ICLR 2026 | DragFlow Empowers DiT with Pinpoint Control: A New SOTA in Region-Supervised Drag-based Image Editing
 03/09 2026
03/09 2026
 452
452
Interpretation: The Future of AI-Generated Content
Key Highlights
The first precise region-based image editing framework tailored for the Diffusion Transformer (DiT) architecture.
The research team abandoned the traditional 'point-by-point tracking' approach and innovatively adopted a 'region-affine supervision' paradigm, fully leveraging the powerful prior capabilities of advanced DiT models like FLUX.1.
This method establishes a new benchmark for drag-based image editing, addressing distortion issues in complex scenes that plagued previous approaches.
Why Does Drag-based Editing in the DiT Era Require a New Paradigm?
Drag-based Image Editing enables users to precisely manipulate image content through simple 'drag-and-drop' interactions, offering far superior editing control compared to text-guided methods by providing direct spatial intervention. However, most existing methods are based on UNet architectures like Stable Diffusion (SD) and suffer from two major bottlenecks:
Insufficient Prior Capabilities: SD's generation priors are weak, causing optimized latent vectors to often deviate from the true image manifold, resulting in distortions like warping and blurring in edited images.
Architectural Mismatch: As DiT architecture models (e.g., FLUX) become mainstream in visual generation, their strong generation priors offer hope for solving distortion problems. However, we found that directly migrating traditional drag strategies to DiT architectures fails to deliver significant performance improvements.
Our findings attribute the root cause to fundamental differences in feature map granularity between UNet and DiT network layers:

Through visualization (as shown below), it becomes evident that UNet features consist mostly of blurry semantic blobs, meaning even point-level operations in UNet can effectively influence surrounding semantic information. In contrast, DiT features scaled to the same size clearly outline fine object contours. Applying point-level tracking and constraints to the latter fails to effectively drive region feature editing, akin to 'feeling an elephant blindfolded.'

Proposed Solution: The DragFlow Editing Framework
To overcome this challenge, we propose DragFlow, a region-supervised precise editing framework designed specifically for DiT. Its core innovations include:
Region-Level Affine Supervision: Replacing fragile single-point tracking with affine transformations of entire regions provides DiT with richer, more stable supervision signals, fundamentally resolving feature mismatch issues and eliminating interaction ambiguities inherent in point operations.
Adapter-Enhanced Inversion: Integrating pre-trained feature extractors like IP-Adapter with adapters significantly improves subject consistency and inversion fidelity in CFG-distilled models (e.g., FLUX.1) by injecting ID Embeddings.
Hard-Constrained Background Preservation: Abandoning classic mask loss functions, this approach applies rigid protection to non-edited background regions via adaptive gradient masks, completely avoiding background contamination.
MLLM-Assisted Interaction: Leveraging multimodal large language models (MLLMs) to analyze and understand user intent beforehand, generating editable prompts and operation types (e.g., translation, deformation, rotation) for user selection, enhancing interaction precision while minimizing user effort.
The complete DragFlow framework, shown below, integrates MLLM-assisted interaction, IP-Adapter ID injection, Key & Value Caching, and the core affine-based region drag optimization workflow.
