Large models reach a strategic crossroads in AI, and companies like ByteDance face a yawning crisis
 10/25 2024
10/25 2024
 416
416


"Many AI companies pursue a 'large and comprehensive' approach, facing commercial challenges and market size limitations. Although deep reasoning has long-term value, few companies dare to invest and persist in this direction."
@ New technological knowledge original
Recently, ByteDance made a big splash in AI again.
An intern at ByteDance, dissatisfied with the team's resource allocation, poisoned the model training process with malicious code, causing significant losses for ByteDance.
Although the claim of 'resource allocation issues' has not been fully substantiated, the fact that an intern could tamper with the training model so easily at least indicates that ByteDance has not given sufficient attention to text model training, leading to lax oversight.
Compared to large text models, ByteDance has been actively pursuing video capabilities, launching two new video models: PixelDance1 and Seaweed2.

This resource tilt reflects a critical divergence among domestic tech giants at the current juncture of LLM development: With limited computing resources, should future large models focus on video or continue to develop text capabilities?
This divergence has become even more crucial and thorny since OpenAI launched the o1 model capable of deep reasoning.
01.
AI video limitations encounter market indifference

At this critical juncture, Baidu CEO Robin Li recently made a bold statement, declaring that Baidu would not pursue video generation like Sora.
The reason lies in Baidu's belief that current video large models are still immature and far from commercial viability. In Li's words, "It may take 10 or even 20 years before we see any business returns."
This assessment is not unfounded.
According to SimilarWeb statistics, Luma AI, a leading AI video generation company globally, recorded only 11.81 million total visits in September, a decrease of 38.49% month-on-month.

Similarly, Runway, a pioneer in AI video generation, recorded only 7.558 million visits in September, less than 1/400 of ChatGPT's traffic.
The lack of user acceptance primarily stems from product flaws.
Taking domestic AI video generation models as an example, despite the emergence of Sora in February this year, leading domestic companies such as Kuaishou, ByteDance, and Zhipu Qingyan have launched their video models. However, it must be acknowledged that all current video models suffer from two significant shortcomings:
Firstly, they struggle to balance cost and quality.
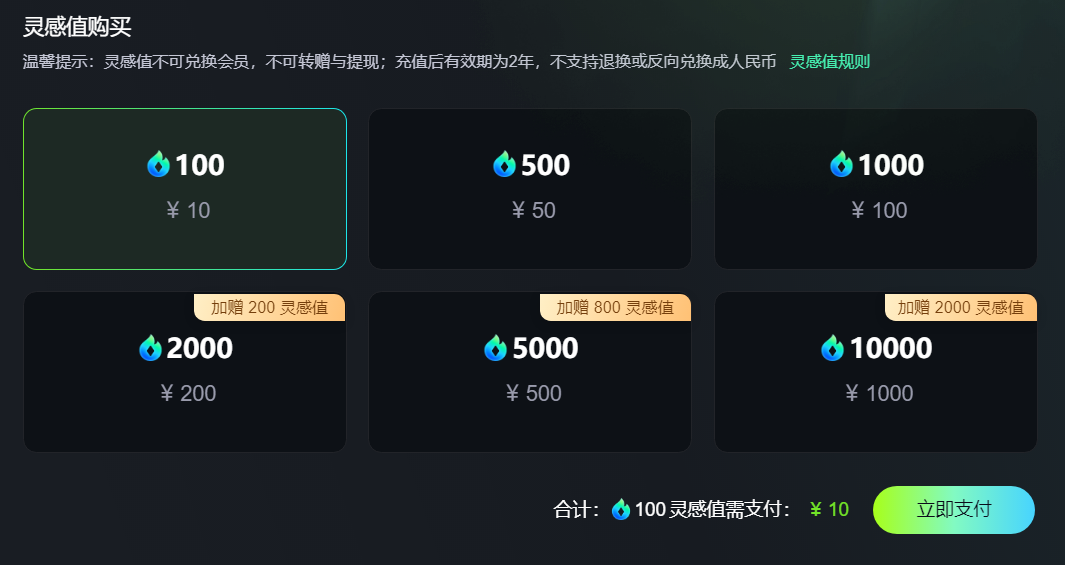
Source: Keling
Taking Kuaishou's Keling as an example, while its generated effects are considered top-notch among domestic video models, the cost is substantial. Generating a 5-second video consumes 10 inspiration points (1 point = 1 yuan), taking approximately 2-5 minutes.
Based on this cost estimation, generating a one-minute short video would cost users at least over ten yuan and take around half an hour.
Moreover, this does not account for the need to regenerate due to AI misunderstandings, which would further increase costs.
Source: Keling
In contrast, Zhipu Qingyan, one of the "Six Tigers of AI" in China, offers a free-to-use video model called "Qingying," but its generated visuals resemble 90s 3D animations, leaving much to be desired.
Although free, the generation time remains lengthy, with users waiting 3-5 minutes for a 5-second clip.

