OpenAI's Missed 7 Months: Will Agent 2.0 Explode with Terminal Adoption?
 11/05 2024
11/05 2024
 561
561

In March 2024, OpenAI shut down the GPT Store, which had only been operating for two months.
Just seven months later, Bret Taylor, the current chairman of OpenAI's board, founded a new company that raised $4.5 billion, also focusing on Agent platforms. The entire AI community embarked on a spree of "ditching" OpenAI, fueled by the release of Claude's "Computer Use" and Zhipu's AutoGLM agent.
On October 26, Microsoft open-sourced OmniParser, a pure vision-based GUI screen parsing tool, and Google's similar product, "Project Jarvis," is expected to launch in December.
It's not just large model vendors joining the spree. A month after announcing a deep collaboration with Zhipu, Honor also presented its own results. On October 30, Zhao Ming, CEO of Honor, demonstrated the AI agent YOYO's ability to autonomously handle tasks. By simply telling the phone to "order 2,000 cups of coffee," YOYO successfully placed an order nearby, keeping nearby coffee shops and delivery drivers busy.
Whether on desktops or mobile devices, Agents are truly realizing "autonomy": from ordering coffee to buying toothpaste, AI can complete all tasks with a single command, without human intervention. Compared to the previous generation of Agents that could only offer suggestions, AutoGLM represents a leap from 1.0 to 2.0.
The secondary market has also been ignited by agents. Following the release of AutoGLM, share prices of companies that invest in, have equity stakes in, or collaborate closely with Zhipu have risen significantly, and "Zhipu concept stocks" have strengthened. Since last week, Zhipu concept stocks have remained active, with related stocks such as Doushen Education, Simei Media, and Changshan Beiming hitting their daily upper limits at one point.
As large models begin to land on mobile devices, vendors struggling with implementation are not only focusing on software capabilities. From agents to "AI OS" centered on large models, large model startups have found a new path for the commercialization of AI large models.
What changes have occurred with Agents in the seven months OpenAI missed?
Why have agents suddenly ignited enthusiasm in the secondary market?
Huatai Securities pointed out that AI Agents have achieved a breakthrough for large models, moving from "speech" to "action."
Compared to the previous generation of Agents that only "talked the talk," whether it's Computer Use or Phone Use, these agent products enable AI to operate autonomously: upon receiving a command, AI will take control of the device personally, including clicking, typing, and other interactive functions.
Taking Anthropic's "Computer Use" as an example, in the demonstration, it completed the task of "filling out company form data" without human intervention.
Upon receiving the task, AI breaks it down into multiple steps:
1. First, check if the required company data exists in existing tables;
2. If no results are found, AI opens the search interface and searches for data information about the relevant company itself;
3. Finally, it completes data entry for each blank section of the table.
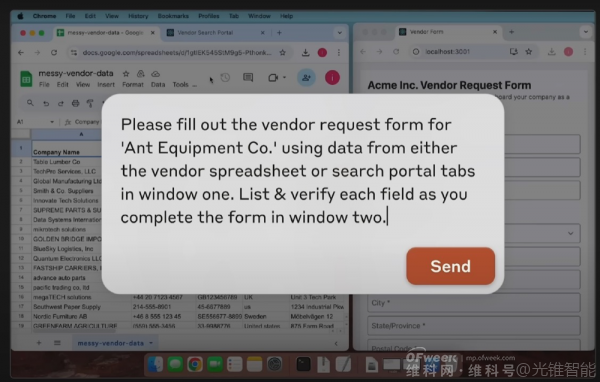
By entering commands in the dialog box, AI autonomously completes the form based on table information
In the demonstration video, Zhipu's AutoGLM smoothly invokes multiple apps on the phone. When the user requests to purchase an Americano from Luckin Coffee, AutoGLM opens the Meituan app to search for the brand, automatically adds the desired item to the shopping cart, and jumps to the checkout interface. The user only needs to select the "Place Order" button.