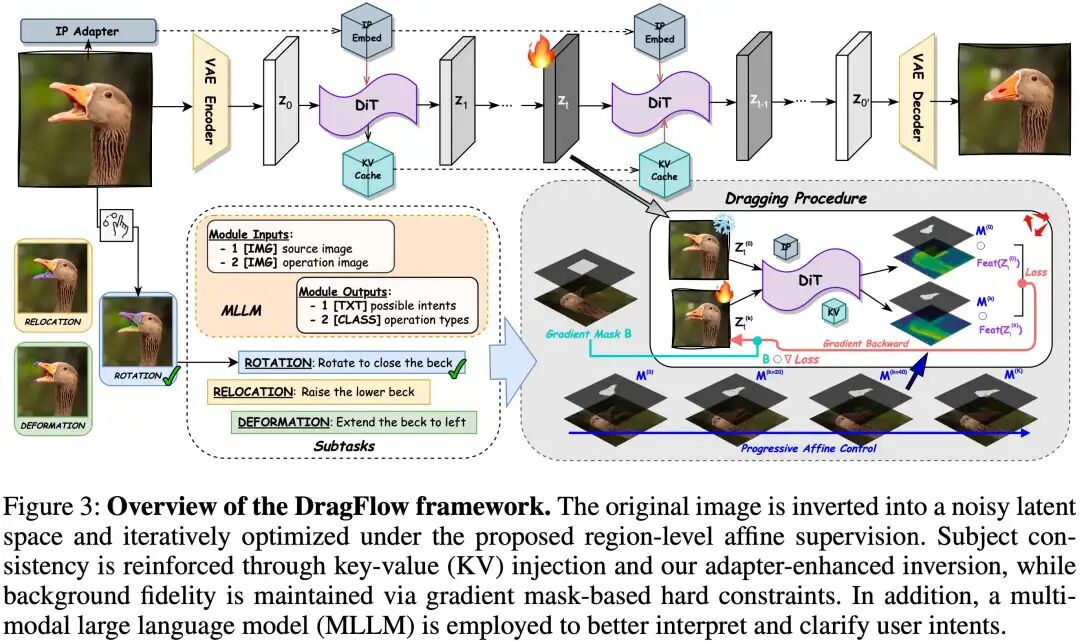
Methodology Deep Dive | DragFlow: Region-Centric Precision Control
DragFlow is designed with the philosophy of treating dragging as holistic region transformations rather than isolated point displacements. This new paradigm, from supervision methods to background handling and identity preservation, is deeply customized for DiT's characteristics.
① Region-Level Affine Supervision: Bidding Farewell to 'Point Tracking'
The core of DragFlow is its innovative region-level supervision strategy. Instead of tracking handle point coordinates at each iteration, it treats the user-specified source region as a whole, gradually 'moving' it to the target position through affine transformations.
1. Iterative Latent Optimization
The entire dragging process optimizes noise-injected latent vectors to ensure feature consistency between the affinely transformed target region and the original source region before optimization.
The loss function is designed as follows:
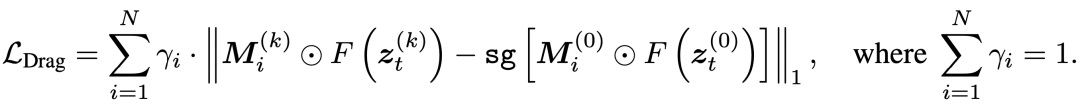
Where:
represents features extracted from DiT's intermediate layers. We found DiT's 17th and 18th double-stream blocks most suitable for drag optimization. denotes the user-specified source region mask, while represents the target region mask computed via affine transformation during the k-th iteration. indicates Stop-gradient, ensuring gradients only flow to the optimized .
2. Affine Transformation for Mask Propagation
The target mask is derived from the source mask through progressively changing affine transformations . Transformation parameters are generated via linear interpolation based on edit type (translation, deformation, or rotation) and iteration step .
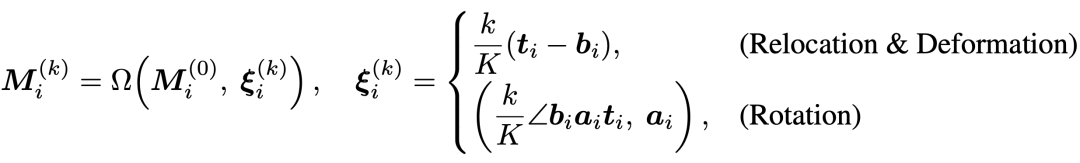
This design offers two major advantages:
Rich Semantic Context: Matching entire region features provides DiT with more stable and robust gradient signals compared to single-point features, effectively avoiding local optima and artifacts.Eliminated Tracking Needs: By progressively supervising regions through geometric movement rather than content point tracking, DragFlow fundamentally avoids the chain-reaction editing failures common in traditional methods, ensuring more stable and reliable processes.
② Background and Subject Fidelity: Tailored Strategies for DiT
Rich supervision signals alone aren't sufficient. On powerful DiT models, maintaining background invariance and subject identity consistency poses greater challenges, especially for CFG-distilled models suffering from 'inversion drift.'
