Apple researchers question large language models! We tested 6 of them and discovered 4 major truths
 10/14 2024
10/14 2024
 623
623
After failing in the automotive business, Apple has decided to increase its investment in generative AI and transfer some employees from the automotive division to the AI division. However, when it comes to AI, Apple seems less confident than domestic and foreign companies such as Baidu, iFLYTEK, OpenAI, and xAI.
Recently, Apple researchers published a paper titled "Understanding the Limitations of Mathematical Reasoning in Large Language Models," questioning the mathematical reasoning abilities of large language models and even arguing that they do not possess genuine reasoning capabilities.
In the paper, Apple researchers provide a simple example by posing a question to a large language model: "Oliver picked 44 kiwis on Friday and 58 on Saturday. On Sunday, he picked twice as many kiwis as on Friday. How many kiwis did Oliver pick in total?" At this point, large language models are able to correctly calculate the answer.

(Image source: Doubao AI generation)
However, when researchers added a modifier to the question, stating that "On Sunday, he picked twice as many kiwis as on Friday, with 5 being smaller than average," some large language models gave incorrect answers, tending to subtract these five smaller kiwis.
During the use of large language models, Xiao Lei has also encountered instances where the models gave incorrect answers, with one even making basic multiplication errors. Nevertheless, large language models are continually evolving, and many previously common errors have been addressed by new technologies.
Apple researchers criticize the mathematical reasoning abilities of large language models, but is this a true reflection of their limitations, or merely an excuse for Apple's own lagging AI technology? After conducting tests, we have arrived at a conclusion.
Which large language models can answer Apple's questions?
For this large language model comparison review, Xiao Lei selected six globally renowned products, including: 1. GPT-4o; 2. iFLYTEK Spark; 3. Doubao; 4. Kimi; 5. Wenxin 3.5; 6. GPT-4o mini. As Wenxin Large Model 4.0 is paid, while the other large language models are free (GPT-4o offers a limited number of free queries per day), for fairness, Xiao Lei chose the free Wenxin Large Model 3.5.
Without further ado, let's dive straight into the testing phase.
I. Kiwi Question: Wenxin Falls Short
For the first round of testing, we chose the kiwi question mentioned by Apple researchers (correct answer: 190 kiwis). From a human perspective, the size of the kiwis does not affect the calculation of the total, but this changes when viewed through the lens of large language models.
In this round, four out of five large language models passed the test, with Doubao and Kimi specifically reminding that the size of the kiwis does not affect the total count. GPT-4o also correctly calculated the total, but due to the translation of the word "average," it additionally calculated the average number of kiwis picked per day over three days. The only large model that did not give the correct answer was Wenxin Large Model 3.5, which excluded five smaller kiwis and arrived at an incorrect total of 185 kiwis.

