Soft-Hardware Integration in Autonomous Driving: Li Auto's Answer
 03/06 2026
03/06 2026
 432
432

In July 2016, Elon Musk terminated Tesla's cooperation with Mobileye, a supplier of intelligent driving chips.
Behind this split lay a clash of philosophies over full-stack closed-loop technology in autonomous driving. Tesla aimed for full-stack control over data and algorithms, but Mobileye refused to fully open up. After negotiations failed, Musk resolved to pursue soft-hardware integration. In subsequent earnings calls, Musk reflected that this "chip-building" gamble allowed Tesla to establish an insurmountable moat in autonomous driving.
Today, Chinese autonomous driving players have also reached the soft-hardware integration stage.
Standing at the 2026 milestone, we see substantial progress in self-developed chips by numerous autonomous driving players. NIO's Shenji chip and XPeng's Turing chip have already been deployed, while Li Auto's Mach 100 chip is set to debut with the all-new Li L9.
However, a common challenge persists: self-developed chips entail extremely high development costs and software adaptation difficulties. Chip tape-outs can cost billions, and algorithm teams spend months on adaptation and optimization, risking scenarios where "peak chip performance fails to translate into real-world efficacy."
If self-developed chips represent an inevitable trend in autonomous driving, how can the pain points of high costs and soft-hardware adaptation be addressed? Recently, Li Auto unveiled research findings that provide theoretical support for integrating intelligent driving software and hardware.
Over the past few years, a key trend in autonomous driving has been the compute arms race. Consumers focus on hardware specs, automakers compete on TOPS (Tera Operations Per Second), with the belief that greater compute power equates to stronger intelligent driving capabilities. We've witnessed compute soar from NVIDIA Orin's 254 TOPS to Thor's 1,000 TOPS, and even higher in domestic self-developed chips, with data constantly refresh (refreshing).
But does Scaling Law apply 100% to intelligent driving?
Not entirely. For instance, with the advent of VLA (Vision-Language-Action) models, autonomous driving faces unprecedented challenges. On one hand, VLA as a logically self-contained architecture requires higher cognitive intelligence to unleash its potential—it must "understand scenes, interpret intentions, and make decisions" like human drivers. On the other hand, automotive intelligent driving differs fundamentally from cloud-based large models. Vehicle chips are constrained by power consumption, heat dissipation, cost, real-time performance, and safety redundancy, making blind parameter and compute stacking unfeasible. The result: models grow smarter, but chips struggle to keep pace.
Li Auto's proposed "co-design law for on-device large language models" identifies the key to breaking this deadlock.
This research addresses two core questions. First, peak chip performance ≠ actual system efficiency; effective compute power matters more. Second, through mathematical methods, a quantifiable, predictable, and implementable framework can be constructed, turning "algorithm-defined chips" from rhetoric into reality.
In short, intelligent driving software and hardware can find optimal solutions for specific scenarios, while suitable hardware-software pairings can be discovered through co-design.
Based on these findings, Li Auto plans to deploy its self-developed Mach 100 chip in the all-new Li L9, challenging the upper limits of automotive intelligence.
So, what does Li Auto's soft-hardware co-design law entail, and what industry pain points does it aim to solve? Let's examine this research.
Algorithms and chips need to "collaborate" as they evolve
In recent years, NVIDIA's computing platforms have been the default choice for high-end automotive intelligent driving. However, as intelligent driving technology advances, NVIDIA faces growing competition. Automakers like Li Auto, XPeng, and NIO are developing self-designed chips, while chipmakers AMD and Qualcomm have also entered the fray, vying for a share of NVIDIA's market.
Why are automakers switching computing platforms? This transformation stems from autonomous driving technology hitting two critical barriers.
The first barrier is the rapid evolution of large models versus the relatively slow iteration of chips, causing hardware to lag behind. As VLA becomes the dominant technical paradigm, intelligent driving models' parameter scales, training data, and capabilities refresh every few months. Yet, automotive-grade chips require 3–5 years from design to tape-out, validation, and deployment. To meet these new model demands, new computing platforms now emphasize native support for MoE sparse computing, ultra-large KV cache capacities, or dynamic resource scheduling—signs that traditional platforms struggle to meet VLA-era performance requirements.
The second barrier is that general-purpose computing platforms fail to fully unlock model capabilities. Intelligent driving models require chips with specific performance parameters, which general-purpose platforms often cannot provide. For example, decision-making in intelligent driving demands extensive MoE invocation capabilities, but general-purpose platforms lack native sparse computing and quantization support. Ensuring low-latency feedback for driving safety is also challenging, as general-purpose platforms may "task-block" each other, compromising output stability. Algorithm adaptation often results in "shoehorning"—sacrificing model precision, real-time responsiveness, or inflating costs with redundant chips.