1. Background Preservation: From 'Soft Constraints' to 'Hard Isolation'
Traditional methods use auxiliary loss terms to constrain background regions, but this proves ineffective in DragFlow as it competes with the dragging loss and is sensitive to inversion errors.
Our solution imposes hard constraints: After each gradient update, we directly reset the latent vectors of background regions to values from the original unedited branch:
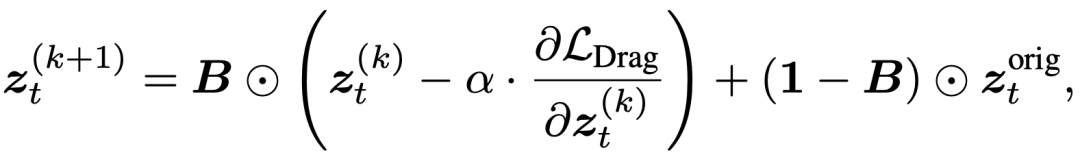
Where:
represents the background mask encompassing all editing trajectories. comes from a pure reconstruction branch, representing the most faithful original background information. Though this 'hard isolation' method increases minor computational overhead, its effectiveness far surpasses soft constraints, achieving near-perfect background fidelity.
2. Subject Consistency: Adapter-Enhanced Inversion
Traditional key-value injection (KV injection) performs poorly on CFG-distilled models like FLUX. We found FLUX suffers from more severe inversion drift than SD (see table below).

To address this, we introduce adapter-enhanced inversion: During inversion and generation, we inject subject identity representations extracted by a pre-trained open-domain adapter (e.g., IP-Adapter). This significantly improves inversion quality and subject consistency in edited results without requiring additional training.
As shown below, incorporating IP-Adapter Embeddings during inversion and sampling dramatically enhances subject identity preservation compared to using KV injection alone.