(Image source: GPT screenshot)
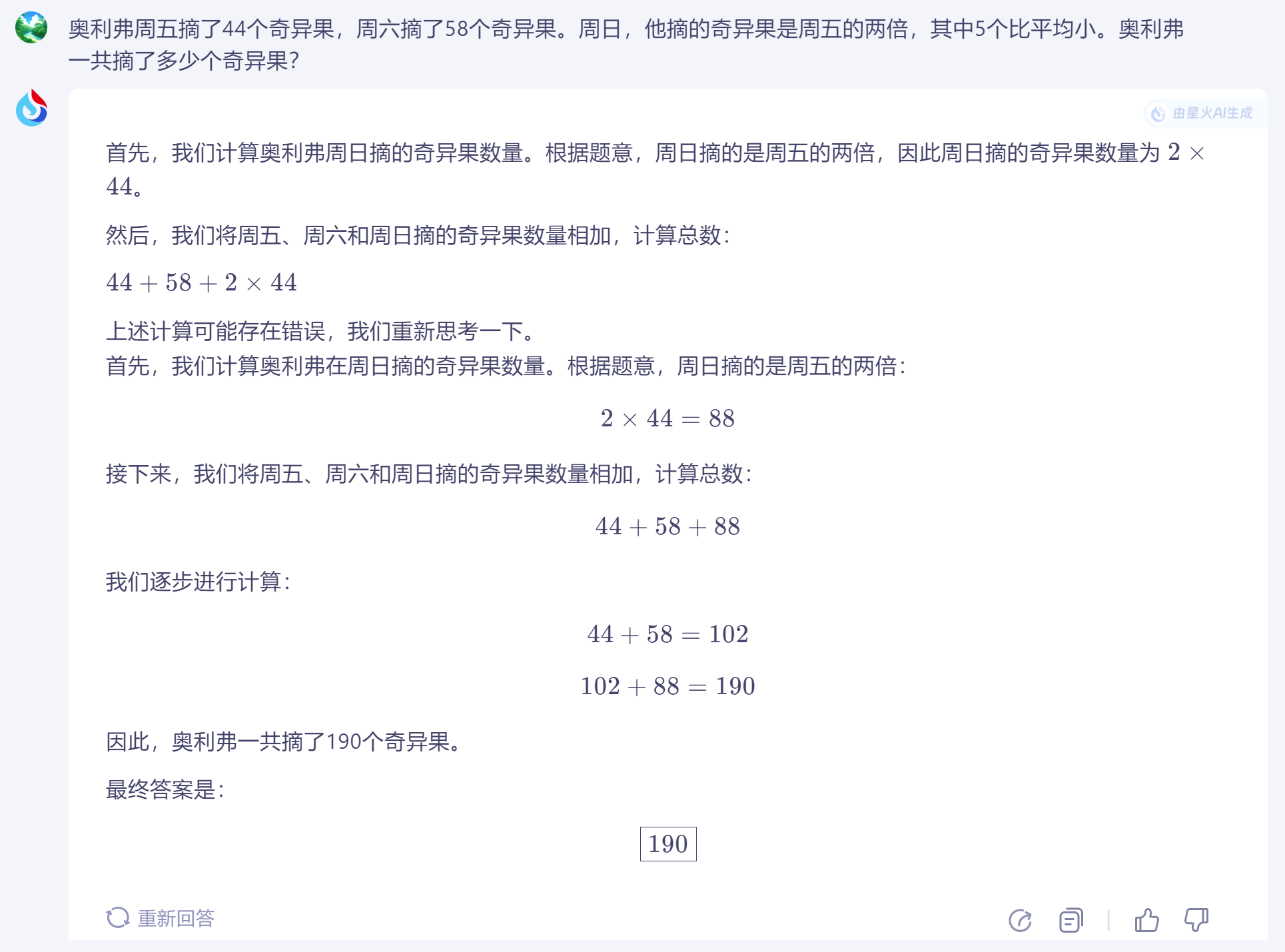
(Image source: iFLYTEK Spark screenshot)