Source: Zhipu Qingyan
Another major shortcoming of AI video generation is the persistent "AI" flavor.
This is a common issue among all video models.
Regardless of how realistic the appearance of characters or objects may seem, viewers often feel something is amiss, akin to the "Uncanny Valley" effect, leaving them uncomfortable.
Ultimately, this reflects inadequate technology.
While most AI video generation algorithms strive to mimic real-world physics and the movements of humans and animals, they struggle to fully comprehend the semantics and emotions behind the data, leading to a lack of "soul" in generated content.

Source: Keling
This overt "AI" flavor significantly contributes to public bias against AI creations.
Due to these shortcomings, AI videos popular on major video platforms tend to focus on "meme" and "humor" content, as such videos have lower cost and effect requirements.
Sadly, despite the lack of widespread success, the AI video sector faces premature competition, with multiple vendors rapidly iterating on features but failing to deliver significant user experience upgrades.
Taking Kuaishou's Keling as an example, its camera control, HD generation, and image-to-video functions are mirrored by other domestic AI video generators, including Zhipu's Qingying and ByteDance's Jimeng.
Source: Keling
However, these homogenized, incremental features fail to significantly enhance user experience.
Ultimately, the intense competition in the video generation sector stems from the limitations faced by current LLMs, as players struggle to continue the "AI narrative" amidst bottlenecks. Unfortunately, no major player has yet to tell this story convincingly.
02.
Deep reasoning as a savior amidst data scarcity