To overcome these challenges, Li Auto argues in its paper that soft-hardware co-design is the key.
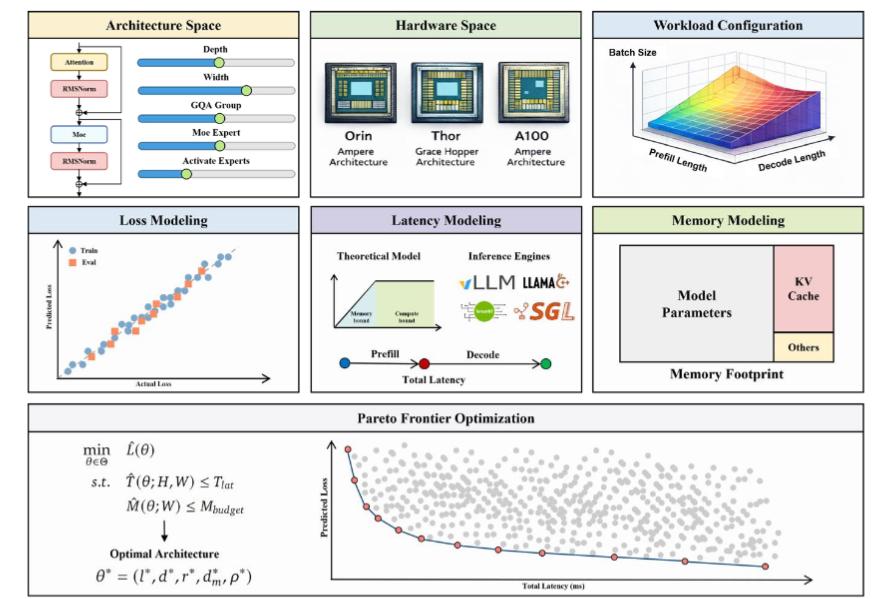
Specifically, Li Auto employs two core mathematical methods to achieve this synergy.
The first is the vehicle-based application of loss function expansion rules, using low-cost methods to "calculate" the model's performance ceiling. This is a common practice in large model R&D. The principle: large models have an inherent "error rate" that grows predictably as model size decreases. By inputting hyperparameters (parameter count, layers, FFN multiplier), final accuracy can be predicted without full training.
In simple terms, running small models a few times can estimate "how smart a large model could become," saving on GPU costs and time.

The second method is a vehicle-based innovation in Roofline performance modeling, "calculating" key hardware parameters required by models. Originally a visual performance analysis framework for HPC (High-Performance Computing), Roofline assesses bottlenecks in application processors. Li Auto extended it for automotive scenarios, adding VLA-specific demands like KV cache (key information caching), MoE routing (expert model allocation mechanisms), and attention mechanisms—factors absent in traditional computing-memory bandwidth balance considerations—to evaluate model impacts on intelligent driving computing platforms.
In simple terms, this calculates the "intelligence ceiling" supported by computing platforms.
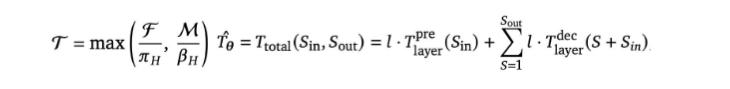
Building on these, the PLAS (Pareto-Optimal LLM Architecture Search) framework emerges, enabling co-design. By inputting chip compute power, bandwidth, cache hierarchy, and engineering constraints (e.g., latency <100ms, power, memory), it automatically generates optimal model architectures—finding the boundary of "highest precision at lowest latency" for current hardware. In short, it identifies the joint optimum for algorithm capabilities and chip design.