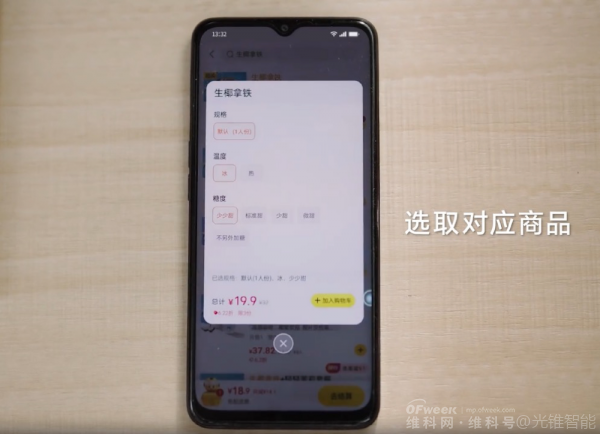
Based on user needs, AI autonomously selects the coffee flavor
Microsoft has also recently open-sourced OmniParser, a tool for identifying web-based visual interfaces. In the example video on the Github showcase page, OmniParser also demonstrates autonomous operation capabilities:
When tasked with collecting vegetarian restaurants, OmniParser locates the word "restaurant" on the webpage by parsing interface elements. After searching and finding no results that meet the criteria, it automatically pulls up the search box, locates relevant restaurants based on keywords, and completes the selection.
These simple operations for humans present considerable challenges for AI:
First, whether on desktops or mobile devices, Agents need to complete steps such as clicking, swiping, and searching. Teaching models to learn and achieve precise operations is a major obstacle hindering Agent evolution.
This breakthrough benefits from the capabilities brought about by the evolution of foundational large models.
For example, how can AI understand and operate a GUI (graphical user interface)?
An Agent's core system is divided into five parts: perception, planning, memory, action, and tools. The perception system captures and analyzes external visual, auditory, and textual information. Based on a complete understanding of this information, the Agent plans the received tasks by combining this information and breaking them down into multiple steps using CoT (chain of thought) for sequential execution.
However, in 2023, large language models were still in the text capability stage. When multimodal capabilities such as video and speech had not yet made breakthroughs, Agents were limited by the capabilities of their underlying foundations and could not fully perceive the environment, leading to errors in the execution of multiple tasks and naturally failing to reach the level of application.
Microsoft's solution is to use screenshots to label all interactable icons and buttons on the screen, extract them as information, and define them based on the recognized content, allowing AI to understand the function of each interaction point and achieve autonomous operation. Similarly, Zhipu's AutoGLM uses multimodal capabilities to recognize and interpret UI on mobile devices.

Based on the above, Zhipu has also found solutions to issues such as insufficient data and strategy distribution drift.
For example, due to the high cost of acquiring trajectory data and insufficient data, it is not possible to fully train large model agents on motor execution capabilities.
To address this, they introduced a self-developed "decoupled intermediate interface for basic agents" design in AutoGLM. Taking "submit order" as an example, AutoGLM serves as an intermediate interface, decoupling the "task planning" and "action execution" phases through a natural language intermediate interface.
Compared to past end-to-end agent processing, this method nearly doubles the accuracy of AI operations.
In addition to the need for precise interactive operations, agents must also have real-time planning and correction capabilities to provide effective solutions promptly when encountering problems, especially when facing complex and diverse tasks.
To this end, AutoGLM employs the "self-evolving online curriculum reinforcement learning framework" technology, allowing agents to continuously learn and improve their response capabilities in mobile and computer-based environments.
"Just like a person acquiring new skills throughout their growth," Zhang Peng explained.
With the support of these two capabilities, AutoGLM has achieved significant performance improvements in Phone Use and Web Browser Use. Official data shows that in the WebArena-Lite benchmark, AutoGLM achieves approximately a 200% performance improvement over GPT-4o.
Overall, after a year of evolution in large language models and multimodal models, AI Agents have finally achieved the transition from individual intelligence to tool use, completing the leap to 2.0.