With various training data nearing exhaustion, how can the myth of LLM's scaling law persist?
After OpenAI's release of the o1 model, the answer became clear: reinforcement learning.
Yang Zhilin, CEO of Dark Side of the Moon, analyzed that the upper limit of this generation of AI technology is determined by the capabilities of text models.
Technically, Yang's assertion holds true.
Even in multimodal tasks, textual understanding and reasoning are crucial. Taking Sora as an example, its training data includes numerous "video-text pairs," where each video clip is accompanied by detailed textual descriptions, enabling the model to establish a mapping between textual semantics and visual representations.
Moreover, for video models to achieve greater progress, such as developing complete narrative structures, they require text models capable of complex logical reasoning.
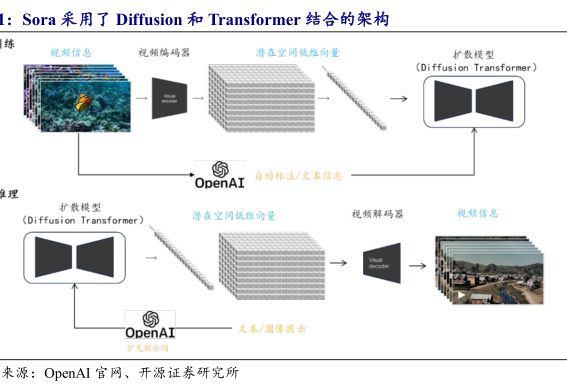
Without text models capable of intricate narrative planning, video models struggle to surpass this ceiling.
Thus, the future direction of LLMs is clear: Text models dictate the upper limit of multimodal capabilities, while deep reasoning defines the upper limit of current text models.
Consequently, following the release of o1, domestic giants like ByteDance, Zhipu Qingyan, and Dark Side of the Moon have integrated "deep search" functionalities into their large models, essentially a connected version of deep reasoning.
However, not all vendors excel in this area.
To compare, we pose a question that tests deep reasoning and analytical abilities: Analyze the global smartphone market trends over the past three years, including market share changes, technological innovations, and shifts in consumer preferences across major brands.
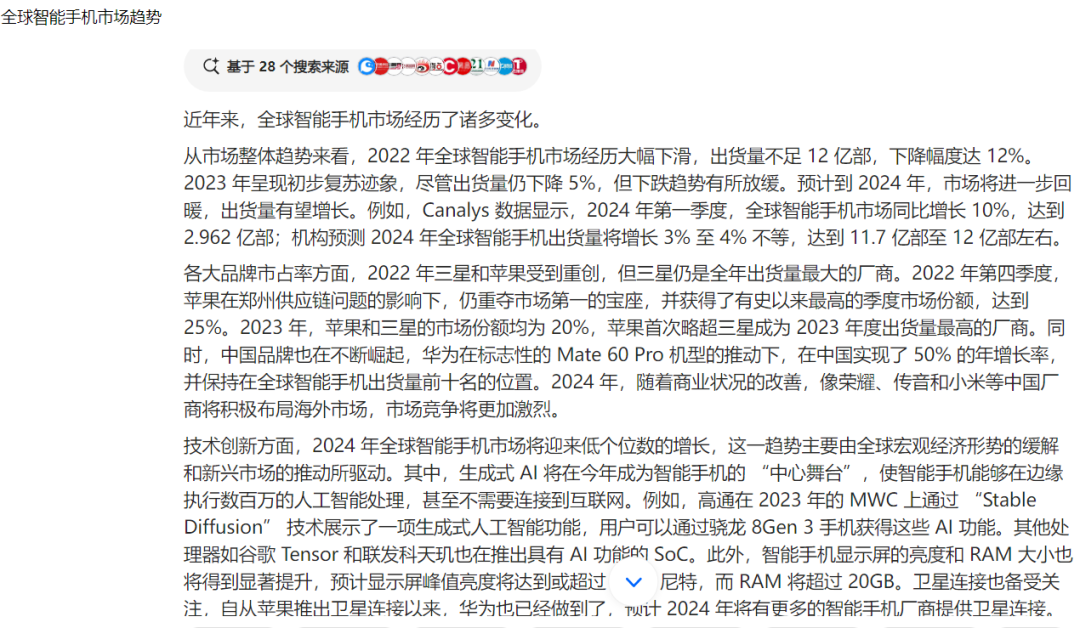
Source: DoubaoFirst, we evaluate ByteDance's Doubao large model.
While it hits some crucial points, its overall content and structure appear bloated and disorganized, lacking sufficient structuring and refinement, thereby imposing a heavy reading burden on users.

Source: Zhipu Qingyan
Next, we evaluate Zhipu Qingyan's AI.
Compared to Doubao, Zhipu AI's deep reasoning is more structured and organized, detailing market performance and share for brands like Apple, Samsung, and vivo.
However, each section's summary and analysis remain somewhat concise.

Source: KIMI
Lastly, we have Kimi from Dark Side of the Moon.
With deep search activated, Kimi exhibits greater depth and thoroughness in information analysis and summarization. It not only illustrates market share changes by year for different brands but also details specific technological innovations introduced by each brand across years.
Overall, Kimi's depth and precision in complex problem analysis significantly surpass those of Doubao and Zhipu AI.
Thus, in the crucial area of "deep reasoning," which tests LLMs' capabilities, domestic vendors have demonstrated notable disparities.
03.
Pursuing 'large and comprehensive' leads to strategic dilemmas