Experiments | Comprehensive SOTA Performance Across Two Benchmarks
To comprehensively evaluate DragFlow, we constructed a new region-level dragging benchmark **ReD Bench**, featuring richer region-to-region correspondences, task type labels (translation, deformation, rotation), and intent descriptions. We also conducted compatibility testing on the existing DragBench-DR.
Quantitative Analysis
As shown in Table 2, DragFlow achieves top performance across multiple metrics on both benchmarks:
**Mean Distance (MD)**: DragFlow obtains the lowest and scores under existing 'point-dragging' and 'patch-dragging' evaluation standards, respectively, indicating its editing results achieve the highest spatial alignment precision with user instructions.**Image Fidelity (IF)**: DragFlow ranks highest in background fidelity (), source-to-target content fidelity (), and source region discrimination before and after dragging (), proving its ability to precisely edit specified regions while maximally preserving image quality and subject features.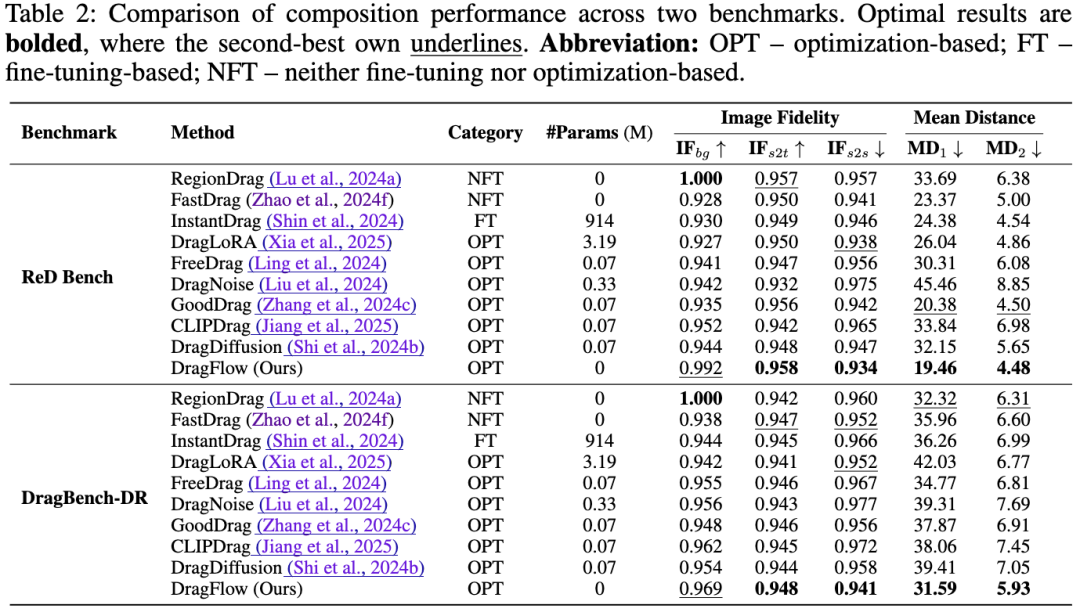
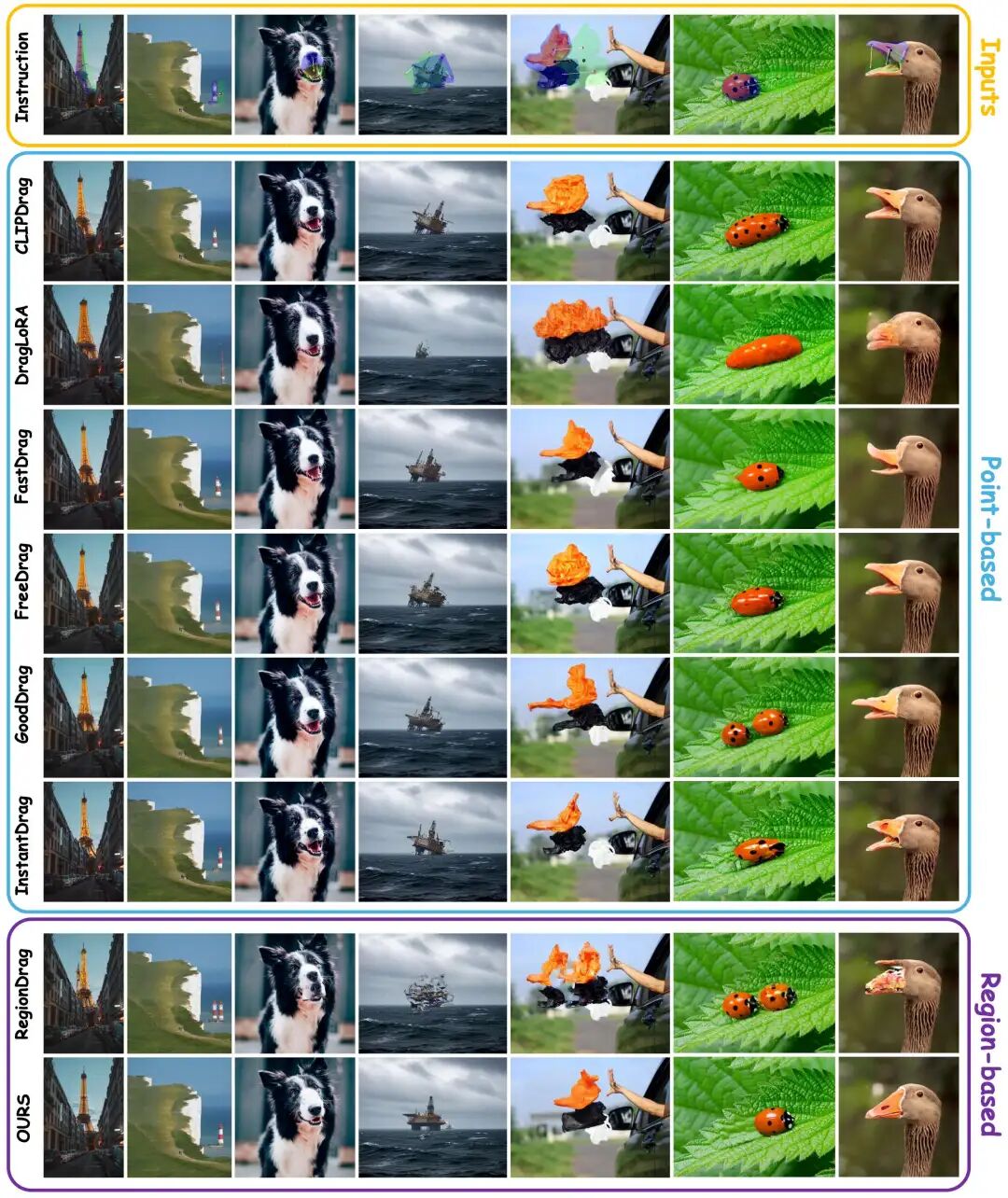
Qualitative Analysis
The visual comparison below demonstrates DragFlow's superiority over existing methods. Whether handling complex structures (buildings), non-rigid deformations (animals), or fine details (oil platforms), DragFlow accurately executes dragging instructions while maintaining overall scene coherence and realistic texture. In contrast, other methods suffer from severe structural distortions, transformation failures, or intent misunderstandings.
