Even without Proprietary Data, AI Applications Can Excel, Consensus and Divergence among Top VCs
 07/05 2024
07/05 2024
 730
730

Hot money has flowed from large models to AI applications, with numerous births and failures occurring simultaneously.
In September last year, a16z listed a Top 50 AI applications list, and now over 20 on the list have fallen behind.
The domestic situation seems even worse. An intuitive judgment: How many AI applications can you name (not excluding those in the B-end)?
QuestMobile data shows that the operational data activity rate of leading AIGC Apps is low, all below 20%; in terms of loyalty, the 3-day retention rate is below 50%; the risk of churn is high, with the uninstall rate of some Apps exceeding 50%.
On the one hand, the performance of basic large models is insufficient; on the other hand, they have not been perfectly integrated with scenarios. The former is difficult to solve on one's own; for the latter, many entrepreneurs pin their hopes on proprietary data, believing that even if they haven't found a business model, they can achieve a flywheel effect based on user behavior data accumulation. This view has been recognized by Vinod Khosla, the "first investor in OpenAI": As long as everyone doesn't suffer significant losses in recent years, the key is to get the model as widely used as possible, with the aim of obtaining a large amount of data for iterative optimization.
However, two co-founders of a16z poured cold water on the "data moat." They believe that while every company can enhance its competitiveness by utilizing its own data, most proprietary data does not have significant advantages.
What is most important for AI applications? This article will combine a16z's conversation on "Build Your Startup With AI" and Business Insider's interviews with nine top VC investors to sort out referential viewpoints.
1. Experience Matters More than Technology
The First Batch of "Casualties"
VCs actively seek truly impactful personalized solutions rather than generic tools.
In the previous article, we explored why a16z favors ElevenLabs: ChatGPT can indeed accomplish some tasks, but more customized and vertical products will emerge in the future.
This raises a question: If ChatGPT were 100 times more powerful than it is now, who would emerge victorious in this "battle royale"?
Let's start with a counterexample.
Marc Andreessen said: "You may know how to utilize chatbots to build SaaS applications and write marketing copy with LLM, so you build an entire system. Six months later, ChatGPT crushes you (suspiciously referring to Jasper).
Moore from Foundation Capital said that founders should first focus on the problems they can solve and then choose the corresponding technology. Moreover, not every product needs a chatbot. She has long been tired of dealing with startups seeking investment with generic use cases.
Until six months ago, Moore would still receive numerous pitches from founders claiming, "We will become the enterprise version of OpenAI." Her response was: "I firmly believe that OpenAI itself will become the enterprise version of OpenAI."
According to Ben Horowitz's viewpoint: You must be truly unique. If a startup can capture differentiation, root itself in a specific domain, grasp all nuances, etc., even if ChatGPT evolves, it won't have much impact on you. But if you're just calculating that your large model can reach ChatGPT-4 levels in two years, you should consider whether to continue.
Optimizing Processes and Enhancing Experiences
For startups aiming to create AI applications, how can they avoid the above situations?
Fundamentally, Ben Horowitz finds this question somewhat tricky as it involves issues of "correctness."
For example, why can AI only serve as a copilot and not the main driver? Because humans cannot fully trust AI.
A truly useful AI application should be able to serve as the main driver. Can this problem be solved? Anyway, it's difficult now, and you don't know whether to solve it from the model level or the application level.
However, Ben Horowitz pointed out an area where models are not good at - processes.
When you use AI to create videos, it involves a series of steps such as copywriting, sound production, and image generation, involving multiple tools. A single model cannot understand your ultimate demands, but an excellent application can. It integrates all tools into a process, greatly improving production efficiency. Many times, an application aims to achieve a certain process, not just the technology itself.
For example, Shidao reviewed SunoV3, which can write its own solos but only supports "one-pot" output without track adjustments. This means that if you want to use SunoV3 to create a mature song, you must navigate different production stacks - generating samples, melodies, vocals, and piecing them together one by one. This would waste time for professional music creators.
