9.11 and 9.9 large models are all wrong, scenarios will become the moat of AI search
 07/26 2024
07/26 2024
 618
618
Preface:
According to the report released by Gartner, a global research and consulting company, in February this year, the search volume of traditional search engines is expected to decline by 25% by 2026.
This prediction highlights the significant changes in people's search habits as generative AI technology continues to evolve, thereby driving rapid advancements in the field of AI search.
Author | Fang Wensan
Image Source | Network

Comparison of 9.11 and 9.9 shows large models' mistakes
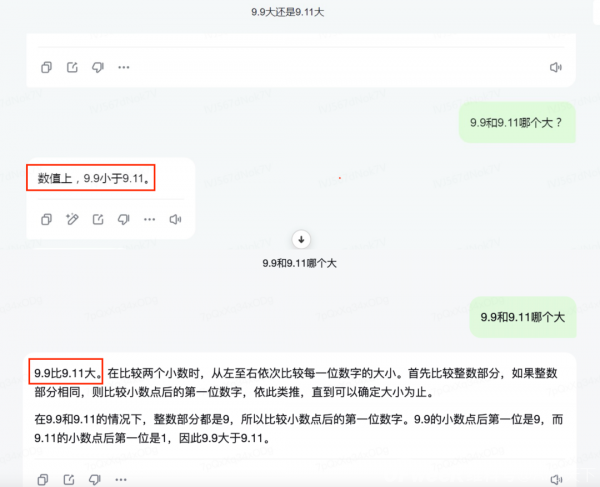
In the field of mathematics, comparing the magnitudes of two decimals is a basic problem. However, when this question is posed to current AI large models, it triggers a series of incorrect answers.
Specifically, when asked [which is greater, 9.11 or 9.9], most AI large models erroneously believe that 9.11 is greater than 9.9, a mistake stemming from incorrect comparisons of the digits after the decimal point.
Most large models, when handling such problems, erroneously compare the digits after the decimal point while neglecting the magnitude of the integer part.
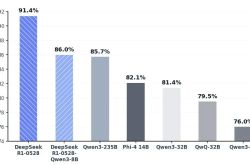
In this incident, multiple well-known AI large models failed to answer this question correctly, including but not limited to ChatGPT-4o, ByteDance's Doubao, Kimi from the Dark Side of the Moon, etc.
Out of 12 AI large models tested, only Ali Tongyi Qianwen, Baidu Wenxin Yiyan, Minimax, and Tencent Yuanbao provided the correct answer, while the remaining 8 models failed to do so.
Poor performance in certain scenarios reflects technological limitations
From a technical perspective, when large models analyze text, they typically use specific mechanisms to break the text into smaller units for processing. This segmentation method may not be rigorous enough when dealing with mathematical problems, leading to situations where the meaning is taken out of context.
① The insufficiency of AI large models in mathematical capabilities partly stems from the inherent limitations of their technical architecture.
Current AI large models are primarily based on the Transformer architecture, which excels in processing sequential data but has limitations in the accuracy of mathematics and logical reasoning.
The Transformer model relies on a self-attention mechanism to capture dependencies in the input data.
However, this mechanism may fail to effectively capture the precise order and logical structure of mathematical operations when processing mathematical expressions.
② AI large models often use floating-point numbers to represent values, but this representation method can introduce errors when comparing precise values after the decimal point, leading to incorrect mathematical judgments.
Although large models are exposed to vast amounts of data during training, their generalization capabilities are still insufficient in mathematical problems, especially when dealing with unseen mathematical problems or scenarios requiring complex reasoning.
③ The original design intent of large models may focus more on textual thinking than numerical thinking.
They excel at processing natural language but struggle in domains that require precise calculations and strict logic, such as mathematics.
④ The quality and diversity of training data directly affect the mathematical capabilities of AI large models.
Existing training datasets lack descriptions of mathematical logic and reasoning processes, and models fail to learn the logical chains of mathematical problem-solving.
The selection and adaptability of scenarios in AI technology are crucial
Although [9.11] and [9.9] large models may encounter challenges in certain scenarios, considering specific scenarios as the moat of AI search is a strategic way of thinking.
-
![]()
DeepSeek R1's Steady Progress Ushers in a Moment of Glory for Chinese AI
-
![]()
JD.com's Impact on Meituan Remains Limited; The Real Battle Shifts to Instant Retail
-
![]()
Is 150,000 yuan the right price for a luxury car?
-
![]()
Image Enhancement, AI Expansion: Honor 400 Series Pioneers the "Li Jian" Era
-
![]()
DeepSeek Revolutionizes Search Industry, Poised to Rewrite Traffic Distribution Patterns
-
![]()
Wei Jianjun Compares Automotive Industry to Evergrande: Is it a Warning or Confusion?
-
![]()
vivo S30 Pro mini Review: Periscope Telephoto and Dimensity 9300+, Small Screen with Impressive Performance
-
![]()
iPhone 17 Pro Max Leaks: Are Apple Fans Prepared for the Next Big Leap?