(Image source: Doubao screenshot)
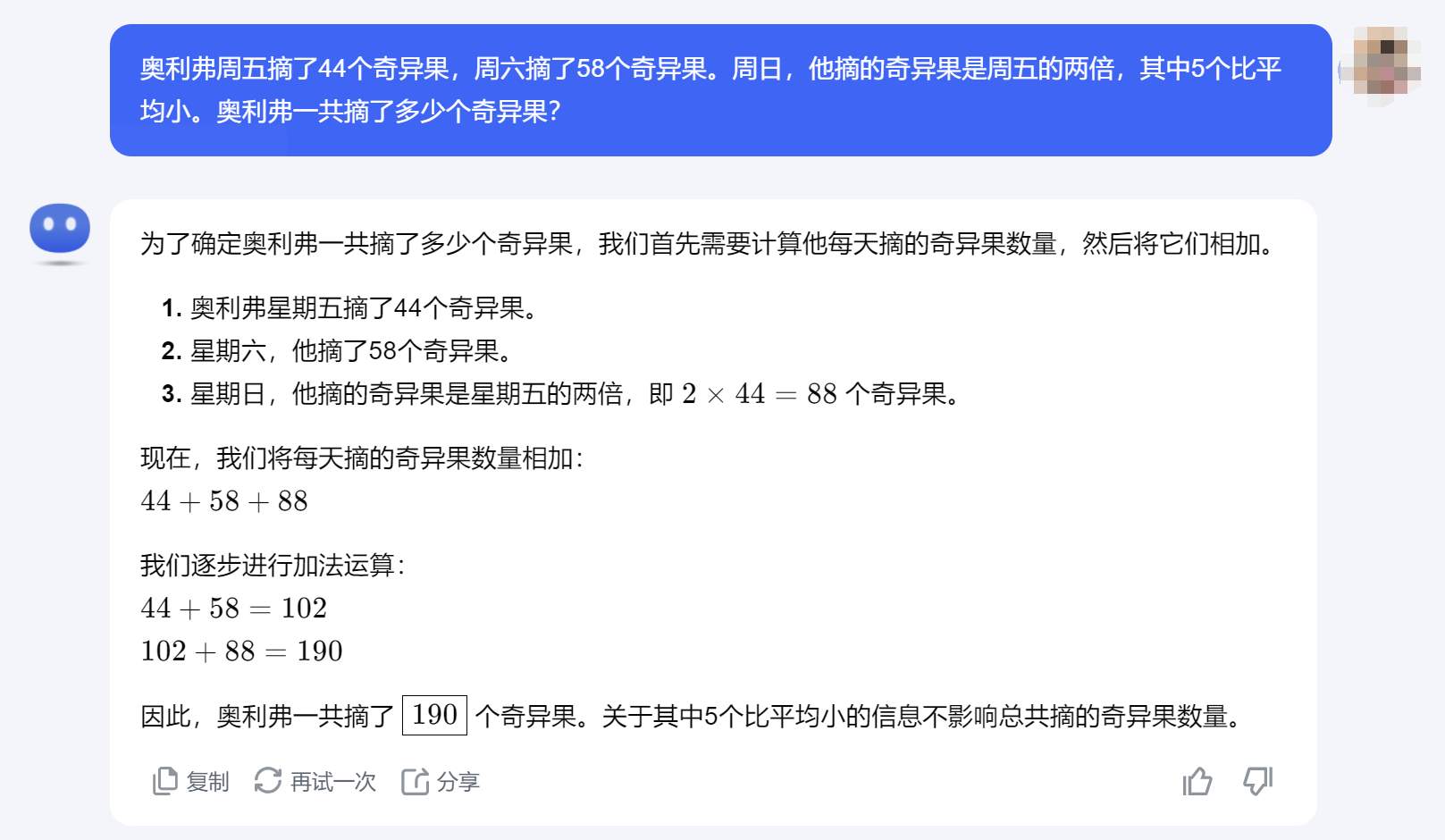
(Image source: Kimi screenshot)

(Image source: Wenxin screenshot)
Apple researchers' paper mentions that GPT-4o mini made an error when calculating this question. After switching to this model, Xiao Lei recalculated the question and, sure enough, GPT-4o mini also gave an incorrect answer.

(Image source: GPT-4o mini screenshot)
Does the accuracy of large language models in solving math problems positively correlate with their parameter count? GPT-4o mini is a smaller model that prioritizes low cost and fast response, with a significantly lower parameter count compared to GPT-4o. The difference in parameter counts likely contributes to the varying results between GPT-4o and GPT-4o mini when reasoning about math problems.
The same is true for Wenxin Large Model. Although there are no official figures, it is estimated that the reasoning cost of Wenxin 4.0 is 8-10 times higher than that of Wenxin 3.5, suggesting the significantly smaller parameter count of the latter.
II. Bus Question: Wenxin Wins
The question for this round of testing was a civil service exam-style math problem, which read as follows:
Due to the influx of tourists during the National Day holiday, a tourist city has seen a significant increase in visitors. The bus company has decided to simplify bus routes and shorten travel times. Buses numbered 1, 2, and 3 depart from the station simultaneously at 7 am. The time taken for these buses to return to the station is 30 minutes, 45 minutes, and 60 minutes, respectively. The buses do not stop for breaks in between. When will they all return to the station simultaneously for the second time? (Correct answer: 1 pm)
The results of this round of testing surprised Xiao Lei. During the test, Xiao Lei tried four large models consecutively, and all of them gave incorrect answers. The only large language model that did not make a mistake was Wenxin 3.5.
Despite Wenxin 3.5's poor performance in the first round, Xiao Lei had no expectations for it. However, to Xiao Lei's surprise, Wenxin 3.5 excelled and became the only model to correctly solve the problem. Even the smaller GPT-4o mini failed to give the correct answer in subsequent tests.