Hazard from Flybridge has a similar viewpoint - truly smart founders will think: either use basic components to radically change the user experience or complete tasks in very specific ways.
Some investors said they no longer prefer "point" solutions - such as online payment processing or project management - and are more inclined toward full-stack solutions.
Rak Garg, a partner at Bain Capital Ventures, values very vertical use cases. He favors "hyper-vertical" AI startups that spark change in small niches within specific industries and cites two "sample" applications:
EvenUp, which focuses primarily on personal injury claims. Lawyers only need to upload plaintiff information, and EvenUp automatically generates a complete report detailing loss details, injury details, and more.
Norm.ai, which primarily addresses compliance issues for large banks, identifies and eliminates compliance risks, shortens compliance time, and enables automatic and unlimited task delegation. AI senior agents answer questions at any time and take action based on legal and regulatory requirements.
Note! Crowded tracks are never favored. Shah, a partner at Obvious Ventures, added: In some tracks, technology has long been commoditized. For example, note-taking and productivity tools, marketing, and copywriting. You must truly stand out to become the N+1 company.
Technology Won't Make You Money
How do you judge the value of an application? Ask customers how much they are willing to pay.
Ben Horowitz believes that this is the true touchstone for measuring the depth and importance of the value you create.
Further, how do you choose a pricing strategy? The first option is to reasonably increase the price based on the cost price; the second is to price based on value. That is, judge the actual value of the product to the customer's business. If the business value is $1 million, can I charge 10%, or $100,000? Why $100,000 instead of $5,000? Because it's worth $1 million to the customer, and they're willing to pay 10%.
In a16z's investment portfolio, there is a startup focused on services such as debt collection. Customers cannot directly use ChatGPT for debt collection, but they can recover money by purchasing debt collection services. This bridges the gap between value and cost. It means that even if some products are technically similar, they can still earn a fortune by providing specific solutions to business problems, which are of great value to customers.
Ben Horowitz added another viewpoint: In the future, the performance gap between open-source and closed-source models will be leveled. There will be fierce competition among models, and the one with the lowest cost will win. Then, the real value lies in the tool layer, and whoever can provide people with a smooth experience will prevail.
2. Can Data Serve as a Moat?
Does data determine success or failure? It roughly divides into two camps.
Pro: Data is crucial, represented by Vinod Khosla, among others.
Vinod Khosla believes that startups' goal in recent years is not to make money but to get their models as widely used as possible, with the aim of obtaining a large amount of data for continuous evolution.
Building unique applications requires unique high-quality data. Wang Jinlin, the founding partner of Foothill Ventures, shared: In reality, what kind of companies to invest in depends on whether they have unique applications. It must possess unique high-quality data, rely on large models developed by other companies, but can provide excellent enterprise services based on unique data. This is an investment-worthy enterprise.
Another Silicon Valley investor, Zhang Lu, the founding partner of Fusion Fund, shared: Having vast amounts of high-quality data is a core advantage for companies in the AI era, and the quality of data is more important than quantity. I am bullish on healthcare because most medical data is not in the hands of traditional tech companies. Worried about data being used for commercial purposes, these companies are reluctant to share data with Microsoft, Google, and others. They prefer to adopt new technologies to enable AI internally and tend to cooperate with startups.
Greylock, a venture capital firm, is somewhat "fence-sitting": Replicable proprietary datasets can create points of differentiation, and only data generated when customers use products can form long-term barriers. For example, datasets generated by customers marking their own behavior data or interacting with products. Additionally, for many vertical industries, data remains in chaotic traditional systems. Therefore, the battlefield for AI startups has shifted from the "old barrier" of data sources to the "new barrier" of data processing (including synthetic data).
Con: Data is important but not absolute, represented by NFX, a16z, and others.
NFX has a famous "nihilistic" viewpoint - AI applications are like bottled water. The firm's research on hundreds of AI application-layer startups found that currently, it is unlikely to achieve differentiation in data and models: unstructured data may give companies an advantage for a while, but ultimately, data alone is insufficient, and models can often be interchangeable in most cases.