Throughout the history of artificial intelligence, its development path is strikingly similar to human evolution, progressing from learning "language" to "solving problems" to "using tools."
More than three months ago, OpenAI divided the path to AGI into five stages. On the day AutoGLM was launched, Zhipu also announced its technology roadmap to the outside world.

At the L1 stage, the focus of AI is on learning to use "language," including speech, text, and vision.
Looking back two years, since the advent of ChatGPT, attention has shifted to generative AI. In just half a year, large language models have emerged frequently: GPT, Claude, GLM, and other series of large models have emerged and continued to evolve, focusing on language understanding, logical ability, and other indicators.
Beyond large language models, AI vendors have also focused on another peak—multimodal large models. Breakthroughs have been achieved around visual and auditory capabilities:
Starting from the first half of this year, end-to-end speech models have been released successively, enabling AI to "hear" human emotions and engage in warm communication.
In April this year, the GPT-4o launch event showcased the charm of real-time dialogue with AI. Compared to previous models, end-to-end speech models compress tasks previously completed by multiple large models into a single model, reducing latency while fully retaining human voice emotions, pauses, and other information, allowing for interruptions and continued communication at any time.
Multimodal models equip large models with "eyes" to see and understand changes in the real-world environment.
Taking Zhipu's GLM-4V-Plus as an example, it not only maintains the dialogue capabilities of large language models but also significantly improves its understanding of video and images. Zhipu has also launched the video call API interface GLM-4-Plus-VideoCall, enabling large models to engage in "video calls" with humans, recognizing surrounding objects and responding fluently.
"The brain is a highly complex system, including multimodal perception and understanding abilities such as hearing, vision, taste, and language, as well as short-term and long-term memory, deep thinking and reasoning abilities, emotions, and imagination," said Zhang Peng.
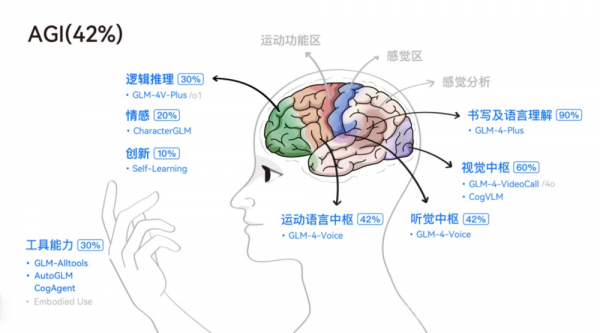
It can be seen that at the current stage, large models are beginning to simulate some human brain functions, including vision, hearing, and language understanding.
Zhipu revealed that in the five stages of their plan, L1 capabilities have "reached 80-90%."
During the evolution of basic abilities such as listening, speaking, reading, and writing, logical thinking ability, representing L2, is also evolving rapidly.
A milestone for L2 is OpenAI's o1 model, which breaks away from the GPT family and focuses on refining CoT (chain of thought) capabilities. It has learned slow thinking: while applying the chain of thought to break down instructions into multiple simple steps for completion, o1 uses reinforcement learning to identify and correct errors.
OpenAI stated that as reinforcement learning increases and thinking time extends, o1's performance will continue to improve. Official data shows that o1 outperformed 93% of participants in programming competitions hosted by Codeforces and exceeded the capabilities of doctoral students in basic disciplines such as physics, chemistry, and biology.
Therefore, o1 is also seen as a new evolution in human logical thinking ability at L2, beginning to demonstrate reasoning abilities on par with humans.
Only after L1 language and multimodal capabilities are basically established can new products with L2 logical thinking ability and L3 tool capability levels emerge based on these underlying capabilities.
This upgraded agent's ability to control smart terminals actually falls under the L3 stage.
As philosopher Engels said, the essential difference between humans and animals lies in their ability to make and use tools.
The upgrade to Agent 2.0 also represents another milestone for humans on the path to AGI.
"AutoGLM can be seen as Zhipu's exploration and attempt in L3 tool capabilities," said Zhang Peng.