(Image source: GPT screenshot)

(Image source: iFLYTEK Spark screenshot)

(Image source: Doubao screenshot)

(Image source: Kimi screenshot)

(Image source: Wenxin screenshot)

(Image source: GPT-4o mini screenshot)
After much contemplation, Xiao Lei believes the only explanation is that as China's leading search engine, Baidu has a deeper understanding of Chinese language and thought patterns, enabling it to accurately interpret the meaning of the word "arrival." Other large models mistook the initial departure and stop at the bus station as the first arrival, failing to grasp the true meaning of "arrival."
Compared to math, this question poses a higher challenge to Chinese comprehension ability. However, the performance of these large language models also underscores the need for improvement in their understanding of human logic. While Wenxin 3.5's victory demonstrates its strength, there is also the possibility of strategic advantage. Therefore, Xiao Lei prepared a third round of hellishly difficult testing.
III. Athlete Question: Free Versions Fail, Paid Version Succeeds
The third question is also a civil service exam-style math problem, but unlike the previous ones, it contains no distracting information and purely tests the computational abilities of large language models. The question reads as follows:
A class of 39 students participated in three sports events: sprinting, long jump, and throwing. The number of participants in each event was 23, 18, and 21, respectively. Five students participated in all three events, 3 only in long jump, and 9 only in throwing. How many students participated only in sprinting? (Correct answer: 9)
Unfortunately, all five large models and one smaller model failed this round of testing, with varying answers and flawed problem-solving approaches.

(Image source: GPT screenshot)

(Image source: iFLYTEK Spark screenshot)

(Image source: Doubao screenshot)

(Image source: Kimi screenshot)

(Image source: Wenxin screenshot)

(Image source: GPT-4o mini screenshot)
In the end, Xiao Lei had to use the paid version of OpenAI o1-preview to calculate the answer, which, as expected, gave the correct result.

(Image source: GPT-4o o1-preview screenshot)
Both the free GPT-4o and the paid o1-preview, both under OpenAI, gave different answers. The reason may lie in the limited resources available to free users, resulting in inferior computational abilities compared to the paid version.
Parameters Determine Performance, Paid Upgrades Enhance Experience
Among the five large models and one smaller model tested in these three rounds, the smallest model, GPT-4o mini, performed the worst, giving incorrect answers in all three rounds.
We can draw the following conclusions:
1. Are smaller models only suitable as placeholders for larger ones?
GPT-4o mini's performance demonstrates that when dealing with complex reasoning problems, smaller models with fewer parameters and resources are more prone to errors. While companies like Baidu, OpenAI, Google, and Microsoft are actively researching smaller models, they may only serve as adequate placeholders for everyday use, answering basic questions at a lower cost. This is analogous to hiring a primary school student versus a PhD candidate – intelligence comes at a price.
According to research firm Epoch AI, the computational power required to train cutting-edge large models doubles every 6-10 months. This immense computational demand places significant economic pressure on AI companies, even giants like Google and Microsoft. As a result, while smaller models may currently lag behind larger ones in performance, AI companies will continue to develop and refine them over time to enhance their capabilities.