As mentioned, since OpenAI launched o1, the development of large models has reached a strategic crossroads.
At this critical juncture, some domestic giants like ByteDance, due to their significant inertia in short video business, have not delved deeply into deep reasoning. Instead, they rely on low-cost competition and a plethora of unrefined features to secure top spots in domestic large model rankings.
Source: Doubao
According to Tan Dai, President of Volcano Engine, "The pricing of Doubao's main model in the enterprise market is only 0.0008 yuan per thousand tokens, 99.3% cheaper than the industry average."
But blindly reducing prices to pursue "cost-effectiveness" reveals, to some extent, a lack of core competitiveness in their own models.
Similar to ByteDance, Zhipu Qingyan, one of the "AI Six Little Tigers," has also embarked on a path of pursuing "bigness and comprehensiveness." In short, the current Zhipu has also become an AI enterprise that strives to "capture everything from painting, video, and search in one fell swoop."
Source: Zhipu Qingyan
But in reality, this pursuit of "bigness and comprehensiveness" reflects a kind of "desperate struggle" in business.
This is because currently, domestic business owners have a low willingness to purchase software, and the value brought by large To B models to enterprises is still fragmented. In 2023, the domestic large model market size was only 5 billion yuan, and it will only increase to 12 billion yuan in 2024.
In the context of a narrow B-end market and an untapped C-end market, any enterprise pursuing large models must continuously raise funds, burn money, and horizontally expand its user base to keep its model alive.
However, this land-grabbing logic is essentially an Internet-era mindset, which cannot truly "revive" AI. Because unlike the Internet, the boundaries of AI products are not determined by the number of users but by tangible technical capabilities.
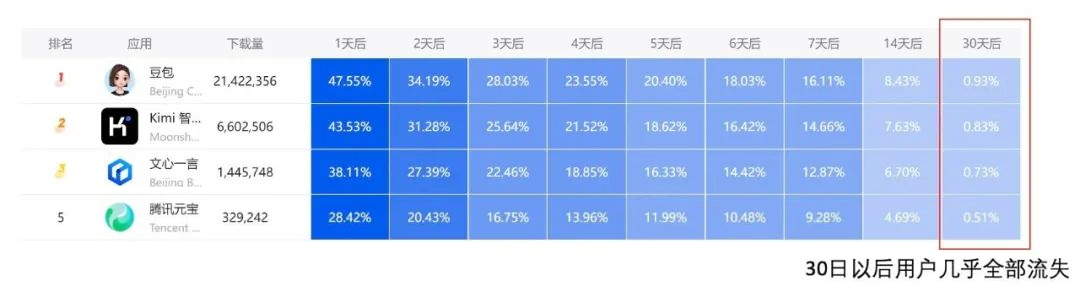
A somewhat counterintuitive reality is that compared to dazzling technologies like video generation that are easier to imagine, it may be deep reasoning, a tough and unsexy technology, that can truly bring breakthroughs to the C-end.
The reason is that video generation primarily serves creative expression, with relatively fixed application scenarios, and its user base and monetization models are relatively homogeneous. Its value lies in content production, with a relatively straightforward ROI.
Essentially, it is more like an efficiency tool rather than a technology that can bring disruptive changes.
In contrast, deep reasoning belongs to basic cognitive abilities, empowering various applications. Its breakthroughs can bring about universal improvements in various directions, and its capabilities can be transferred and reused, making it easier to generate synergies.
More importantly, as this technology develops, it will gain a deeper understanding of users and provide increasingly personalized and precise advice.
This characteristic of continuous learning and evolution makes it difficult to replace with simple tools or services, which is a lesson that some short-lived "viral apps" need to learn from.
Unfortunately, on this difficult but correct path, there are still only a handful of enterprises that dare to persevere and achieve success.
-
![]()
"Silver October" Sales Surge: Multiple Brands Hit Record Highs, New Energy Penetration Rate Eyes 60%
-
![]()
Leveraging AI to Govern Factories Amidst Fierce Industrial Rivalry
-
![]()
Alibaba Initiates Strategic Campaign for 'Embodied AI'
-
![]()
Xiaoma and WeRide return to list in Hong Kong simultaneously, but Tiancheng Lou and Xu Han haven't won yet
-
![]()
Superior Sound, High Usability, and Strong Security: Hikvision Unveils an All-Encompassing Networked Audio System
-
![]()
Who Will Be the Pioneer in Launching Solid-State Batteries?
-
![]()
Why Apple Can Still Win Without AI Enhancement
-
![]()
Why Is NVIDIA Making a Strategic Play on Nokia?