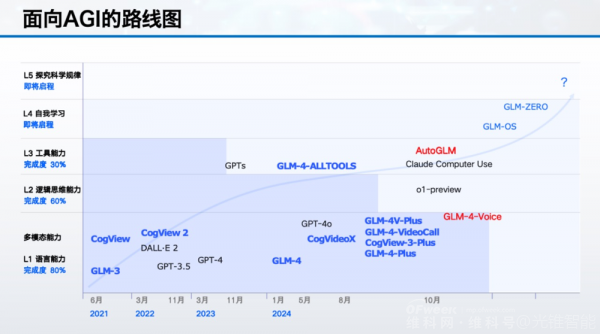
Looking ahead to L4 and L5, OpenAI believes that at the L4 stage, AI can innovate on its own; at the L5 stage, AI possesses the ability to integrate into or form its organization.
Zhipu has also provided new definitions for the L4 and L5 stages. Compared to OpenAI, Zhipu has more aggressive expectations for AGI.
"We believe that L4-level AI means that AI can achieve self-learning, self-reflection, and self-improvement. L5 means that AI comprehensively surpasses humans, possessing the ability to explore ultimate questions such as scientific laws and the origin of the world," said Zhang Peng.
As AI advances to the L3 stage, large model vendors have also pressed the "accelerator" button on commercialization efforts.
In fact, terminal hardware and large model vendors are moving towards each other. Observing AI hardware released this year, whether or not it is equipped with an agent makes a significant difference in the AI capabilities of the product.
The most notable comparison is the Honor Magic7, released on October 30, equipped with the YOYO agent.
Based on the agent's ability to execute tasks directly, Zhao Ming's request for 2,000 cups of beverages overwhelmed all nearby coffee shops. From "step-by-step" interaction to the agent's "autonomous execution," Zhao Ming proudly announced, "Mobile phones have entered the era of autonomous driving."
To tap into the potential of combining hardware and AI capabilities, it is no longer surprising to see intelligent terminal vendors and large model companies collaborating.
Among them, Zhipu is currently the domestic large model startup with the most collaborations with mobile phone manufacturers. Previously, Zhipu officially announced a strategic cooperation with Honor, and in the past six months, it has successively collaborated with Samsung, Intel, and Qualcomm to support terminal intelligence upgrades by providing underlying AI capabilities.
Similarly, Apple believes that the Apple Intelligence agent will directly improve iPhone sales. In the just-concluded Q4 2024 earnings call, CEO Tim Cook said, "The iPhone 16 series sold better than the iPhone 15 series, and after the launch of Apple Intelligence, user enthusiasm for upgrading to iOS 18.1 was double that of the same period last year."
Empowering AI will be an important strategy for mobile phone manufacturers in the coming years. According to IDC forecasts, AI-powered mobile phone shipments are expected to increase by 363.6% year-on-year in 2024, reaching 230 million units. Anthony Scarsella, IDC's research director for mobile phones, stated that after achieving triple-digit growth in 2024, AI-powered mobile phones will experience double-digit growth for four consecutive years.
Why are hardware terminal manufacturers so enthusiastic about the implementation of agents? Behind this lies the fact that agents have fundamentally disrupted the power dynamics between hardware manufacturers and consumer platforms.
Taking "Zhao Ming Orders Coffee" as an example, before the advent of agents, users mostly relied on channel inertia when ordering coffee. Users would choose to place orders on platforms like Meituan, Starbucks Mini Programs, Ele.me, etc., based on factors such as habits, coupons, and points. However, with the introduction of agents that place orders on behalf of users, platforms no longer directly interact with customers, and agents gain the right to allocate orders directly for the platform. In other words, by integrating agents, AI terminal manufacturers gain the right to "tax" software platforms.
Similar to how Apple is currently "pained" by countless manufacturers due to the "Apple Tax," which they cannot help but accept. It is precisely because Apple controls the distribution and revenue flow of the App Store that it can rely on a business model that almost "earns effortlessly," allowing it to increase the company's overall revenue quality with software service revenue that averages over 70% gross margin.