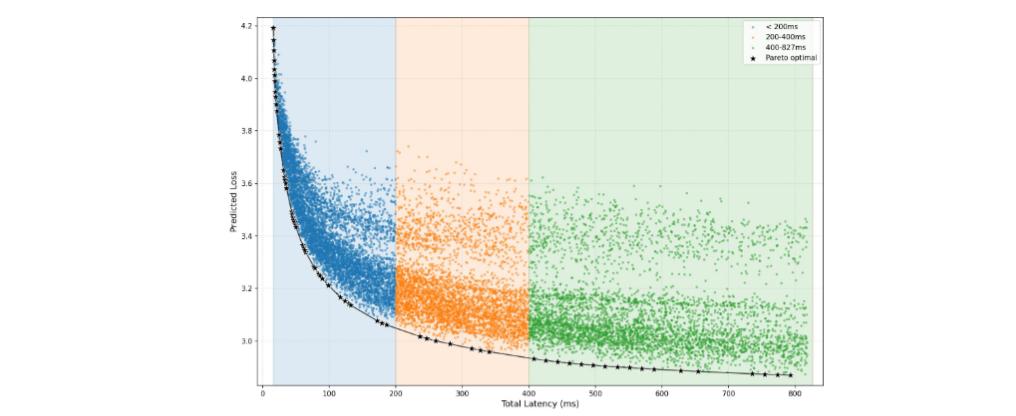
Li Auto also demonstrated Pareto-optimal frontiers across hardware platforms (Jetson Orin/Thor), validating the cross-platform generalizability of its "hardware co-design scaling law" and identifying NVIDIA platform capability ceilings.
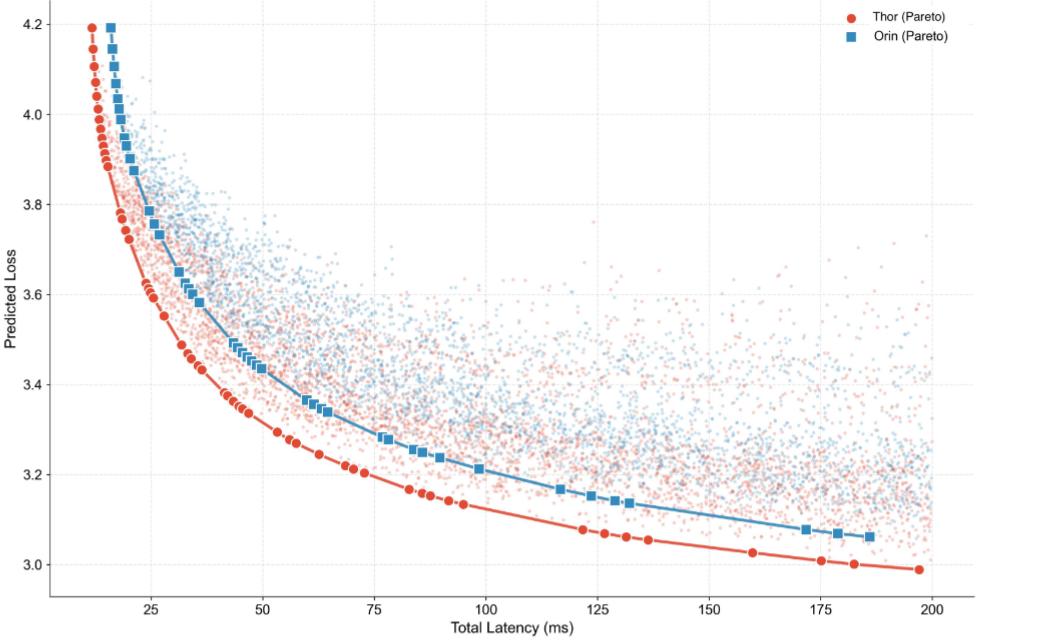
This design paradigm's greatest value lies in ending the fragmented industry processes of "designing chips first, then adapting algorithms" or "developing algorithms first, then finding chips."
"Originally, Orin chips didn't support running language models. But NVIDIA lacked time, so we wrote our own low-level inference engine," Li Auto founder and CEO Li Xiang revealed in an interview.
Traditionally, chip engineers pursued raw compute power while algorithm engineers sought smarter models, only to discover "incompatibility" during integration, wasting resources. Co-design breaks these silos, ensuring chips and algorithms evolve in tandem from the outset.
For autonomous driving players pursuing soft-hardware integration, Li Auto's research offers a replicable blueprint.
No universal chips—only scenario-optimized chips
Li Auto's mathematical co-design process is not overly complex. Yet, in the AI era, the value of a good question far outweighs countless shallow insights.
Why did Li Auto pursue co-design research? It encountered early challenges in deploying autonomous driving technology.
"Deploying VLMs on vehicle chips poses huge challenges, especially on mainstream Orin-X chips designed without large model applications in mind. We had to overcome numerous engineering hurdles," said Zhan Kun, head of Li Auto's foundation models, in 2024. Even during NVIDIA Orin's high-end intelligent driving deployment, Li Auto experienced the pain of "soft-hardware fragmentation." While NVIDIA platforms offered strong theoretical compute, deploying large language models often revealed that "peak chip performance ≠ actual system efficiency."
