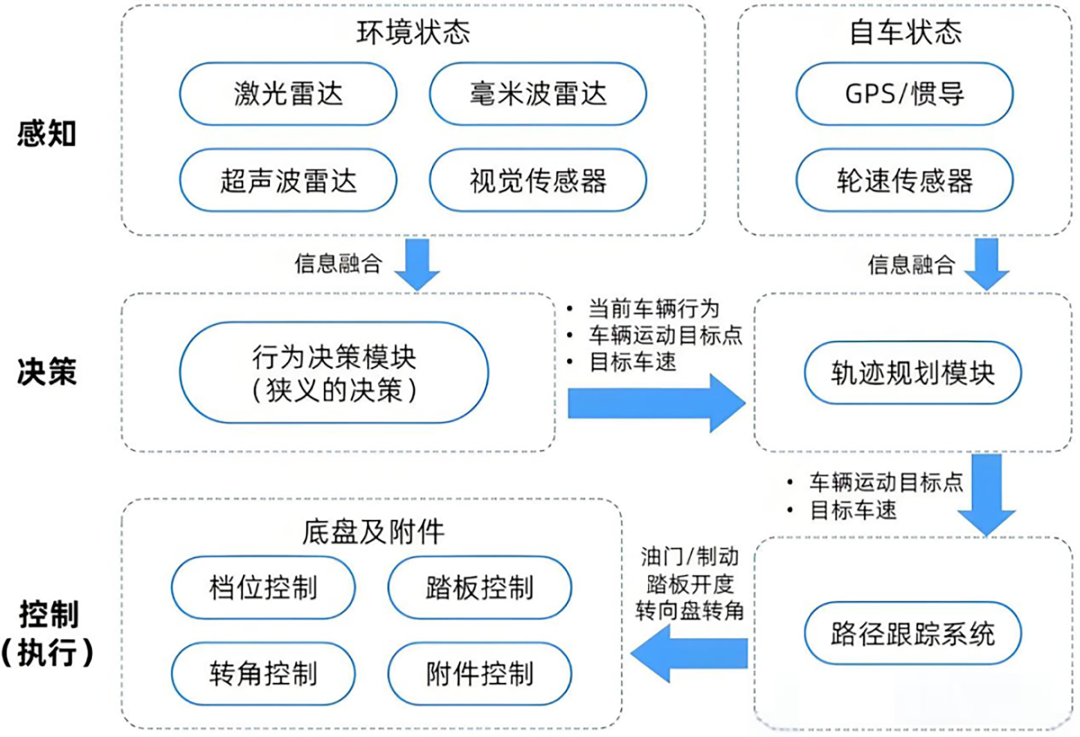
Schematic diagram of modular architecture. Image source: Internet
The introduction of VLA models has revolutionized this process. Vision-Language-Action (VLA) models are inherently end-to-end intelligent systems that integrate multimodal perception, high-level logical reasoning, and low-level action execution through a unified neural network.
Their core value lies in aligning previously independent perception (seeing), logic (thinking), and execution (acting) modules within a shared semantic space. Unlike traditional autonomous driving systems, VLA models not only recognize pixels or geometric structures in the environment but also comprehend the semantic logic behind these signals.
The VLA model comprises three core components: a visual encoder, a large language model (LLM) backbone network, and an action decoder. The visual encoder transforms multi-view images captured by cameras into high-dimensional feature vectors, which encode spatial layouts and object characteristics of the environment. The LLM backbone, serving as the decision-making center, logically processes these visual features using vast world knowledge accumulated during pretraining. The action decoder then translates these abstract reasoning results into specific physical actions, such as steering angles and acceleration/deceleration values.
Schematic diagram of VLA architecture. Image source: Internet
This integrated mapping approach enables the system to handle driving tasks in a manner closer to human cognition. During human driving, the brain does not first mentally plot the exact coordinates of every pedestrian before making calculations; instead, it directly generates evasive actions based on a holistic understanding of the scene (e.g., "this pedestrian might cross the road"). By leveraging a shared Transformer architecture, VLA models co-encode language, visual, and action modalities, constructing a unified semantic space that seamlessly connects perception, understanding, and action decision-making.
Is language translation important?
Many articles introducing XPENG's second-generation VLA model mention the removal of the "language translation" step. What role does language translation play, and is it important for autonomous driving?
Language translation refers to converting visual signals into natural language descriptions (e.g., "A traffic officer is directing traffic at the intersection ahead") and then deriving action commands from these textual descriptions. This design initially aimed to leverage the logical reasoning capabilities of large language models. However, as technology advances toward mass production, its drawbacks have become increasingly apparent.
While natural language excels at expressing abstract logic, it may lack precision when describing highly complex three-dimensional physical worlds. Compressing high-dimensional, continuous visual streams into discrete textual labels inevitably results in the loss of substantial spatial details and motion trends.
Moreover, training VLA models requires researchers to annotate vast amounts of video data with detailed manual narratives, explaining what is happening in each frame and why specific actions are taken. This "nanny-style" supervised learning is not only costly but also fails to keep pace with the model's evolutionary needs due to the slow annotation process.