According to the fourth-quarter report of 2024, Apple's software services business accounted for 26% of revenue, with a business gross margin of 74%, and the company's overall gross margin was 44%.
Seeing such high-quality revenue, it's no wonder that AI hardware manufacturers are actively pursuing the integration of agents. Major companies that have witnessed this new monetization model have also started cooperating with AI hardware manufacturers.
In addition to enhancing AI software functions such as photo editing and text summarization and integrating agents, building large end-side models and deeply integrating them into hardware systems to become native capabilities is the next step for mobile phone manufacturers to strengthen their AI capabilities.
Based on the core capabilities provided by end-side large models, AI mobile phones are now capable of doing many things that were previously impossible, and using agents to perform tasks is just the first step.
In contrast, Zhipu has even grander ambitions. They hope to deeply integrate AI capabilities into terminals and reshape operating systems with large models.
"We hope our efforts can drive a new paradigm shift in human-computer interaction and lay a solid foundation for building GLM-OS, a general-purpose computing system centered on large models," said Zhang Peng when unveiling AutoGLM.
Not only are smartphones focusing on enhancing AI capabilities, but chip manufacturers are also accelerating the integration of AI capabilities. Last month, Qualcomm announced that it would integrate Zhipu's GLM-4V end-side visual large model into the Snapdragon 8 Ultimate Edition chip for deep adaptation and inference optimization. The launched ChatGLM application supports real-time voice conversations using cameras and also allows for uploading photos and videos for dialogue.
Before AI is perfectly implemented in embodied intelligence, mobile phones, computers, and other terminals will be better scenarios for the implementation of large AI models. Through the demonstration of L3 tool capabilities, AutoGLM will have the opportunity to tear open new business models.
However, Zhipu's AutoGLM currently relies on calling the phone's accessibility permissions to achieve cross-application calls. In the future, if more complex instructions are to be completed, it will be necessary to establish deep cooperation with smart terminal manufacturers and application developers to obtain more operational permissions.
The "soft" strength of large models must ultimately be realized through "hard" means.
Currently, the commercialization of large models is still primarily based on software payments, including subscriptions for C-end users and API interfaces or project-based models for B-end users. However, in the future, to truly realize AGI and unleash even greater capabilities, it will be necessary to interact with the physical world through hardware.
The implementation of agents on the end-side represents an opportunity that helps large model companies accumulate substantial engineering capabilities on hardware and even obtain some valuable edge data. This lays a solid foundation for future interactions with the physical world, whether through XR devices or embodied intelligent robots.
In the future, the implementation on smart terminals will be a new high ground for large model technology and commercialization.
-
![]()
Over 40,000 Autonomous Vehicles in 300 Cities: The First Comprehensive Technical Standard 'General Technical Specifications for Functional Autonomous Vehicles' Marks an Industry Watershed?
-
![]()
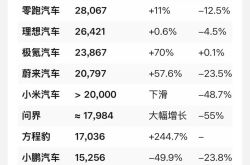
February Sales Plunge for Emerging Automakers: Is the Era of Booming Growth Over?
-
![]()
Overseas Contribution at 73%, MiniMax Sets an Example for AI Global Expansion
-
![]()
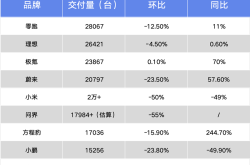
February Sales Report: Leapmotor Tops New Forces, Zeekr Enters Top Three
-
![]()
What Are the Tricks Behind 7-Year Low-Interest Auto Loans?
-
![]()
Strait of Hormuz Blockade Triggers Global Reassessment of China’s New Energy Vehicle Strategy
-
![]()
Price Reductions as a Counterattack: Why Are Joint Venture Cars Ceding More Market Share?
-
![]()
MWC Unveils the Second Half of the Automotive Industry! Chips, AI, and Communications Become Core Sectors