Elaborately designed model architectures frequently underutilized hardware, while hardware compromises risked impairing model intelligence—like displaying a flawless statue in a damaged state. This disconnection motivated Li Auto to seek a fundamental solution.
The approach focused on enhancing model performance while balancing deployment timelines, hardware, and application costs. Specific goals included: reducing model design and selection cycles from months to one week; delivering superior intelligence without expensive chips; and rapidly selecting optimal model configurations per scenario to shorten development cycles.
From this research, Li Auto distilled six core conclusions, each addressing pain points in on-device large model deployment and underscoring the necessity of self-developed chips.
First, sparse computing will become standard for automotive AI. In typical batch-size-1 automotive scenarios, MoE sparse architectures dominate efficiency. Future vehicle chips must natively support sparse computing and dynamic routing, rather than merely providing dense matrix multiplication. Unlike cloud-based "comprehensive" models, automotive AI demands "specialized and precise" architectures.
Second, memory subsystem design trumps peak compute. The paper highlights "wide-but-shallow" optimal architectures, showing that memory bandwidth and cache efficiency often outweigh theoretical TOPS in determining real-world performance. Chip memory hierarchies must adapt, reserving sufficient high-speed cache for KV caches and attention mechanisms.
Third, phase-aware microarchitecture optimization. During model operation, Prefill and Decode stages have vastly different hardware demands. Prefill requires massive parallel compute, while Decode needs memory bandwidth and space, leaving compute idle. Conventional GPU designs fix these processes, but automotive intelligent driving demands real-time and deterministic performance. New chips must support dynamic microarchitecture reconfiguration or resource allocation to stabilize both stages.
Fourth, break the 4x FFN (Feed-Forward Network) fixed pattern. Traditional Transformers default to a 4x FFN expansion ratio, amplifying dimensions regardless of input complexity before compressing. Given limited automotive compute resources, "full throttle equals fuel explosion." Chips need flexible matrix multiplication and activation function unit ratios to match VLA models' actual workloads.
Fifth, quantization acceleration requires native hardware support. To meet real-time, safety, and power demands, intelligent driving models should ideally quantize from FP16/BF16 to INT8, yielding a 2x acceleration factor. However, Li Auto's tests showed only 1.3–1.6x acceleration on conventional platforms due to nonlinear operator and precision conversion overheads, wasting compute resources. Next-gen chips must natively support mixed-precision computing and operator fusion at the instruction set and unit levels.
Sixth, no universal chips—only scenario-optimized chips. Synthesizing these conclusions, maximizing model capabilities demands rethinking hardware compute architectures, fundamentally proving the necessity of "algorithm-defined chips." Only by deeply understanding upper-layer algorithm needs can the most efficient dedicated compute architectures be designed.
These findings are not theoretical. To validate its co-design law, Li Auto conducted rigorous tests on NVIDIA Jetson Orin/Thor platforms. Results showed that models optimized under the co-design law achieved 19.42% higher precision than Qwen2.5-0.5B at identical latency, directly proving that soft-hardware co-design delivers "superior performance on identical hardware" with immediate, quantifiable engineering benefits.
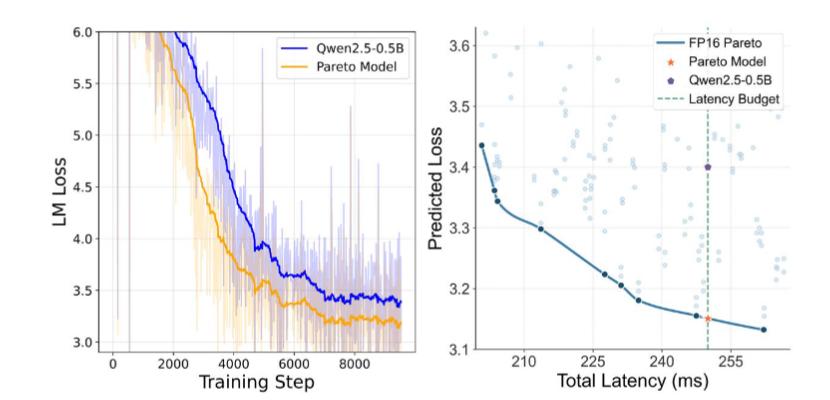
For the product side, this discovery directly led to Li Auto's development of the self-researched Mach 100 chip. As the first model to be equipped with the Mach 100, the all-new Li L9 was even touted by Li Xiang on Weibo as having three times the effective computing power of NVIDIA's Thor-U chip, making it the world's most powerful intelligent driving brain.