Ablation Studies
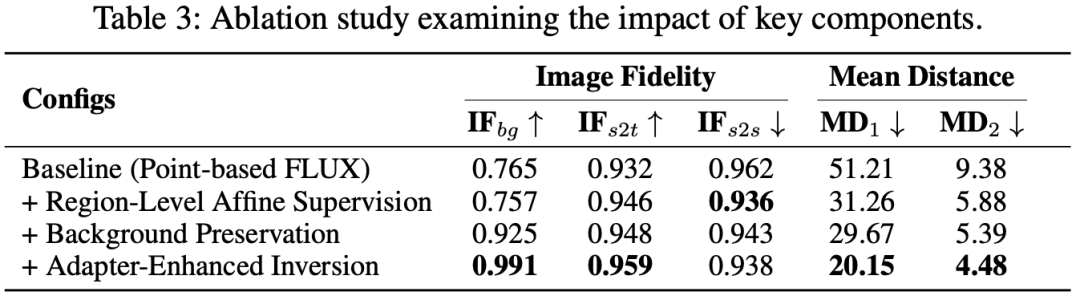
We verified DragFlow's effectiveness by incrementally adding its core components. Results (see Table 3 and Figure 6) clearly show:
Switching from point-based baseline to region-level affine supervision dramatically reduces MD (51.21 → 31.26), proving regional supervision's superiority.Adding background preservation boosts from 0.757 to 0.925, significantly improving background quality.Finally introducing adapter-enhanced inversion further increases , strengthening subject consistency while reducing MD to its lowest (20.15).
Qualitative ablation comparisons (shown below) illustrate the effects before and after each modification:

Meanwhile, multiple quantitative metrics used in the ablation experiments also confirm that each component of DragFlow is indispensable and synergistic:
Summary | DragFlow Ushers in a New Era of Precise DiT Editing
DragFlow represents a paradigm revolution in the field of drag-and-drop editing. Its contributions and advantages can be summarized as follows:
Pioneering DiT Drag Framework: It successfully migrates and adapts drag-and-drop editing capabilities from UNet to the more powerful DiT architecture for the first time, unlocking SOTA-level generative priors for models like FLUX. Region Supervision Core: The proposed "region-level affine supervision" paradigm replaces fragile, sparse point feature tracking with holistic, robust region feature matching, fundamentally solving editing challenges under the DiT architecture. Systematic Fidelity Design: By combining adapter-enhanced inversion with hard-constrained background preservation, it provides a complete solution for CFG-distilled models suffering from inversion drift, ensuring both subject consistency and background purity. Establishing New Benchmarks: The introduced ReD Bench offers more comprehensive and true-intention-aligned evaluation standards for region-level drag editing research.
DragFlow not only comprehensively outperforms existing methods across all metrics but, more importantly, charts a clear and effective path for leveraging the powerful priors of next-generation DiT generative architectures to achieve refined and controllable image editing.
References
[1] DragFlow: Unleashing DiT Priors with Region Based Supervision for Drag Editing
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