(Image source: Doubao AI generation)
2. Want smarter AI services? Pay up.
The free versions of several large models performed similarly, capable of solving math problems with distracting conditions. However, when confronted with linguistically ambiguous or overly complex math problems, their performance suffered. Fortunately, in the face of Lei Tech's hellishly difficult question, the paid o1-preview model ultimately gave the correct answer, salvaging the reputation of large language models and proving that only paid users can experience the best of what they have to offer.
3. Local large models have local advantages, and Baidu is stable.
It can be seen from the fact that Wenxin 3.5 outperforms other competitors in the second test that large language models rely on a large amount of data processing. However, the amount of data and the ease of access vary among different countries or regions. Due to differences in language and living habits, the large model with better overall performance may not necessarily win in specific scenarios. Therefore, large language models also need localization adaptation.
4. Large models are still far from human intelligence, so don't be fooled by exaggerated claims.
Driven by capital, many media outlets, self-media, startups, and even influential entrepreneurs are promoting the "AI threat theory", claiming that AI has surpassed human intelligence. They often use individual cases to prove that AI large models have achieved doctoral or even higher levels of intelligence. However, when we test these large models with common math problems or work tasks, they are easily stumped.
Large models and AI certainly pose many security threats, such as the danger posed by out-of-control autonomous vehicles to urban traffic and human life. However, to claim that AI intelligence can approach or replace human intelligence is purely misleading.
Large models may indeed be overestimated, but it is a fact that Apple is falling behind
On balance, the views of Apple researchers are partly right and partly wrong. Current AI lacks sufficient logical reasoning ability, especially when facing complex mathematical problems. However, AI is not completely devoid of logical reasoning. Even Wenxin 3.5, which is relatively outdated, demonstrated its ability to interpret and reason with text and mathematics in the second round of testing.
The first GPT was released in 2018 with only 117 million parameters. By 2020, GPT-3 had grown to 175 billion parameters. In just six years, GPT has experienced significant improvements in user experience with each new generation.
The biggest problem with current large language models is still the limited number of parameters and low computing power. Even with relatively abundant resources, o1-preview struggled with mathematical problems that other large models found unsolvable, yet it still provided correct answers. As large models continue to optimize, increase their parameters, and enhance their computing power, their reasoning abilities will naturally improve.
When Apple entered the new energy vehicle market, it suffered heavy losses of billions of dollars and eventually gave up. Now, as Apple ventures into the field of generative AI, its researchers are again questioning the capabilities of large language models, raising doubts about the progress of Apple's generative AI projects. Rather than criticizing other AI large models, Apple would be better served by increasing its investment in AI research and development and accelerating its layout in generative AI, given the latter's even greater financial demands compared to new energy vehicles.
If Apple misses the best opportunity to develop and deploy generative AI, and OpenAI, Google, Microsoft, xAI, and other companies divide up the overseas market with their AI large models, while Baidu, iFLYTEK, Alibaba, Douyin, and other companies occupy the domestic market with their AI large models, Apple's generative AI business may end up with the same fate as its new energy vehicle business.
The images in this article are from: 123RF Stock Photo Library Source: Leikeji
-
![]()
The Story Behind the 'Elephant's' Shift: Shineray Automobile's Quest for Brand Resurgence and Innovation
-
![]()
315 Exposes AI Black Market: Large Models Manipulated, Alarming Truth Revealed
-
![]()
Just Now, Jensen Huang Kept the Entire Silicon Valley Awake Again
-
![]()
Directly from Guangzhou's 'Problematic Vehicle Exhibition': Traditional Brand EVs Face Major Challenges—Is It Time to Learn from New Players?
-
![]()
After Watching 3·15, Are You Afraid to Use AI? To Prevent AI Poisoning, Major AI Companies Have Three Tricks Up Their Sleeves
-
![]()
OPPO and Vivo Raise Prices Together: A Major Upheaval in the 2026 Smartphone Market
-
![]()
AI Phones Hit a Pivotal Moment: Between Doubao and Qianwen, Gemini Chooses a Unique Approach
-
16,000 Employees Affected! The Biggest Job Cuts in the History of an AI Titan