Having a self-developed chip not only signifies Li Auto's transition from a "passive chip adapter" to an "algorithm-defined chip" stage but also provides Chinese autonomous driving companies with a theoretical weapon that is "ready to use" in the VLA era.
Li Xiang's AI Engineering Methodology
The integration of software and hardware, along with collaborative development, has long been a compulsory course (which means "compulsory course") for every AI giant globally.
In 2013, Jeff Dean, then head of Google Brain, casually did a calculation on a napkin. The results showed that to support users' use of speech recognition models, Google would need to double its data center cluster. These simple numbers sent chills down the spines of all the executives present.
To avert this crisis, Google promptly launched the TPU development project. The hardware was defined based on an old paper, designing the chip to match the matrix operations required by the algorithm. Fifteen months later, Google developed the TPU and was no longer "held hostage" by GPUs. Today, through Google Cloud and Gemini, Google sells TPUs worldwide.
Google's practical actions prove that only through software-hardware synergy can every bit of computing power be utilized effectively. Li Auto has also found its direction for a closed-loop, full-stack autonomous driving technology on this path.
Recall that in 2025, leading players in intelligent driving technology were still referencing DeepSeek's technology, using distillation methods to bring AI large models "down from the cloud." Li Auto made a series of adjustments to its intelligent driving large models through pre-training, post-training, and reinforcement training, ultimately developing the "Driver Model"—VLA—that rivals human intelligence.
"We conducted extensive research and embraced Deepseek R1 from its launch to its open-source release. DeepSeek's speed exceeded expectations, so the arrival of VLA was faster than anticipated," Li Xiang once summarized.
Today, after achieving software-hardware integration, the "algorithm-native model" tailored for vehicle endpoints enables intelligent driving to optimize the entire chain of perception, decision-making, planning, and control within the same mathematical framework, further reducing system latency, improving accuracy, and enhancing energy efficiency.
This transformation is essentially an evolution of AI engineering capabilities. In the past, engineers relied on experience to fine-tune and iterate through trial and error. Now, with the PLAS framework and mathematical laws, the optimal solution can be "generated with a single click."
"Whenever we want to change and enhance capabilities, the first step is always research, the second step is development, the third step is expressing those capabilities, and the fourth step is transforming them into business value," Li Xiang said.
Li Auto has put considerable effort into achieving this goal.
At the foundational research level, Li Auto's investment can be described as "extravagant." Over the past eight years, Li Auto has consistently increased its R&D investment. In 2025 alone, Li Auto expects its R&D investment to reach 12 billion yuan, with 6 billion yuan allocated to the field of artificial intelligence.
With this R&D investment, we can clearly see the growth trajectory of Li Auto's autonomous driving technology. From 2021 to November 2025, Li Auto has published nearly 50 papers in areas such as BEV (Bird's-eye-view), end-to-end models, VLM (Visual Language Models), VLA (Visual Language Action Models), reinforcement learning, world models, and AI foundation models, with over 2,500 citations. Among these, 32 papers were accepted at top conferences.
In foundational research, Li Auto's organizational structure is also evolving toward a direction more suitable for AI research. In January of this year, Li Auto took the lead in implementing a series of organizational adjustments. Among them, Zhan Kun, Li Auto's Senior Expert in Autonomous Driving Algorithms, took over the foundation model business, overseeing the overall development of Li Auto's VLA foundation models and fully integrating the relevant R&D teams. This marks Li Auto's intelligent driving fully entering the era of AI large models.
At the end of January, Li Xiang also made it clear internally that the technical R&D team's structure would be significantly adjusted, referencing the operational models of the most advanced AI companies and redefining personnel roles based on collaborative construction of silicon-based life forms. Through continuous optimization of its internal structure, Li Auto hopes to achieve deep synergy among its algorithm, chip, and OS teams, enabling research results to be rapidly transformed into mass-production capabilities.
Based on his understanding of AI, Li Xiang has also become the automotive industry's CEO who "most supports" AI development. Recently, Li Xiang also expressed on his social media that learning to use Agents can amplify the gap between top experts and ordinary people.
Perhaps the most important rule in the AI era is to go ALL in AI.
Tesla FSD (Tesla's autonomous driving), once a global leader, has gradually lost its "wow factor" under the pursuit of Chinese autonomous driving companies achieving full-stack technological closure.
The law of software-hardware co-design (which means "collaborative design") is just the beginning. Chinese smart car manufacturers are now defining the upper limits of automotive intelligence.
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