Where can you find application differentiation? One is user experience. In cryptocurrency, user experience is like eating glass. AI now faces a similar issue. Will someone come up with a stunning AI application? But it won't be 100% a pure chatbot. The second is distribution, involving issues of confrontation with social platforms. The third is customer perceived value, which may turn into brand marketing, infusing emotional value into the richest and most mundane materials.
a16z is not so "extreme," but both leaders denied the claim that "proprietary data is the most important barrier."
Marc Andreessen described a scenario:
A chain of hospitals said, "I have a lot of proprietary data that I can use to build AI solutions. Isn't that unique?"
Andreessen believes that in almost all cases, this claim does not hold. The above "advantage" is just an illusion. Because the amount of available data on the internet and in various environments is astonishingly large. Therefore, even if you cannot access specific personal medical information, you can still obtain other vast amounts of medical information, which is more valuable than so-called "proprietary data." Even if "proprietary data" sometimes works, it will not become a critical barrier in most cases.
He added an argument: so far, we have not seen a rich or mature data market. If data really had tremendous value, it would have a clear market price. This somehow proves that the value of data is not as high as people imagine.
Ben Horowitz concurred. He believes that raw data - those datasets that have not undergone any processing - are overvalued. For example, many datasets considered most valuable, such as a company's own codebase, are stored on GitHub. None of the companies a16z has worked with have built independent programming models based on their own code.
He pointed out that every company can enhance its competitiveness by utilizing its own data, such as Meta using it to train large models. However, most proprietary data does not have significant advantages (only very specific types of data have real value). Therefore, it is unrealistic to think that collecting data can be monetized like selling oil or that it is a new oil resource.
In summary, the proponents believe that proprietary data is precious due to its scarcity; the opponents believe that proprietary data is only scarce in a few cases.
Interestingly, a16z did recently lead a $100 million investment in Hebbia, an AI search engine. Hebbia aims at vast amounts of non-public data, claiming to be able to read and understand unstructured private data that has not been accessed. Its official blog even challenges Google - Google only indexes 4% of the world's data, while Hebbia aims to process the remaining 96%. If true, then so-called proprietary data is essentially "naked."
Following this line of thought, two questions can be raised:
1. What is truly "scarce" data? Ben Horowitz described another scenario: For insurance companies, you can access people's lifespan information from general databases but don't know their specific health conditions and lifestyles. At this time, the truly valuable data is the expected lifespan of people with specific medical records and lab results.
2. Does having more and better data automatically make top-tier applications better? If so, which is more important: data quality or "massiveness"? If not, which is more crucial: experience or data? Shidao believes that in the short term, data will bring a flywheel effect, and experience optimization depends on data, but in the long run, if AI applications experience "inflation," the role of data as a moat will also be questionable. Looking forward to seeing everyone's insightful viewpoints in the comments section.
Source of images in this article: Internet illustrations
-
![]()
Dissecting Alibaba's Earnings Report: Legacy Businesses Stabilize, New Growth Narratives Emerge
-
![]()
Teasing Huang, Being Adorable! Olaf Robot Debuts at GTC: Is Embodied AI Finding Its 'Killer App'?
-
![]()
Tencent Music Reports 11 Billion Yuan in Earnings, Yet Its Stock Price Plummets by 30%. What Concerns the Market?
-
![]()
Farewell to the Subsidy Era: China's AI Cloud Services Usher in a New Cycle of 'Value Restoration'
-
![]()
Where Has Roborock's Profit Gone?
-
![]()
Revenue Surges to 3.76 Billion as Horizon Ramps Up Future Investments
-
![]()
Has the Smartphone Era Embraced Price Hikes? Is Pausing New Releases the Optimal Strategy?
-
![]()
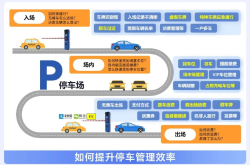
Elevating Vehicle Owner Experience and Boosting Management Efficiency: Hikvision's Parking Solutions Take Center Stage