XPENG's second-generation VLA model abandons language as a "crutch" in favor of a more extreme self-supervised learning approach. Under this framework, the model can directly learn from raw video footage and real driving trajectories. As long as there is video input and corresponding physical action output, the model can autonomously learn causal relationships without human intervention.
Eliminating language also significantly enhances system real-time performance. In autonomous driving, millisecond-level delays directly impact safety. VLA models, with their multi-step reasoning process (vision -> language -> action), often struggle to meet millisecond-level response requirements due to their lengthy computational chains. Directly mapping visual signals to actions eliminates the time-consuming intermediate decoding and generation steps.
To achieve this, the representation of actions must also evolve. Transforming continuous trajectory predictions into discrete action tokens and integrating them into the large model's vocabulary is currently a viable approach. This way, action generation resembles language prediction of the next word, fully leveraging the large model's existing sequence modeling capabilities.
This shift from "language understanding" to "physical intuition" represents an evolution of autonomous driving toward a more advanced form of intelligence. It enables the model to operate like an experienced driver making decisions through muscle memory.
What are the advantages of VLA?
Technological advancements in autonomous driving have enabled systems to perform well on highways or urban roads. However, the most challenging scenarios remain "long-tail" cases. These refer to extreme situations that rarely occur during normal driving and are difficult to cover through exhaustive rule-based approaches. Examples include unusually shaped debris suddenly appearing on the road, complex construction barriers, or non-standard hand gestures from traffic officers.
In traditional architectures, encountering such unfamiliar scenarios may cause the perception module to malfunction or the planning and control module to execute stiff (rigid) emergency braking due to the absence of matching rules.
The VLA model's advantage lies in introducing "understanding" into driving decisions. Large-scale pretrained models possess robust knowledge bases and contextual comprehension abilities. For instance, even if the model has not encountered a specific type of construction fence during training, it can infer from general knowledge learned from internet data that "red-and-white objects typically represent obstacles" or "individuals wearing reflective vests are usually workers."
This knowledge-based decision-making mode enables VLA models to handle complex interaction logic. In scenarios like tidal lanes or unmapped narrow roads, VLA models can analyze the intentions of surrounding vehicles and subtle environmental changes to make more human-like plans. Rather than merely avoiding obstacles, they can understand that "the preceding vehicle's deceleration might be to yield to pedestrians" and proactively adjust accordingly, avoiding the frequent abrupt braking or jerky movements common in traditional systems.
VLA models also possess "dual-system thinking" capabilities. They can achieve instinctive driving reactions akin to fast thinking through rapid pathways while also engaging enhanced reasoning logic for in-depth analysis when encountering extremely complex situations (slow thinking). This flexibility ensures the system maintains efficiency while possessing the upper limit to handle highly challenging decisions.
To address the scarcity of long-tail data, some technical solutions incorporate "world models." These can be viewed as "simulated brains" for autonomous driving systems, capable of predicting the future impact of actions and simulating numerous extreme, real-world-difficult-to-collect hazardous scenarios for self-training. The integration of VLA and world models enables autonomous driving to evolve from "real-world trial-and-error" to "imaginative progression."
This enhanced capability signifies a transformation of autonomous driving systems from "competent drivers" to "wise driving experts." VLA models not only solve the "how to drive" problem but also address the underlying "why drive this way" comprehension issue.
What are the challenges in implementing VLA?
Large models typically require billions or even tens of billions of parameters. Achieving millisecond-level inference responses on vehicle-mounted embedded platforms demands extensive engineering optimizations.
Mixture-of-Experts (MoE) architectures can divide the model into smaller modules specialized in different domains, activating only the most relevant experts at any given moment. This approach significantly reduces computational load during inference without sacrificing model capacity. For example, Li Auto successfully deployed a 32B large model distilled into a 3.2B MoE architecture on its Thor chip.
Compressing inference steps is also crucial. Traditional path generation requires multiple iterations (e.g., Diffusion models). By introducing algorithms like Flow Matching, the original 10-step reasoning process can be compressed to 2 or even 1 step, enabling complete interactive responses at 10Hz frame rates. Additionally, mixed-precision inference (e.g., INT8/FP8/FP4) and customized low-level operator optimizations can further leverage hardware efficiency.
Although VLA models serve as the "brain" responsible for complex cognitive decisions, the industry widely acknowledges the need to retain a rigorously validated traditional control system as a "safety foundation." This hybrid architecture ensures that even if the large model experiences hallucinations or reasoning errors in rare cases, the underlying safety net can maintain the final line of defense.
Final Thoughts
The proliferation of VLA models marks a shift in the focus of autonomous driving data competition. Previously, companies competed based on the volume of manually annotated data. Now, the competition centers on computational power reserves, world model simulation efficiency, and the ability to leverage large-scale unlabeled video data.
The closed loop from logical understanding to physical action in VLA models not only accelerates the maturation of end-to-end technologies but also brings autonomous driving systems one step closer to true "human-like" behavior. As algorithms, computational power, and data continue to improve, physical AI based on VLA architectures will demonstrate its value across broader mobility scenarios, reshaping future standards for safety and efficiency in transportation.
-- END --
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







